株式会社 日立製作所 藤井 智明
2021年よりElastic Stackに関する社内での技術支援に携わっています。最近の技術支援において、Elasticの機械学習を活用する興味深い取り組みに関わることができました。本記事では、その技術支援で得られた知見に関して紹介したいと思います。
はじめに
Elastic Stackは、Elastic社が提供するプロダクト群です。Elastic Stackは、データの蓄積・検索・分析を行うElasticsearch、データの可視化・管理を行うKibana、データの収集を行うLogstash、Beatsで構成されます。Elastic Stackを活用することで、様々なソースから様々なフォーマットでデータを収集し、収集したデータをリアルタイムに検索、分析、可視化することができます。
また、Elastic Stackを活用することで、機械学習を実現することもできます。具体的には、Elastic Stackの有償オプションとして提供されている、Elasticの機械学習機能を活用することで、機械学習を実現します。Elasticの機械学習機能では、データの異常や外れ値を見つけたり、傾向に基づいて予測を立てたりすることができます。
本記事では、Elasticの機械学習機能の概要と、機械学習機能「異常検知」による教師なし機械学習に関して紹介します。
Elasticの機械学習機能の概要
Elasticの機械学習機能は、データを分析し、データの動作パターンのモデルを生成する機能です。
ユーザは、解決したい課題、利用できるデータの種類に基づき、教師なし機械学習または教師あり機械学習を選択します。機械学習機能には、各機械学習に対応する機能があります。
教師なし機械学習に対応する機能
教師なし機械学習に対応する機能には、「異常検知」と「データフレーム分析(外れ値検出)」の2つがあります。
| # | 機能 | 説明 | 分析対象 |
|---|---|---|---|
| 1 | 異常検知 | 時刻と値をセットにした時系列データの分析と、特定の時間帯における特定の傾向の学習を、継続的に実行・モデル化することで、データの正常な動作のベースラインを作成し、データの異常なパターンの特定や、将来の動作の予測を行う機能。 | 時系列データ |
| 2 |
データフレーム分析 (外れ値検出) |
各データが他のデータとどれだけ類似しているか、周囲のデータがどれだけ密集しているかを分析し、異常なデータの値を外れ値として識別・検出する機能。ただし、分析を継続的に実行するわけではない。 |
データセット (同じ構造を持つ データのコレクション) ※時系列データは不要 |
教師あり機械学習に対応する機能
教師あり機械学習に対応する機能には、「データフレーム分析(回帰)」と「データフレーム分析(分類)」の2つがあります。
| # | 機能 | 説明 | 分析対象 |
|---|---|---|---|
| 1 |
データフレーム分析 (回帰) |
連続的な数値を予測するために、データ間の関係を学習する機能。 例えば、Webのリクエストの応答時間など。 |
データセット (同じ構造を持つ データのコレクション) ※時系列データは不要 |
| 2 | データフレーム分析 (分類) |
個別のカテゴリを予測するために、データ間の関係を学習する機能。 例えば、DNS(Domain Name System)のリクエストが悪意のあるドメインが発信したものか否かなど。 |
データセット (同じ構造を持つ データのコレクション) ※時系列データは不要 |
機械学習機能「異常検知」による教師なし機械学習
機械学習機能「異常検知」で教師なし機械学習を実現することができます。
機械学習機能「異常検知」は、時系列データを分析することで、正常な動作のベースラインを作成し、データセット(同じ構造を持つデータのコレクション)内の異常なパターンを特定します。分析では、Elasticsearchからデータを取得し、異常な結果をKibanaで可視化します。
本記事では、実際に、機械学習機能「異常検知」で教師なし機械学習を実現する例を、異常検知ジョブの作成→異常検知結果の表示→予測の作成の流れで、紹介します。
教師あり機械学習のデータフレーム分析(分類)を試した内容については、次回記事を参照してください。
機械学習機能を利用する前に
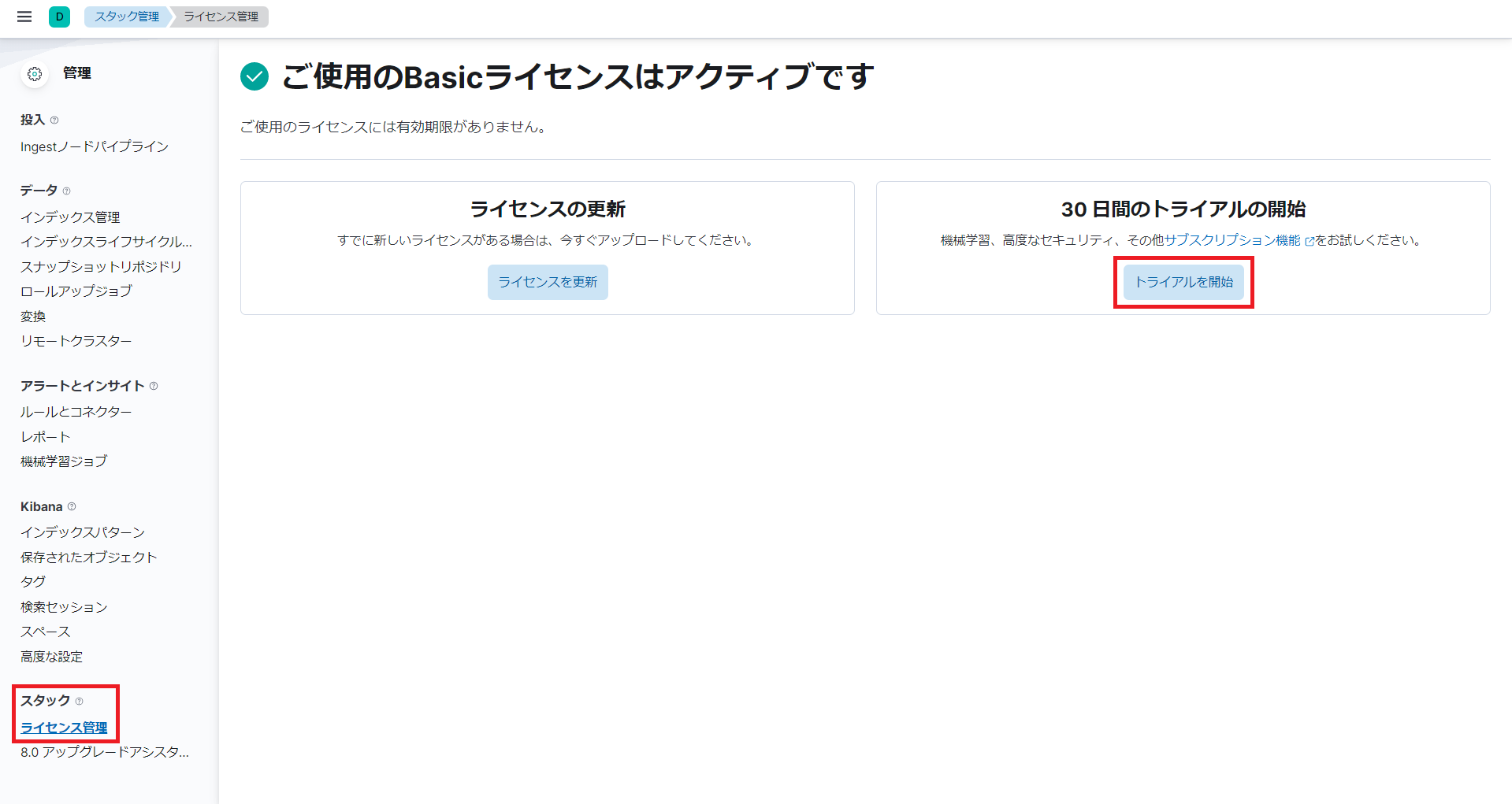
機械学習機能を利用するには、有償のライセンスが必要になるため、今回はお試しの30日間無料トライアルを使用します。
「スタック管理」の「ライセンス管理」を選択して、「30日間のトライアルの開始」の「トライアルを開始」ボタンをクリックして始めます。
利用する時系列データ
今回は、REST APIによる入力を受け付ける社内システムのログを利用します。ログは、時系列データとなっており、時刻や、HTTPリクエスト、トランザクションなどのデータを含みます。
異常検知ジョブの作成
最初に、異常検知ジョブの作成を行います。
Kibanaのホーム画面を表示します。
「分析」をクリックし、分析画面を表示します。
「機械学習」をクリックし、機械学習の概要画面を表示します。
「初めての異常検知ジョブを作成しましょう。」の方の「ジョブを作成」をクリックし、インデックスパターンまたは保存検索の選択画面を表示します。
インデックスパターンまたは保存検索の選択画面では、インデックスパターンまたは保存検索を選択します。
今回の例では、「fb-request-*」というインデックスパターンを選択します。「fb-request-*」は、社内システムから取得したHTTPリクエストに関する時系列データのインデックスに対応するインデックスパターンです。
「fb-request-*」というインデックスパターンを選択し、インデックスパターンを利用したジョブの作成画面を表示します。
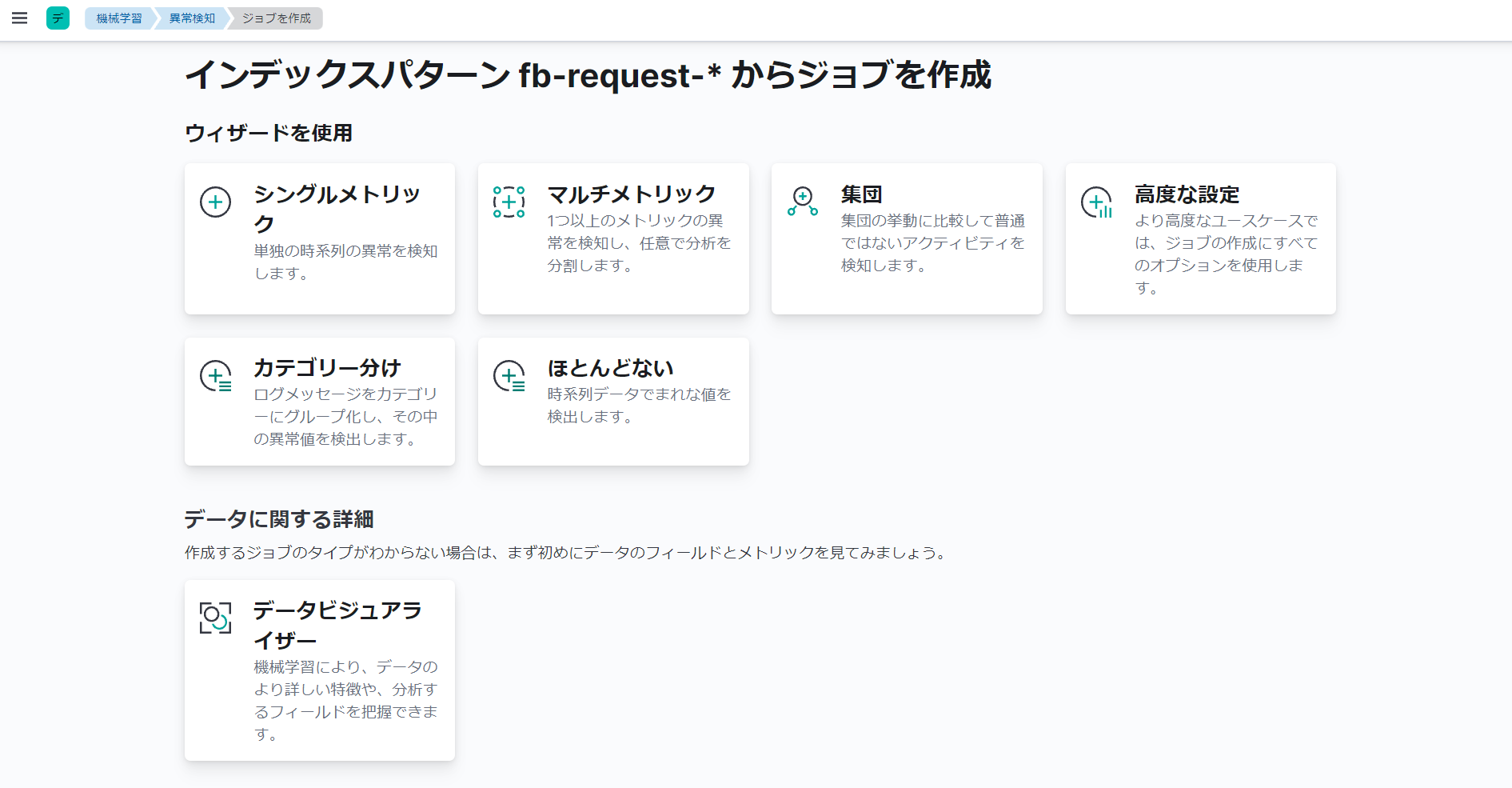
インデックスパターンを利用したジョブの作成画面では、「ウィザードを使用」という項目から、利用するウィザードを選択します。
今回の例では、「シングルメトリック」というウィザードを選択します。「シングルメトリック」は、シングルメトリックジョブを作成するためのウィザードです。シングルメトリックジョブは、時系列データを分析し、単一メトリックの異常を検知する、異常検知ジョブです。
「シングルメトリック」というウィザードを選択し、時間範囲の設定画面を表示します。
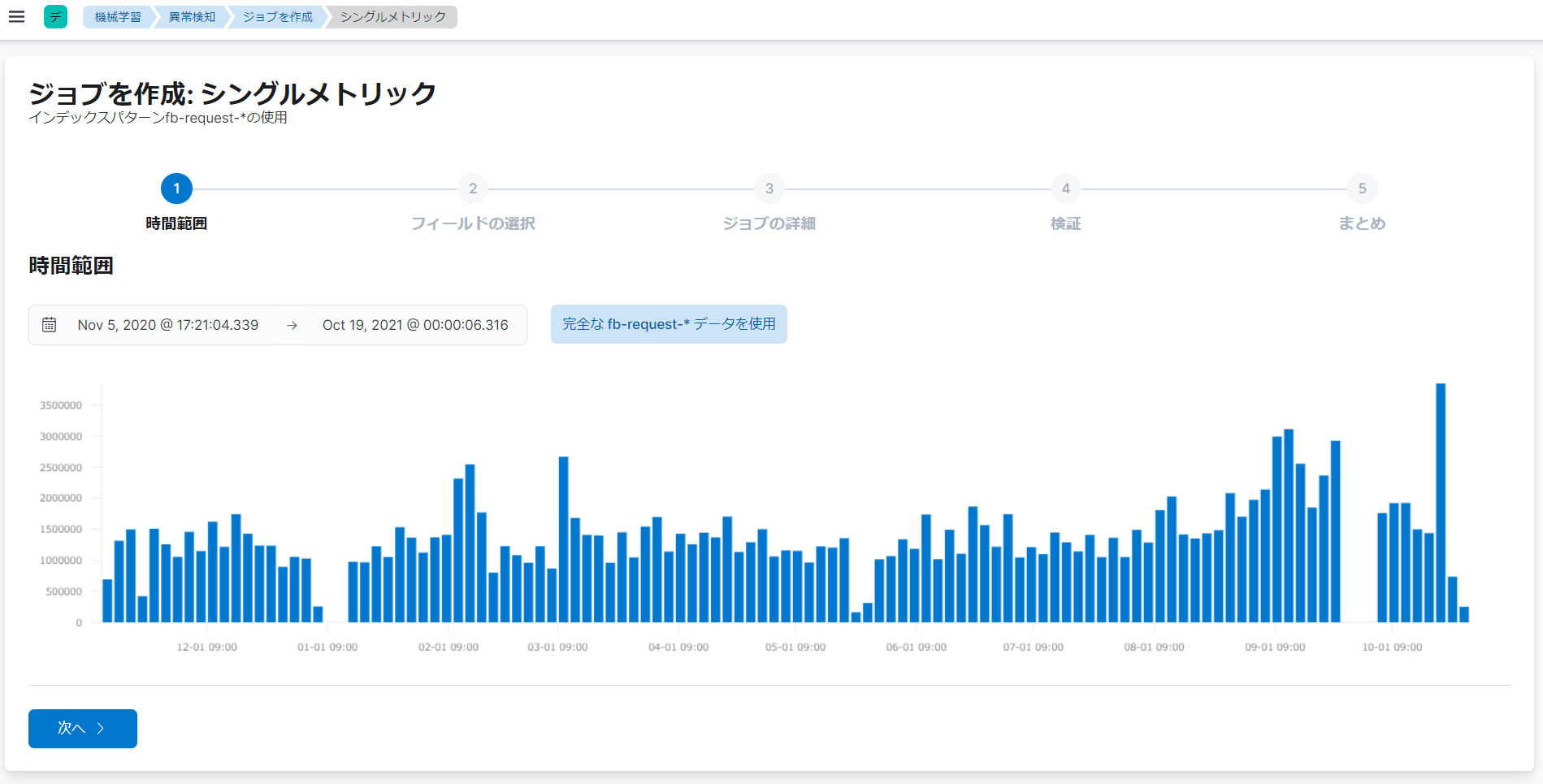
時間範囲の設定画面では、時間範囲を設定します。時間範囲は、タイムピッカーで開始日時と終了日時を指定するか、「完全な<インデックスパターン名>データを表示」(<インデックスパターン名>の部分は、選択したインデックスパターン名が表示される)をクリックすることで、設定します。「完全な<インデックスパターン名>データを表示」をクリックすると、データが存在する全時間範囲を表示することができます。
今回の例では、「完全なfb-request-*データを表示」をクリックすることで、時間範囲を設定します。
時間範囲の設定が完了したら、「次へ」をクリックし、フィールドの選択画面を表示します。
フィールドの選択画面では、利用するフィールドを選択します。
今回の例では、「Count(Event.rate)」というフィールドを選択します。「Count(Event.rate)」は、イベントレート(一定時間内に発生したイベントの数)を取得するフィールドです。
フィールドを選択すると、グラフ、設定項目、「マルチメトリックジョブに変換」というリンクが追加で表示されます。
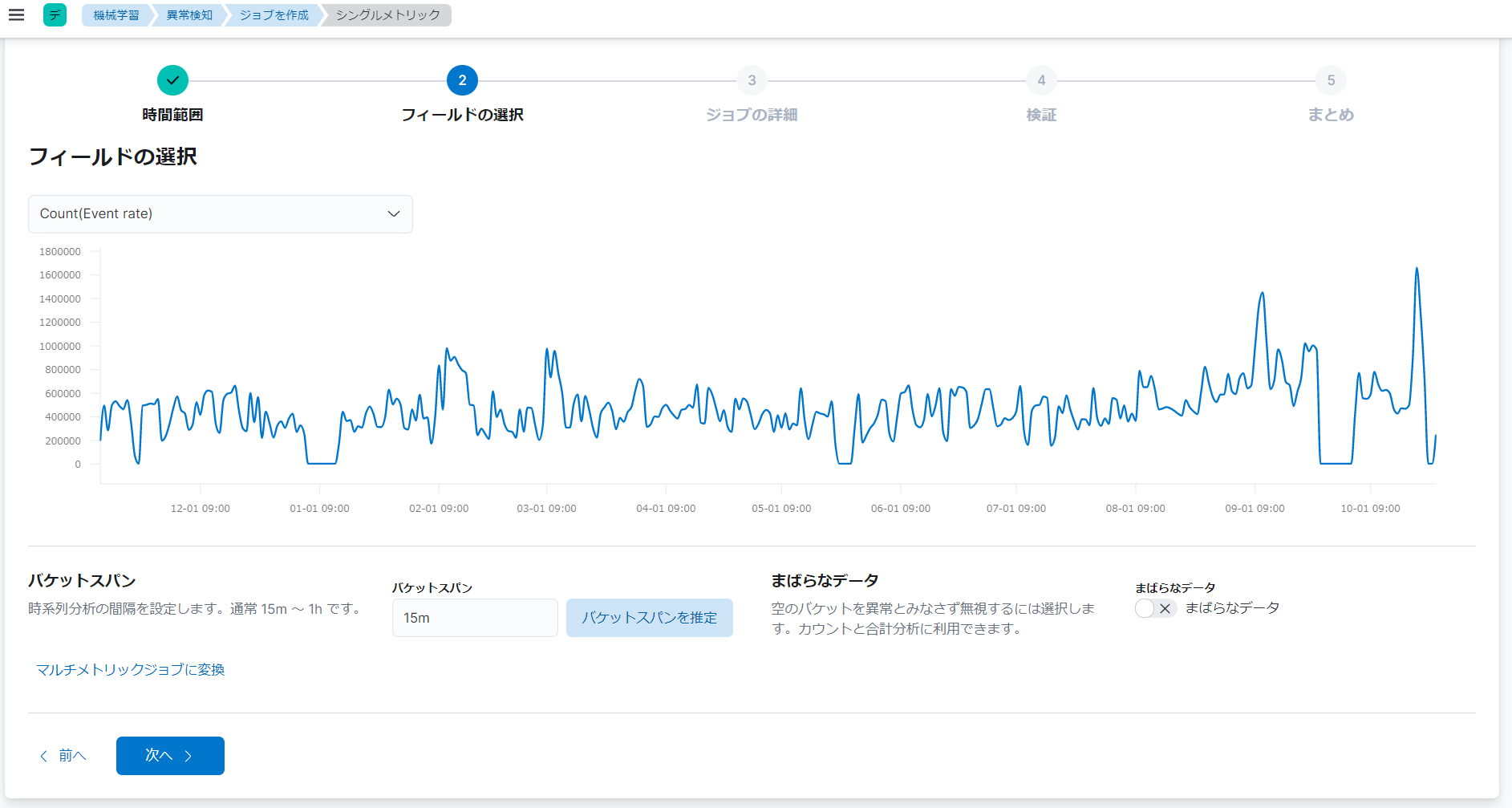
設定項目には、「バケットスパン」と「まばらなデータ」の2つがあります。
| # | 設定項目 | 説明 | デフォルト設定 |
|---|---|---|---|
| 1 |
バケットスパン |
時系列分析の間隔を設定するための項目。 通常は、15m(15分)~1h(1時間)を設定する。「バケットスパンを推定」をクリックすることで、バケットスパン推定器により計算された、時系列分析を実行できる最小の間隔を設定することもできる。 |
15m (15分) |
| 2 | まばらなデータ | まばらなデータであるかないかを設定するための項目。 オン(まばらなデータである)に設定すると、空のバケットを異常とみなさずに無視する。Count(カウント)とSum(合計)の分析に利用できる。 |
オフ (まばらなデータでない) |
今回の例では、「バケットスパン」は、設定を変更しません。「まばらなデータ」は、空のバケットを異常とみなさないようにするため、オン(まばらなデータである)に設定を変更します。
「マルチメトリックジョブに変換」というリンクは、クリックすることで、現在作成中のシングルメトリックジョブをマルチメトリックジョブに変換することができます。マルチメトリックジョブは、「マルチメトリック」というウィザードで作成できる、時系列データを分析し、複数メトリックの異常を検知する、異常検知ジョブです。
今回の例では、「マルチメトリックジョブに変換」というリンクは、クリックしません。
フィールドの選択が完了したら、「次へ」をクリックし、ジョブの詳細設定画面を表示します。
ジョブの詳細設定画面では、異常検知ジョブの詳細設定を行います。
基本の設定項目には、「ジョブID」、「ジョブの説明」、「グループ」の3つがあります。
| # | 設定項目 | 説明 |
|---|---|---|
| 1 | ジョブID | ジョブを識別するためのIDを設定するための項目。 |
| 2 | ジョブの説明 | どのようなジョブであるかの説明の記載を設定するための項目。 オプションのため、設定しなくてもよい。 |
| 3 | グループ | ジョブを所属させるグループを設定するための項目。 オプションのため、設定しなくてもよい。 |
今回の例では、「ジョブID」に「fb-request_job」を設定します。「ジョブの説明」と「グループ」は、設定を変更しません。
基本の設定項目の他、「追加設定」と「高度な設定」もあります。「追加設定」と「高度な設定」により、より詳細な設定を行うこともできます。
今回の例では、「追加設定」と「高度な設定」を行いません。
異常検知ジョブの詳細設定が完了したら、ジョブの検証画面を表示します。
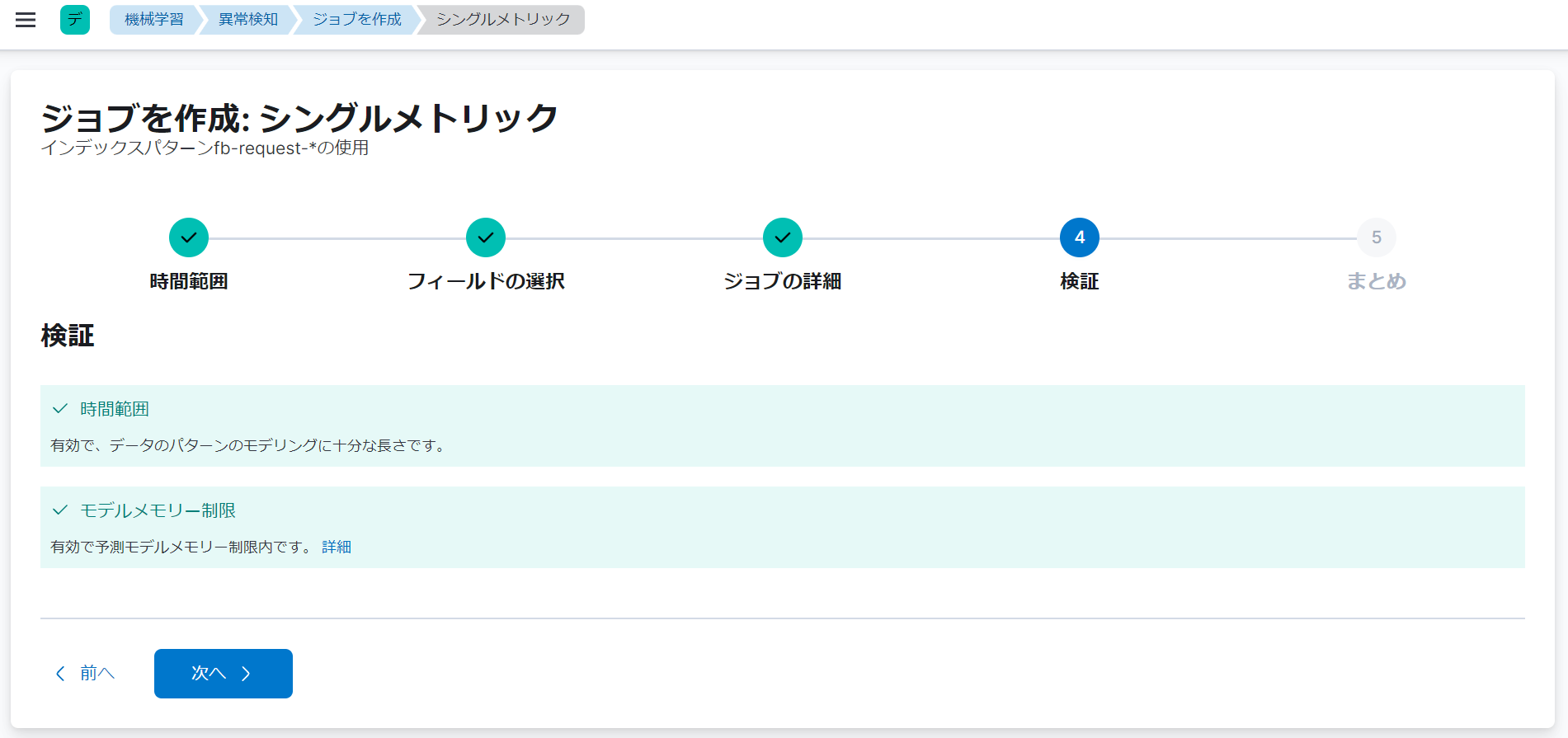
ジョブの検証画面では、異常検知ジョブの設定に関する検証結果が表示されます。
今回の例では、「時間範囲」と「モデルメモリー制限」の2つに関して、検証結果が表示されます。いずれの検証結果にも「✓」が表示されています。「✓」の表示は、異常検知ジョブの設定に関する検証が正常に完了したことを意味しています。
異常検知ジョブの設定に関する検証が完了したら、「次へ」をクリックし、ジョブの作成に関する設定の確認画面を表示します。
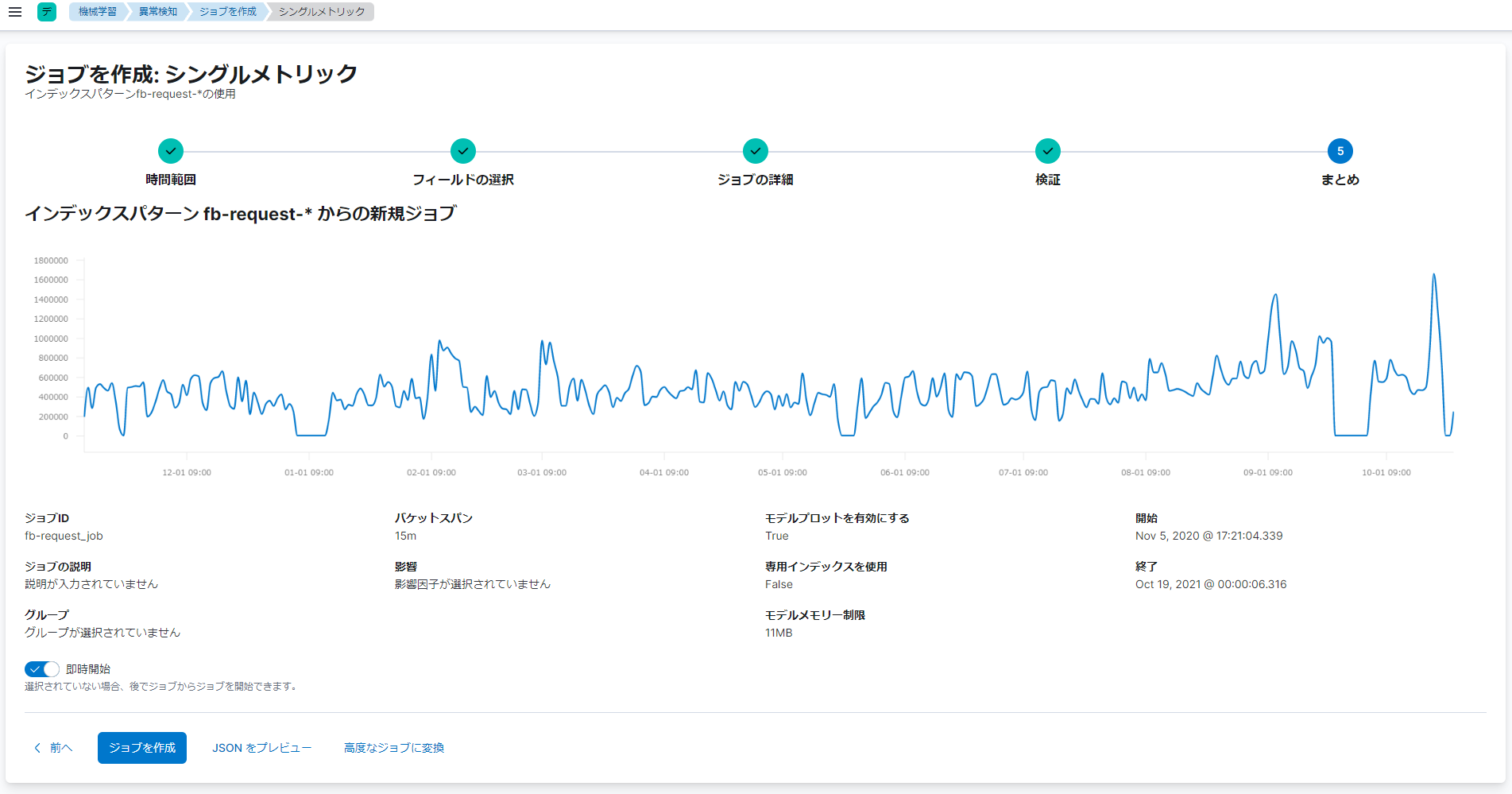
ジョブの作成に関する設定の確認画面では、異常検知ジョブの設定を確認します。
異常検知ジョブの設定の確認が完了したら、「ジョブを作成」をクリックし、異常検知ジョブの作成を開始します。異常検知ジョブの作成を開始したら、完了するまで待ちます。異常検知ジョブの作成が完了したら、ジョブの作成完了画面で、「結果を表示」(下図赤枠)をクリックできるようになります。
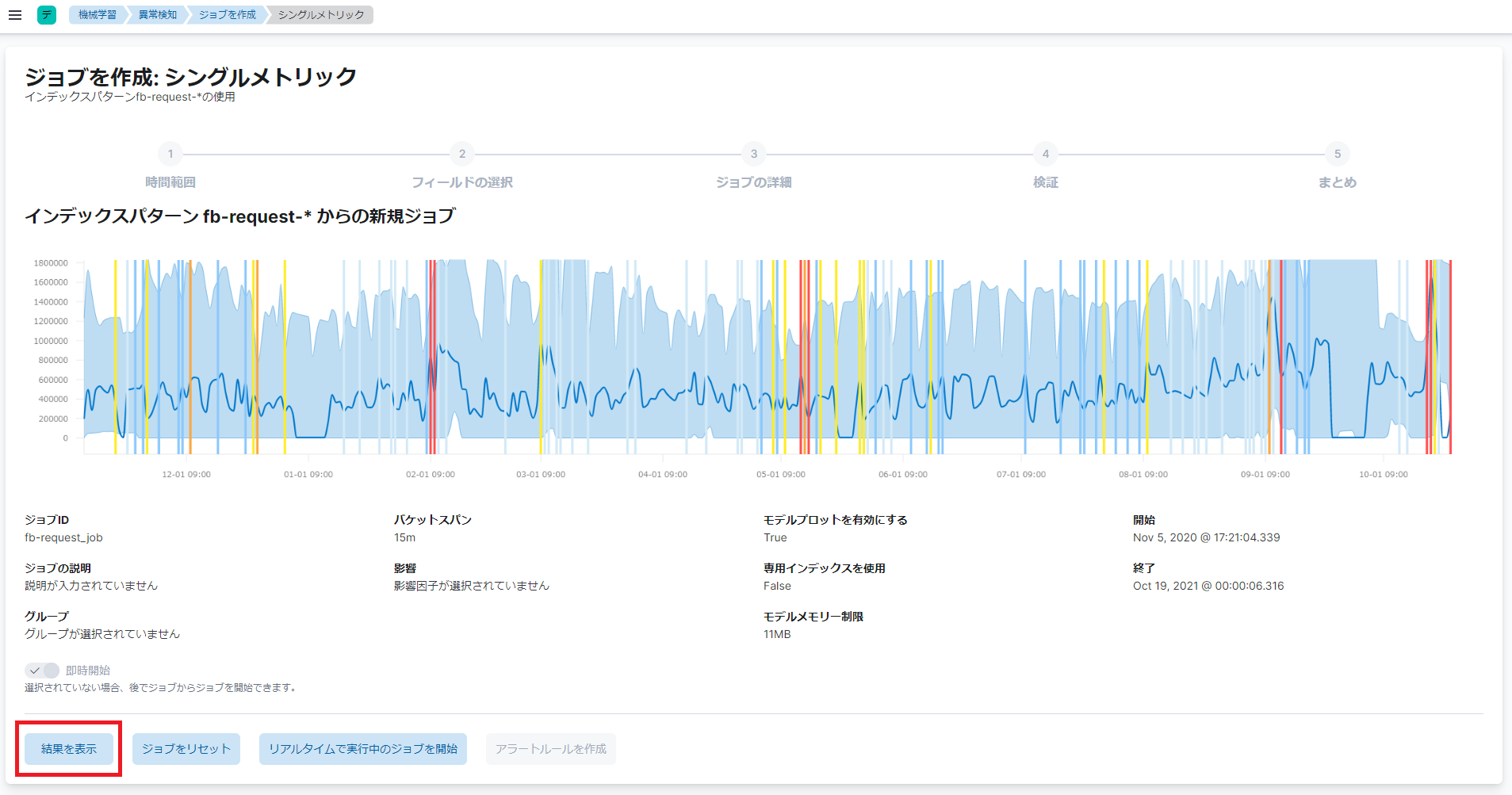
これで、異常検知ジョブの作成が完了しました。
異常検知結果の表示
異常検知ジョブの作成が完了したら、異常検知結果の表示を行います。
ジョブの作成完了画面で、「結果を表示」(上図赤枠)をクリックし、シングルメトリックビューアーを表示します。
※シングルメトリックビューアーに異常が表示されない場合は、異常として検知されたデータがグラフの下部分にあるタイムセレクター(下図赤枠)の範囲に含まれていない可能性があります。その場合は、異常として検知されたデータが含まれるように、タイムセレクター(下図赤枠)の範囲を調整します。タイムセレクター(下図赤枠)の範囲を調整すると、シングルメトリックビューアーが再描画されます。
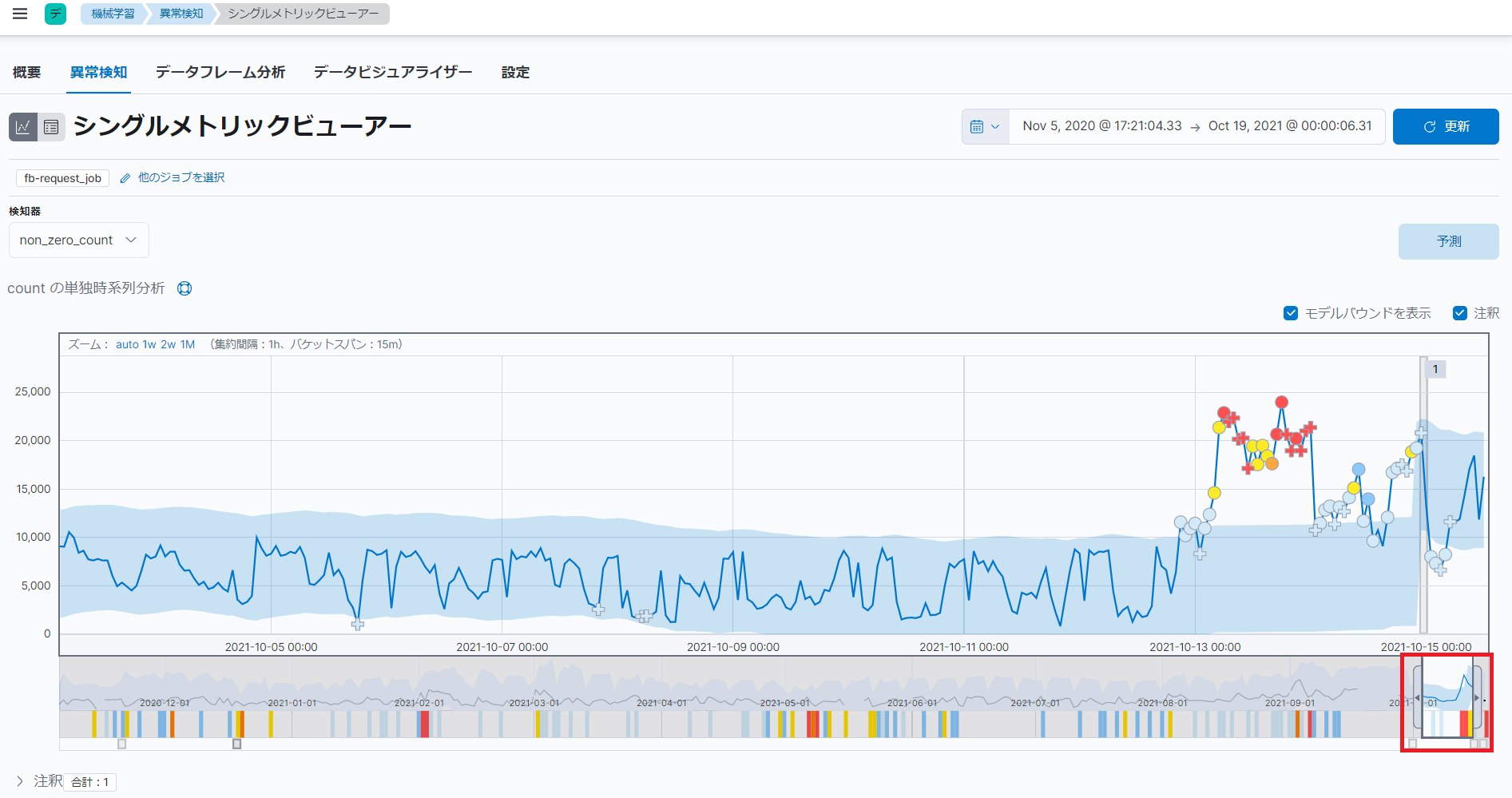
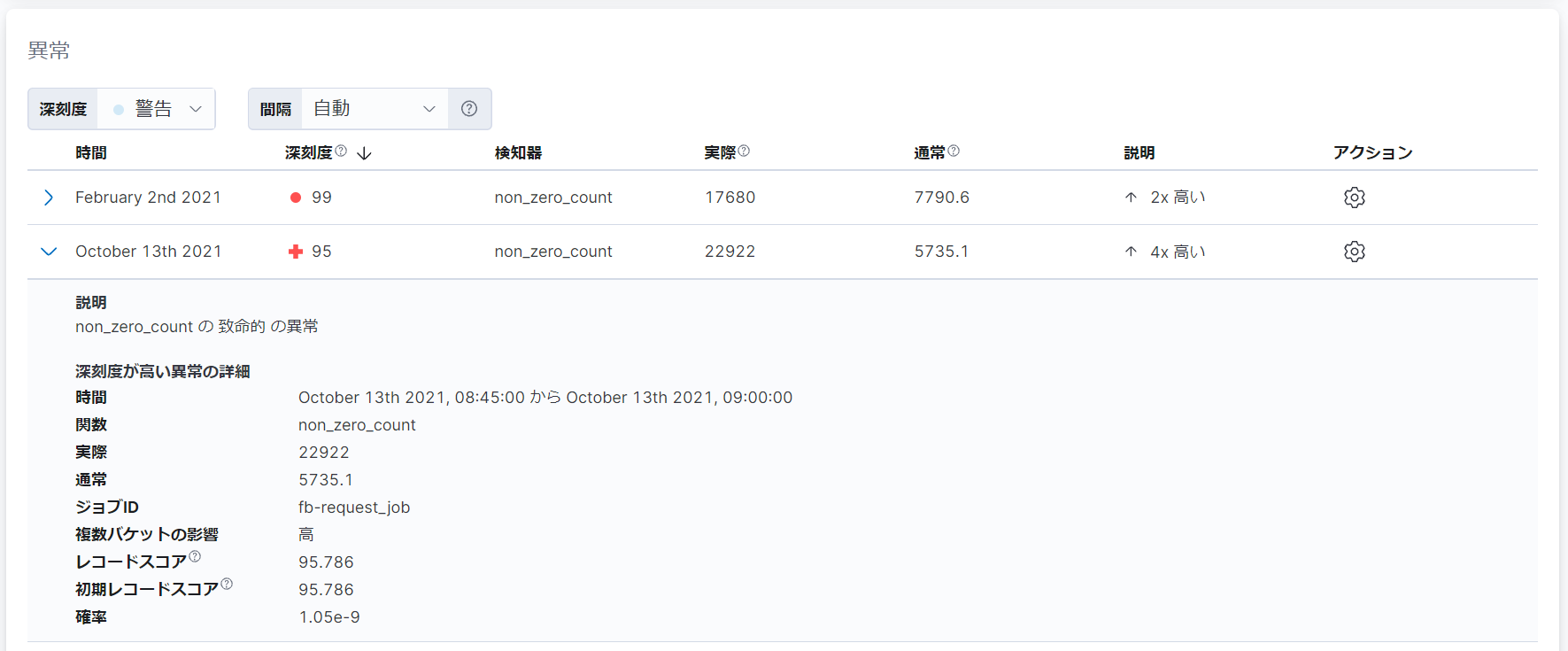
シングルメトリックビューアーには、「count の単独時系列分析」と「異常」という2つの項目があります。
「count の単独時系列分析」という項目では、グラフが表示されます。グラフの青色の線は、実際のデータの値を表しています。グラフの青色の網掛け領域は、モデルにより予測されたデータの期待値の範囲を表しています。実際のデータの値がこの領域の外にある場合、その値を持つデータは異常として検知されます。
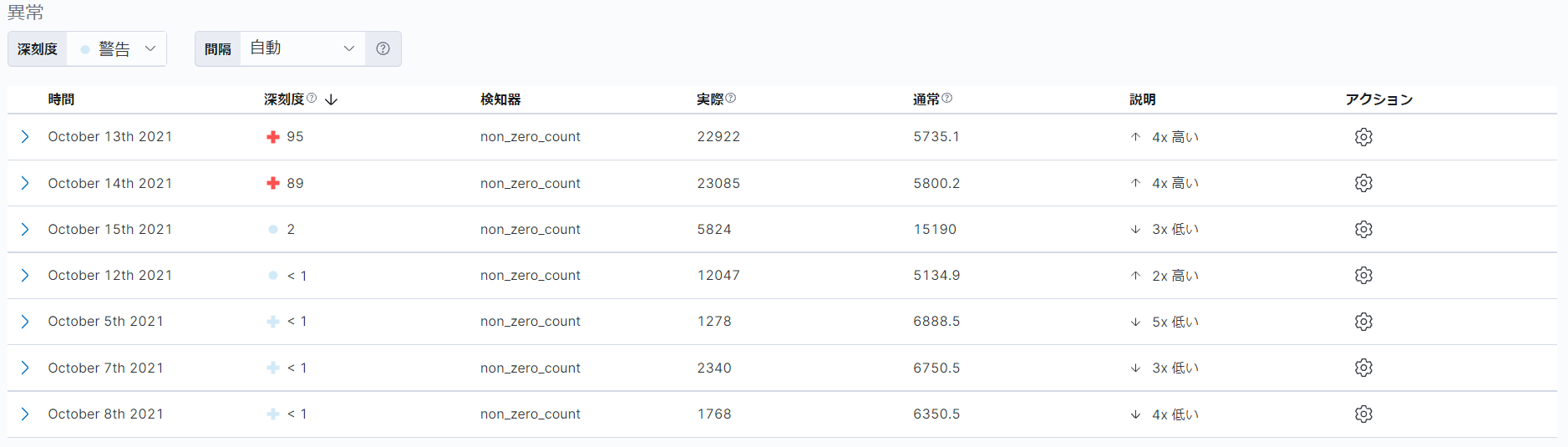
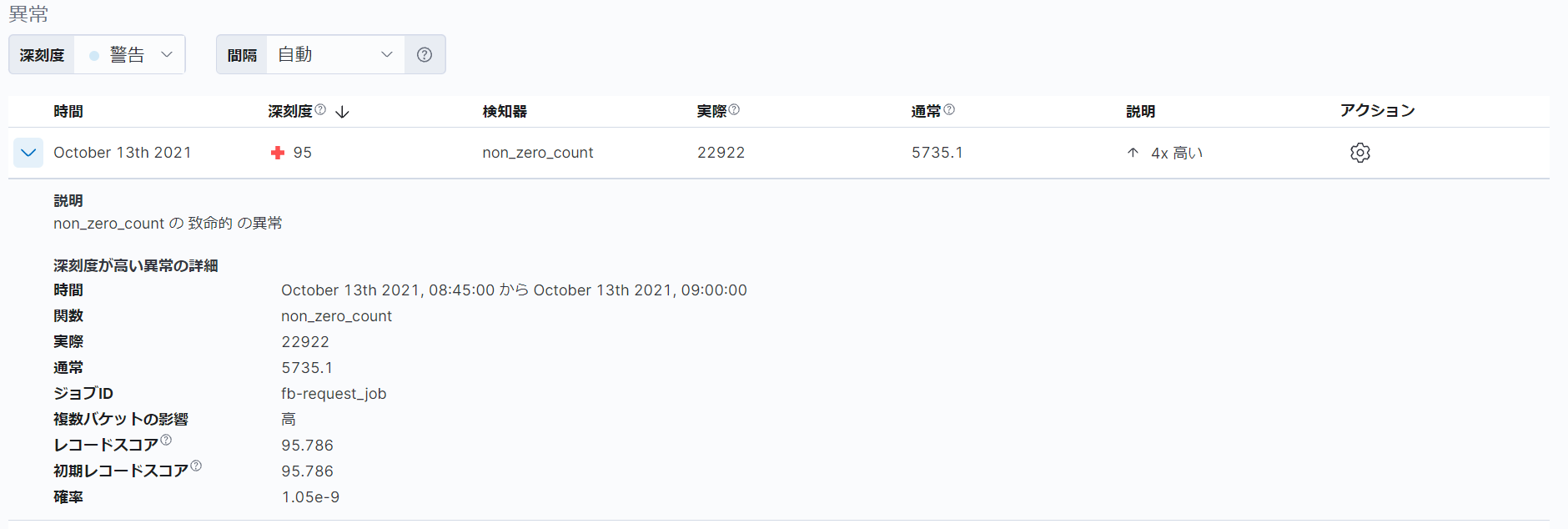
「異常」という項目では、検知された異常が深刻度の高い順にリストで表示されます。異常として検知された各データに対して、深刻度が計算されます。深刻度の値は、0~100であり、以前に異常として検知されたデータと比較してどれだけ異常かを表します。深刻度の色は、深刻度の値に基づき、青(0~25)、黄(25~50)、橙(50~75)、赤(75~100)のいずれかで表示されます。深刻度の印は、複数バケットへの影響度に基づき、丸(低)、十字(中~高)のいずれかで表示されます。
今回の例では、2021年10月13日に深刻度95の異常が検知されたことがわかります。また、異常が検知された理由は、イベントレートの実際の値が、通常の「5735.1」という値と比較して約4倍高い、「22922」という値になっているためであることがわかります。
表示された行の左端にある「>」をクリックすることで、異常の詳細を参照することもできます。
シングルメトリックビューアーの他、異常エクスプローラーで異常検知結果を表示することもできます。異常エクスプローラーは、シングルメトリックビューアーで、異常エクスプローラーのアイコン(下図赤枠)をクリックすることで、表示できます。
異常エクスプローラーのアイコン(上図赤枠)をクリックし、異常エクスプローラーを表示します。
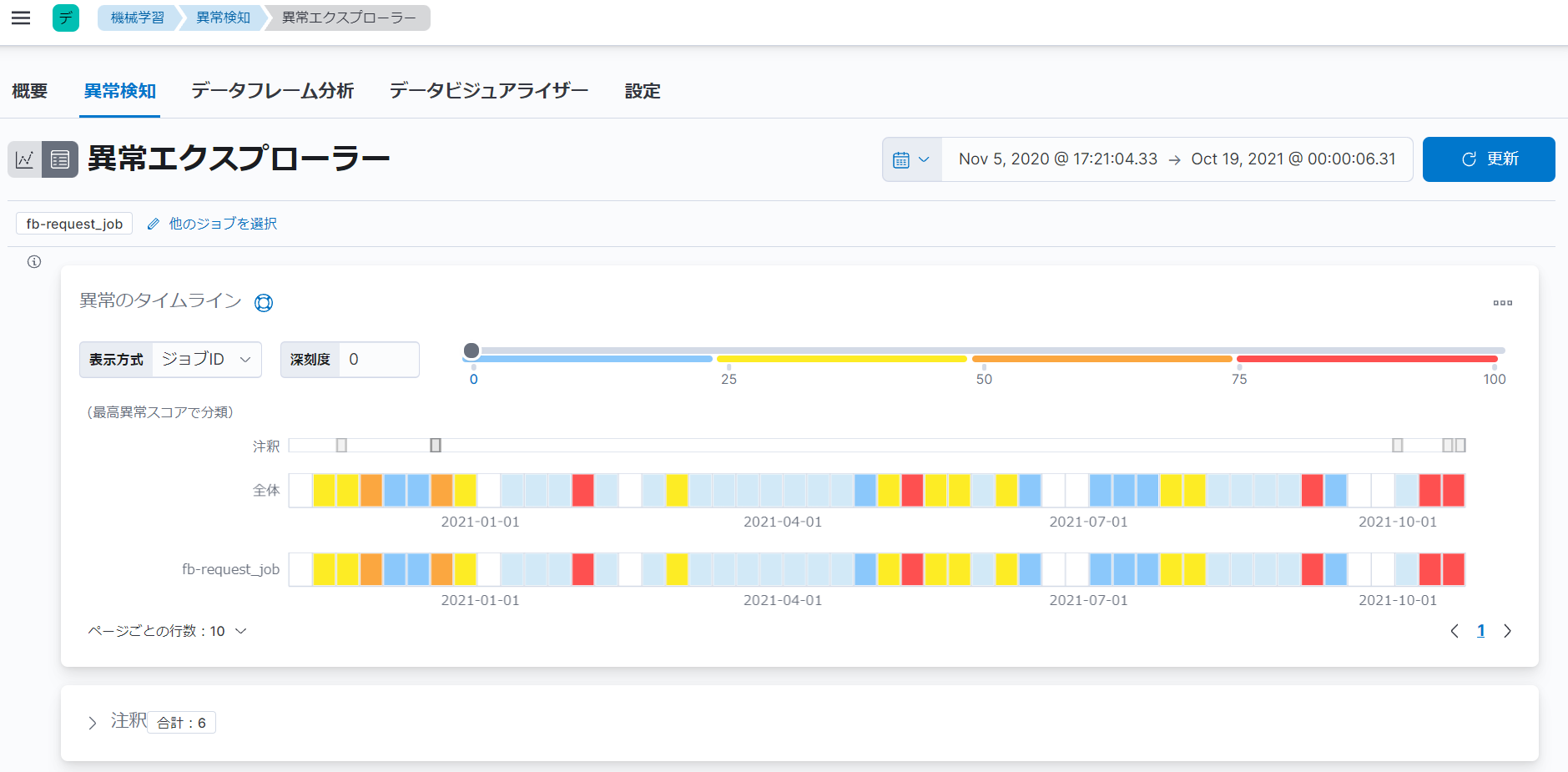
異常エクスプローラーには、「異常のタイムライン」と「異常」という2つの項目があります。
「異常のタイムライン」という項目では、スイムレーンが表示されます。スイムレーンは、選択した期間内に分析されたデータのバケットの概要を表します。全体的なスイムレーンを表示するか、ジョブまたは影響因子別に表示することができます。スイムレーンの各ブロックは、深刻度別に色分けされています。深刻度の値は、0~100であり、以前に異常として検知されたデータと比較してどれだけ異常かを表します。深刻度の色は、深刻度の値に基づき、青(0~25)、黄(25~50)、橙(50~75)、赤(75~100)のいずれかで表示されます。
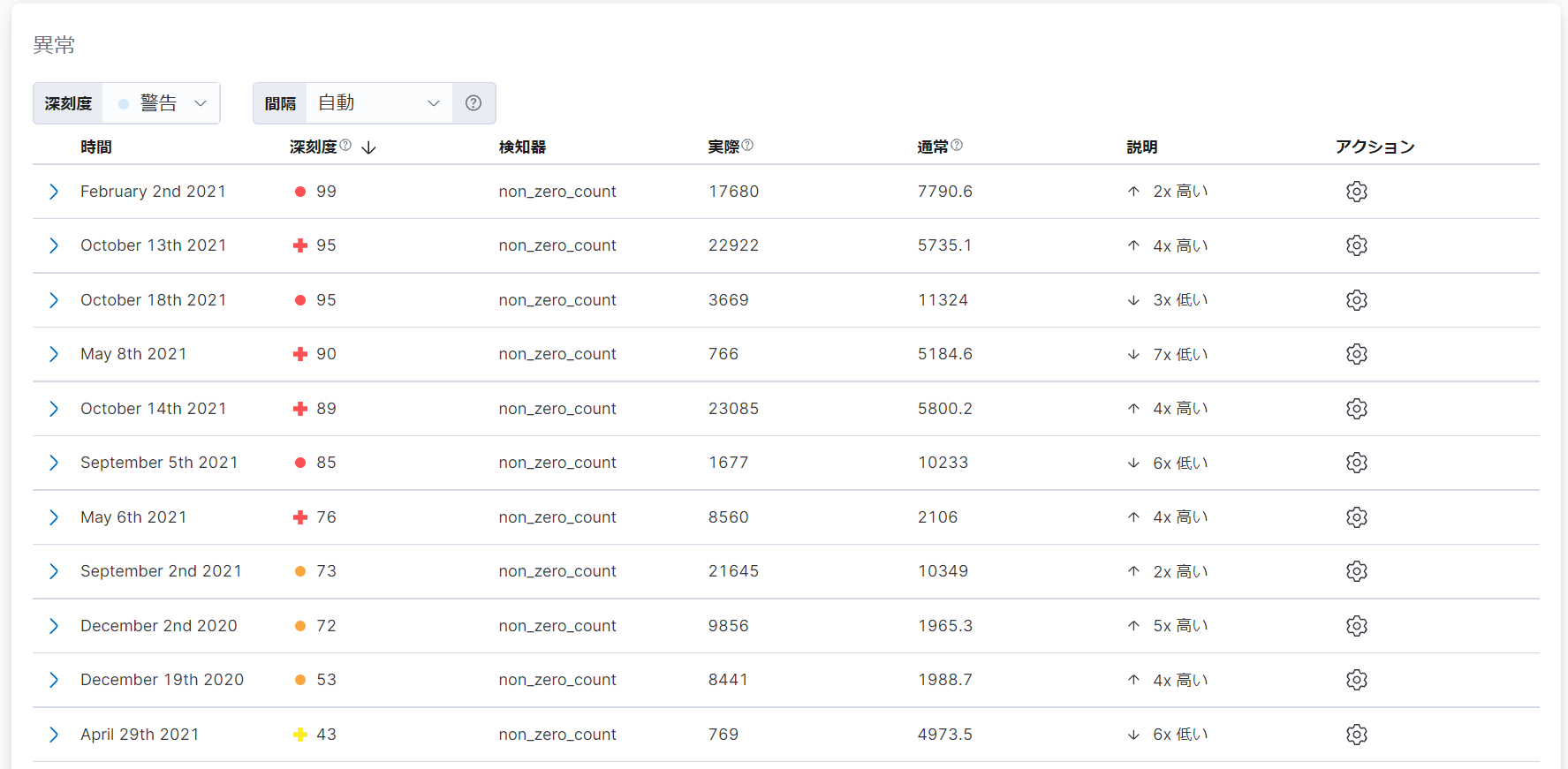
「異常」という項目では、前述のシングルメトリックビューアーの「異常」という項目と同様に、検知された異常が深刻度の高い順にリストで表示されます。
同様に、表示された行の左端にある「>」をクリックし、異常の詳細を参照することもできます。
これで、異常検知結果の表示が完了しました。
予測の作成
異常検知結果の表示が完了したら、最後に、予測の作成を行います。
シングルメトリックビューアーで、「予測」(下図赤枠)をクリックします。

「予測」(上図赤枠)をクリックすると、予測期間の設定画面が表示されます。
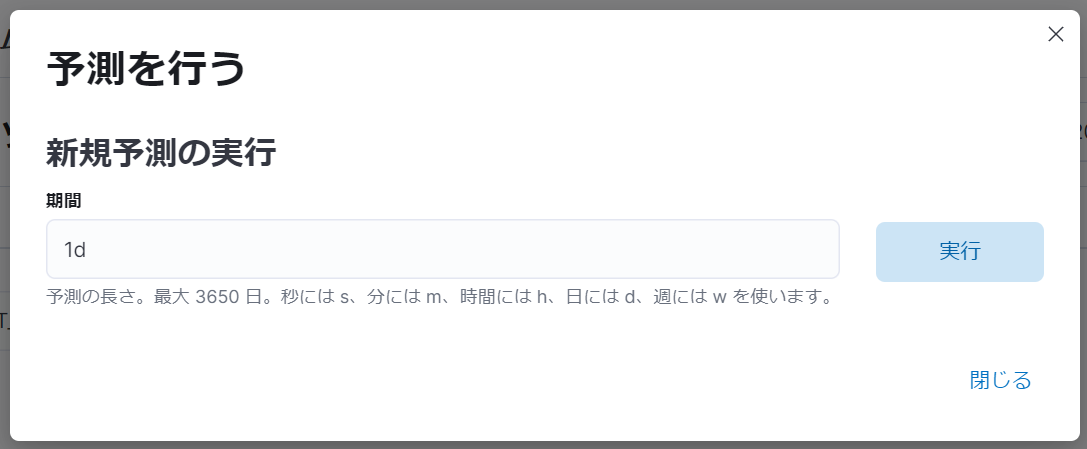
予測期間の設定画面では、新規予測の実行に関して、期間を設定します。期間には、「1d」(1日)がデフォルトで設定されています。
今回の例では、期間に「1w」(1週間)を設定します。
期間を設定したら、「実行」をクリックします。「実行」をクリックすると、シングルメトリックビューアーの「count の単独時系列分析」という項目のグラフに、予測の表示が追加されます。
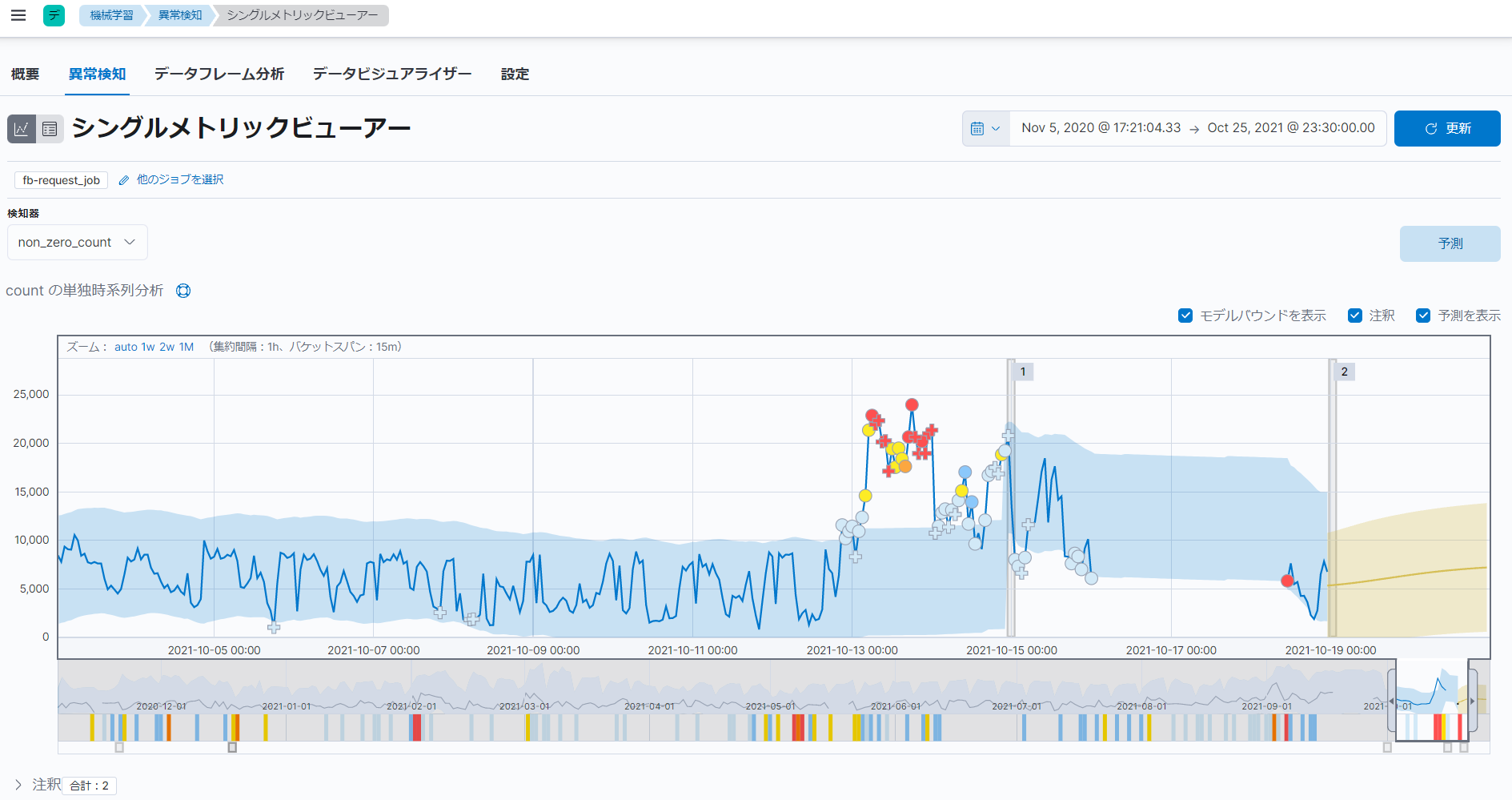
グラフの黄色の線は、予測されたデータの値を表しています。グラフの黄色の網掛け領域は、予測の範囲を表しています。
これで、予測の作成が完了しました。
なお、ご参考ですが、ここからさらに、実際のデータと予測のデータを比較することもできます。つまり、今回の例でいうと、1週間後の実際のデータと今回作成した予測のデータを比較することもできるということです。グラフには、実際のデータの値(青色の線)、データの期待値の範囲(青色の網掛け領域)、異常、予測されたデータの値(黄色の線)、予測の範囲(黄色の網掛け領域)が含まれます。グラフを参照することで、機械学習機能「異常検知」がデータの将来の動作をどの程度の精度で予測できているかを確認することもできます。
おわりに
本記事では、Elasticの機械学習機能の概要と、機械学習機能「異常検知」による教師なし機械学習に関して紹介しました。
Elasticの機械学習機能は、ボタンをクリックするだけの簡単な操作で、運用性に優れた機械学習を実現しています。皆さんもElasticの機械学習機能をぜひ試してみてください。