2020/12/26: 前処理に間違いがあったため修正しました。あわせてデータセットの無音部を予め削除しました。val_accが少し改善して91%になりました。
2021/01/01: Convを2次元から1次元に変更し、BN層やDropout層を入れて、val_accが96%になりました。
「Pythonで長い会議を見える化」シリーズ、話者ダイアリゼーションの精度をこれ以上高めるには、デジタル声紋であるx-vectorを導入する必要があります。
x-vectorは、動向の回で学んだように、以下のように教師あり話者識別の最終隠れ層の出力として得られます。
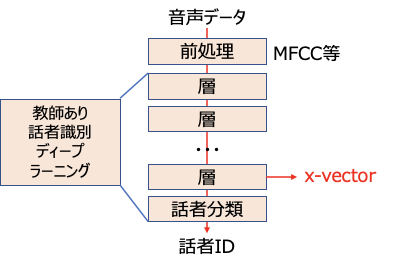
よって、最初の前提として、それなりに高精度な教師ありデーィプラーニングによる話者識別モデルを得る必要があります。そのためには先日学んだPyTorchを使うとよさそうです。
PyTorchは以下の点で今回の目的に合致します。
- torchaudioにて、音声データセット、MFCC等の主要な変換関数が提供されている。
- 教師ありデーィプラーニングによる話者識別モデルは、MFCC等の音声スペクトログラムを画像と見立てて処理するものが多い。その際に画像系のtorchvisionが役立つ。
- 前処理やモデルや学習の表現自由度が高いため、カスタマイズしやすい。
- 最新の本分野の論文の多くはPyTorchを前提に実践されており、成果が利用しやすい。
今回、PyTorchでもサポートされているmozilla.orgのCommonVoice 5.1の日本語データセットを使いました。validatedデータセットには、170人の計6158種の日本語音声クリップが登録されています。このうちランダムで80%抽出したものを学習データ、残りの20%を検証データとします。
なお、データセットの音声クリップは前後に微妙に無音部があるため、予め無音部を削除しました。これは、最終目的である話者ダイアリゼーションにおいては、無音削除したデータでのx-vectorを使う必要があるためです。無音部削除のコードは本記事の最後で紹介しています。
前処理は、以下のようにしています。
- 音声クリップを25ms単位(12.5msホップ)・40次元のMFCCに変換する。
- バッチ学習には時間長をあわせる必要があるため長さを10秒(=12.5ms×800)に揃える。ほとんどの音声クリップは10秒未満であるため、10秒に設定しておくことでデータを十分に学習に活用可能。なお、不足する分は音声クリップを繰り返してパディングする。
- ランダムな時間位置から、ランダムに2〜4秒の長さを切り出す。切り出し時間位置を変えることによるデータ拡張を実現している。また切り出す長さをランダムにしているため、次の拡大縮小とあわせてピッチ変更によるデータ拡張を実現している。
- 拡大縮小して3秒に揃える。MFCC後のデータを使っているため、音の高低成分は変えずに時間軸方向に拡大縮小しており、ピッチ変更によるデータ拡張を実現している。
上記のうち、10秒クリップの部分だけは丁度良いライブラリが無く自作しましたが、他はtorchaudioやtorchvisionで用意されているものを使え、PyTorchでの開発効率が高いことがわかります。
なお、検証データの前処理は、データ拡張の必要が無いため、頭の3秒を切り出すのみにしています。
ディープラーニングモデルは、音声に特化した1次元畳み込み層を4層、全結合層を2層、各層にBatch Normalizationを入れて、要所にDropoutを持つ、比較的単純かつ初歩的なCNNとしています。なお、BNとDropoutの併用は良く無いという記事がいろいろ出ていますが、ケースバイケースなようです。
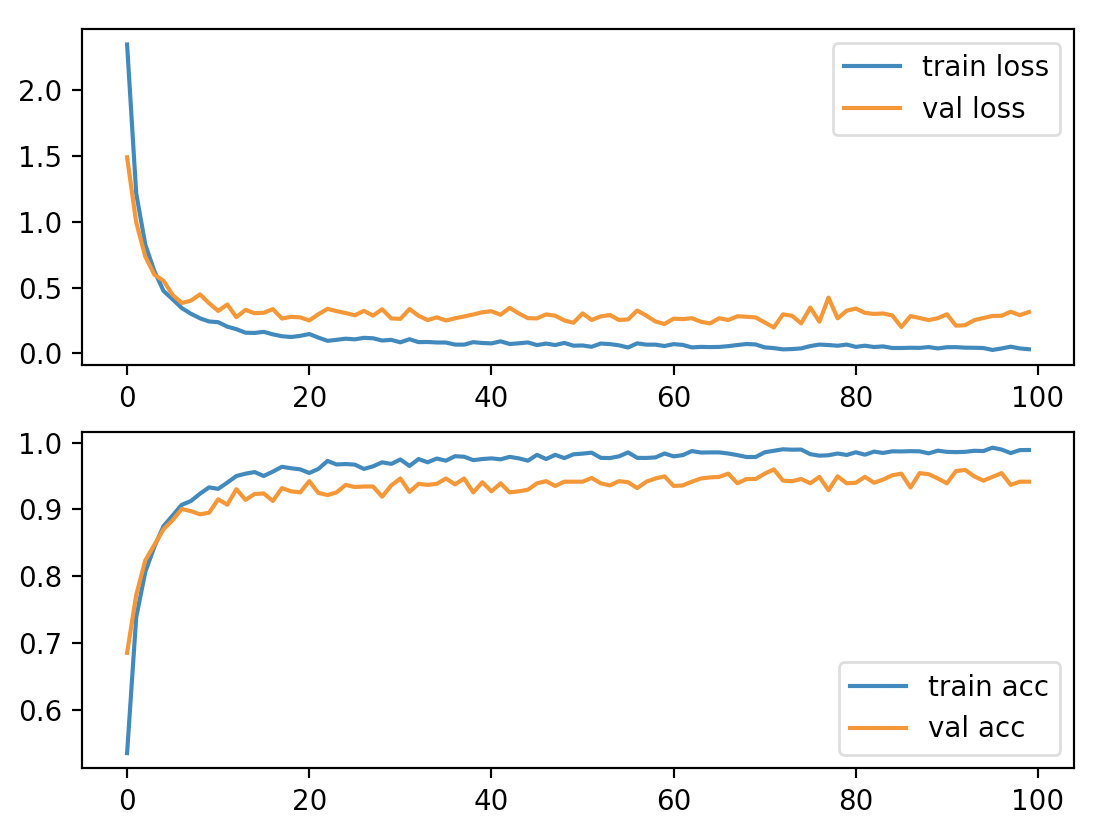
以下が学習結果です。長いので、epoch0〜10と最適値のepoch71の他は、epoch10ごとに表示しています。
epoch:0, loss:2.350, acc:0.535, val_loss:1.492, val_acc:0.685, can_save:False
epoch:1, loss:1.217, acc:0.738, val_loss:0.996, val_acc:0.772, can_save:False
epoch:2, loss:0.827, acc:0.807, val_loss:0.736, val_acc:0.824, can_save:False
epoch:3, loss:0.625, acc:0.844, val_loss:0.599, val_acc:0.847, can_save:False
epoch:4, loss:0.475, acc:0.875, val_loss:0.552, val_acc:0.870, can_save:False
epoch:5, loss:0.412, acc:0.891, val_loss:0.445, val_acc:0.884, can_save:False
epoch:6, loss:0.345, acc:0.907, val_loss:0.384, val_acc:0.901, can_save:True
epoch:7, loss:0.302, acc:0.912, val_loss:0.401, val_acc:0.897, can_save:False
epoch:8, loss:0.267, acc:0.923, val_loss:0.449, val_acc:0.893, can_save:False
epoch:9, loss:0.242, acc:0.933, val_loss:0.382, val_acc:0.895, can_save:False
epoch:10, loss:0.237, acc:0.931, val_loss:0.323, val_acc:0.915, can_save:True
epoch:20, loss:0.147, acc:0.955, val_loss:0.251, val_acc:0.942, can_save:True
epoch:30, loss:0.084, acc:0.975, val_loss:0.262, val_acc:0.946, can_save:False
epoch:40, loss:0.076, acc:0.976, val_loss:0.321, val_acc:0.927, can_save:False
epoch:50, loss:0.060, acc:0.984, val_loss:0.304, val_acc:0.942, can_save:False
epoch:60, loss:0.070, acc:0.979, val_loss:0.264, val_acc:0.935, can_save:False
epoch:70, loss:0.045, acc:0.986, val_loss:0.235, val_acc:0.954, can_save:False
epoch:71, loss:0.040, acc:0.988, val_loss:0.197, val_acc:0.960, can_save:True
epoch:80, loss:0.049, acc:0.986, val_loss:0.341, val_acc:0.940, can_save:False
epoch:90, loss:0.047, acc:0.986, val_loss:0.297, val_acc:0.939, can_save:False
最適値のepoch71でval_loss=0.197, val_acc=0.960となっています。データセットなど条件は異なりますが、Biometric Recognition Using Deep Learning: A SurveyのTable7を見ると、EER 5%くらいが数年前の最高峰のようです。
以下が学習結果のグラフです。
以下がソースコードです。x_vectorである最終隠れ層の出力も取れるように汎用化しています。
import random
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset, random_split
import torchaudio
from torchvision import transforms
torchaudio.set_audio_backend('sox_io')
# CommonVoiceをもとにtransformできるようにしたデータセット
# CommonVoiceはあらかじめダウンロードしておくこと
# https://commonvoice.mozilla.org/ja/datasets
class SpeechDataset(Dataset):
sample_rate = 16000
def __init__(self, train=True, transform=None, split_rate=0.8):
tsv = './CommonVoice/cv-corpus-5.1-2020-06-22/ja/validated.tsv'
# データセットの一意性確認と正解ラベルの列挙
import pandas as pd
df = pd.read_table(tsv)
assert not df.path.duplicated().any()
self.classes = df.client_id.drop_duplicates().tolist()
self.n_classes = len(self.classes)
# データセットの準備
self.transform = transform
data_dirs = tsv.split('/')
dataset = torchaudio.datasets.COMMONVOICE(
'/'.join(data_dirs[:-4]), tsv=data_dirs[-1],
url='japanese', version=data_dirs[-3])
# データセットの分割
n_train = int(len(dataset) * split_rate)
n_val = len(dataset) - n_train
torch.manual_seed(torch.initial_seed()) # 同じsplitを得るために必要
train_dataset, val_dataset = random_split(dataset, [n_train, n_val])
self.dataset = train_dataset if train else val_dataset
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
x, sample_rate, dictionary = self.dataset[idx]
# リサンプリングしておくと以降は共通sample_rateでtransformできる
if sample_rate != self.sample_rate:
x = torchaudio.transforms.Resample(sample_rate)(x)
# 各種変換、MFCC等は外部でtransformとして記述する
# ただし、推論とあわせるためにMFCCは先にすませておく
x = torchaudio.transforms.MFCC(log_mels=True)(x)
# 最終的にxのサイズを揃えること
if self.transform:
x = self.transform(x)
# 特徴量:音声テンソル、正解ラベル:話者IDのインデックス
return x, self.classes.index(dictionary['client_id'])
# 学習モデル
class SpeechNet(nn.Module):
def __init__(self, n_classes):
super().__init__()
self.conv = nn.Sequential(
nn.BatchNorm1d(40),
nn.Conv1d(40, 128, kernel_size=5, padding=2),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2),
nn.Conv1d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2),
nn.Conv1d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2),
nn.Conv1d(128, 64, kernel_size=3, padding=1),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.Dropout(),
)
self.fc = nn.Sequential(
nn.Linear(30*64, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(1024, n_classes),
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 最後の1次元に指定サイズにCropし、長さが足りない時はCircularPadする
# 音声データの時間方向の長さを揃えるために使うtransform部品
class CircularPad1dCrop:
def __init__(self, size):
self.size = size
def __call__(self, x):
n_repeat = self.size // x.size()[-1] + 1
repeat_sizes = ((1,) * (x.dim() - 1)) + (n_repeat,)
out = x.repeat(*repeat_sizes).clone()
return out.narrow(-1, 0, self.size)
def SpeechML(train_dataset=None, val_test_dataset=None, *,
n_classes=None, n_epochs=15,
load_pretrained_state=None, test_last_hidden_layer=False,
show_progress=True, show_chart=False, save_state=False):
'''
前処理、学習、検証、推論を行う
train_dataset: 学習用データセット
val_test_dataset: 検証/テスト用データセット
(検証とテストでデータを変えたい場合は一度学習してステートセーブした後に
テストのみでステート読み出しして再実行すること)
(正解ラベルが無い場合は検証はスキップする)
n_classes: 分類クラス数(Noneならtrain_datasetから求める)
n_epocs: 学習エポック数
load_pretrained_state: 学習済ウエイトを使う場合の.pthファイルのパス
test_last_hidden_layer: テストデータの推論結果に最終隠れ層を使う
show_progress: エポックの学習状況をprintする
show_chart: 結果をグラフ表示する
save_state: test_acc > 0.9 の時のtest_loss最小値更新時のstateを保存
(load_pretrained_stateで使う)
返り値: テストデータの推論結果
'''
# モデルの準備
if not n_classes:
assert train_dataset, 'train_dataset or n_classes must be a valid.'
n_classes = train_dataset.n_classes
model = SpeechNet(n_classes)
if load_pretrained_state:
model.load_state_dict(torch.load(load_pretrained_state))
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# 前処理の定義
Squeeze2dTo1d = lambda x: torch.squeeze(x, -3)
train_transform = transforms.Compose([
CircularPad1dCrop(800),
transforms.RandomCrop((40, random.randint(160, 320))),
transforms.Resize((40, 240)),
Squeeze2dTo1d,
])
test_transform = transforms.Compose([
CircularPad1dCrop(240),
Squeeze2dTo1d
])
# 学習データ・テストデータの準備
batch_size = 32
if train_dataset:
train_dataset.transform = train_transform
train_dataloader = DataLoader(
train_dataset, batch_size=batch_size, shuffle=True)
else:
n_epochs = 0 # 学習データが無けれはエポックはまわせない
if val_test_dataset:
val_test_dataset.transform = test_transform
val_test_dataloader = DataLoader(
val_test_dataset, batch_size=batch_size)
# 学習
losses = []
accs = []
val_losses = []
val_accs = []
for epoch in range(n_epochs):
# 学習ループ
running_loss = 0.0
running_acc = 0.0
for x_train, y_train in train_dataloader:
optimizer.zero_grad()
y_pred = model(x_train)
loss = criterion(y_pred, y_train)
loss.backward()
running_loss += loss.item()
pred = torch.argmax(y_pred, dim=1)
running_acc += torch.mean(pred.eq(y_train).float())
optimizer.step()
running_loss /= len(train_dataloader)
running_acc /= len(train_dataloader)
losses.append(running_loss)
accs.append(running_acc)
# 検証ループ
val_running_loss = 0.0
val_running_acc = 0.0
for val_test in val_test_dataloader:
if not(type(val_test) is list and len(val_test) == 2):
break
x_val, y_val = val_test
y_pred = model(x_val)
val_loss = criterion(y_pred, y_val)
val_running_loss += val_loss.item()
pred = torch.argmax(y_pred, dim=1)
val_running_acc += torch.mean(pred.eq(y_val).float())
val_running_loss /= len(val_test_dataloader)
val_running_acc /= len(val_test_dataloader)
can_save = (val_running_acc > 0.9 and
val_running_loss < min(val_losses))
val_losses.append(val_running_loss)
val_accs.append(val_running_acc)
if show_progress:
print(f'epoch:{epoch}, loss:{running_loss:.3f}, '
f'acc:{running_acc:.3f}, val_loss:{val_running_loss:.3f}, '
f'val_acc:{val_running_acc:.3f}, can_save:{can_save}')
if save_state and can_save: # あらかじめmodelフォルダを作っておくこと
torch.save(model.state_dict(), f'model/0001-epoch{epoch:02}.pth')
# グラフ描画
if n_epochs > 0 and show_chart:
fig, ax = plt.subplots(2)
ax[0].plot(losses, label='train loss')
ax[0].plot(val_losses, label='val loss')
ax[0].legend()
ax[1].plot(accs, label='train acc')
ax[1].plot(val_accs, label='val acc')
ax[1].legend()
plt.show()
# 推論
if not val_test_dataset:
return
if test_last_hidden_layer:
model.fc = model.fc[:-1] # 最後の隠れ層を出力する
y_preds = torch.Tensor()
for val_test in val_test_dataloader:
x_test = val_test[0] if type(val_test) is list else val_test
y_pred = model.eval()(x_test)
if not test_last_hidden_layer:
y_pred = torch.argmax(y_pred, dim=1)
y_preds = torch.cat([y_preds, y_pred])
return y_preds.detach()
# 呼び出しサンプル
if __name__ == '__main__':
train_dataset = SpeechDataset(train=True)
val_dataset = SpeechDataset(train=False)
result = SpeechML(train_dataset, val_dataset, n_epochs=100,
show_chart=True, save_state=True)