この記事は、第2のドワンゴ Advent Calendar 2015の記事です。
はじめに
「結月ゆかり」について
結月ゆかりというキャラクタをみなさんはご存知でしょうか?
結月ゆかりはボーカロイドやボイスロイドのイメージキャラクターの1人であり、ここ最近人気が急上昇しているキャラクタです。
結月ゆかり実況
結月ゆかり実況とは、「ボイスロイドの結月ゆかりを用いて実況解説をつけた(ゲーム)実況動画」の総称です。
かつてのボーカロイドの時の様に、「結月ゆかり実況だから(知らないゲームの動画でも)見る」という固定ファンがいるくらいには盛り上がっているジャンルだったりします。
ですが、この「結月ゆかり実況」動画、作るのがとても大変です。慣れてない人が動画を作ろうとした場合、動画1本作るのに1週間以上かかってしまう場合もあったりします。(最近はゆっくりMovieMakerのおかげもあって「ゆっくり実況動画」はかなり簡単に動画編集できるようにはなってはいますが、依然「ボイスロイド実況動画」は手間が多く時間がかかってしまいます。)
自動化したい
主に動画編集の何が面倒くさいのかを考えてみたところ、次の3つが原因かなと思いました。
- 音声wavファイル生成し動画のタイミングに合わせて配置する
- セリフに合わせた字幕を動画に配置する
- 立ち絵を出してアニメーションさせる
手間だと思った部分は自動化したくなるのがエンジニアですよね!というわけでこれら3つを自動化し、結月ゆかり実況をサクっと作れるようにしてみました。
本題:結月ゆかりを音声認識で喋らせる
要するに、「ゆかりさんがゲーム動画を実況」していればよいわけなので、自分が喋った音声を音声認識させてゆかりさんに読み上げてもらうことにしました。
リアルタイムにせよ、録画済みの動画にせよ、「自分が動画をみながら場面に合わせて言いたいこと喋れば勝手に音声と字幕とアニメーションが入る」というわけです。
実際にできた動画
ぐだぐだ解説するよりも先に動画を見てもらった方がわかりやすいと思います。こちらの動画を先に御覧ください。
構成
工数をかけずに実現したかったので、出来合いの以下のものを組み合わせてみただけになります。
使ったもの
- RealSenseSDKの音声認識モジュール
- みくみくまうす
- XSplit
構成図
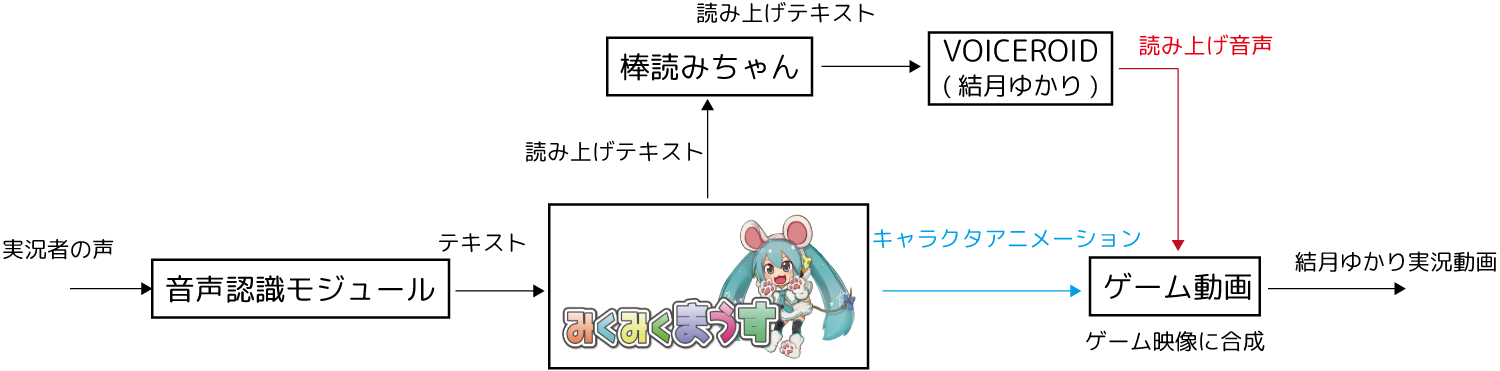
使ったものの紹介
RealSenseSDK
RealSenseはIntelが推進しているNUI(Natural User Interface)を家庭用PCに組み込んでいくプロジェクトであり、RealSenseSDKはその開発SDKとなります。
SDKの機能をフルで使おうとするとRealSense専用カメラが必要になるのですが、今回用いる音声認識モジュールはこのカメラを持ってなくても汎用のマイクさえあれば利用することができます。
みくみくまうす
みくみくまうすは私が作成しているMMD音声読み上げツールです。
MMDモデルを画面に表示して、テキストを読み上げつつアニメーションしてくれるというツールです。
みくみくまうすには「読み上げテキストを解析して自動アニメーション」「読み上げ中のテキストを字幕表示」の機能がついています。そのためみくみくまうすで描画されたゆかりさんをそのまま動画にオーバーレイすれば結月ゆかり実況動画ができあがることになります。
実装について
音声認識モジュールの実装
それでは実際の実装について説明していきます。
まず、音声認識モジュール部ですが、ここの責務は音声をテキストに変換してみくみくまうすに渡すことです。
RealSenseSDKを導入するといくつかサンプルプロジェクトもインストールされます。今回はその中のC#版音声認識サンプル「Speech Recognition(C#)」を使います。Speech Recognition(C#)はWindowsFormsで実装された単純な音声認識サンプルで、「音声認識された文字列を画面に出す」という機能しかありません。これを改造して、音声認識された文字列をみくみくまうすに渡すようにします。
音声認識のテキストを取得する
Speech Recognitionの中身を読むと、VoiceRecognitionというクラスが音声認識を管理しているクラスということがわかります。ここにOnRecognition()という認識結果を受け取ってアレコレするコールバックが生えていたので、ここから音声認識結果のテキストを抜き取ってRxのIObservableを用いてOnRecognationAsObservableとしてVoiceRecognitionの外に通知してあげるようにします。
class VoiceRecognition
{
MainForm form;
PXCMAudioSource source;
PXCMSpeechRecognition sr;
/// <summary>
/// 認識テキスト通知用Subject
/// </summary>
private readonly Subject<string> _onRecognationSubject = new Subject<string>();
/// <summary>
/// 音声認識した結果のテキスト通知
/// </summary>
public IObservable<string> OnRecognationAsObservable => _onRecognationSubject.AsObservable();
void OnRecognition(PXCMSpeechRecognition.RecognitionData data)
{
if (data.scores[0].label < 0)
{
form.PrintConsole(data.scores[0].sentence);
//ここで認識結果のテキストを外に流す
_onRecognationSubject.OnNext(data.scores[0].sentence);
if (data.scores[0].tags.Length > 0)
form.PrintConsole(data.scores[0].tags);
}
else
{
form.ClearScores();
for (int i = 0; i < PXCMSpeechRecognition.NBEST_SIZE; i++)
{
int label = data.scores[i].label;
int confidence = data.scores[i].confidence;
if (label < 0 || confidence == 0) continue;
form.SetScore(label, confidence);
}
if (data.scores[0].tags.Length > 0)
form.PrintConsole(data.scores[0].tags);
}
}
//以下変更無し
音声認識の結果をJsonに変換する
みくみくまうすで読み上げさせる際のデータフォーマットに合わせたJsonを生成する必要があるでの、次のクラスを実装してプロジェクトに追加します。
[DataContract]
class CommentInfo
{
/// <summary>
/// キャラクタのアニメーション
/// </summary>
[DataMember] public string emotion;
/// <summary>
/// コメントのカラー
/// </summary>
[DataMember] public string tag;
/// <summary>
/// 読み上げるメッセージ
/// </summary>
[DataMember] public string text;
/// <summary>
/// コメント投稿者
/// </summary>
[DataMember] public string name;
/// <summary>
/// 運営コメントかどうか
/// </summary>
[DataMember] public bool isInterrupted;
private readonly DataContractJsonSerializer jsonSerializer;
public CommentInfo(string text)
{
jsonSerializer = new DataContractJsonSerializer(typeof (CommentInfo));
//読み上げテキストを設定
this.text = text;
//それ以外はすべてデフォルト値
name = "";
isInterrupted = false;
tag = "";
emotion = "";
}
public string ToJson()
{
string result = "";
using (var stream = new MemoryStream())
{
jsonSerializer.WriteObject(stream, this);
stream.Position = 0;
var reader = new StreamReader(stream);
result = reader.ReadToEnd();
}
return result;
}
}
みくみくまうすから接続できるようにする
みくみくまうすはTCP Clietとして対象のサーバに接続し、読み上げテキストを待ち受けるという仕組みになっています(APIリファレンス)。
そこでSpeechRecognition側にTcpServerを立て、みくみくまうすから接続できるようにします。
(本当はプロセス間通信を使いたかったんですが、みくみくまうすが用いているUnityではプロセス間通信は使えないのです)
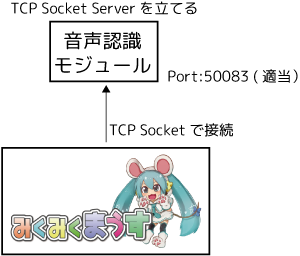
class TcpServerManager
{
private string hostAddress = "127.0.0.1";
private int port = 50083;
private List<TcpClient> tcpClients;
private Encoding encoding;
private TcpListener listener;
public TcpServerManager()
{
tcpClients = new List<TcpClient>();
encoding = Encoding.UTF8;
}
/// <summary>
/// サーバ起動
/// </summary>
public void ServerStart()
{
listener = new TcpListener(IPAddress.Parse(hostAddress), port);
listener.Start();
Accept();
}
/// <summary>
/// 外部からの接続を待機する
/// </summary>
async void Accept()
{
while (true)
{
var client = await listener.AcceptTcpClientAsync();
client.NoDelay = true;
//接続してきたクライアントをリストで保持
tcpClients.Add(client);
}
}
public void Disconnect()
{
listener.Stop();
}
/// <summary>
/// 全てのクライアントにMessageをブロードキャストする
/// </summary>
public void SendToAll(string message)
{
//接続が切れているクライアントは除去する
var closedClients = tcpClients.Where(x => !x.Connected).ToList();
closedClients.ForEach(x => tcpClients.Remove(x));
foreach (var client in tcpClients)
{
//接続が切れていないか再確認
if (!client.Connected) { continue; }
var ns = client.GetStream();
var byteMessage = encoding.GetBytes(message);
try
{
do
{
ns.WriteAsync(byteMessage, 0, byteMessage.Length);
} while (ns.DataAvailable);
}
catch (Exception e)
{
if (!client.Connected)
{
client.Close();
}
}
}
}
}
そしてこのTcpServerをSpeechRecognitionのコンストラクタで起動します。
private TcpServerManager _tcpServerManager;
public MainForm(PXCMSession session)
{
InitializeComponent();
//FormのコンストラクタでTcpServerを起動
_tcpServerManager = new TcpServerManager();
_tcpServerManager.ServerStart();
//以下略
}
みくみくまうすに音声認識結果を渡す
最後に、音声認識した結果をJsonに変換し、TcpSocket経由でみくみくまうすに流し込んであげるようにします。
private IDisposable recognationSendDisposable;
//VoiceRecognitionの初期化メソッド(最初から用意されている)
private void DoVoiceRecognition()
{
voiceRecognition = new VoiceRecognition();
//VoiceRecognition初期化時にOnRecognationAsObservableをSubscribe
recognationSendDisposable =
voiceRecognition
.OnRecognationAsObservable
.Subscribe(x =>
{
//音声認識結果をJson化
var json = new CommentInfo(x).ToJson();
//TcpSocketでブロードキャスト
_tcpServerManager.SendToAll(json);
});
voiceRecognition.DoIt(this, session);
this.Invoke(new VoiceRecognitionCompleted(
delegate
{
Start.Enabled = true;
Stop.Enabled = false;
MainMenu.Enabled = true;
if (closing) Close();
}
));
}
private void Stop_Click(object sender, EventArgs e)
{
stop = true;
// Stopが押されたら購読終了
recognationSendDisposable?.Dispose();
}
みくみくまうす側の実装
みくみくまうす側は汎用的に使えるように作ってあるので、特にコード変更するといったことはしていません。ポート番号を指定して起動してあげればそのまま利用することができるようになっています。
動作確認
ここまでで動くようになったはずなので、動作確認をしましょう。
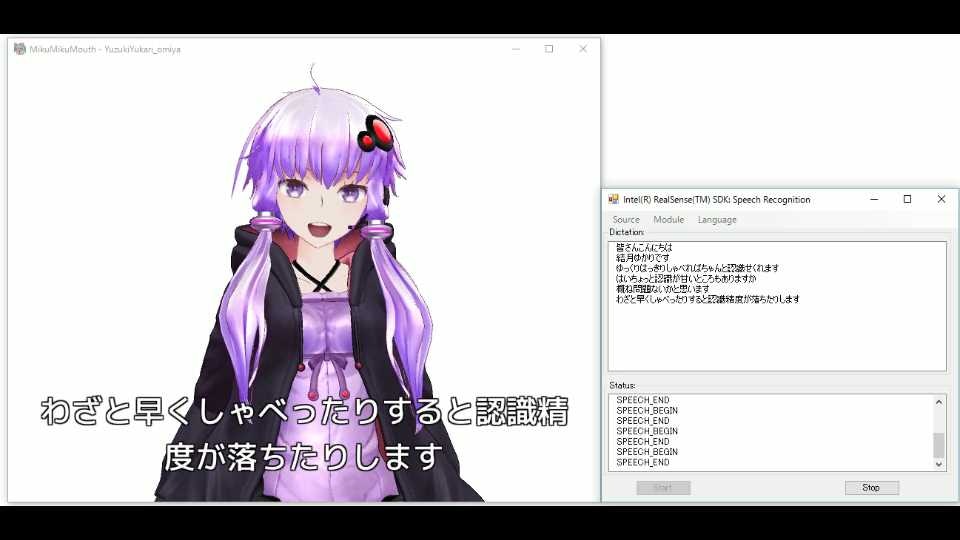 音声認識で結月ゆかりさんを喋らせる
音声認識で結月ゆかりさんを喋らせる音声認識については、ゆっくりハッキリと発音してあげることで概ね問題ない変換精度となりました。
早口で喋ったり、ぼそぼそ喋ったりすると途端に変換精度が落ちてしまうので注意が必要です。
映像合成
音声認識した結果をちゃんと喋るようになったのでは、あとはこれをゲーム映像に合成してあげて完成です。
映像合成についてはXSplitを使って行います。みくみくまうす側でゆかりさんを描画したあと、それをクロマキー合成させて映像に重ね、それを録画します。
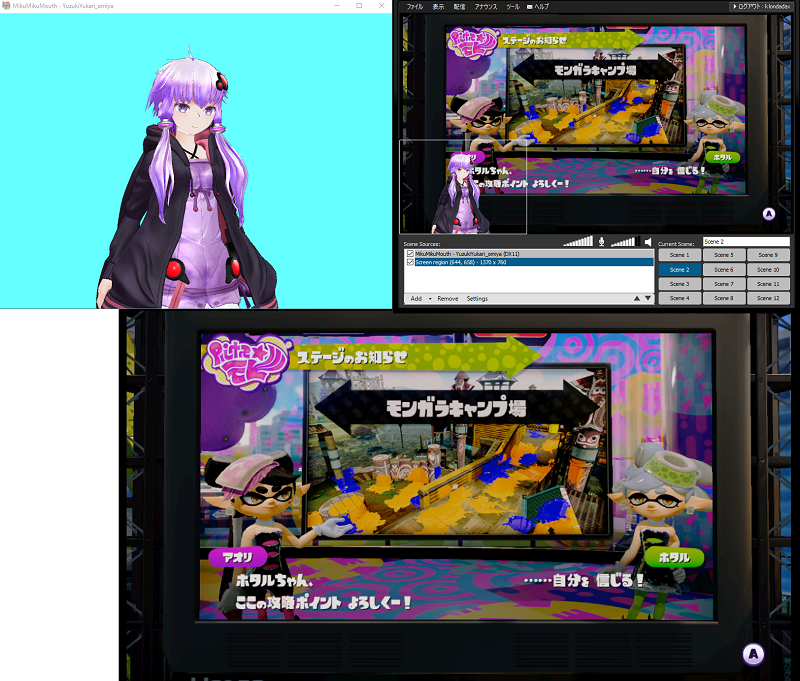
左上:みくみくまうす、右上:XSplit、下:キャプチャしたゲーム映像
完成
そしてできあがったものが、最初に貼った
動画

【スプラトゥーン】 ゆかりさんに音声認識で実況してもらった
この動画となります。
実際にやってみた感想
発声から読み上げまでに数秒の遅延はあるものの、ちゃんと実況として成立しているなと思いました。
この手法の一番の問題点は音声認識の精度なのですが、音声認識用のマイクをちゃんと口元に近づけ、ゆっくり、はっきりと喋ればそれなりの精度で認識してくれます。
ただ、ゲーム中って(特にイカの対戦ゲームとか)興奮して早口になったり叫んだりしてしまうので、実際にこれでちゃんとした結月ゆかり実況動画が作れるかと言ったら微妙かもしれませんね。
(ちなみに作った音声認識モジュールは公開する予定はありません。サンプルコードそのまんまだし、公開するならちゃんと作りたいです。)
おまけ(生放送で使う)
これをそのまま応用して、「地声を隠し、リスナーとゆかりさんがコミュニケーションとれる生放送ができるのでは?」とやってみました(というかもともとこっちを先にやりました)。
構成
音声認識の結果を生放送の運営コメントとして一回投稿し、その結果を読み上げてもらう形式にしました。
(音声認識の結果のログがコメントとして残るのでリスナーにわかりやすくなるため)
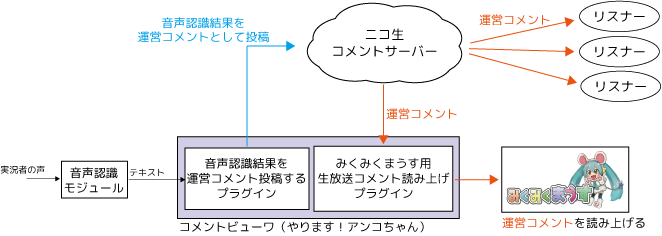
コメントビューワとしてやります!アンコちゃんを使い、アンコちゃん用のプラグインを作って音声認識結果を運営コメントとして投稿するようにしました。(自分でコメントサーバーにつなぐの面倒くさいからね…)
ここでコツとして、音声認識結果のテキストを運営コメントととして投稿するときに、8秒ほどディレイさせると良いでしょう。(配信映像はだいたい8~10秒ほど遅延してリスナーに届きます。そのため、音声認識した結果をすぐに運営コメントととして投稿すると、「運営コメントが少し未来のことを喋ってるようにリスナーからは見えてしまう」ようになってしまいます。)
結果
**番組崩壊しました。**普通に話す口調でそのまま音声認識にかけると認識精度が著しく悪くなり、ゆかりさんがずっと迷言を言い続ける生放送になってしまいました。「ゆかりさんになりきって放送する」といったことは難しそうです。
以下ポエム
迷言連発するゆかりさん、これはこれで面白いからむしろ認識精度はガバい方がいいんじゃないかなぁと思っていたりします。
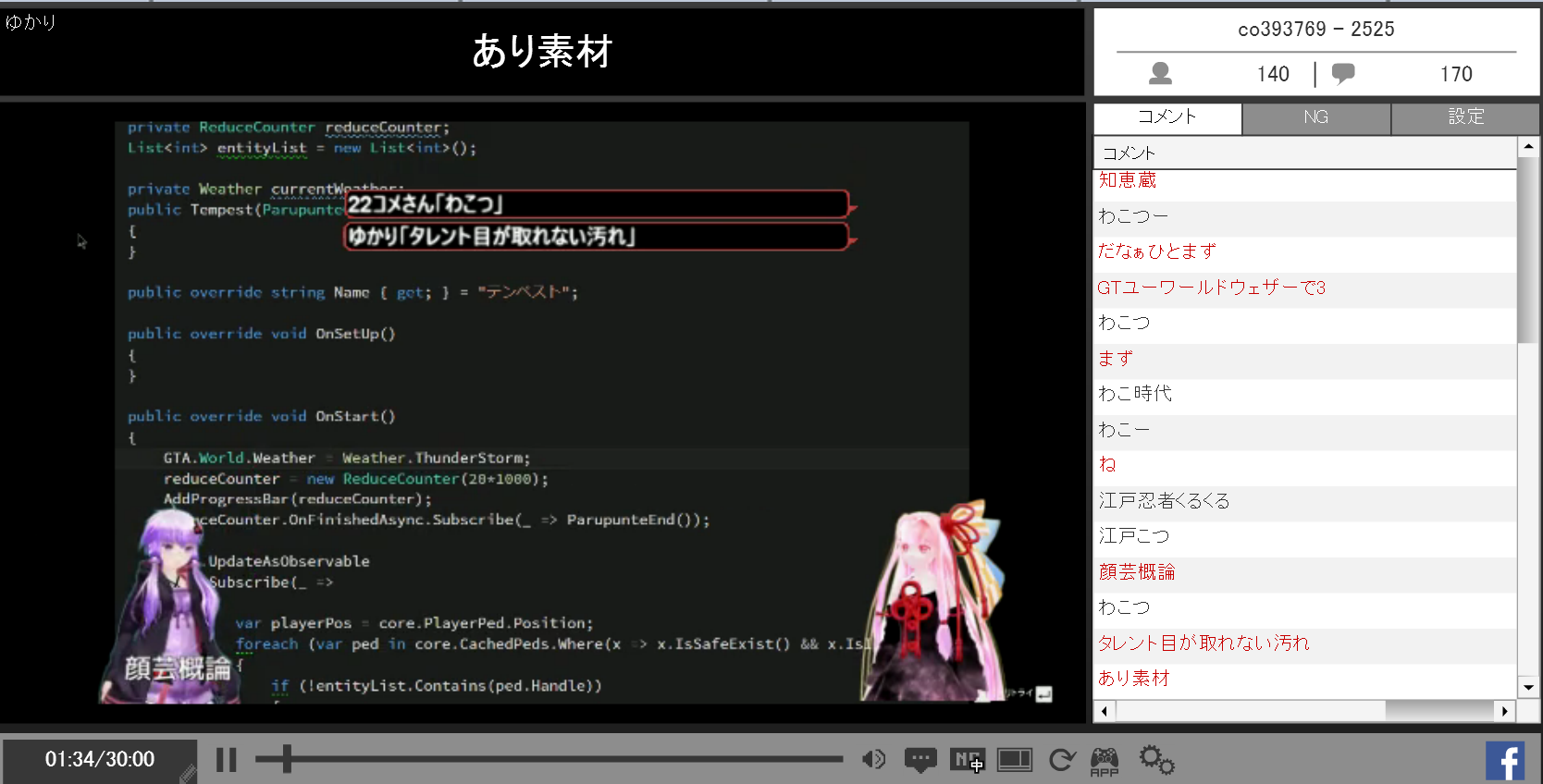
(実際に生放送でやってみた時のキャプチャ。オレンジのコメントが音声認識結果を運営コメントととして投稿したものです。「顔芸概論」というワードがツボりました。)
ちなみに自分の生放送でこの音声認識ゆかりさんを使ったところ、「追加利下げ」「中国の市場」「減収の見直し」「調光装置の生産」など微妙に関連しそうなワードへの誤変換が連発したことがありました。そのせいでリスナーはこの音声認識ゆかりさんを「工場長ゆかり」と呼ぶようになりました。工場長ゆかり語録、面白いのが多いのでそのうちまとめたいなぁ…。
といったところで今回は終わります。ありがとうございました。