はじめに
Byte Swapping(エンディアン変換)について説明します。
エンディアンとは何か、
どのようなときにByte swappingが必要になるのかを説明します。
エンディアンとは
メモリアドレスはbyte単位で割り振られます。
例えば
Addr 0x100000を指定すると
そのアドレスにある1byteが特定できます。
Addr 0x100001を指定すると
そのアドレスにある1byteが特定できます。
一方で
2byte以上のデータ型はbyte境界を跨ってデータを配置
する必要があります。
例えば
2byteの符号なし整数(値は0x1234とします)をメモリに配置することを考えます。
Addr 0x100000 = 0x12, 0x100001 = 0x34 とする流儀と、 .. ビッグ
Addr 0x100000 = 0x34, 0x100001 = 0x12 とする流儀 .. リトル
の2つの方法が考えられます。
それぞれ、ビッグエンディアン、リトルエンディアンといいます。
表現を変えると
データの先頭byteを小さいアドレスに置く方式⇒ビッグエンディアン
データの先頭byteを大きいアドレスに置く方式⇒リトルエンディアン
とも言えます。
どちらかの流儀に統一されればよいのですが、
悲しいことにどちらの流儀も世の中に普及しています。
Intel CPUアーキテクチャはリトルエンディアン
TCP / IPプロトコルはビッグエンディアン
となっています。
ビッグエンディアンのデータをバイナリ形式でみると、
左側に先頭バイトが表示されるため可読性がよいです。
例えば、2byteの符号なし整数0x1234は
ビッグエンディアンでは0x1234は0x12 0x34と表示されますが、
リトルエンディアンでは0x1234は0x34 0x12と表示されます。
ビッグエンディアンがしばしば使われるのはこのような理由からかもしれません。
2byte以上のデータを扱うときには、
何らかの方法でどちらの流儀かの情報を取得する
もしくは、
暗黙の仮定を置く
ことになります。
なお、エンディアンと同じ意味で、
endianness / byte orderという表現も使われます。
Byte swappingとは
エンディアンを相互に変換すること、つまり、
ビッグエンディアン⇒リトルエンディアン
または
リトルエンディアン⇒ビッグエンディアン
のことをByte swappingといいます。エンディアン変換とも言います。
Byte順番を並び変えるためswappingと表現されます。
2byte / 4byteの例を次に示します。
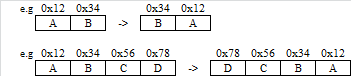
Byte swappingが必要になるケース
Byte swappingはどのようなケースで必要となるのでしょうか。
外部のデータを扱わないプログラムは
Byte swappingの必要はありません。
ネットワークやファイルなど、外部のデータを扱うケース、
かつ、
外部のデータとCPUアーキテクチャのエンディアンが違う
ときにByte swappingが必要となります。
実装
Byte swappingの実装例を示します。
2byte / 4byteの符号なし整数をbyte swappingします。
使用したプロセッサ / OS / gccは以下です。
Intel(R) Core(TM) i7-2600 CPU @ 3.40GHz 64bit
Ubuntu14.04 64bit
gcc (Ubuntu 4.8.2-19ubuntu1) 4.8.2
(*)4つのspaceをtabに置き換えてください。
CFLAGS=-g -O0 -I. -Wextra -Wno-unused-parameter -Wall -Werror
CC=gcc
INCS=test.h
OBJS=test.o
LIBS=#-lpthread -lm
TARGET=test
%.o: %.c $(INCS)
>---$(CC) -c -o $@ $<
$(TARGET): $(OBJS)
>---$(CC) -o $@ $^ $(LIBS)
clean:
>---rm -rf $(TARGET) *.o
# include <stdio.h>
# include <stdint.h>
inline uint16_t swap16(uint16_t value)
{
uint16_t ret;
ret = value << 8;
ret |= value >> 8;
return ret;
}
inline uint32_t swap32(uint32_t value)
{
uint32_t ret;
ret = value << 24;
ret |= (value&0x0000FF00) << 8;
ret |= (value&0x00FF0000) >> 8;
ret |= value >> 24;
return ret;
}
int main(int argc, char* argv[])
{
uint16_t val16;
uint32_t val32;
if (argc != 2) {
return -1;
}
if (sscanf(argv[1], "%x", &val32) == -1) {
return -1;
}
val16 = (uint16_t)(val32>>16);
printf("0x%04x : 0x%04x\n", val16, swap16(val16));
printf("0x%08x : 0x%08x\n", val32, swap32(val32));
return 0;
}
実行
$ make clean
$ make
$ ./test 12345678
0x1234 : 0x3412
0x12345678 : 0x78563412
アセンブラ(-O0;最適化なし)
objdumpでアセンブラを出力してみます。
$ objdump -d test.o
0000000000000000 <swap16>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 89 f8 mov %edi,%eax
6: 66 89 45 ec mov %ax,-0x14(%rbp)
a: 0f b7 45 ec movzwl -0x14(%rbp),%eax
e: c1 e0 08 shl $0x8,%eax
11: 66 89 45 fe mov %ax,-0x2(%rbp)
15: 0f b7 45 ec movzwl -0x14(%rbp),%eax
19: 66 c1 e8 08 shr $0x8,%ax
1d: 66 09 45 fe or %ax,-0x2(%rbp)
21: 0f b7 45 fe movzwl -0x2(%rbp),%eax
25: 5d pop %rbp
26: c3 retq
0000000000000027 <swap32>:
27: 55 push %rbp
28: 48 89 e5 mov %rsp,%rbp
2b: 89 7d ec mov %edi,-0x14(%rbp)
2e: 8b 45 ec mov -0x14(%rbp),%eax
31: c1 e0 18 shl $0x18,%eax
34: 89 45 fc mov %eax,-0x4(%rbp)
37: 8b 45 ec mov -0x14(%rbp),%eax
3a: 25 00 ff 00 00 and $0xff00,%eax
3f: c1 e0 08 shl $0x8,%eax
42: 09 45 fc or %eax,-0x4(%rbp)
45: 8b 45 ec mov -0x14(%rbp),%eax
48: 25 00 00 ff 00 and $0xff0000,%eax
4d: c1 e8 08 shr $0x8,%eax
50: 09 45 fc or %eax,-0x4(%rbp)
53: 8b 45 ec mov -0x14(%rbp),%eax
56: c1 e8 18 shr $0x18,%eax
59: 09 45 fc or %eax,-0x4(%rbp)
5c: 8b 45 fc mov -0x4(%rbp),%eax
5f: 5d pop %rbp
60: c3 retq
0000000000000061 <main>:
61: 55 push %rbp
62: 48 89 e5 mov %rsp,%rbp
65: 48 83 ec 20 sub $0x20,%rsp
69: 89 7d ec mov %edi,-0x14(%rbp)
6c: 48 89 75 e0 mov %rsi,-0x20(%rbp)
70: 83 7d ec 02 cmpl $0x2,-0x14(%rbp)
74: 74 07 je 7d <main+0x1c>
76: b8 ff ff ff ff mov $0xffffffff,%eax
7b: eb 7f jmp fc <main+0x9b>
7d: 48 8b 45 e0 mov -0x20(%rbp),%rax
81: 48 83 c0 08 add $0x8,%rax
85: 48 8b 00 mov (%rax),%rax
88: 48 8d 55 fc lea -0x4(%rbp),%rdx
8c: be 00 00 00 00 mov $0x0,%esi
91: 48 89 c7 mov %rax,%rdi
94: b8 00 00 00 00 mov $0x0,%eax
99: e8 00 00 00 00 callq 9e <main+0x3d>
9e: 83 f8 ff cmp $0xffffffff,%eax
a1: 75 07 jne aa <main+0x49>
a3: b8 ff ff ff ff mov $0xffffffff,%eax
a8: eb 52 jmp fc <main+0x9b>
aa: 8b 45 fc mov -0x4(%rbp),%eax
ad: c1 e8 10 shr $0x10,%eax
b0: 66 89 45 fa mov %ax,-0x6(%rbp)
b4: 0f b7 45 fa movzwl -0x6(%rbp),%eax
b8: 89 c7 mov %eax,%edi
ba: e8 00 00 00 00 callq bf <main+0x5e>
bf: 0f b7 d0 movzwl %ax,%edx
c2: 0f b7 45 fa movzwl -0x6(%rbp),%eax
c6: 89 c6 mov %eax,%esi
c8: bf 00 00 00 00 mov $0x0,%edi
cd: b8 00 00 00 00 mov $0x0,%eax
d2: e8 00 00 00 00 callq d7 <main+0x76>
d7: 8b 45 fc mov -0x4(%rbp),%eax
da: 89 c7 mov %eax,%edi
dc: e8 00 00 00 00 callq e1 <main+0x80>
e1: 89 c2 mov %eax,%edx
e3: 8b 45 fc mov -0x4(%rbp),%eax
e6: 89 c6 mov %eax,%esi
e8: bf 00 00 00 00 mov $0x0,%edi
ed: b8 00 00 00 00 mov $0x0,%eax
f2: e8 00 00 00 00 callq f7 <main+0x96>
f7: b8 00 00 00 00 mov $0x0,%eax
fc: c9 leaveq
fd: c3 retq
アセンブラ(-O2;最適化あり)
最適化オプションを-O2にして再度コンパイルしてアセンブラを出力します。
swap16 / swap32がコンパクトになりました。
0000000000000000 <swap16>:
0: 89 f8 mov %edi,%eax
2: 66 c1 c0 08 rol $0x8,%ax
6: c3 retq
7: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
e: 00 00
0000000000000010 <swap32>:
10: 89 f8 mov %edi,%eax
12: 0f c8 bswap %eax
14: c3 retq
0000000000000000 <main>:
0: 83 ff 02 cmp $0x2,%edi
3: 75 64 jne 69 <main+0x69>
5: 48 83 ec 18 sub $0x18,%rsp
9: 48 8b 7e 08 mov 0x8(%rsi),%rdi
d: 31 c0 xor %eax,%eax
f: 48 8d 54 24 0c lea 0xc(%rsp),%rdx
14: be 00 00 00 00 mov $0x0,%esi
19: e8 00 00 00 00 callq 1e <main+0x1e>
1e: 83 f8 ff cmp $0xffffffff,%eax
21: 74 4a je 6d <main+0x6d>
23: 0f b7 54 24 0e movzwl 0xe(%rsp),%edx
28: be 00 00 00 00 mov $0x0,%esi
2d: bf 01 00 00 00 mov $0x1,%edi
32: 89 d0 mov %edx,%eax
34: 89 d1 mov %edx,%ecx
36: c1 e0 08 shl $0x8,%eax
39: 66 c1 e9 08 shr $0x8,%cx
3d: 09 c1 or %eax,%ecx
3f: 31 c0 xor %eax,%eax
41: 0f b7 c9 movzwl %cx,%ecx
44: e8 00 00 00 00 callq 49 <main+0x49>
49: 8b 54 24 0c mov 0xc(%rsp),%edx
4d: be 00 00 00 00 mov $0x0,%esi
52: bf 01 00 00 00 mov $0x1,%edi
57: 31 c0 xor %eax,%eax
59: 89 d1 mov %edx,%ecx
5b: 0f c9 bswap %ecx
5d: e8 00 00 00 00 callq 62 <main+0x62>
62: 31 c0 xor %eax,%eax
64: 48 83 c4 18 add $0x18,%rsp
68: c3 retq
69: 83 c8 ff or $0xffffffff,%eax
6c: c3 retq
6d: 83 c8 ff or $0xffffffff,%eax
70: eb f2 jmp 64 <main+0x64>
rol
swap16ではrol命令が使われています。
0000000000000000 <swap16>:
0: 89 f8 mov %edi,%eax
2: 66 c1 c0 08 rol $0x8,%ax
6: c3 retq
7: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
e: 00 00
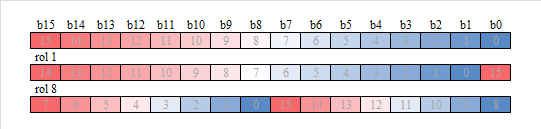
rolは左方向にビットローテションする命令です。
8ビットローテションすることで2 Byte Swappingを実現しています。
図で示します。
rol 1すると全体に1ビット左にずれて、左端のb15が右端に移動します。
rol 8すると全体が8ビット左にずれて、左側の8ビットが右側にきます。
2 byte swappingできます。
bswap
swap32ではbswap命令が使われています。
0000000000000010 <swap32>:
10: 89 f8 mov %edi,%eax
12: 0f c8 bswap %eax
14: c3 retq
bswapはレジスタの値をByte Swappingする命令です。
なお、movbeという命令もあり、こちらは
メモリからレジスタにデータを読み込んだり、
レジスタからメモリにデータを書き出したり
するときにByte swappingできます。