株式会社 日立製作所 藤井 智明
2021年よりElastic Stackに関する社内での技術支援に携わっています。最近の技術支援において、Elasticの機械学習を活用する興味深い取り組みに関わることができました。本記事では、その技術支援で得られた知見に関して紹介したいと思います。
はじめに
前回に引き続き、機械学習機能を紹介します。今回は、「データフレーム分析(分類)」による教師あり機械学習に関して紹介します。7.13で正式にリリースされた新しいElasticの機械学習機能です。機械学習の実行には、有償のライセンスが必要になるため、今回はお試しの30日間無料トライアルを使用します。
「Stack Management」の「License Management」を選択して、「Start a 30-day trial」ボタンをクリックして始めます。
利用するデータセット
Elastic Stackにはサンプルデータがいくつか用意されており、今回は「Sample flight data」を利用します。
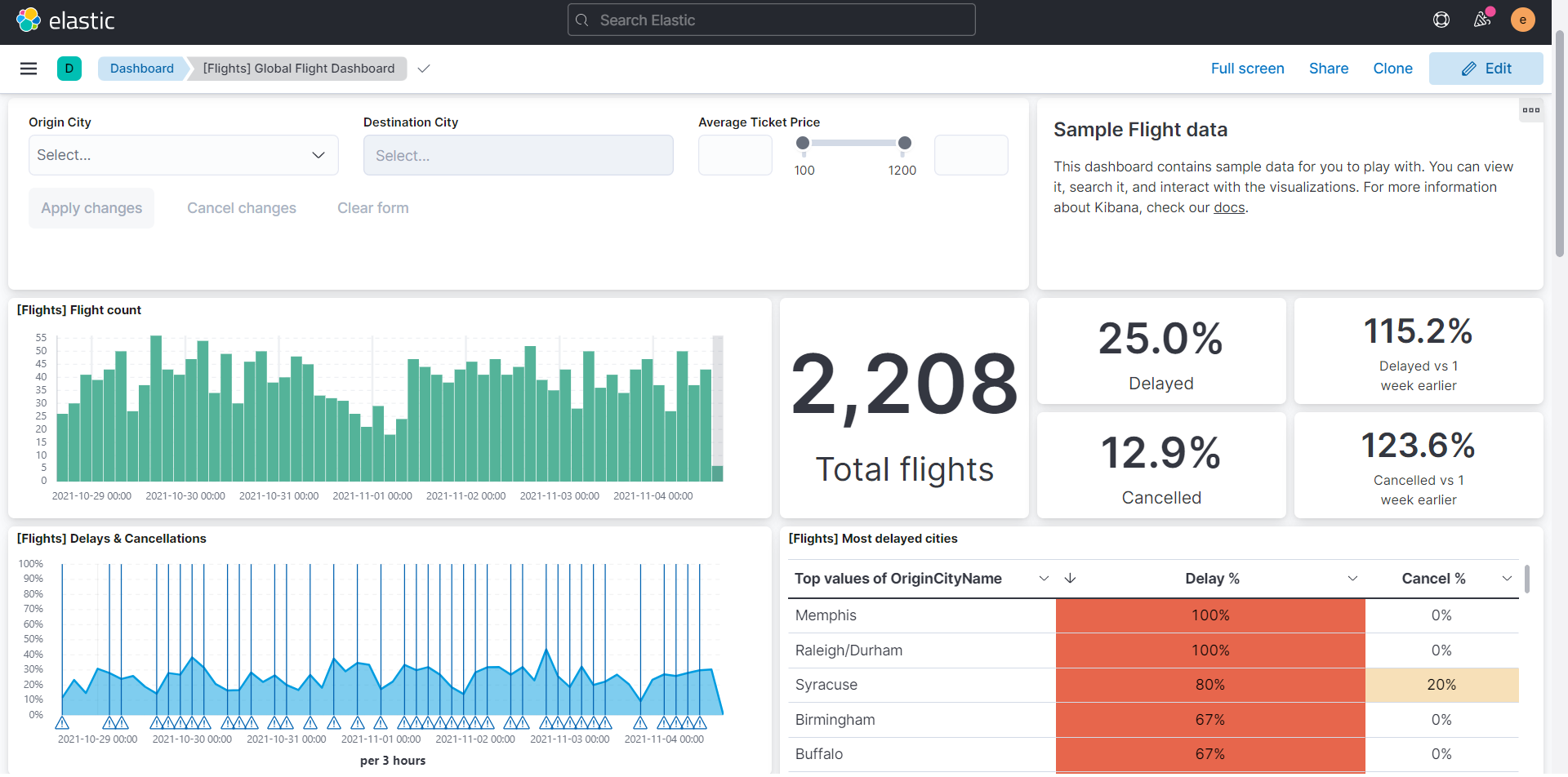
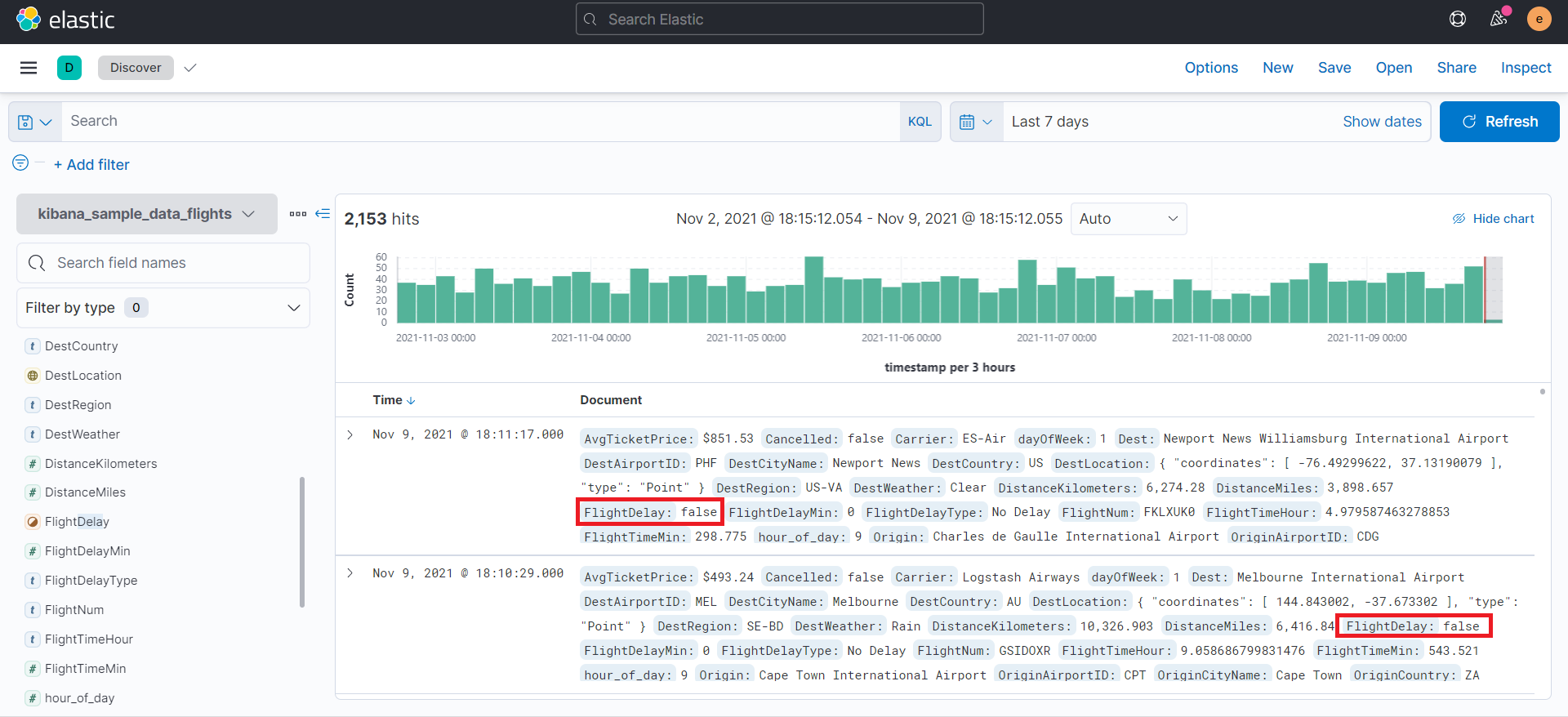
このサンプルデータはダッシュボードの例のように4つの航空会社のフライト数や遅延率、キャンセル率、遅延のタイプ、天候などの様々なデータや画面が用意されています。
<ダッシュボードの例1>
フライト数や、遅延率、キャンセル率など
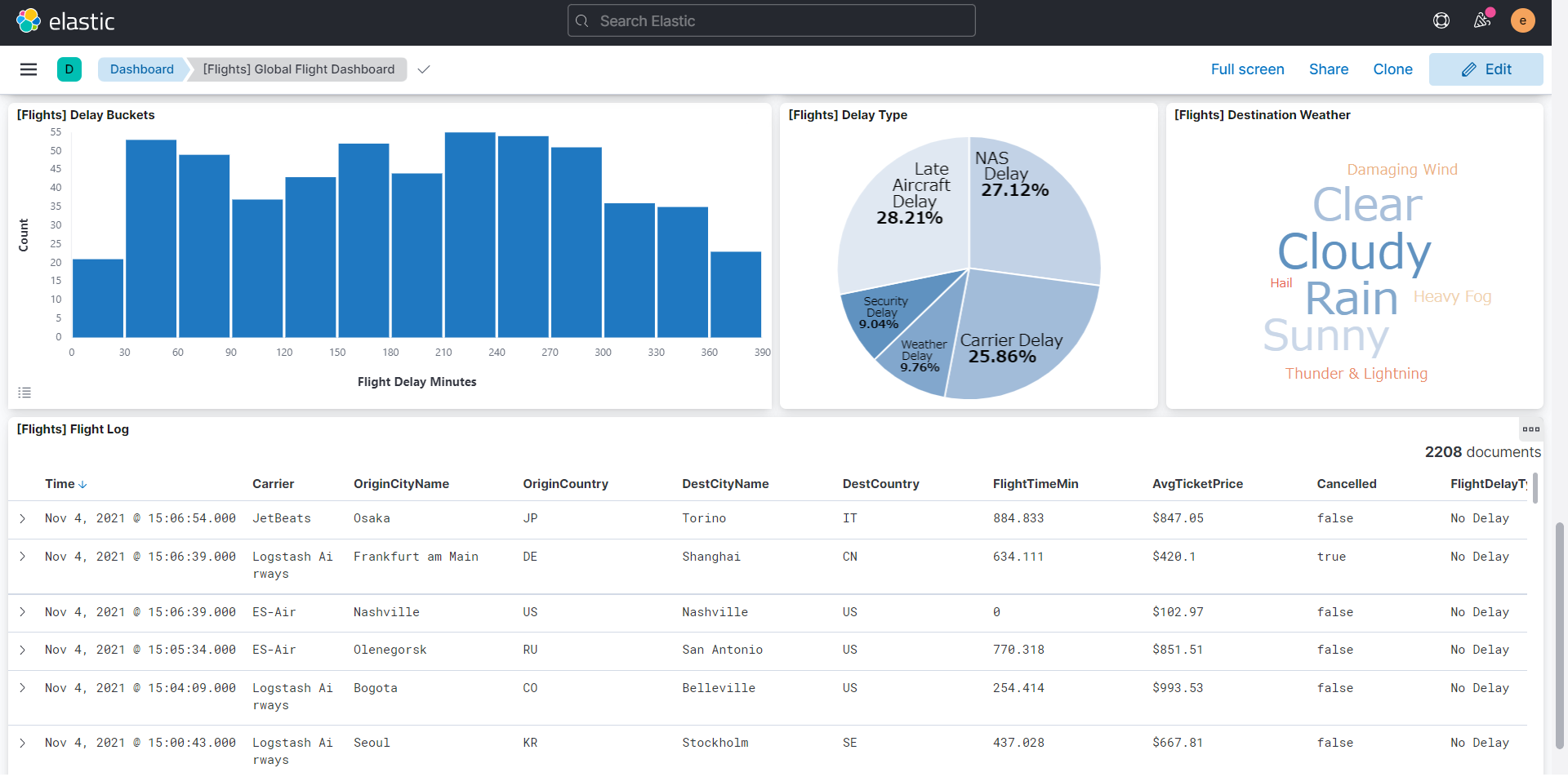
<ダッシュボードの例2>
遅延のタイプや、天候状況、フライトの詳細ログなど
サンプルデータには、フライトが遅延したかどうかのフラグに該当するデータ(true/false)が含まれているため、フライトの遅延をデータフレーム分析で分類してみたいと思います。
データフレーム分析(分類)は、正解を含むデータを与えることで、そのほかのデータで正解データを導き出せるかを学習し予測してくれます。これにより、サンプルデータ内にフライトの遅延を事前に予測できるデータがあれば、遅延を予想することができます。
サンプルデータの追加方法は下記の公式サイトを参照しました。
Get up and running with sample data
データフレーム分析ジョブの作成
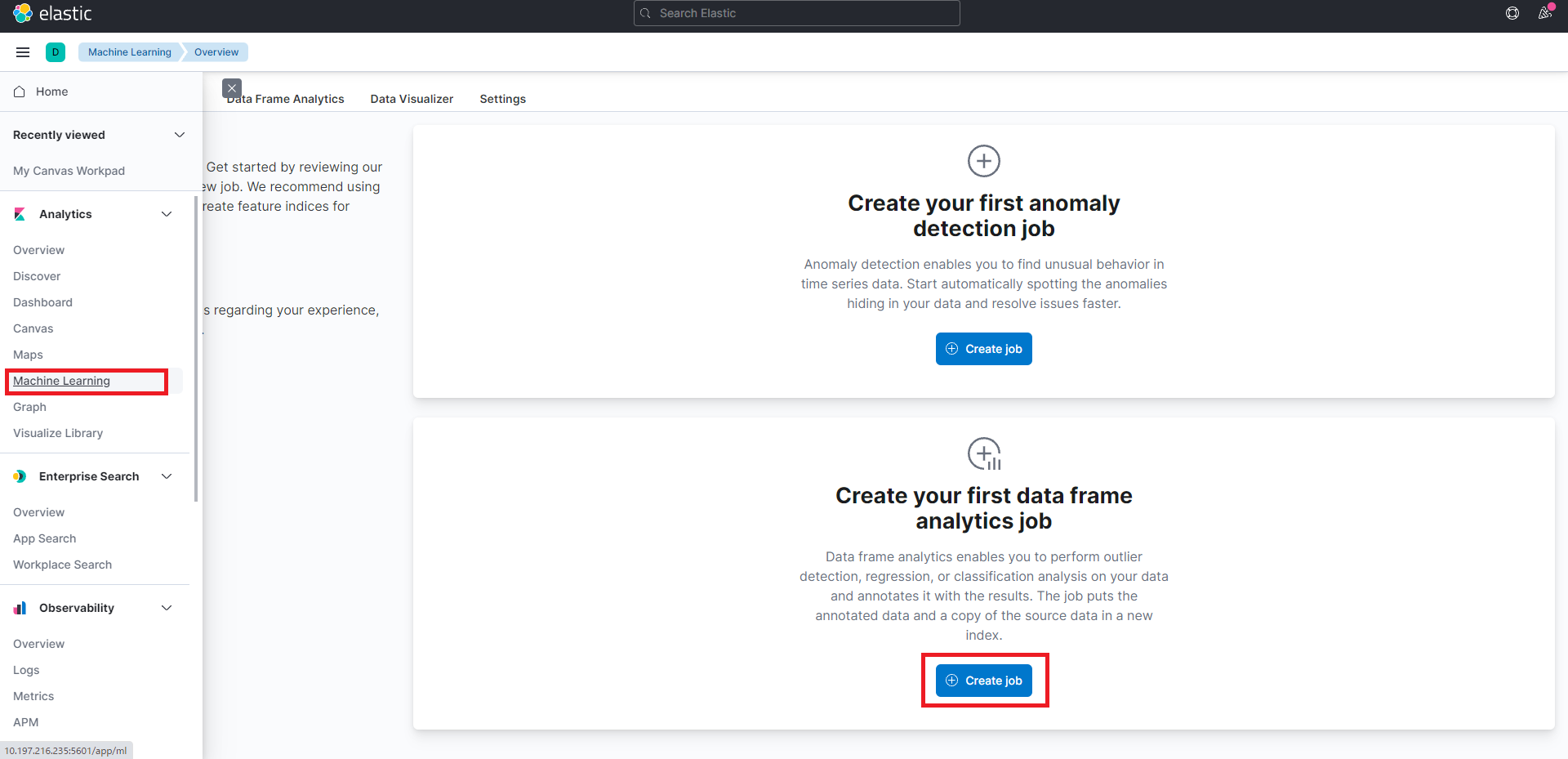
では早速、機械学習のジョブの作成を行っていきたいと思います。KibanaからMachine Learningを選択すると、下記の画面に遷移します。新しくデータフレーム分析ジョブを作成するために、下のCreate your first data frame analytics jobをクリックします。
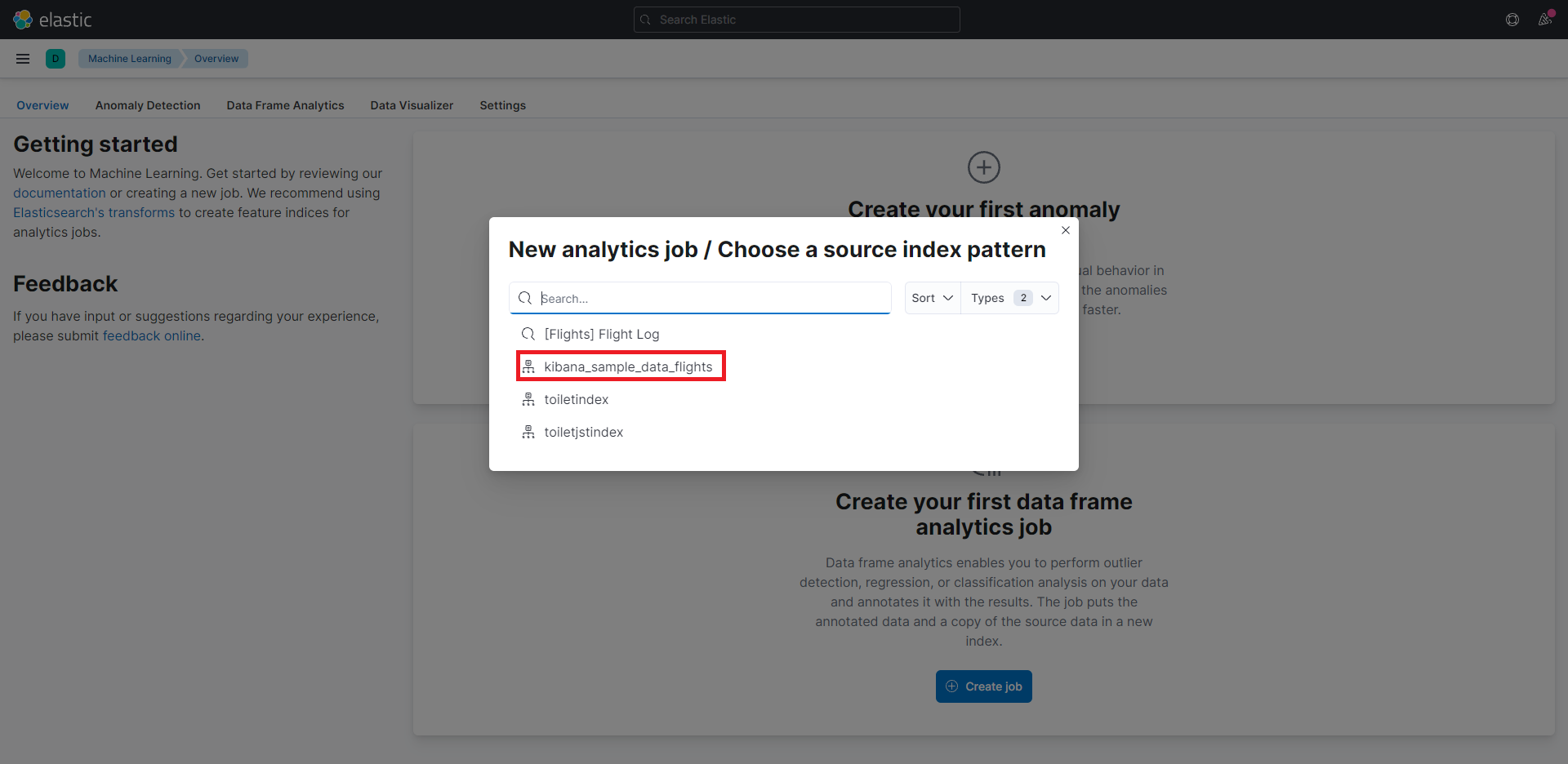
すると、下記の画像のように分析したいindexを選択する画面が表示されるので、先ほど追加した「kibana_sample_data_flights」を選択します。
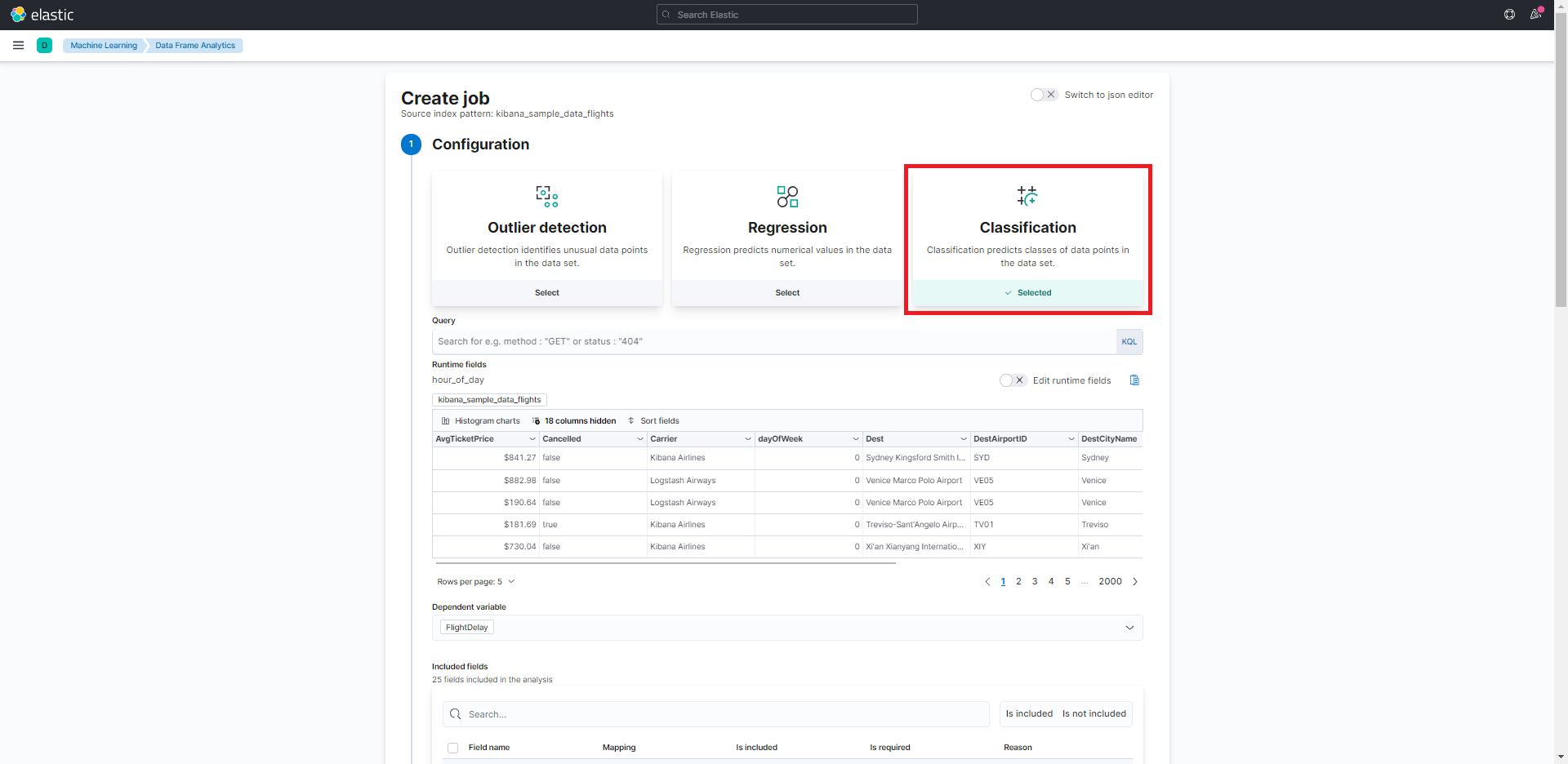
以降で機械学習の設定をしていきます。
教師あり機械学習の開始
上記までの手順を踏むと、下記の画像のように機械学習を設定する画面に遷移します。今回は、「Classification(分類)」を試してみました。
設定については、下記の公式サイトを参照しました。
Predicting delayed flights with classification analysis
「Classification(分類)」を選択します。
「Dependent variable」(従属変数)には、予測したいフィールドを選択します。選択するフィールドは、正解データを含む必要があります。今回は、遅延したかどうかを予測したいため、true/falseのデータを持つ「FlightDelay」を選択します。
また、トレーニングデータの割合である「Training percent」は、デフォルトの80%のままとします。この場合、データの80%が学習に利用され、残りの20%が正答率の確認に利用されます。
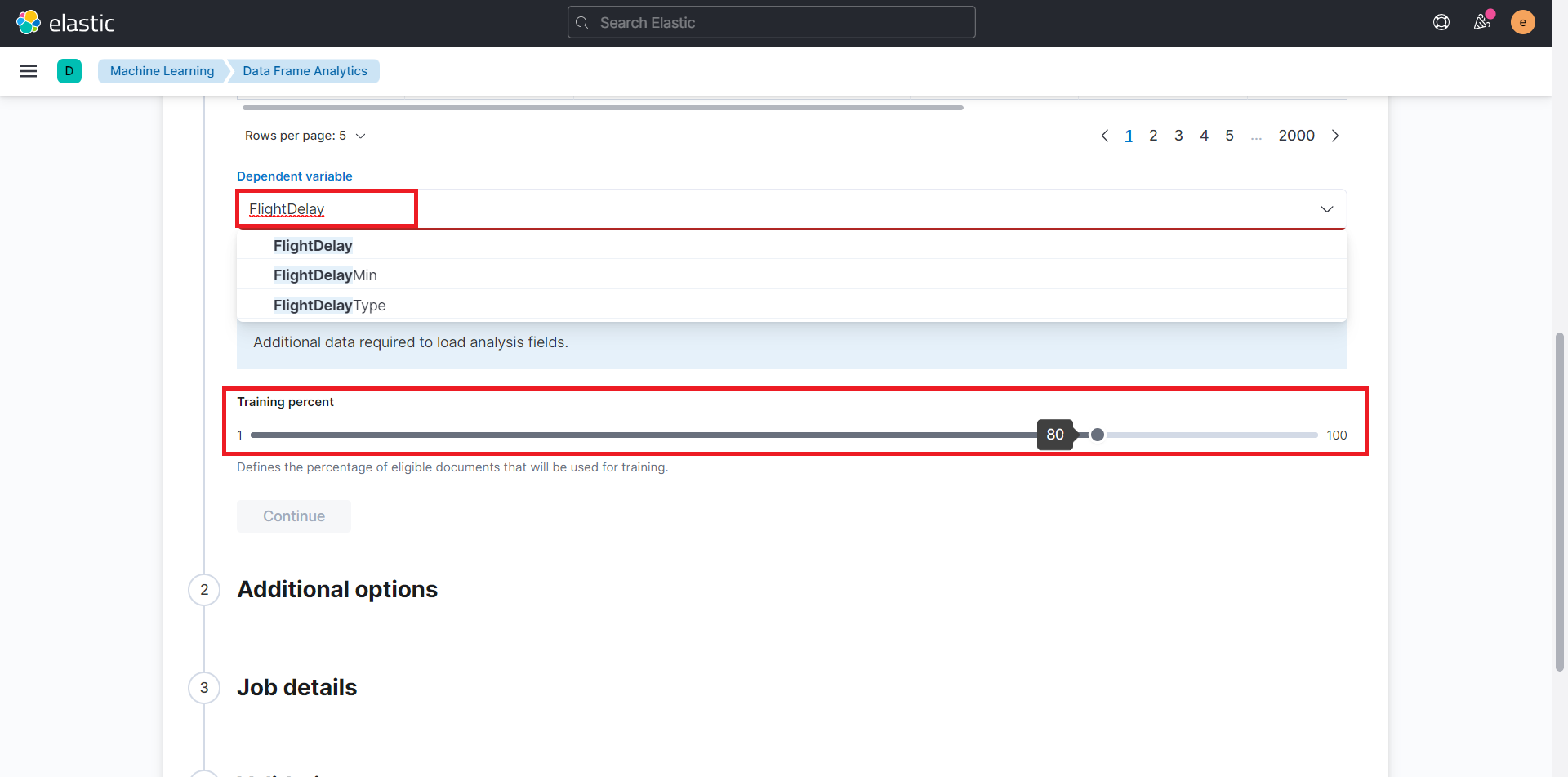
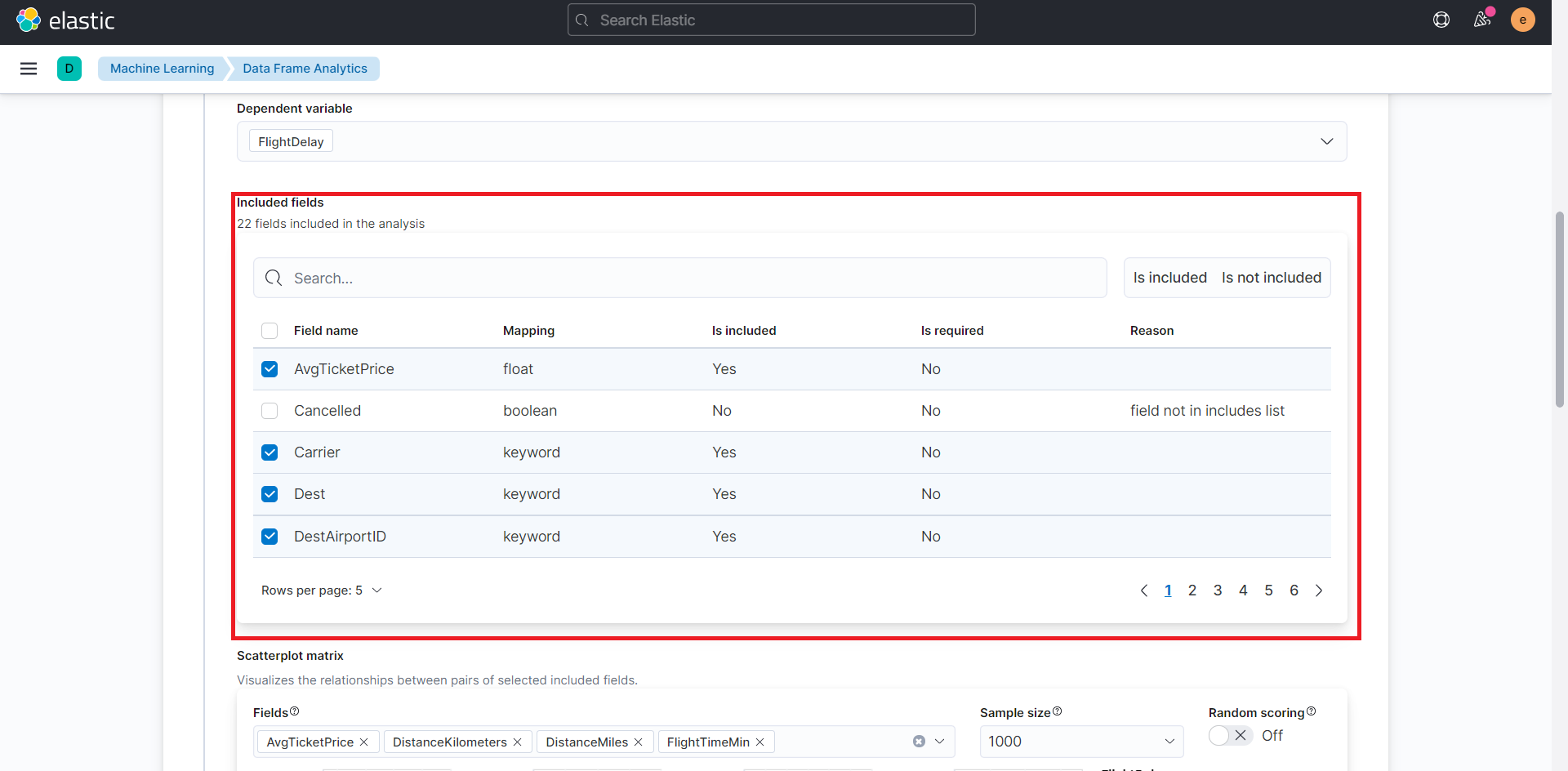
次に正解データを導くフィールドと関係のない「Cancelled」および正解データに付随する情報である「FlightDelayMin」「FlightDelayType」を学習範囲から除くために、チェックを外します。
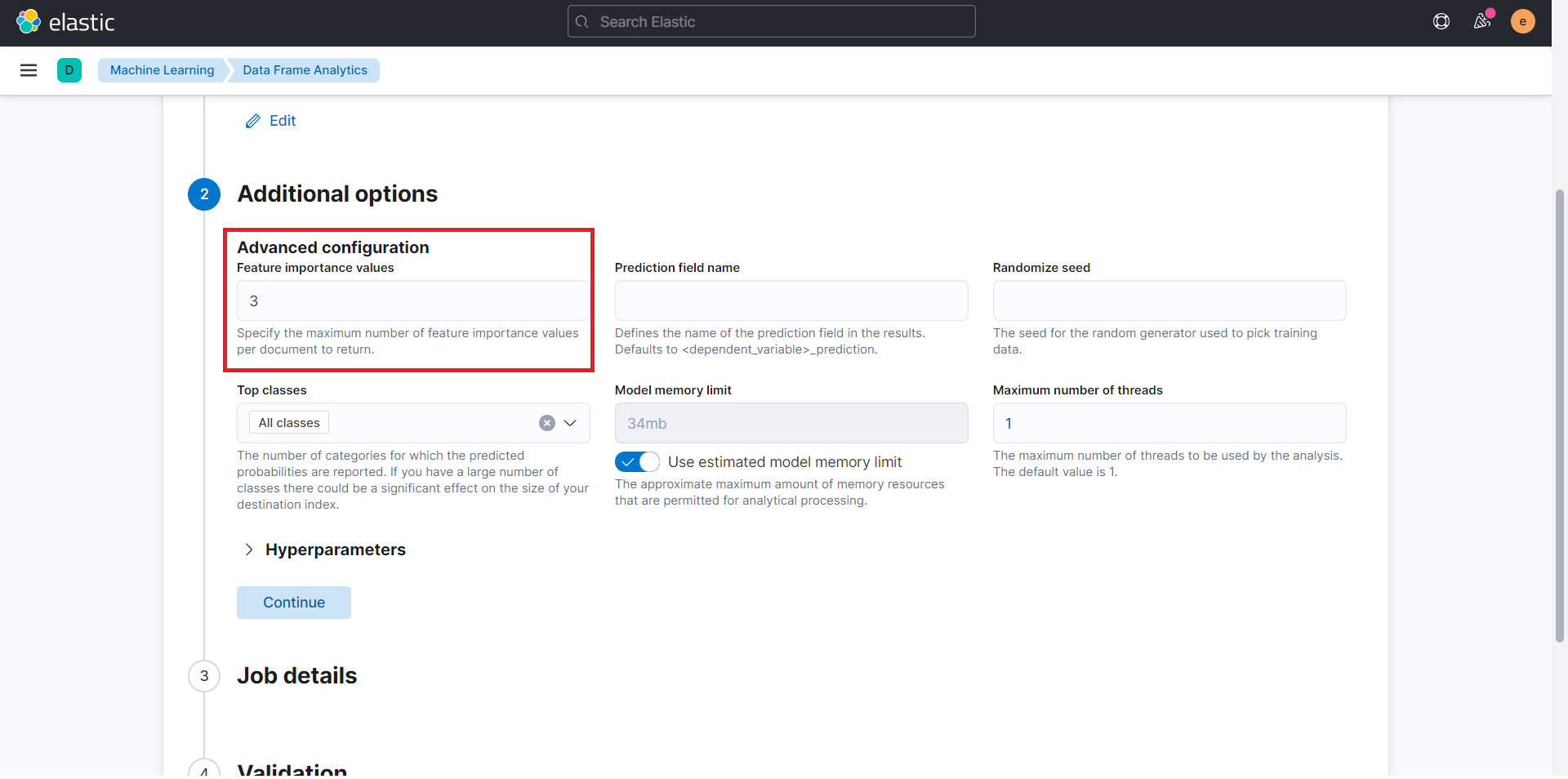
特徴量の重要度の値を設定しておくことで、機械学習で影響の大きかったフィールドを計測してくれます。処理に時間が掛かるため、3までに設定するのが良いようです。このため、今回は「3」を設定します。
ジョブIDに「model_flight_delay」を設定します。
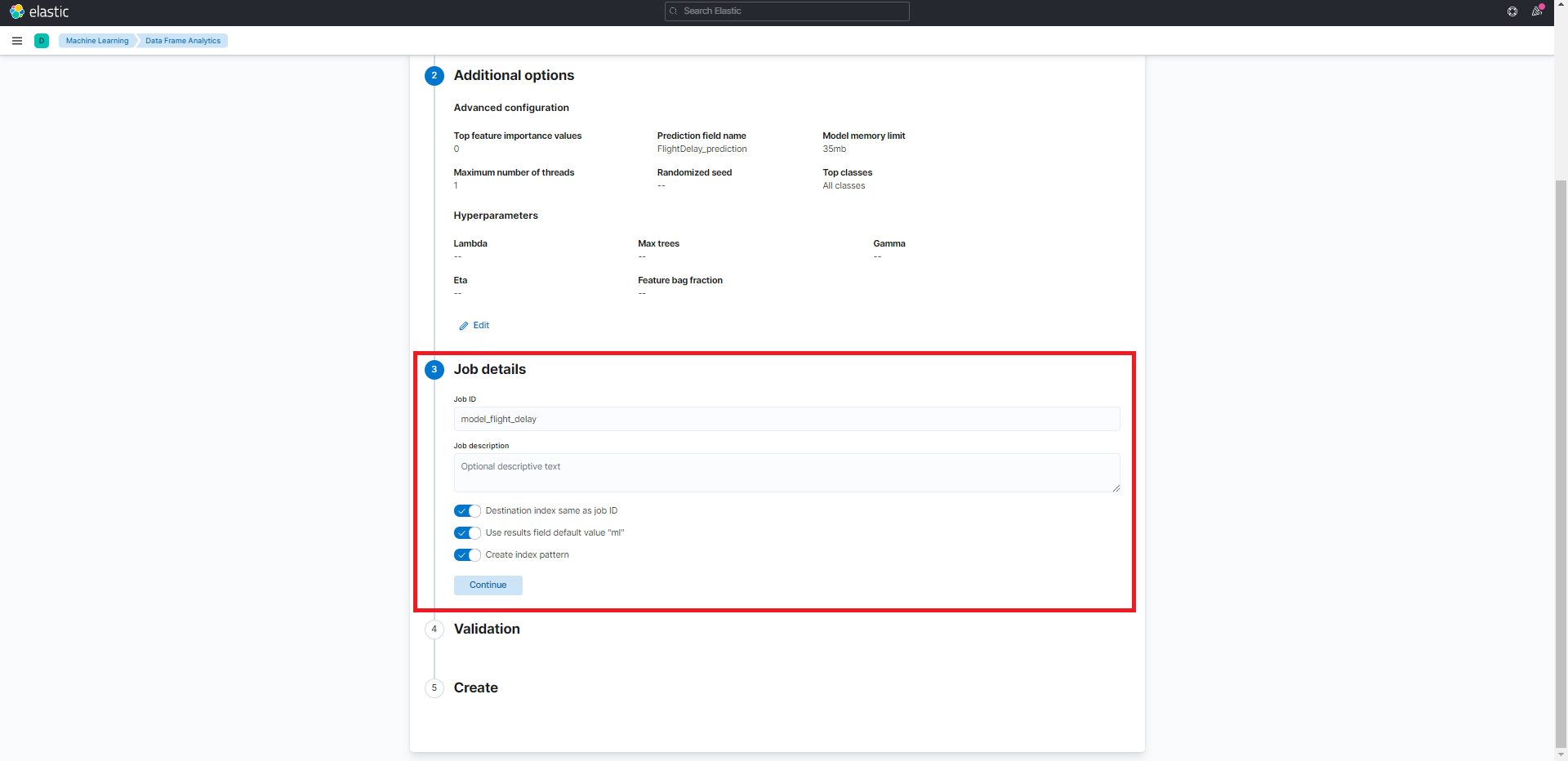
ジョブの実行前に自動的にチェックしてくれます。今回は、特徴量の重要度の値を設定したことにより、実行時間が掛かる恐れがあることを警告してくれています。
設定が終わったので、ジョブの作成を実行します。
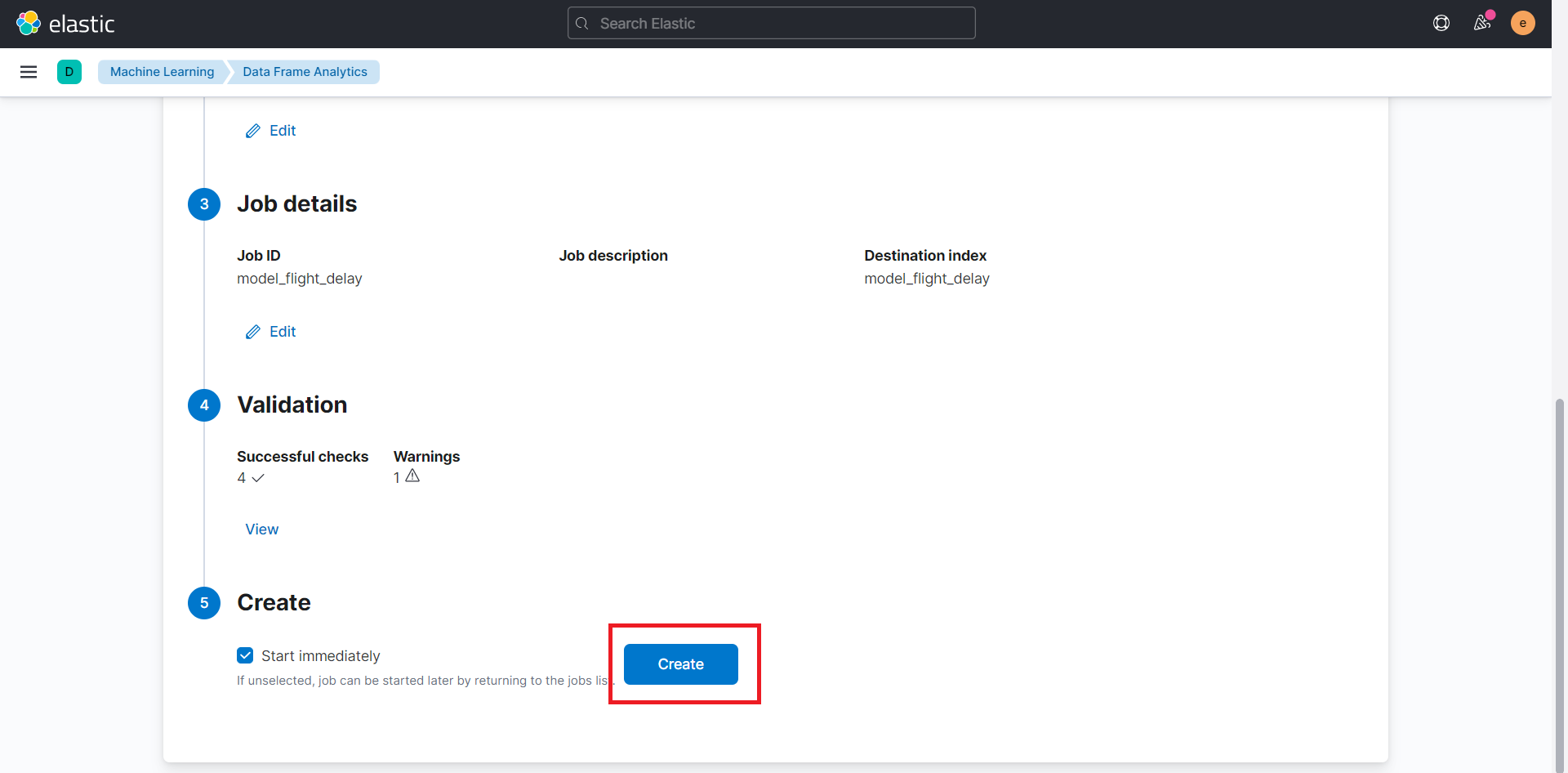
すべての処理が完了すると、結果を表示できます。
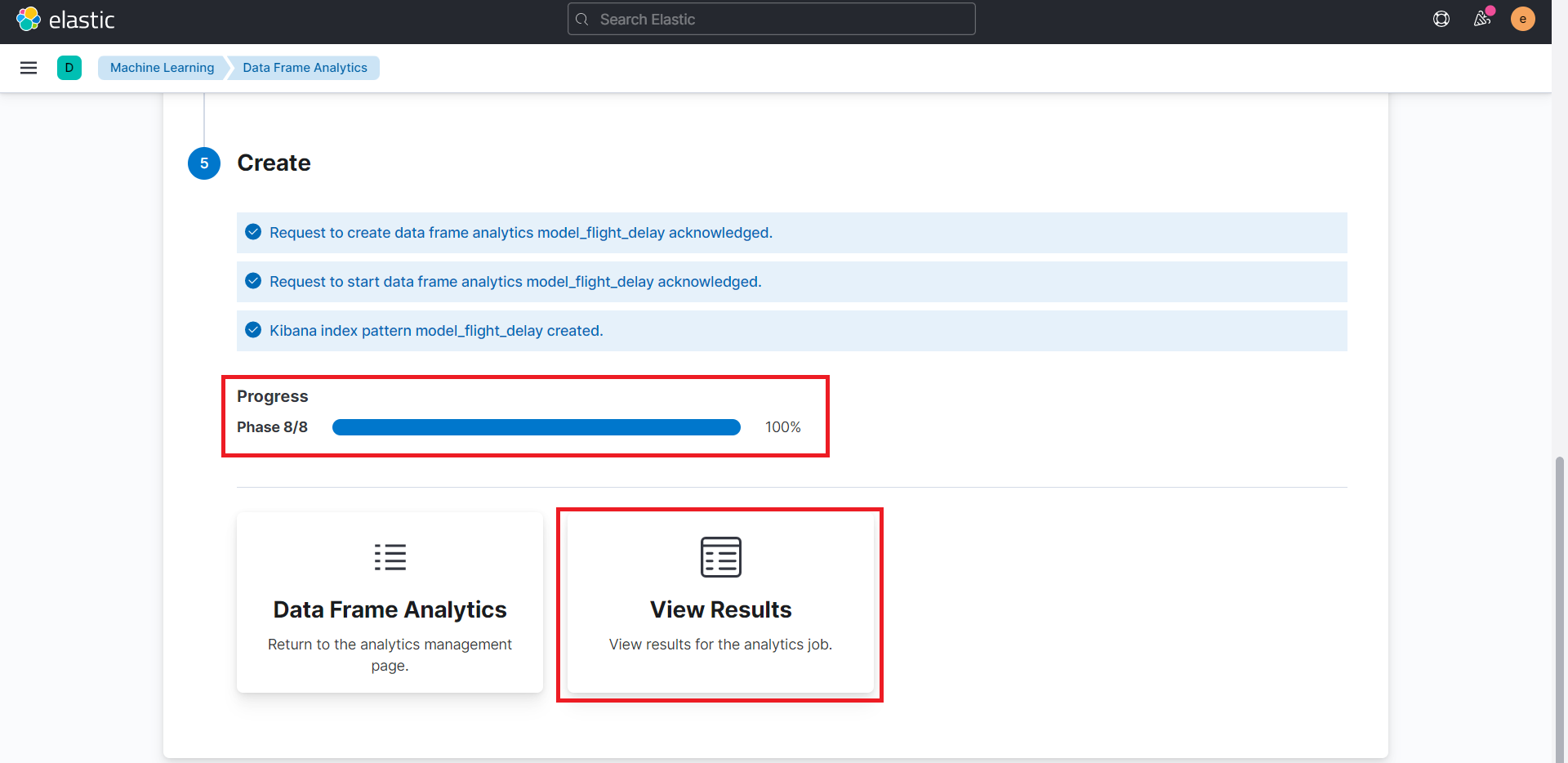
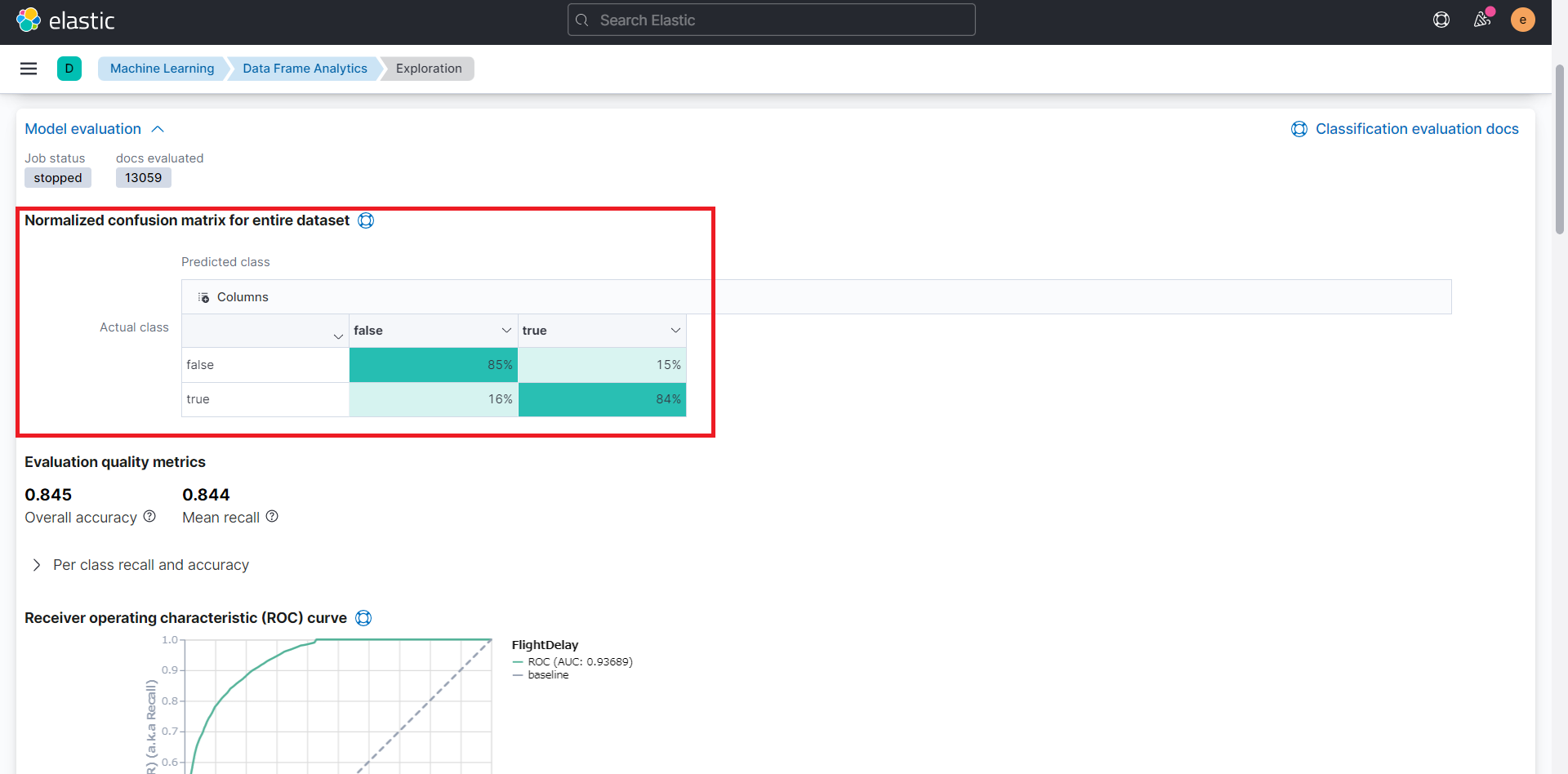
結果の表示
分析結果では、トレーニングおよび結果の確認で利用されたドキュメント数を確認することができます。
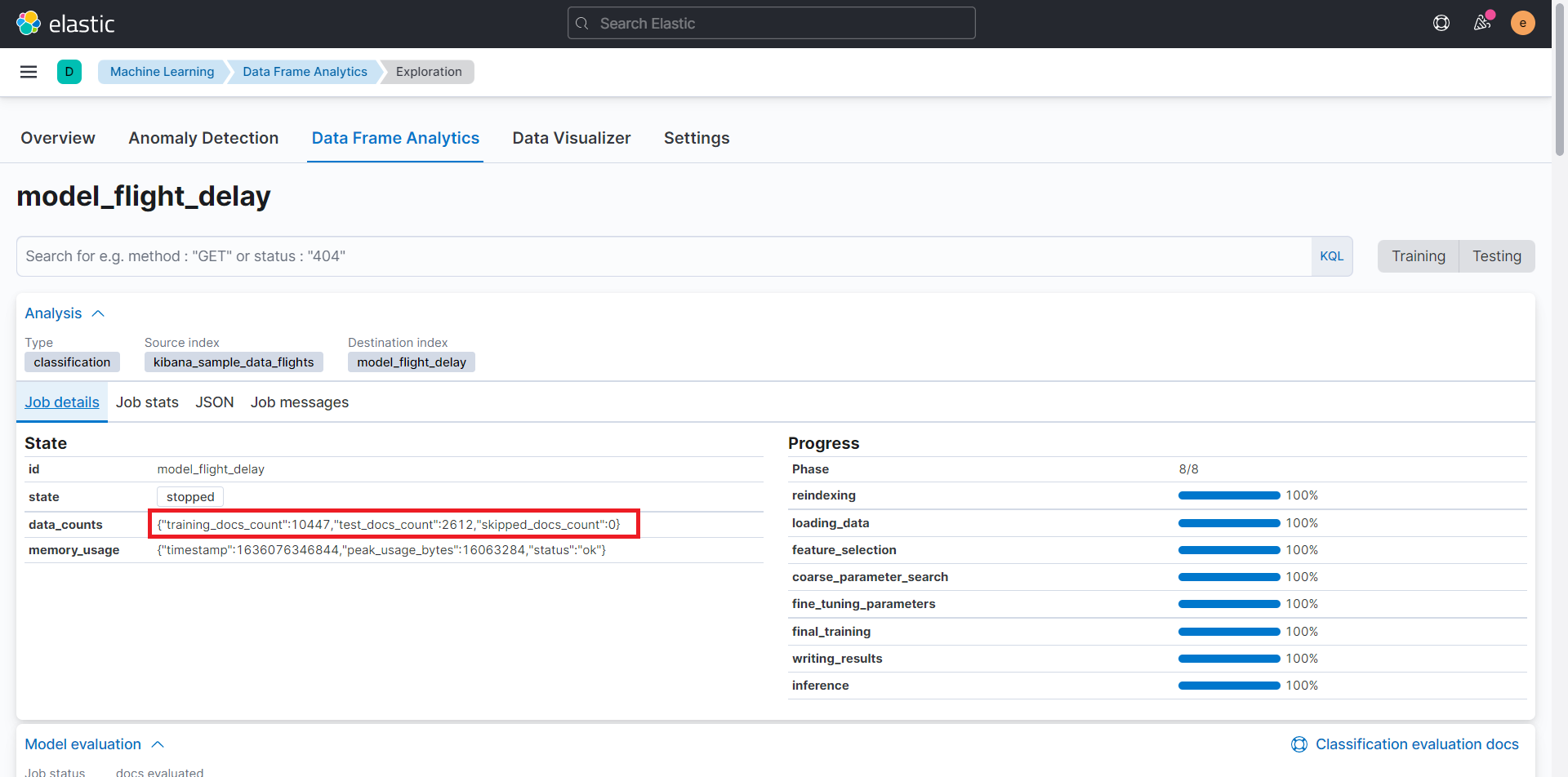
正答率を確認できます。約80%で遅延かどうかを予測することができました。
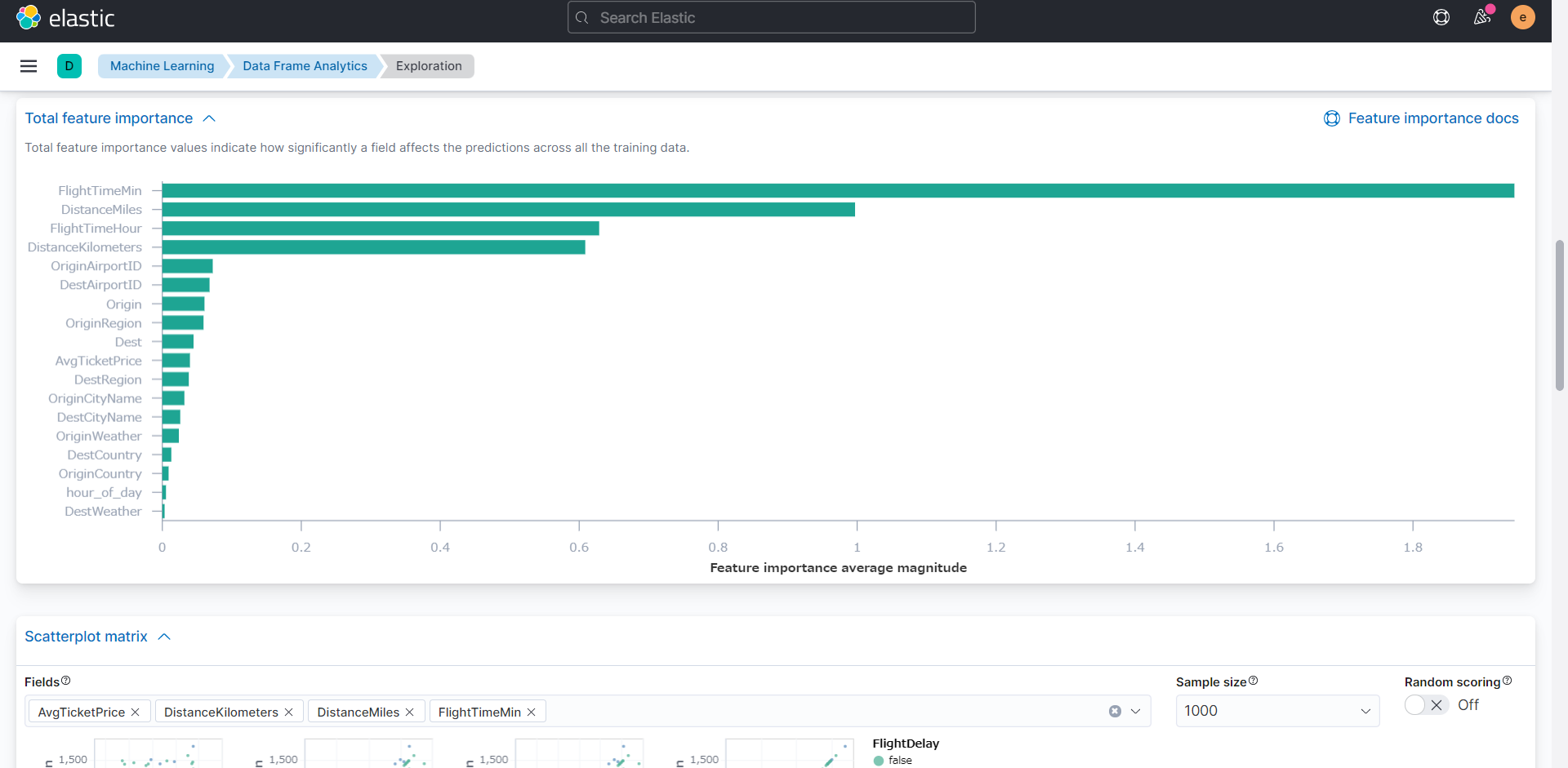
特徴量の結果より、「FlightTimeMin」や「DistanceMiles」、「FlightTimeHour」、「DistanceKilometers」など、飛行時間や飛行距離が遅延の要因となっていることが確認できます。
おわりに
今回は予測したいデータ(遅延かどうかのtrue/falseデータ)とその他のフライトのデータ(フライトの時間や距離、天候、出発地、到着地、チケット代など)から、新機能である「データフレーム分析(分類)」を用いて、遅延かどうかの予測を試しました。分析結果では、遅延かどうかを約80%の確率で予測することができました。またその予測の要因となったデータも抽出することができました。
上記分析を、プログラミング無しでブラウザ上で機械学習を実行できました。予測したいデータのフィールドを持つインデックスがあると簡単に適用できそうなので、機械学習に興味のある方はぜひお試しください。