あまり触れてこなかったオブジェクト指向に苦手意識があり、Rubyで何かを作ってみたら理解が捗るんじゃないかというのと、Webスクレイピングに興味があったので、表題の通り、Highcharts1 を使って描画するところまでやってみた。
成果物
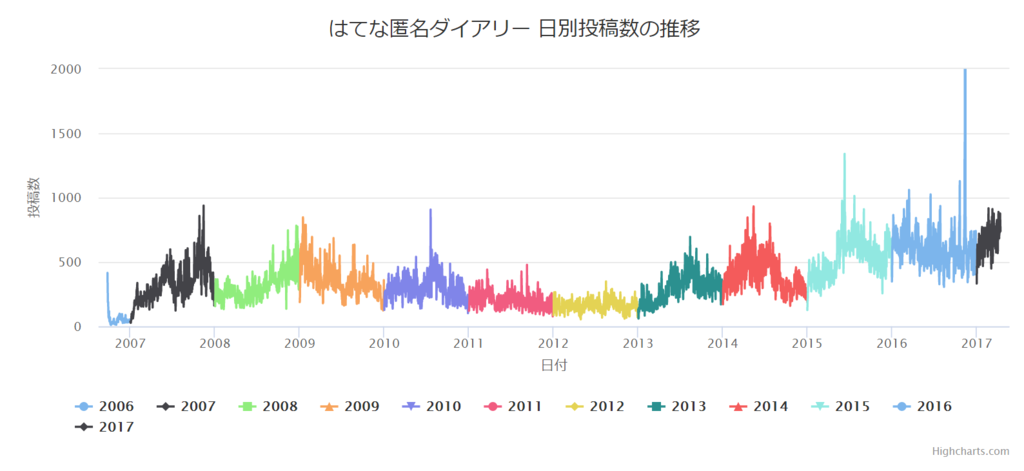
11年間で最も投稿が多かった日
| 日付 | 1日の投稿数(件) |
|---|---|
| 2016-11-12 | 10674 |
| 2016-11-13 | 5919 |
| 2016-11-10 | 1431 |
| 2016-11-11 | 1344 |
| 2015-06-11 | 1340 |
| 2016-10-20 | 1128 |
| 2016-03-15 | 1060 |
| 2016-06-16 | 1025 |
| 2015-06-10 | 1017 |
| 2015-07-23 | 1013 |
11年間で最も投稿が少なかった日
| 日付 | 1日の投稿数(件) |
|---|---|
| 2006-10-09 | 10 |
| 2006-11-01 | 12 |
| 2006-10-08 | 14 |
| 2006-10-31 | 15 |
| 2006-10-26 | 15 |
| 2006-10-11 | 16 |
| 2006-10-07 | 16 |
| 2006-10-27 | 19 |
| 2006-10-10 | 19 |
| 2006-10-18 | 20 |
- サービス開始は2006年9月24日
~感じたこと~
- 2016年11月12日や2016年10月20日といった荒らされていた日を確認することが出来た
- 2008年に入ってから一気に記事数が増えているのが不思議だなと思った
- 年末年始は記事を書いている人が少ないので、独身・一人暮らしが少ない感じの可能性がある
- 2011年から2012年にかけて記事数が減っているのは、震災もあり匿名サイトに構ってられないみたいな流れがあったんだろうか
- 2018年から2019年にかけてはちょっとずつ日別投稿数が減っていき、オリンピック後ぐらいにまたどんどん記事が増えていくのでは?見守っていきたい
ToDo
- コードのリファクタリング(highchartに描画するためのデータ整形部分がやばい)
- テストコードの切り分け(やり方が分からなかった、
rakeを使う?) - 1日ごとに
cronみたいな形で動かして記事件数を取得し、グラフが更新されるようにしたい
以下は技術的(これを果たして技術と括って良いのか)な話とか、どうして作るかに至ったか?書いていきます。
『はてな匿名ダイアリー』について
はてな匿名ダイアリーは、株式会社はてなが実験として展開しているサービスの1つで、ユーザーが匿名で日記を投稿できることから、多種多様な日記が投稿されています。しかし、日記の投稿サイトなのに1日に何件の日記が投稿されているのかがパット見分からないというわけで可視化したくなってやってみました。
サイトの仕様
-
http://anond.hatelabo.jp/robots.txt があるが
crawl-Delayをclawl-Delayとtypoしていた 2- 自分も「やるぞ!」ってなった時に作ったリポジトリ名を同様に間違えた
- 1日に投稿された日記は
http://anond.hatelabo.jp/20170101といった形で確認できる - 1ページにつき25件の日記が表示され、25件ごとにページが増える
-
http://anond.hatelabo.jp/20170101?date=20170101&page=30で30ページ目の日記が表示される
-
- 記事の無いページにもアクセスできるが、記事が存在しないので要素が表示されない
実装方針
-
robots.txtやGoogle検索を参考にスクレイピング間隔を決める - ページに25件の日記を表示する要素(
day)があるかないかを判別していく - 見ているページに
dayがあり、次のページに無かった場合、そのページの日記タイトルを表示する要素(h3)を数える - 2と3を足し算!したものをDBに格納する
- DBに格納したデータをHighchartsで整形してサイトで描画
しホスティングする
時間を使った所
実装方針2の処理について
1ページごとにあるかないか単純に確認していくのは1日辺りのアクセス数が$ O(n) $ になります。もし、スクレイピングしたかった日が100件の投稿だった場合、1ページに25件表示されているのだから、その日に生成されているのは4ページまでなので、4回スクレイピングをすれば100件という事が求められる事は明らかです。
しかし、10000件投稿されていた場合、10000/25=400で400回スクレイピングする必要があります。それを365日分スクレイピングしていくとなると、最終的にどれぐらい実行する事になり、相手側のサーバーにどれだけの負荷をかけさせる事になるのか判断がしづらいです。
そこで、1日にどのぐらい日記が投稿されているのかを事前に確認し、これからどのぐらいのデータを扱うのか見積もりました。その結果、1500件(60ページ以上)投稿されている日が無い様に見えたので、60ページを上限とした二分探索で処理する事にしました。
最終的に、二分探索のコードを実装する事になったので時間がかかったものの、$ O(log_2n) $ で済んだので、実行時間もアクセス数も改善されました。3 また、投稿数が1500を超える日があった事も分かり、それについては1500件になっていたデータを確認して、その日だけ上限変えたりしてSQLを叩く形で済ませました。
データベースの設計と作成
Qiitaに参考になる記事(最後に記載)があったので、設計はすぐに終わりました。ですが、PostgreSQLには更新時にcurrent timestampを書き込むという様なupdated_atを手助けしてくれる関数が存在しなかったので、先人の知恵を借りました。
さいごに
- webスクレイピングに関すること
- PostgreSQL・SQLに関すること
- グラフ描画に関すること
を、実際に作りながら知見として蓄積する事が出来ました ![]()
Webスクレイピングする内容にもよりますが、今回の様にデータの最大量を見積もっておくと、実装時に全探索をする必要がないという状況が生まれるのではないかというのは考えとして持っておくと良さそうだなと思った次第です。
スケジュールとしては4月4日にアイデア出して作業、就活、大学といった感じなので、1ヶ月かかっちゃいました。最終的にはHeroku辺りでホスティングして、SQLを何度も実行されてアレだからキャッシュを~みたいな事を考えたりしたかったけど、あんまり余裕が無いので、今回はとりあえずここまでです。お読み頂きありがとうございました。
関連サイト
- 作業リポジトリ
- 描画用リポジトリ(Sinatra+PostgreSQL)
-
外套とdoyagao
- はてブAPIを利用してはてな匿名ダイアリーを分析しているブログ
-
PostgreSQLで更新時のtimestampをアップデートするには
- タイトル通り
-
データベースオブジェクトの命名規約(Qiita記事)
- データベースの設計で参考になりました