TwitterAPIの使い方の学ぶために、キーワードとして「コロナ」を含むツイートの件数を調べることにしました。
「コロナ」を含む全てのツイートを取得したいですが、TwitterAPIにはこちらリンクのように
・180リクエスト/15分 かつ 100ツイート/1リクエストという取得件数の制限
・過去7日間分のみという取得対象期間の制限
があります。
そのため20分ごとに1秒間「コロナ」を含むツイートの取得を行いました。
期間指定の方法はこちらの記事を参考にさせていただきました。
TwitterAPIで期間指定してTweetを取得する方法
実行
試したコードがこちらです。
qiita.py
import urllib
from requests_oauthlib import OAuth1
import requests
import sys
import datetime
import openpyxl
def search_tweets(CK, CKS, AT, ATS, word, count, range):
# 文字列設定
word += ' exclude:retweets' # RTは除く
word = urllib.parse.quote_plus(word)
# リクエスト
url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q="+word+"&count="+str(count)
auth = OAuth1(CK, CKS, AT, ATS)
response = requests.get(url, auth=auth)
data = response.json()['statuses']
# 2回目以降のリクエスト
cnt = 0
tweets = []
while True:
if len(data) == 0:
break
cnt += 1
if cnt > range:
break
for tweet in data:
tweets.append(tweet['text'])
maxid = int(tweet["id"]) - 1
url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q="+word+"&count="+str(count)+"&max_id="+str(maxid)
response = requests.get(url, auth=auth)
try:
data = response.json()['statuses']
except KeyError: # リクエスト回数が上限に達した場合のデータのエラー処理
print('上限まで検索しました')
break
return tweets
# APIの秘密鍵
CK = '*************************' # コンシューマーキー
CKS = '*************************************************' # コンシューマーシークレット
AT = '**************************************************' # アクセストークン
ATS = '*************************************************' # アクセストークンシークレット
d=datetime.datetime(2020,7,16,00,00,00)
td=datetime.timedelta(minutes=20)
n=72
f="%Y-%m-%d_%H:%M:%S_"
l=[]
for i in range(n):
l.append((d+i*td).strftime(f))
dd=datetime.datetime(2020,7,16,00,00,1)
tdd=datetime.timedelta(minutes=20)
nn=72
f="%Y-%m-%d_%H:%M:%S_"
ll=[]
for i in range(nn):
ll.append((dd+i*tdd).strftime(f))
print(l)
print(ll)
sss=[]
for (i,n) in zip(l,ll):
word = f'コロナ since:{i}JST until:{n}JST' # 検索ワード
count = 100 # 一回あたりの検索数(最大100/デフォルトは15)
range = 5 # 検索回数の上限値(最大180/15分でリセット)
# ツイート検索・テキストの抽出
tweets = search_tweets(CK, CKS, AT, ATS, word, count, range)
# 検索結果を表示
kk=(str(len(tweets)))
sss.append(kk)
print(kk)
wb=openpyxl.load_workbook("corona.xlsx") #Excelファイルを起動
ws=wb["Sheet1"]
for (i, j) in enumerate(sss, 1) :
ws.cell(row=i,column=1,value=int(j))
wb.save('corona.xlsx')'
こちらのコードでは、7月16日に20分ごとに1秒間72回取得し、件数を"corona.xlsx"に入力しています。
これを元に1日の件数を推定します。
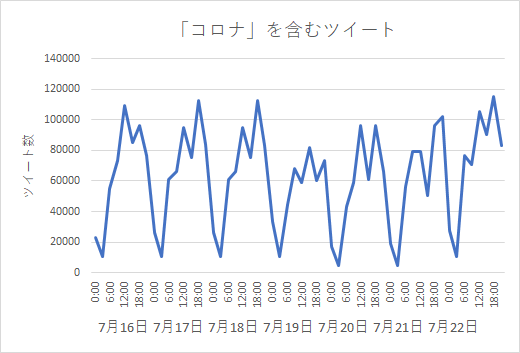
2020/7/16~2020/7/22の一週間でのツイートはこのようになり、合計で3561600件、一日平均50万件になることがわかりました!