はじめに
Linux環境においてハードディスクやUSBメモリなどのストレージデバイスへアクセスするためには、mountコマンドでデバイスをマウントする必要があります。
普段おまじないのようにこのコマンドを使用していますが、一度デバイスをマウントしてしまえば、デバイスの種類やファイルシステムを意識することなく、ファイルへの操作を行うことができます。
身近でありながら不思議な機能を持っているmountがどのように動作しているか気になったのでカーネルのソースコードを少し調べてみました。
ただし、
- 実際のファイルシステムのコードを追う方が直接mountシステムコールを見ていくよりも理解がしやすい
- いきなりext4とかだとファイルシステムの構造自体が難しくて理解しきれない
ことから、比較的シンプルなファイルシステムであるminixのソースコードをベースに調査を行っています。
minixファイルシステムは実運用されているシステムではほぼ使用されていないと思いますが、基本的なことが把握できれば他のファイルシステムについても応用が効くのではないかと思います。
調査対象のカーネルソースコードのバージョンは4.19です。引用したソースコード中の日本語コメントは私が追記した説明となります。
mountコマンドのおさらい
mountコマンドのフォーマットは以下のようになっています。
mount [-fnrsvw] [-t fstype] [-o options] device dir
また、mountコマンドから実行されるmountシステムコールは以下のように定義されています。
int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);
当然ですが、カーネルのmountシステムコールの定義もユーザ層のmountシステムコールと同じ引数を持ちます。ただし、引数名は少し違っています。
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
char __user *, type, unsigned long, flags, void __user *, data)
{
return ksys_mount(dev_name, dir_name, type, flags, data);
}
mountコマンドの各引数とmountシステムコールの引数とは以下のように対応しています。
| 概要 | mountコマンド | mountシステムコール |
|---|---|---|
| ファイルシステムの存在するファイル名 | device | source |
| ファイルシステムのマウント先ディレクトリ名 | dir | target |
| ファイルシステム名 | fstype | filesystemtype |
| オプション | options | mountflags |
| オプション(ファイルシステム依存) | options | data |
ファイルシステムの登録
上述の通り、mountシステムコールを実行するためには、マウント対象となるファイルシステムを指定する必要があります。
これは言い換えれば、カーネル側では該当するファイルシステム名を元に何か処理を行うことを意味しています。
よって、ファイルシステムモジュールではまず、ファイルシステムをカーネルに登録する必要があります。
ファイルシステムモジュールでは以下のように初期化時にregister_filesystemを実行し、ファイルシステムの登録を行います。
file_system_type構造体のnameメンバがファイルシステム名となっており、minixファイルシステムでは"minix"がファイルシステム名として設定されています。
また、モジュールのrelease時にはunregister_filesystemを実行し、ファイルシステムの登録を解除します。
mountメンバ関数については後述します。
static struct file_system_type minix_fs_type = {
.owner = THIS_MODULE,
.name = "minix",
.mount = minix_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
MODULE_ALIAS_FS("minix");
static int __init init_minix_fs(void)
{
int err = init_inodecache();
if (err)
goto out1;
/* ファイルシステムの登録 */
err = register_filesystem(&minix_fs_type);
if (err)
goto out;
return 0;
out:
destroy_inodecache();
out1:
return err;
}
static void __exit exit_minix_fs(void)
{
/* ファイルシステムの登録解除 */
unregister_filesystem(&minix_fs_type);
destroy_inodecache();
}
module_init(init_minix_fs)
module_exit(exit_minix_fs)
file_system_type構造体のデータはリスト(file_systems)によって管理されており、find_filesystem関数にファイルシステム名を指定することで該当のfile_system_typeデータへのポインタを取得できます。
未登録のファイルシステムを指定した場合、find_filesystemは該当のファイルシステムが見つからないため、file_systemsリストの末端のポインタをリターンします。
init_minix_fs実行時点ではファイルシステムは登録されていないので、register_filesystemはリターンされたリストの末端に新しいfile_system_type型のデータを登録します。
static struct file_system_type **find_filesystem(const char *name, unsigned len)
{
struct file_system_type **p;
for (p = &file_systems; *p; p = &(*p)->next)
if (strncmp((*p)->name, name, len) == 0 &&
!(*p)->name[len])
break;
return p;
}
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
BUG_ON(strchr(fs->name, '.'));
if (fs->next)
return -EBUSY;
write_lock(&file_systems_lock);
p = find_filesystem(fs->name, strlen(fs->name));
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
register_filesystemで登録したファイルシステム名は、/proc/filesystemsで確認できます。
モジュールをアンロードし、unregister_filesystemを実行すると、/proc/filesystemsから該当のファイルシステム名が削除されます。
$ cat /proc/filesystems
nodev sysfs
nodev rootfs
nodev ramfs
nodev bdev
nodev proc
...
vsfs
minix #minixが登録されている
register_filesystemでファイルシステム名を登録したことで、カーネルはmountシステムコールに指定されたファイルシステム名と実際のファイルシステムとを結びつけることができるようになります。
mountコマンドで-tによるファイルシステム名を省略した際の動作
ちなみに、-tでファイルシステムを指定せずにmountコマンドを実行した場合でもmountは成功します。これはどうしてでしょうか。
試しに以下のように-tを指定せずにmountを実行した際のシステムコールへ渡される引数をstraceで見てみます。
$ dd if=/dev/zero of=minix.img bs=1024 count=2048
$ mkfs.minix minix.img
$ mkdir mnt
$ sudo strace -o strace.txt mount -o loop minix.img mnt
すると、以下のようにmountシステムコール実行時には"minix"がファイルシステム名としてちゃんと指定されていることが見えます。
また、mountの前に/proc/filesmystemsをreadしていることもわかります。
このことから、-tを指定しない場合、mountコマンドは/proc/filesystemsを使って指定のパーティション上のファイルシステム名を推測してくれていることがわかります。
(指定したデバイスファイルの先頭を読みだして、マジックナンバーを照合しているのではないかと思います。)
open("/proc/filesystems", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0444, st_size=0, ...}) = 0
read(3, "nodev\tsysfs\nnodev\trootfs\nnodev\tr"..., 1024) = 411
...
mount("/dev/loop1", "~/mnt", "minix", MS_MGC_VAL, NULL) = 0
mount実行時のカーネル処理の流れ
次にmountシステムコールを実行時のカーネルの処理の流れについて見ていきます。
上述の通り、mountシステムコールの実体はfs/namespace.cで定義されていますが、実体はksys_mountとなっています。
また、ksys_mountはユーザ層からの引数のコピーを行っていますが、最終的な処理はdo_mountにまかせています。
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
char __user *, type, unsigned long, flags, void __user *, data)
{
return ksys_mount(dev_name, dir_name, type, flags, data);
}
int ksys_mount(char __user *dev_name, char __user *dir_name, char __user *type,
unsigned long flags, void __user *data)
{
int ret;
char *kernel_type;
char *kernel_dev;
void *options;
kernel_type = copy_mount_string(type);
ret = PTR_ERR(kernel_type);
if (IS_ERR(kernel_type))
goto out_type;
kernel_dev = copy_mount_string(dev_name);
ret = PTR_ERR(kernel_dev);
if (IS_ERR(kernel_dev))
goto out_dev;
options = copy_mount_options(data);
ret = PTR_ERR(options);
if (IS_ERR(options))
goto out_data;
ret = do_mount(kernel_dev, dir_name, kernel_type, flags, options);
kfree(options);
out_data:
kfree(kernel_dev);
out_dev:
kfree(kernel_type);
out_type:
return ret;
}
do_mount内ではflagsにセットされた値をもとにローカル変数のmnt_flagsにフラグを立てていきます(以下では省略)。
最終的にflagsにセットされたフラグに応じてmount処理を呼び分けています。ここでは新規にマウントした際に実行されるdo_new_mountに焦点を当てます。
long do_mount(const char *dev_name, const char __user *dir_name,
const char *type_page, unsigned long flags, void *data_page)
{
struct path path;
unsigned int mnt_flags = 0, sb_flags;
int retval = 0;
/* 省略 */
if (flags & MS_REMOUNT)
retval = do_remount(&path, flags, sb_flags, mnt_flags,
data_page);
else if (flags & MS_BIND)
retval = do_loopback(&path, dev_name, flags & MS_REC);
else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE))
retval = do_change_type(&path, flags);
else if (flags & MS_MOVE)
retval = do_move_mount(&path, dev_name);
else
retval = do_new_mount(&path, type_page, sb_flags, mnt_flags,
dev_name, data_page);
dput_out:
path_put(&path);
return retval;
}
do_new_mountを見ると、register_filesystemで登録したfile_system_type型のデータを取得しています。そして、vfs_kern_mountにそのデータを渡しています。
static int do_new_mount(struct path *path, const char *fstype, int sb_flags,
int mnt_flags, const char *name, void *data)
{
struct file_system_type *type;
struct vfsmount *mnt;
int err;
if (!fstype)
return -EINVAL;
/* register_filesystemで登録したfile_system_typeデータを取得 */
type = get_fs_type(fstype);
if (!type)
return -ENODEV;
/* file_system_typeデータに設定したmountを実行 */
mnt = vfs_kern_mount(type, sb_flags, name, data);
if (!IS_ERR(mnt) && (type->fs_flags & FS_HAS_SUBTYPE) &&
!mnt->mnt_sb->s_subtype)
mnt = fs_set_subtype(mnt, fstype);
/* 省略 */
}
vfs_kern_mountは以下のようになっています。ここで重要な処理はmount_fsです。
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
struct mount *mnt;
struct dentry *root;
if (!type)
return ERR_PTR(-ENODEV);
mnt = alloc_vfsmnt(name);
if (!mnt)
return ERR_PTR(-ENOMEM);
if (flags & SB_KERNMOUNT)
mnt->mnt.mnt_flags = MNT_INTERNAL;
root = mount_fs(type, flags, name, data);
if (IS_ERR(root)) {
mnt_free_id(mnt);
free_vfsmnt(mnt);
return ERR_CAST(root);
}
mnt->mnt.mnt_root = root;
mnt->mnt.mnt_sb = root->d_sb;
mnt->mnt_mountpoint = mnt->mnt.mnt_root;
mnt->mnt_parent = mnt;
lock_mount_hash();
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts);
unlock_mount_hash();
return &mnt->mnt;
}
EXPORT_SYMBOL_GPL(vfs_kern_mount);
mount_fsでは引数に指定されたtypeのmountメンバ関数を実行しています。つまり、register_filesystemで登録されたfile_system_typeに設定されていたmount関数となります。
ここでようやくファイルシステムの登録とmountシステムコールとがつながりました。
struct dentry *
mount_fs(struct file_system_type *type, int flags, const char *name, void *data)
{
struct dentry *root;
struct super_block *sb;
char *secdata = NULL;
int error = -ENOMEM;
if (data && !(type->fs_flags & FS_BINARY_MOUNTDATA)) {
secdata = alloc_secdata();
if (!secdata)
goto out;
error = security_sb_copy_data(data, secdata);
if (error)
goto out_free_secdata;
}
/* register_filesystemで登録されたmount関数を実行 */
root = type->mount(type, flags, name, data);
if (IS_ERR(root)) {
error = PTR_ERR(root);
goto out_free_secdata;
}
sb = root->d_sb;
BUG_ON(!sb);
WARN_ON(!sb->s_bdi);
/* 省略 */
}
では、type->mount関数では何を行っているでしょうか。上で少し触れましたが、type->mountの実体はminix_mountとなります。
minix_mountの実装は以下のようになっており、カーネルが提供しているmount_bdevを実行するだけの関数です。
static struct dentry *minix_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return mount_bdev(fs_type, flags, dev_name, data, minix_fill_super);
}
mount_bdevの大きな処理としては以下の3つになります。1、2についてはここでは深くは立ち入りません。
- blkdev_get_by_pathでdev_nameに対応するブロックデバイス情報を取得
- sgetでstruct super_block型のデータを作成. dev_nameで指定したデバイスが既にマウント済みの場合はそのスーパーブロック情報を返す
- fill_superでファイルシステムからスーパーブロックを読みだす
struct dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct block_device *bdev;
struct super_block *s;
fmode_t mode = FMODE_READ | FMODE_EXCL;
int error = 0;
if (!(flags & SB_RDONLY))
mode |= FMODE_WRITE;
/* dev_nameに対応するブロックデバイス情報を取得 */
bdev = blkdev_get_by_path(dev_name, mode, fs_type);
if (IS_ERR(bdev))
return ERR_CAST(bdev);
/*
* once the super is inserted into the list by sget, s_umount
* will protect the lockfs code from trying to start a snapshot
* while we are mounting
*/
mutex_lock(&bdev->bd_fsfreeze_mutex);
if (bdev->bd_fsfreeze_count > 0) {
mutex_unlock(&bdev->bd_fsfreeze_mutex);
error = -EBUSY;
goto error_bdev;
}
/* struct super_blockデータを作成 */
s = sget(fs_type, test_bdev_super, set_bdev_super, flags | SB_NOSEC,
bdev);
mutex_unlock(&bdev->bd_fsfreeze_mutex);
if (IS_ERR(s))
goto error_s;
if (s->s_root) {
if ((flags ^ s->s_flags) & SB_RDONLY) {
deactivate_locked_super(s);
error = -EBUSY;
goto error_bdev;
}
/*
* s_umount nests inside bd_mutex during
* __invalidate_device(). blkdev_put() acquires
* bd_mutex and can't be called under s_umount. Drop
* s_umount temporarily. This is safe as we're
* holding an active reference.
*/
up_write(&s->s_umount);
blkdev_put(bdev, mode);
down_write(&s->s_umount);
/* 新規マウント時はelseパスに入る(はず)*/
} else {
s->s_mode = mode;
snprintf(s->s_id, sizeof(s->s_id), "%pg", bdev);
sb_set_blocksize(s, block_size(bdev));
/* ファイルシステムからスーパーブロックを読みだす */
error = fill_super(s, data, flags & SB_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(s);
goto error;
}
s->s_flags |= SB_ACTIVE;
bdev->bd_super = s;
}
return dget(s->s_root);
error_s:
error = PTR_ERR(s);
error_bdev:
blkdev_put(bdev, mode);
error:
return ERR_PTR(error);
}
EXPORT_SYMBOL(mount_bdev);
では、fill_superでは具体的に何を行っているでしょうか。fill_superの実体はbdev_mountの引数で指定されたminix_fill_superになります。
ここで、minix_fill_superの実装を見る前にminixファイルシステムの構造について簡単に説明します。
minixファイルシステム
minixには3つのバージョンがありますが、概略の説明には大きく影響しないので、バージョンごとの違いについては省略します。特に断りがなければ、バージョン1を前提にしています。
minixのファイルシステムは大きく分けて、以下のようにブートブロック、スーパーブロック、inodeビットマップ、zoneビットマップ、inode格納領域、データ格納領域から構成されています。
1ブロックは1024バイトです。ブートブロックとスーパーブロックはそれぞれ1ブロック消費しますが、inodeビットマップ、zoneビットマップ、inode格納領域、データ格納領域が使用するブロック数はファイルシステム上のファイルやディレクトリ数に依存します。ですので、必ずしも以下の図の通りのブロック数になるとは限りません。
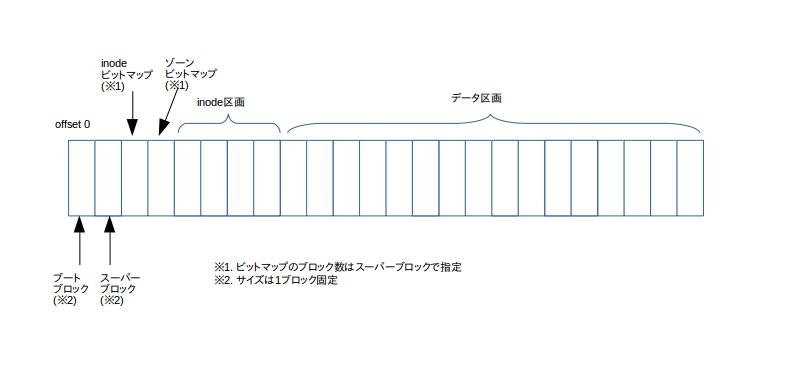
- ブートブロック:minixファイルシステムの先頭1ブロック目に格納される。ブートパーティションとして指定された場合の起動コードを格納する領域
- スーパーブロック:minixファイルシステムの先頭2ブロック目に格納される。ファイルシステムの各種情報を格納する領域
- inodeビットマップ:inode区画の使用状況を管理する。例えば、inode番号2が使用されている場合、inodeビットマップの2ビット目がセットされる
- ゾーンビットマップ:データ区画の使用状況を管理する
- inode区画:inodeが格納される領域
- データ区画:ファイルやディレクトリ等のデータが格納される領域
minixファイルシステムのスーパーブロックの読み出し
minix_fill_superの主な処理は以下となります。リストの番号はソースコード中のコメントと対応しています。
- ブロックデバイスからスーパーブロックを読みだす
- ブロックデバイスから読みだしたスーパーブロック情報を作業用領域にコピーする
- ブロックデバイスからinodeビットマップ、ゾーンbitmapを読みだす
- スーパーブロックの処理関数群をスーパーブロック情報に設定する
- rootパスの取得
static int minix_fill_super(struct super_block *s, void *data, int silent)
{
struct buffer_head *bh;
struct buffer_head **map;
struct minix_super_block *ms;
struct minix3_super_block *m3s = NULL;
unsigned long i, block;
struct inode *root_inode;
/* メモリ上での作業用のスーパーブロック情報 */
struct minix_sb_info *sbi;
int ret = -EINVAL;
sbi = kzalloc(sizeof(struct minix_sb_info), GFP_KERNEL);
if (!sbi)
return -ENOMEM;
s->s_fs_info = sbi;
BUILD_BUG_ON(32 != sizeof (struct minix_inode));
BUILD_BUG_ON(64 != sizeof(struct minix2_inode));
/* ブロックサイズを設定. BLOCK_SIZEは1024
#define BLOCK_SIZE_BITS 10
#define BLOCK_SIZE (1<<BLOCK_SIZE_BITS)
*/
if (!sb_set_blocksize(s, BLOCK_SIZE))
goto out_bad_hblock;
/* 1. ブロックデバイスからオフセット1のブロック(2つ目のブロック==スーパーブロック)の読みだし */
if (!(bh = sb_bread(s, 1)))
goto out_bad_sb;
/* 2. ブロックデバイスから読みだしたスーパーブロック情報を作業用領域にコピー */
ms = (struct minix_super_block *) bh->b_data;
sbi->s_ms = ms;
sbi->s_sbh = bh;
sbi->s_mount_state = ms->s_state;
sbi->s_ninodes = ms->s_ninodes;
sbi->s_nzones = ms->s_nzones;
sbi->s_imap_blocks = ms->s_imap_blocks;
sbi->s_zmap_blocks = ms->s_zmap_blocks;
sbi->s_firstdatazone = ms->s_firstdatazone;
sbi->s_log_zone_size = ms->s_log_zone_size;
sbi->s_max_size = ms->s_max_size;
s->s_magic = ms->s_magic;
/* 省略 */
/*
* Allocate the buffer map to keep the superblock small.
*/
/* 3. inodeビットマップ数、ゾーンbitmap数の判定 */
if (sbi->s_imap_blocks == 0 || sbi->s_zmap_blocks == 0)
goto out_illegal_sb;
i = (sbi->s_imap_blocks + sbi->s_zmap_blocks) * sizeof(bh);
map = kzalloc(i, GFP_KERNEL);
if (!map)
goto out_no_map;
/* 3. inodeビットマップ、ゾーンbitmapの読み出し */
sbi->s_imap = &map[0];
sbi->s_zmap = &map[sbi->s_imap_blocks];
block=2;
for (i=0 ; i < sbi->s_imap_blocks ; i++) {
if (!(sbi->s_imap[i]=sb_bread(s, block)))
goto out_no_bitmap;
block++;
}
for (i=0 ; i < sbi->s_zmap_blocks ; i++) {
if (!(sbi->s_zmap[i]=sb_bread(s, block)))
goto out_no_bitmap;
block++;
}
minix_set_bit(0,sbi->s_imap[0]->b_data);
minix_set_bit(0,sbi->s_zmap[0]->b_data);
/* Apparently minix can create filesystems that allocate more blocks for
* the bitmaps than needed. We simply ignore that, but verify it didn't
* create one with not enough blocks and bail out if so.
*/
block = minix_blocks_needed(sbi->s_ninodes, s->s_blocksize);
if (sbi->s_imap_blocks < block) {
printk("MINIX-fs: file system does not have enough "
"imap blocks allocated. Refusing to mount.\n");
goto out_no_bitmap;
}
block = minix_blocks_needed(
(sbi->s_nzones - sbi->s_firstdatazone + 1),
s->s_blocksize);
if (sbi->s_zmap_blocks < block) {
printk("MINIX-fs: file system does not have enough "
"zmap blocks allocated. Refusing to mount.\n");
goto out_no_bitmap;
}
/* set up enough so that it can read an inode */
/* 4. スーパーブロックの処理関数群を設定 */
s->s_op = &minix_sops;
/* 5. rootパスのinode取得
#define MINIX_ROOT_INO 1
*/
root_inode = minix_iget(s, MINIX_ROOT_INO);
if (IS_ERR(root_inode)) {
ret = PTR_ERR(root_inode);
goto out_no_root;
}
/* 5. rootパスのdentry作成 */
ret = -ENOMEM;
s->s_root = d_make_root(root_inode);
if (!s->s_root)
goto out_no_root;
if (!sb_rdonly(s)) {
if (sbi->s_version != MINIX_V3) /* s_state is now out from V3 sb */
ms->s_state &= ~MINIX_VALID_FS;
mark_buffer_dirty(bh);
}
/* 省略 */
各処理ついて説明します。
1. ブロックデバイスからスーパーブロックを読みだす
minixファイルシステムの概要で説明したとおり、minixファイルシステムのスーパーブロックは2ブロック目に格納されています。そのため、sb_read(s, 1)でブロックデバイスの先頭から2ブロック目(オフセット1のブロック)を読みだしています。
ブロックデバイスから読みだしたブロックデータの格納先のポインタはbuffer_head構造体に格納されます。
buffer_headは以下のように定義されており、一部を説明すると、ブロックデータの格納先へのポインタはb_data、ブロックデータが格納されているページはb_pageとなります。また、ブロックサイズはページサイズ以下と決まっているため、1つのページには複数のブロックのデータが格納される場合があります。b_this_pageは同じページに格納されているブロックデータのリストとなります。
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head *b_this_page;/* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */
size_t b_size; /* size of mapping */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
atomic_t b_count; /* users using this buffer_head */
};
2. ブロックデバイスから読みだしたスーパーブロック情報を作業用領域にコピーする
ブロックデバイス中のスーパーブロックの構造は以下の構造体の通りとなっています。
minixファイルシステムの場合は読みだしたスーパーブロックをそのまま使うのではなく、メモリ上での作業用構造体に値を移し替えています。
struct minix_super_block {
__u16 s_ninodes;
__u16 s_nzones;
__u16 s_imap_blocks;
__u16 s_zmap_blocks;
__u16 s_firstdatazone;
__u16 s_log_zone_size;
__u32 s_max_size;
__u16 s_magic;
__u16 s_state;
__u32 s_zones;
};
3. ブロックデバイスからinodeビットマップ、ゾーンbitmapを読みだす
ビットマップ情報は対応する区画の使用状況を管理する領域です。また、inode区画はinodeを管理する領域です。minixのinodeは以下のように定義されており、1つ32バイトです。
あるファイルのinodeを取得する場合は、inode番号をインデックスとしてinode区画から以下構造体サイズのデータを取得します。
struct minix_inode {
__u16 i_mode;
__u16 i_uid;
__u32 i_size;
__u32 i_time;
__u8 i_gid;
__u8 i_nlinks;
__u16 i_zone[9];
};
実際にinodeを読みだすコードを見た方がイメージが湧きやすいと思います。
inode区画はゾーンビットマップの次から始まるので、先頭2ブロック+ビットマップ領域分を飛ばした上でinode番号に応じたブロックを求め、sb_breadで読みだしています。そして、ブロックから読みだしたデータへのポインタにinode格納位置のオフセットを足して、inodeの格納先のアドレスを算出しています。
struct minix_inode *
minix_V1_raw_inode(struct super_block *sb, ino_t ino, struct buffer_head **bh)
{
int block;
struct minix_sb_info *sbi = minix_sb(sb);
struct minix_inode *p;
if (!ino || ino > sbi->s_ninodes) {
printk("Bad inode number on dev %s: %ld is out of range\n",
sb->s_id, (long)ino);
return NULL;
}
ino--;
/* inodeが格納されているブロック番号 */
block = 2 + sbi->s_imap_blocks + sbi->s_zmap_blocks +
ino / MINIX_INODES_PER_BLOCK;
*bh = sb_bread(sb, block);
if (!*bh) {
printk("Unable to read inode block\n");
return NULL;
}
p = (void *)(*bh)->b_data;
/* ino % MINIX_INODES_PER_BLOCKはブロック中のオフセット */
return p + ino % MINIX_INODES_PER_BLOCK;
}
4. スーパーブロックの処理関数群をスーパーブロック情報に設定する
inodeの割当や削除等はスーパーブロックの処理関数を使用して行います。
minixで実装しているのは以下の関数ですが、super_operations自体は他にも関数IFが定義されています。
static const struct super_operations minix_sops = {
.alloc_inode = minix_alloc_inode,
.destroy_inode = minix_destroy_inode,
.write_inode = minix_write_inode,
.evict_inode = minix_evict_inode,
.put_super = minix_put_super,
.statfs = minix_statfs,
.remount_fs = minix_remount,
};
5. rootパスの取得
rootのパス設定を行ったことで、マウントポイントをrootとして、マウントしたファイルシステムにアクセスできるようになります。
おわりに
minixファイルシステムの実装を通してmount時に何を行っているかを見てきました。
mountについて簡単にまとめると以下のようになります。
- mountシステムコールの実行前にファイルシステム情報(ファイルシステム名、mount関数)を登録しておく必要がある
- mountシステムコール実施時に登録したファイルシステム情報を取得し、該当するファイルシステムのmountを実行する
- ファイルシステムのmount関数を経由して実行されるfill関数が、ファイルシステムが焼かれているブロックデバイスからスーパーブロック情報を読みだす
- fill関数がビットマップ情報やrootパスを設定し、マウントポイントにアクセスできるようにする
ファイルシステムによって細かい箇所は異なると思いますが、大まかな流れについてはどのファイルシステムでも基本的には同じだと思います。
誤っている箇所等がありましたらご指摘いただけますと幸いです。
参考文献
OSについて基礎的な解説をしているサイトです。ファイルシステムについては、40 File System Implementationの説明がわかりやすく、参考になりました。