Go言語でSA-IS(Suffix Array - Induced Sorting)を実装しました。SA-ISは接尾辞配列(Suffix Array)の構築アルゴリズムです。本記事の内容は次の3本になります。
- Go言語で実装したSA-IS(go-sais)について紹介します
- SA-ISのアルゴリズムについて解説します
- Go言語の入門書を執筆しました
Go言語のSA-IS実装
Go言語の標準パッケージには、既に接尾辞配列の実装(index/suffixarray)が存在します。標準パッケージのソースコードを見たところLarsson-Sadakane法(qsufsort)であったため、より高速と言われているSA-ISを実装しました。
実装内容
SA-ISは接尾辞配列の構築部分のアルゴリズムです。そのため、構築部分の実装のみ標準パッケージから置き換えています。接尾辞配列を使用した検索部分やテストなどは標準パッケージのソースコードからコピーしました。
ベンチマーク
下記コマンドでgo-saisと標準パッケージのベンチマークを取得しました。
$ go test -bench . github.com/tobi-c/go-sais/suffixarray
$ go test -bench . index/suffixarray
取得結果は下記の表のとおりです。
| NewIndexRandom | NewIndexRepeat | SaveRestore | |
|---|---|---|---|
| go-sais/suffixarray | 778500400 ns/op | 162400650 ns/op | 45003666 ns/op |
| index/suffixarray (標準パッケージ) |
1448997500 ns/op | 2484993800 ns/op | 45519330 ns/op |
NewIndexRandamはランダムの文字列に対して接尾辞配列を構築しています。
go-saisは、標準パッケージと比べて約半分(53%)の時間で実行できました。
NewIndexRepeatは繰り返しが続く文字列に対して接尾辞配列を構築しています。
go-saisは、標準パッケージと比べて約1/17(5.8%)の時間で実行できました。
SaveRestoreは、接尾辞配列の書込みと読込みの処理です。
その部分の実装に差がないため、ほぼ同等な実行時間です。
ベンチマークで使用する文字列がランダムのため、大雑把な指標ですがそれなりに高速化されました。特に繰り返しが続く文字列では、標準パッケージの実装に比べて大幅に時間が短縮できました。(繰り返しが続く文字列はSA-ISにとって都合のよいデータのようです)
SA-ISのアルゴリズム
ここからはSA-ISのアルゴリズムの解説です。まずは接尾辞配列などの各種定義について記載し、その後にアルゴリズムの手順について説明します。
もし厳密な話を知りたい場合は下記論文をご参照ください。C言語の実装も載っています。
(pdf)Two Efficient Algorithms for Linear Suffix Array Construction. Ge Nong, Sen Zhang and Wai Hong Chan
接尾辞配列などの定義
接尾辞、接尾辞配列の定義やSA-ISで使用するType分け、LSM部分文字列、LMS-Prefixについて説明します
接尾辞
接尾辞(Suffix)とは、対象文字列の各位置を開始位置として、その開始位置から末尾までの部分文字列のことです。ここではsuf(文字列, 開始位置)と記述します。
たとえば文字列"base"の接尾辞は次の4つです。
suf("base", 0) = "base"
suf("base", 1) = "ase"
suf("base", 2) = "se"
suf("base", 3) = "e"
このように接尾辞の数は、対象となる文字列の文字数だけ存在します(上記の例だと文字列の長さが4のため、接尾辞も4つ)。
接尾辞配列
接尾辞配列(Suffix Array)とは、対象文字列の接尾辞を文字列順でソートし、その開始位置を格納した配列です。先ほどの文字列"base"の接尾辞配列は次のようになります。
| 接尾辞 | 接尾辞配列 |
|---|---|
| suf("base", 1) = "ase" | 1 |
| suf("base", 0) = "base" | 0 |
| suf("base", 3) = "e" | 3 |
| suf("base", 2) = "se" | 2 |
この例の場合、いずれも先頭文字が異なるため、その先頭文字のみでソートできます。"ase"が接尾辞配列の最初の要素になり、その後に"base", "e", "se"と続きます。接尾辞配列自体に格納するのは接尾辞の文字列そのものではなく、元の文字列("base")の開始位置です。そのため、今回の例では["ase", "base", "e", "se"]ではなく、[1, 0, 3, 2]といった配列が接尾辞配列になります。
SA-ISはこの接尾辞配列を構築するアルゴリズムです。
番兵($)
番兵とは、文字列の最後を表す文字のことです。たとえばC言語のヌル文字(\0)などがあります。接尾辞配列では、この番兵を接尾辞の順序を一意にするために他のどんな文字よりも小さい文字として扱います。またここでは番兵を'$'で記述します。
たとえば文字列"aa"の接尾辞配列を考えると、suf("aa", 0) = "aa"とsuf("aa", 1) = "a"のどちらが小さいかを決めなければなりません。このとき文字列の最後は必ず'$'として"aa$"にすれば、suf("aa$", 0) = "aa$"、suf("aa$", 1) = "a$" となり、2文字目の「'a' > '$'」から「"aa$" > "a$"」と判断できます。
接尾辞のType (S-Type, L-Type, LMS-Type)
SA-ISでは、対象文字列の各文字に対して、S-TypeとL-Typeといった2つのTypeに区分けします。各文字のTypeは次のとおりです。
文字列Sに対して
* 番兵($)はS-Type
* S[i] < S[i+1]の場合 : S[i]はS-Type
* S[i] > S[i+1]の場合 : S[i]はL-Type
* S[i] = S[i+1]の場合 : S[i]はS[i+1]と同じType
(S[i+1]がS-Typeならば、S[i]はS-Type,
S[i+1]がL-Typeならば、S[i]はL-Type)
(S[i]は文字列Sのi番目の文字を表す)
また「S[i-1]がL-Type、かつ、S[i]がS-Type」の場合、S[i]のことをLMS-Type(Leftmost S-Type)と呼びます。
例として文字列S="aababcabddabcab$"のType分けを示します。
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | a | a | b | a | b | c | a | b | d | d | a | b | c | a | b | $ |
| type | S | S | L | S | S | L | S | S | L | L | S | S | L | S | L | S |
| LMS | * | * | * | * | * |
線グラフにすると、S-Typeが右上がり、L-Typeが右下がり、LMS-TypeがV字の部分に該当します。
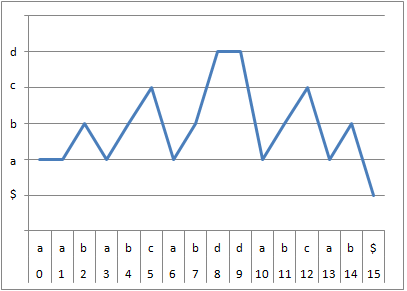
このTypeは、接尾辞のsuf(S, i)とsuf(S, i+1)の比較に使用できます。S[i]がS-Typeならば「suf(S, i) < suf(S, i+1)」、S[i]がL-Typeならば「suf(S, i) > suf(S, i+1)」です。たとえば上記の例のS[8]はL-Typeであるため、「suf(S, 8) > suf(S, 9)」になります。「suf(S, 8) = "ddabcab\$"」 と「suf(S, 9) = "dabcab\$"」を確認してみると「"ddabcab\$" > "dabcab$"」であり、Type分けが示した結果通りです。
S-Typeから開始する接尾辞のことを「S-Typeの接尾辞」と呼ぶことにします。同様にL-Type、LMS-Typeから開始する接尾辞のことを「L-Typeの接尾辞」「LMS-Typeの接尾辞」とします。
LMS部分文字列
LMS部分文字列とは、LMS-Typeの位置で切り出した部分文字列のことです。また最後の"$"もLMS部分文字列になります。たとえば先程の例の文字列S="aababcabddabcab$"のLMS部分文字列は、"abca", "abdda", "abca","ab$","$"の5つです。表で書くと次のようになります。
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | a | a | b | a | b | c | a | b | d | d | a | b | c | a | b | $ |
| type | S | S | L | S | S | L | S | S | L | L | S | S | L | S | L | S |
| LMS | * | * | * | * | * | |||||||||||
| "abca" | a | b | c | a | ||||||||||||
| "abdda" | a | b | d | d | a | |||||||||||
| "abca" | a | b | c | a | ||||||||||||
| "ab$" | a | b | $ | |||||||||||||
| "$" | $ |
LMS-Prefix
LMS-Prefixとは、接尾辞をLMS-Typeの位置で切り取った部分文字列のことです。
先頭文字がLMS-Typeの場合、次のLMS-Typeまでが対象です。また"$"もLMS-Prefixになります。
ここではsuf(S, i)のLMS-Prefixをpre(S, i)と記述します。
たとえば接尾辞suf(S, 6) = "abddabcab$"のLMS-Prefixは、S[10]の'a'がLMS-Typeであるため、pre(S, 6) = "abdda"になります。LMS-Prefixの一覧は次のとおりです。
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S[i] | a | a | b | a | b | c | a | b | d | d | a | b | c | a | b | $ |
| type | S | S | L | S | S | L | S | S | L | L | S | S | L | S | L | S |
| LMS | * | * | * | * | * | |||||||||||
| pre(S,0) | a | a | b | a | ||||||||||||
| pre(S,1) | a | b | a | |||||||||||||
| pre(S,2) | b | a | ||||||||||||||
| pre(S,3) | a | b | c | a | ||||||||||||
| pre(S,4) | b | c | a | |||||||||||||
| pre(S,5) | c | a | ||||||||||||||
| pre(S,6) | a | b | d | d | a | |||||||||||
| pre(S,7) | b | d | d | a | ||||||||||||
| pre(S,8) | d | d | a | |||||||||||||
| pre(S,9) | d | a | ||||||||||||||
| pre(S,10) | a | b | c | a | ||||||||||||
| pre(S,11) | b | c | a | |||||||||||||
| pre(S,12) | c | a | ||||||||||||||
| pre(S,13) | a | b | $ | |||||||||||||
| pre(S,14) | b | $ | ||||||||||||||
| pre(S,15) | $ |
先頭文字がLMS-TypeであるLMS-Prefixは、LMS部分文字列と一致します。この表では、pre(S, 3) = "abca", pre(S, 6) = "abdda", pre(S, 10) = "abca", pre(S, 13) = "ab$", pre(S, 15) = "$"が該当します。SA-ISではLMS部分文字列を文字列順でソートしますが、そのときLMS-PrefixをソートすることでLMS部分文字列のソートを実現します。
アルゴリズムの説明
SA-ISは接尾辞配列を構築するアルゴリズムです。次の手順で構築します。
- LMS部分文字列のソート
- LMS-Typeの接尾辞のソート
- S-Type、L-Typeの接尾辞のソート
このうち、「1. LMS部分文字列のソート」と「3. S-Type、L-Typeの接尾辞のソート」は同じような操作で実現しています。「3. 接尾辞のソート」のほうが比較的簡単であるため、そちらから説明していきます。
また、それぞれの変数は下記の意味になります。
S : 入力となる文字列。例ではS="aababcabddabcab$"を使用。
SA : 結果(接尾辞配列)を格納する配列。構築途中の値を格納するためにも使用。例では長さ16の配列。
3. S-Type、L-Typeの接尾辞のソート
この処理では前提として、LMS-Typeのみの接尾辞配列が構築済みとします(「2. LMS-Typeの接尾辞のソート」から)。「3. S-Type、L-Typeの接尾辞のソート」は、次の3つの処理で実施します。
- 3.1. LMS-Typeの配置
- 3.2. L-Typeのソート
- 3.3. S-Typeのソート
これらの処理は、いわゆるバケットソートを軸にして実行します。
3.1. LMS-Typeの配置
LMS-Typeの接尾辞配列は構築済みのため、その要素(LMS-Typeの接尾辞の開始位置)を配列SAに設定します。このとき、SAの設定は次のように行います。
- ソート済みのLMS-Typeの順序は崩さない
- SAの設定箇所は、先頭文字ごとのに区分けした範囲。同じ先頭文字を場合は右詰めで設定
上記のように設定するため、まず先頭文字ごとのバケットを作成します。パケットに格納する値は、文字の出現回数をカウントし、それぞれの文字でSAを区分けした右端の位置です。バケット設定のコードは次のとおりです(コードはGo言語に似た疑似コードです)
// bucketはSAの要素の最大値を格納できる配列
// (bucketの要素の初期値は全て0とする)
// SAに出現する文字のカウント
for i := 0; i < len(SA); i++ {
bucket[S[i]]++
}
// 先頭文字の格納位置を決める(右詰め用)
sum := -1
for i := 0; i < len(bucket); i++ {
sum += bucket[i]
bucket[i] += sum
}
次にこのバケットを使用して、LMS-Typeの接尾辞配列を末尾から先頭まで順に処理します。LMS-Typeの文字でバケットの値を取得し、その位置にLMS-Typeの「接尾辞の開始位置(接尾辞配列の要素)」を設定します。SAに設定後、バケットの値を-1して設定位置を1つ手前に移動します。
// LMSSAは「LMS-Typeの接尾辞配列」
for k := len(LMSSA) - 1; k >= 0; k-- {
i := LMSSA[k]
ch := S[i] // LMS-Typeの先頭文字を取得
SA[bucket[ch]] = i // LMS-Typeの「接尾辞の開始位置」を設定
bucket[ch]-- // バケットを-1
}
例
文字列S="aababcabddabcab$"のLMS-Typeの開始位置は、3, 6, 10, 13, 15でした。それぞれの接尾辞でソートすると次の順序になります。
suf(S, 15) = "$" suf(S, 13) = "ab$" suf(S, 10) = "abcab$" suf(S, 3) = "abcabddabcab$" suf(S, 6) = "abddabcab$"前提としてこの順序を持つ配列LMSSA=[15,13,10,3,6]は構築済みとします。
次にバケットを作成します。
$ a b c d 文字のカウント 1 6 5 2 2 バケットの値 0 6 11 13 15 各文字の区分け 0 1~6 7~11 12~13 14~15 バケットの値は、文字のカウントを先頭から順に累積した値から-1したものです。
たとえば'b'のバケットの値「11」は、'$','a','b'の文字のカウントの累計-1(1 + 6 + 5 - 1)です。
バケットの値から、各文字の区分けが判断できます。
このバケットと配列LSMSAを使用して、次のようにSAを設定します。
i 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 先頭文字の範囲 $ a b c d SA[i] 15 13 10 3 6 先頭文字ごとの範囲に配列LMSSAの値を設定します。
SAには未設定の箇所(空欄部分)がありますが、LMSSAの順序を崩していない状態です。
3.2. L-Typeのソート
3.1で設定したLMS-Typeの位置を利用して、すべてのL-Typeの「接尾辞の開始位置」を配列SAに設定します。手順としては、まずLMS-Typeの時と同様に先頭文字ごとのバケットを作成します。バケットは基本的に3.1のときと同じですが左詰め用です。
// bucketはSAの要素の最大値を格納できる配列
// (bucketの要素の初期値は全て0とする)
// SAに出現する文字のカウント
for i := 0; i < len(SA); i++ {
bucket[S[i]]++
}
// 先頭文字の格納位置を決める(左詰め用)
sum := 0
for i := 0; i < len(bucket); i++ {
b := bucket[i]
bucket[i] += sum
sum += b
}
次にこのバケットとLMS-Typeを設定した配列SAを使用して、L-Typeを設定します。SAを先頭から末尾まで順に処理し、SA[i]-1がL-Typeならば、SA[i]-1をSAに設定します。このときSAに設定する位置は、バケットを使用してその先頭文字の範囲に左詰めします。
for i := 0; i < len(SA); i++ {
if 「SA[i]に値がある」かつ「SA[i]-1がL-Type」 {
ltypeIndex := SA[i]-1
ch := S[ltypeIndex] // 接尾辞の先頭文字を取得
SA[bucket[ch]] = ltypeIndex // L-Typeの「接尾辞の開始位置」を設定
bucket[ch]++ // バケットを+1
}
}
この手順ですべてのL-Typeが接尾辞の文字列順でSAに設定されます。すべてのL-Typeを網羅できるのは、次のような理由です。
- SA[i]がLMS-Typeならば、その定義からSA[i]-1はL-Type
- SA[i]がL-TypeかつSA[i]-1がS-Typeならば、次にL-Typeが出現するのはLMS-Typeの手前
- SA[i]-1がL-Typeならば、suf(S, SA[i]-1) > suf(S, SA[i])
また左詰めで文字列順にソートできる理由は、上記に加えて次のような接尾辞の性質のためです。
- suf(S, SA[i]-1)とsuf(S, SA[j]-1)が同じ先頭文字ならば、その順序はsuf(S, SA[i])とsuf(S, SA[j])の順序で決まる
これによって手前に出現した値を左詰めで設定すれば、接尾辞配列の順序どおりになります。
例
左詰め用のバケットを用意します。
$ a b c d 文字のカウント 1 6 5 2 2 バケットの値 0 1 7 12 14 各文字の区分け 0 1~6 7~11 12~13 14~15 バケットの値は、文字のカウントを先頭から順に累積した値です。ただし自身のカウントは除きます。
たとえば'b'のバケットの値「7」は、'$','a'の文字のカウントの累積した数(1 + 6)です。次にL-Typeの設定をSAの先頭から順に処理します。
「SA[0] = 15」の処理は「SA[0]-1 = 14」の設定です。設定は次の手順で行います。
- S[14]='b'のため、bのバケットを参照して7を取得
- SA[7]に14を設定(下記表の青文字の部分)
- bのバケットを+1
この処理をSAの末尾まで順に処理します。設定の流れは次の表のようになります。
i 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 先頭文字の範囲 $ a b c d SA[i]:初期状態 15 13 10 3 6 SA[0] = 15の処理 15 13 10 3 6 14 SA[3] = 12の処理 15 13 10 3 6 14 12 SA[4] = 10の処理 15 13 10 3 6 14 12 9 SA[5] = 3の処理 15 13 10 3 6 14 2 12 9 SA[6] = 6の処理 15 13 10 3 6 14 2 12 5 9 SA[7] = 14, SA[8] = 2, SA[12] = 12, SA[13] = 5は、SA[i]-1がS-Typeのためスキップ SA[14] = 9の処理 15 13 10 3 6 14 2 12 5 9 8 この処理ですべてのL-Typeの接尾辞を文字列順に設定できました。
3.3. S-Typeのソート
今度は「3.2. L-Typeのソート」で設定したL-Typeを利用して、すべてのS-Typeの「接尾辞の開始位置」を配列SAに設定します(ただし番兵($)は除く)。「3.1. LMS-Typeの配置」でSA内に設定したLMS-Typeの開始位置はこの処理で上書きされます。手順としては次のとおりです。
- 先頭文字ごとのバケットを作成(右詰め用。3.1.と同じ)
- SAを末尾から先頭まで順に処理し、SA[i]-1がS-TypeならばSAに設定(3.2の類似処理)
S-TypeをSAに設定する処理は次のとおりです。
for i := len(SA)-1; 0 <= i; i-- {
if 「SA[i]に値がある」かつ「SA[i]-1がS-Type」 {
stypeIndex := SA[i]-1
ch := S[stypeIndex] // 接尾辞の先頭文字を取得
SA[bucket[ch]] = stypeIndex // S-Typeの「接尾辞の開始位置」を設定
bucket[ch]-- // バケットを-1
}
}
この手順ですべてのS-Typeが接尾辞の文字列順でSAに設定され、接尾辞配列が完成します。
例
用意するバケットは3.1.と同じです。S-Typeを設定する処理は、SAの末尾から処理します。
「SA[15] = 8」での処理は「SA[15]-1 = 7」の設定です。設定は次の手順で行います。
- S[7] = 'b'であるため、bのバケットを参照して11を取得
- SA[11]に7を設定(下記表の青文字の部分)
- bのバケットを-1
この処理をSAの先頭まで順に処理します。設定の流れは次の表のようになります。
i 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 先頭文字 の 範囲 $ a b c d SA[i]:初期状態 15 13 10 3 6 14 2 12 5 9 8 SA[15] = 8の処理 15 13 10 3 6 14 2 7 12 5 9 8 SA[14] = 9は、9-1 = 8がL-Typeのためスキップ SA[11] = 5の処理 15 13 10 3 6 14 2 4 7 12 5 9 8 SA[10] = 12の処理 15 13 10 3 6 14 2 11 4 7 12 5 9 8 SA[11] = 7の処理 15 13 10 3 6 14 2 11 4 7 12 5 9 8 SA[10] = 4の処理 15 13 10 3 6 14 2 11 4 7 12 5 9 8 SA[9] = 11の処理 15 13 10 3 6 14 2 11 4 7 12 5 9 8 SA[8] = 2の処理 15 1 10 3 6 14 2 11 4 7 12 5 9 8 SA[7] = 14の処理 15 13 1 10 3 6 14 2 11 4 7 12 5 9 8 SA[6] = 6, SA[5] = 3, SA[4] = 10は、SA[i]-1がL-Typeのためスキップ SA[3] = 1の処理 15 0 13 1 10 3 6 14 2 11 4 7 12 5 9 8 SA[2] = 3, SA[0] = 15は、SA[i]-1がL-Typeのためスキップ。SA[1] = 0はSA[i]-1がマイナスのためスキップ このS-Typeのソートが終わると、SAは文字列Sの接尾辞配列になります。
1. LMS部分文字列のソート
「3. S-Type、L-Typeの接尾辞のソート」の処理では、LMS-Typeの接尾辞配列が必要でした。「1. LMS部分文字列のソート」と「2. LMS-Typeの接尾辞のソート」は、このLMS-Typeの接尾辞配列を作成するまでの処理になります。
「1. LMS部分文字列のソート」の手順は次のとおりです。
- 1.1. LMS-Typeのソート(先頭文字のみ)
- 1.2. L-Typeのソート
- 1.3. S-Typeのソート
- 1.4. LMS-Prefixの配列からLMS部分文字列の抽出
1.1~1.3の処理でLMS-Prefixのソートを行い、1.4でLMS-Prefixの配列からLMS部分文字列の抽出を行います。
また1.1~1.3の処理は、3.1~3.3の処理とほとんど同じ処理になっています。
1.1. LMS-Typeのソート(先頭文字のみ)
この処理は、「3.1. LMS-Typeの配置」の類似処理です。しかし、ソート済みのLMS-Typeがまだ存在しないため、バケットを使用して先頭文字のみでソートします。2文字目以降の順番はここでは決められません。手順としては次のとおりです。
- 先頭文字ごとのバケットを設定(右詰め用。3.1.と同じ)
- 文字Sを先頭から末尾まで順に処理し、LMS-Typeの文字位置を配列SAに格納
LMS-Typeの設定は、文字列Sに対して末尾から先頭まで順に処理します。
for i := len(S)-1; 0 <= i; i-- {
if 「S[i]がLMS-Type」 {
ch := S[i] // 接尾辞の先頭文字を取得
SA[bucket[ch]] = i // LMS-Typeの「文字位置(接尾辞の開始位置)」を設定
bucket[ch]-- // バケットを-1
}
}
例
用意するバケットは3.1.と同じです。
LMS-Typeの設定処理は次のとおりです。
i 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 先頭文字の範囲 $ a b c d SA[i] 15 3 6 10 13 3.1の結果と比べると、先頭文字aの範囲内で順番が入れ替わっています。
1.2. L-Typeのソート
処理自体は「3.2. L-Typeのソート」と同じです。しかし、1.1.でLMS-Typeが正しくソートされていないため、接尾辞配列としては正しい順番になりません。
例
処理は3.2と全て同じであるため省略します。結果は次のとおりです。
i 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 先頭文字の範囲 $ a b c d SA[i] 15 3 6 10 13 14 2 5 12 9 8 3.2の結果と比べるとSA[12]=5とSA[13]=12の部分が入れ替わっています。
これは1.1で2文字目の順序を決められなかったためです。
1.3. S-Typeのソート
この処理も手順自体は「3.3. S-Typeのソート」と同じです。
例
処理は3.3と全て同じであるため省略します。結果は次のとおりです。
i 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 先頭文字の範囲 $ a b c d SA[i] 15 0 13 1 3 10 6 14 2 4 11 7 5 12 9 8 pre(S, SA[i])
(LMS-Prefix)$ aaba ab$ aba abca abca abdda b$ ba bca bca cdda ca ca da dda 3.3の結果と比べるとSA[9]=4とSA[10]=11、SA[4]=3とSA[5]=10が入れ替わっています。
このように接尾辞の文字列順では、一部がソートできていない状態です。
しかし、一方でLMS-Prefixの文字列順ではソートした状態になっています。
1.4. LMS-Prefixの配列からLMS部分文字列の抽出
LMS部分文字列以外の値は不要です。LMS部分文字列は、LMS-Typeから開始するLMS-Prefixと一致するため、その値のみ残します。
例
LMS-Typeの開始位置は3, 6, 10, 13, 15であるため、その部分のみが残すようにします。
SA[i]
(LMS部分文字列の開始位置)15 13 3 10 6 pre(S, SA[i])
(LMS-Prefix)$ ab$ abca abca abdda この抽出によって、ソートしたLMS部分文字列の配列が作成できました。
2. LMS-Typeの接尾辞のソート
ここでは、ソート済みのLMS部分文字列を使用して、LMS-Typeのみの接尾辞配列を構築します。実施手順は下記の2つです。
- 2.1. LMS部分文字列に順序番号付与と重複チェック
- 2.2. 順序番号の接尾辞配列を求める(再帰呼び出し)
このうち、2.1の重複チェックですべてのLMS部分文字列が重複しないならば、LMS部分文字列の開始位置とLMS-Typeの接尾辞配列が一致するため、2.2の処理は不要となります。
2.1 LMS部分文字列に順序番号付与と重複チェック
順序番号(name)とは、LMS部分文字列の文字列順に採番した値です。ただし、LMS部分文字列が同じ値の場合は同じ番号とします。採番した順序番号は、LMS部分文字列の開始位置順になるように格納します。
// LMSSubstringsは、LMS部分文字列の開始位置を格納した配列
// Namesは順序番号を格納する配列
name := 0
Names[LMSSubstring[0]/2] = name
for i := 1; i < len(LMSSubstrings); i++ {
if LMSSubstrings[i-1]と LMSSubstrings[i] のLMS部分文字列が不一致 {
name++
}
// LMS部分文字列の開始位置順に順序番号を格納
Names[LMSSubstrings[i]/2] = name
}
// Namesの未設定部分は取り除く
このとき、順序番号を格納する配列(Names)の長さは、元の文字列の1/2で足ります(長さが最大になる場合は、L-TypeとS-Typeが交互に出現する文字列のため)。元の文字列より長さが小さくなるため、2.2で再帰呼び出しを行ってもいずれ停止します。
例
まずソート済みのLMS部分文字列に対して順序番号を採番します。
LMS部分文字列の開始位置 15 13 3 10 6 LMS部分文字列 $ ab$ abca abca abdda 順序番号 0 1 2 2 3 "abca"は同じ文字列で2回登場しているため、同じ順序番号が割り当たります。もしすべてて異なる順序番号が割り当たれば「3. S-Type、L-Typeの接尾辞のソート」に進みます。
次に順序番号をLMS部分文字列の開始位置順に並び替えます。
LMS部分文字列の開始位置 3 6 10 13 15 LMS部分文字列 abca abdda abca ab$ $ 順序番号 2 3 2 1 0 この処理によって順序番号の配列[2, 3, 2, 1, 0]が取得できます。順序番号の配列[2, 3, 2, 1, 0]の接尾辞は、次のようにLMS-Typeの接尾辞と対応しています。
No 順序番号の配列の接尾辞 LMS-Typeの接尾辞 LMS-Typeの接尾辞の開始位置 0 [2,3,2,1,0] abcabddabcab$ 3 1 [3,2,1,0] abddabcab$ 6 2 [2,1,0] abcab$ 10 3 [1,0] ab$ 13 4 [0] $ 15
2.2. 順序番号の接尾辞配列を取得(再帰呼び出し)
順序番号の配列(Names)の接尾辞配列は、LMS-Typeの接尾辞配列の順序と一致します。LMS-Typeの接尾辞配列は、SAIS全体の再帰呼び出しによって取得します。
例
順序番号の配列[2, 3, 2, 1, 0]の接尾辞配列は[4, 3, 2, 0, 1]です。対応するLMS-Typeの接尾辞は次のとおりです。
No 順序番号の配列の接尾辞 LMS-Typeの接尾辞 LMS-Typeの接尾辞の開始位置 4 [0] $ 15 3 [1,0] ab$ 13 2 [2,1,0] abcab$ 10 0 [2,3,2,1,0] abcabddabcab$ 3 1 [3,2,1,0] abddabcab$ 6 対応するLMS-Typeの接尾辞が文字列順にソートされます。この表の「LMS-Typeの接尾辞の開始位置」がLMS-Typeの接尾辞配列(「3. S-Type、L-Typeの接尾辞のソート」の配列LMSSA)になります。
まとめ
接尾辞配列を構築するSA-ISの手順について説明しました。「1. LMS部分文字列のソート」と「3. S-Type、L-Typeの接尾辞のソート」では、結果を格納するSAの領域を使用して省メモリ化している様子が見えたと思います。SA-ISは日本語の説明も多いため、こちらの内容ではいまいちだった方は参考URLをご参照ください。
参考URL
- sais(https://sites.google.com/site/yuta256/sais)
- 接尾辞配列構築アルゴリズムの Java 7 による実装
- SA-IS - Shogo Computing Laboratory
- SAIS(Suffix Array - Induced Sorting) - EchizenBlog-Zwei
- SA-IS: SuffixArray線形構築 - sileのブログ
- ビームの報告書: Suffix Array を作る - SA-IS の実装
- SA-IS - (iwi) { 反省します - TopCoder部
- 接尾辞配列(Suffix Array)の効率的な実装手法について - xxxxxeeeeeの日記
- 高速文字列解析の世界
Go言語入門
Go言語入門というタイトルの本を執筆しました。その名の通りGo言語の入門書です。後半はRaspberry Piを使ったLEDを点滅や温度データの収集なども記載しています。go-saisの実装の文法部分は、この入門書の内容で理解できると思います(アルゴリズム自体の理解はまた別に必要ですが。。)