Pythonで音声ファイルのスペクトログラム描画をしてみました。とてもよくあるパターンではありますが、モノラル・ステレオ両対応になっているのが特徴です。
後でも述べますが、スペクトログラム描画により、人間が話しているところと、無音もしくは人間の会話周波数と異なるノイズとを、一目瞭然で区別することが可能です。例えば、話者識別の教師データを作る場合など、スペクログラムを見ることで、やりやすくなるでしょう。
なお、音声分析にはlibrosaを使う場合も多いようです。
細かい説明はコードに書かれていますが、以下概要です。
- pysoundfileでwaveファイルを読み込み
- 冒頭5分のみ切り出し(必須ではありませんが処理速度の関係で時間を短くしました)
- 高速フーリエ変換
- 7kHz未満の周波数のみ切り出し(人間の音声は3.4kHz未満がほとんどで、7kHz未満でも高音質)
- 音圧をdBに変換(相対dB)
- 結果を、縦軸が周波数・横軸が経過時間とし、dB値によるカラーマップを、グラフ描画(ステレオだとCHごとにグラフ描画)
以下がコードです。
import numpy as np
import matplotlib.pyplot as plt
import soundfile as sf
from scipy import signal as sg
# 入力はwavファイルであること(mp3等は入力前にツールで変換する)
x, fs = sf.read('sample.wav', always_2d=True)
x = x[:fs*300] # 最初の5分間だけを分析する
# stftのパラメータ
nperseg = 256
noverlap = nperseg // 2
# ウインドウがぴったりと切り分けられるように入力配列の後ろを少し削る
# stftしたデータを逆stftをするときに、この前処理があると、変換逆変換でピッタリと戻る
rest_of_window = (len(x) - nperseg) % (nperseg - noverlap)
if rest_of_window > 0:
x = x[:-rest_of_window]
# soundfileの形式をstftするには転置する
f, t, Zxx = sg.stft(x.T, fs=fs, nperseg=nperseg, noverlap=noverlap)
# 逆stftの式(今回は使わない)
# _, x = sg.istft(Zxx, fs=fs, nperseg=nperseg, noverlap=noverlap)
# x = x.T
# 人間の声を分析するため7kHz以上の高音はカット
f = f[f < 7000]
Zxx = Zxx[:,:len(f)]
# スペクトログラムを描画するために相対デシベルを求める
dB = 20 * np.log10(np.abs(Zxx))
# スペクトログラムの描画
channels = dB.shape[0]
fig, ax = plt.subplots(channels)
if channels == 1:
ax = (ax,) #チャネル1つの時はaxがスカラーなので調整
for i in range(channels):
ax[i].set_title(f'CH{i+1}-Time-Frequency')
ax[i].set_xlabel('Time(s)')
ax[i].set_ylabel('Frequency(Hz)')
ax[i].pcolormesh(t, f, dB[i], shading='auto', cmap='jet')
plt.subplots_adjust(wspace=0.5, hspace=0.5)
plt.show()
出力結果
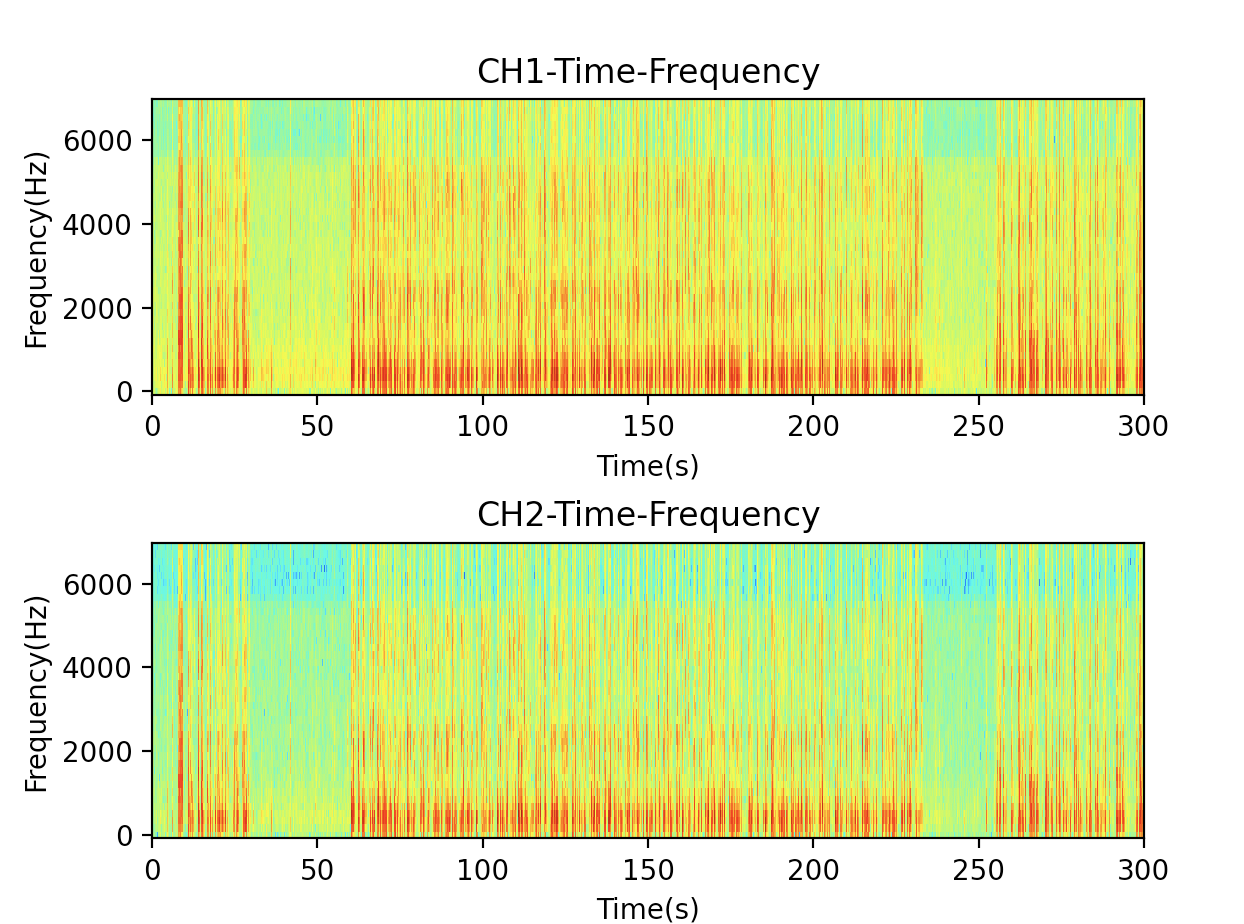
赤っぽいところが人が話をしている箇所、青っぽいところが無音です。会話なのか、会話ではないのかの区別は容易になりそうです。しかし、このグラフを人間が見ただけでは、話者の違いまでを判別するのは難しそうです。左右の短い話をしている人と、真ん中の長い話をしている人は、別人なのですが、その違いは、目で見てもわからないでしょう。