この記事はパーソルキャリア Advent Calendar 2018の5日目です。
データ周りの業務を受け持ってしばらく経ったので、データマート等分析系システムの設計指針と実装例について書きます。
tl;dr.
- よくある業務系システムのテーブルから、分析系システム向けのテーブルを作る方法論について書いてみます
- 自分が参考にしている考え方
- ウィンドウ関数を用いて非正規化テーブルを作る実例(Redshiftベース)
- バッチ処理・データ転送処理の設計やワークフロー系のツール(処理の冪等性、DigDagやAirFlowなどのツール、etc...)については、本稿ではお話ししません。
想定読者
- アプリ開発にはある程度慣れており、DBも触れる方
- 分析向けのDBについて、RedshiftやBigQueryは知っていたり触ったことはあるが、分析向けのテーブル、データマートを1から作ったことはない方
前提として、以下の場面を想定します
- あるECサイトの履歴データが、とりあえず立ち上げたRedshiftに丸々移送されている状態
- 分析もそのままで出来なくはないが、業務システムのテーブル構造のままなのでちょっとやりづらい。。そんな時
そもそも分析向きのテーブルってなんだっけ
Star Schemaについて
DWH(データウェアハウス)、データマートなど、分析系システムと呼ばれるシステムの設計に関して、もっとも伝統的な考え方がスタースキーマと呼ばれるテーブル構成です。
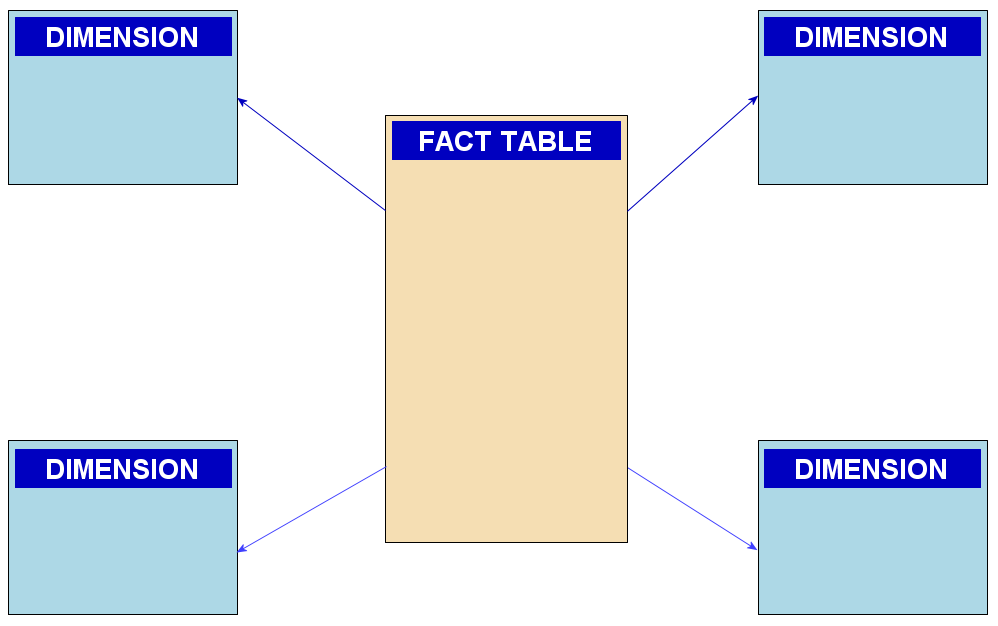
スタースキーマは中心にファクト(Fact, 事実)、その周囲にディメンション(Dimension、面・分析の切り口)が配置される概念図からその名がついています。
[Why Do I Need a Star Schema?]
(https://medium.com/data-ops/why-do-i-need-a-star-schema-338c1b029430)
facts are measurable data about the event.
ファクトは、イベントに関する計測可能なデータであり、例えば売り上げ金額や個数です。多くの場合、ディメンションに繋がる外部キーも同時に持ちます。例えば、購入した商品のID, 購入者の顧客ID, 購入された店舗のIDなどなど。
Dimensions are the actors or attributes related to the sale
ディメンションはアクター、または属性情報の集まりです。分かりやすい例であれば顧客マスタがディメンションとなり、ファクトをこうしたテーブルと結合することで年齢や性別といった分析の切り口が提供されます。
今はStar Schemaだけではダメです
上記の考え方は今でも有用ですが、とはいえこの考え方に徹頭徹尾従ってデータマートを構築しても最近の潮流には合いません。理由は主にデータストレージのコスト低下により、ファクトとディメンションを分けたままにしておく必要性がなくなったことです。
旧来はデータ量を最低限にするために両テーブルをそのままにし、可視化するBIツール側で結合するのが主流だったようです。しかし、現在であれば全てのディメンションを結合した非正規化テーブルをあらかじめ作っておくべきです。これをしたとしても大したコストになりませんし、LookerやTableauなどのBIツールで見に行く際にも大幅に楽になります。
こうした議論は「ビッグデータを支える技術」に詳しく載っています。この話に限らず大変広い内容がよくまとまった名著なので、データに関わる業務を始めたばかりの方は是非。
実例
それでは、とあるECサイトの業務システム(っぽい)データを例に、分析用テーブルを作って見ましょう。Redshiftクラスタに、遊び場用のsandboxスキーマを用意してある前提で進めます。
ユーザー属性テーブル
CREATE TABLE sandbox.user (
user_id INTEGER
,user_name VARCHAR(50)
,birth DATE
,sex SMALLINT
,address VARCHAR(50)
,updated DATE
);
INSERT INTO sandbox.user VALUES
(101,'Alice','1990-04-04',1,'静岡県','2018-04-01')
,(101,'Alice','1990-04-04',1,'東京都','2018-04-29')
;
Aliceは4/1にサイトに登録、月末に住所を変えたようです。
支払方法テーブル
CREATE TABLE sandbox.payment_method (
user_id INTEGER
,method_name VARCHAR(50)
,updated DATE
);
INSERT INTO sandbox.payment_method VALUES
(101,'コンビニ','2018-04-02')
,(101,'カード','2018-04-10')
;
ECサイトですから、メインの支払方法を選べます。別テーブルに持っているようです。Aliceは最初のお買い物でコンビニ払いを選択、後日自分のカードを使うように変更したようです。
注文テーブル
CREATE TABLE sandbox.purchase_order (
user_id INTEGER
, item_id VARCHAR(10)
, amount INTEGER
, ordered DATE
);
INSERT INTO sandbox.purchase_order VALUES
(101,'A01',3,'2018-04-02')
,(101,'B01',1,'2018-04-15')
,(101,'B02',2,'2018-04-30')
;
これがファクトですね。登録した月内に3回の注文がありました。話を広げすぎると分かり辛いので、今回はこの3テーブルを対象にしましょう。
目指す姿
先ほどの議論からして、こうした形のテーブルが作れれば良さそうです。
| ordered | item_id | amount | user_id | age | address | payment_method_name |
|---|---|---|---|---|---|---|
| 2018-04-02 | A01 | 3 | 101 | 27 | 静岡県 | コンビニ |
| 2018-04-15 | B01 | 1 | 101 | 28 | 静岡県 | カード |
| 2018-04-30 | B02 | 2 | 101 | 28 | 東京都 | カード |
属性情報の変化を捉えなければならない点に注意してください。月内に誕生日を迎えたAliceは4/15の購入において28歳の顧客として扱われます。支払い方法・住所も都度変動しているので、それぞれイベントが発生した時点の情報を参照できるとベストと言えます(もちろん、分析用途によってはここまでする必要がない場合もあります)。
有効期間付きの属性情報テーブルを作成する
まずは、2つのテーブルに散った顧客のディメンションを1テーブルに非正規化する事から始めましょう。いくつかアプローチはありますが、最近実務にも適用して良さげだったのが開始日と終了日を持つ属性情報テーブルを作る方法です。
このような形のテーブルを中間テーブルとして作成します。
| user_id | start_dt | end_dt | birth | address | payment_method_name |
|---|---|---|---|---|---|
| 101 | 2018-04-01 | 2018-04-01 | 1990-04-04 | 静岡県 | null |
| 101 | 2018-04-02 | 2018-04-09 | 1990-04-04 | 静岡県 | コンビニ |
| 101 | 2018-04-10 | 2018-04-28 | 1990-04-04 | 静岡県 | カード |
| 101 | 2018-04-29 | 9999-12-31 | 1990-04-04 | 東京都 | カード |
テーブル設計
CREATE TABLE sandbox.user_history (
user_id INTEGER
, start_dt DATE
, end_dt DATE
, birth DATE
, address VARCHAR(50)
, payment_method VARCHAR(50)
, primary key(user_id, start_dt)
)
sortkey(user_id, start_dt, end_dt)
;
この辺りから分析環境として新しく作るテーブルなので、キー情報を意識していきます。プライマリキーは直感的にもそう複雑でないので置いておくとして、ソートキーが重要です。
最初は違和感あると思うのですが、Redshiftにはインデックスが存在しません。代わりにソートキーと呼ばれるキーがその役割を果たします。
後々ファクトであるpurchase_orderと結合することが見えているので、その時結合条件となるであろうuser_id,start_dt,end_dtにキーを振っておきましょう。順番も重要となります(なお、順番に依存せず効くinterleaved sortkeyも存在します。この辺りは場面に応じた使い分けが必要)。
データの抽出
まず、user_idとstart_dtを抜き出すことを考えましょう。ちょっと面倒ですが、対象となる各テーブルから更新があった日毎にレコードを抜き出し、最後にdistinctを掛けて実現します。
with update_history as
(
select distinct
user_id, updated
from
(
select
user_id, updated
from
sandbox.user
union all
select
user_id, updated
from
sandbox.payment_method
)
)
内部のクエリ結果が目指す表の左2列と等しくなることはなんとなくわかっていただけると思います。結果は省略して次に進みます。
select
his.user_id
,his.updated as start_dt
-- 一旦end_dtは省略
,u.birth
,u.address
,p.method_name as payment_method_name
from
update_history his
left join
sandbox.user u
on his.user_id = u.user_id
and his.updated = u.updated
left join
sandbox.payment_method p
on his.user_id = p.user_id
and his.updated = p.updated
こんな感じで結合すると、歯抜けのデータが得られます。下表のような形ですね。
| user_id | start_dt | birth | address | payment_method_name |
|---|---|---|---|---|
| 101 | 2018-04-01 | 1990-04-04 | 静岡県 | null |
| 101 | 2018-04-02 | null | null | コンビニ |
| 101 | 2018-04-10 | null | null | カード |
| 101 | 2018-04-29 | 1990-04-04 | 東京都 | null |
このままではいまいち使えません。addressに対して、例えば「nullだったら前を遡ってnullじゃない値を返してくれる、とか出来ればいいのになあ」と思いませんか。思いますよね。
それを実現できるのが種々のウィンドウ関数です。
ウィンドウ関数は、より効率的に分析業務クエリを作成する機能をアプリケーション開発者に提供します。ウィンドウ関数はパーティションまたは結果セットの「ウィンドウ」で演算し、ウィンドウのすべての行に値を返します。
説明だけだと分かりづらいので実例を見ましょう。with句で宣言したupdate_historyに対して...
select
his.user_id
,his.updated as start_dt
-- u.birthがnullだったら、user_idごとにupdatedでソートし、1つ手前のu.birthを返す(1つ前がnullなら無視する)
,nvl(u.birth, lag(u.birth) ignore nulls over(partition by his.user_id order by his.updated)) as birth
-- u.addressがnullだったら、以下同文
,nvl(u.address, lag(u.address) ignore nulls over(partition by his.user_id order by his.updated)) as address
-- p.method_nameがnullだったら、以下同文
,nvl(p.method_name,lag(p.method_name) ignore nulls over(partition by his.user_id order by his.updated)) as payment_method_name
from
update_history his
left join
sandbox.user u
on his.user_id = u.user_id
and his.updated = u.updated
left join
sandbox.payment_method p
on his.user_id = p.user_id
and his.updated = p.updated
...やっていることはコメントに書いた通りです。一つずつ見ていきましょう。
NVL(またはcoalesce)
NVL または COALESCE 式は、Null ではないリストの最初の式の値を返します。式がすべて Null の場合、結果は Null です。
DB製品ごとに名前が違ったりしますが、単にnullなら第二引数の値を返すやつです。これはウィンドウ関数じゃないですね。
LAG関数
LAG ウィンドウ関数は、パーティションの現在の行より上 (前) の指定されたオフセットの行の値を返します。
ある列に対し、パーティションで区切られた範囲(=ウィンドウ)で何らかの演算を行うのがウィンドウ関数です。更新日に沿って並べ、直前の値を埋めてほしい今回のケースにぴったりと言えます。ignore nullsはオプションなので用途によって外せばまた結果が変わります。また、直前でなく2つ前、3つ前など任意のオフセットを指定可能です。
LEAD関数
上の例にはまだ出てきてませんが、LAGと全く逆の動きをしてくれるのが、LEADです。これは実は今回のケースでも、end_dtを算出するために使えます。後ろのレコードのupdatedを引っ張ってきて、日付を-1すれば求めるend_dtになるからです。
ここまで踏まえると、下記SQLを導くことができます。user_historyテーブルの完成です。
with update_history as
(
select distinct
user_id, updated
from
(
select
user_id, updated
from
sandbox.user
union all
select
user_id, updated
from
sandbox.payment_method
)
)
insert into sandbox.user_history
select
his.user_id
,his.updated as start_dt
,nvl(dateadd(day, -1, lead(his.updated) over(partition by his.user_id order by his.updated)),to_date('9999-12-31','yyyy-mm-dd')) as end_dt
,nvl(u.birth,lag(u.birth) ignore nulls over(partition by his.user_id order by his.updated)) as birth
,nvl(u.address,lag(u.address) ignore nulls over(partition by his.user_id order by his.updated)) as address
,nvl(p.method_name,lag(p.method_name) ignore nulls over(partition by his.user_id order by his.updated)) as payment_method_name
from
update_history his
left join
sandbox.user u
on his.user_id = u.user_id
and his.updated = u.updated
left join
sandbox.payment_method p
on his.user_id = p.user_id
and his.updated = p.updated
factと繋げて非正規化テーブルにする
あとはファクトであるところのpurchase_orderテーブルと結合してあげるだけです。
select
p.ordered
,p.item_id
,p.amount
,p.user_id
,datediff (year, u.birth, p.ordered) + (
case when date_part (doy, u.birth) > date_part (doy, p.ordered) then -1 else 0 end
) as age
,u.address
,u.payment_method_name
from
sandbox.purchase_order p
left join
sandbox.user_history u
on p.user_id = u.user_id
and u.start_dt <= p.ordered
and p.ordered <= u.end_dt
求める結果が得られたでしょうか?実際にはこの結果をまたテーブルに格納し、BIツールなどで参照しに行くのが普通の流れかと思います。今回のように履歴付きの属性情報テーブルを用意しておくと、分析対象のファクトが増えた時に大変汎用性高く使えるので便利です。
補題: 年齢の算出
今回は「購入時の年齢」を算出したいと仮定しているので、ファクトと結合するこの局面で年齢を算出することになります。この手法については下記リンクのものを参考にしています。
まとめ
- 分析系システムは、分析系システムの考え方に沿って非正規化テーブルを設計していくと良いです。
- 「ビッグデータを支える技術」は名著です。
- ディメンション系のテーブルは、必要に応じて有効期間を持たせる設計にすると汎用性が上がります。その際、実装にはウィンドウ関数が便利です。
そうそう、実際に使ったテーブルがある場合は消しておくと良いと思います。
drop table if exists sandbox.user;
drop table if exists sandbox.purchase_order;
drop table if exists sandbox.payment_method;
drop table if exists sandbox.user_history;
ここまでお読みいただきありがとうございました!