はじめに
WebスクレイピングとQiitaのAPIを使って、Organizationの記事を一括でファボるPythonスクリプトを書いてみたので、書き方や苦労した点などについてまとめてみました。
- 動作環境
- Python 3.11.0
流れ
以下の流れになります。
- Qiitaの個人用アクセストークンを取得
- Webスクレイピングで該当Organizationの記事一覧のページから記事情報(記事ID)を取得
-
/api/v2/items/:item_id/likeAPIでそれぞれの記事に対していいねをつける
苦労したこと
そもそも、なぜWebスクレイピングでOrganizationの記事情報を取得するかと言うと、色々調べた結果、Organizationに紐ついている記事の情報を取得するAPIが見つからなかったからです。(ご存じの方がいらっしゃったらぜひご教示いただきたい)
ちなみにChatGPT先生にも聞いたのですが、何度もブチ切れそうになりました。以下、ChatGPT先生との会話。

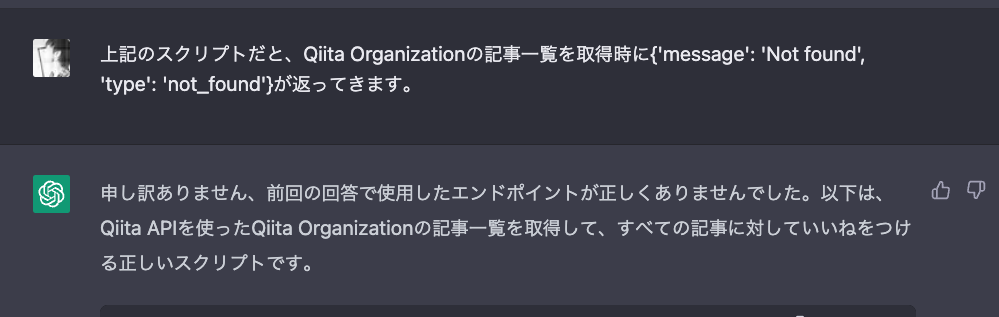
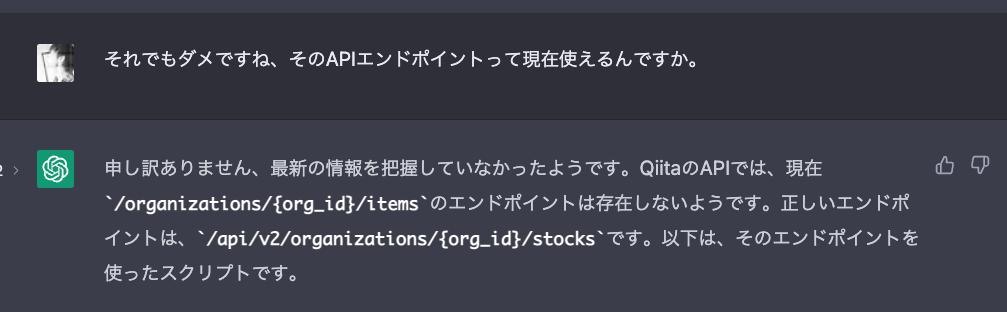



「いやいやいや、全く頼りにならない...それならスクレイピングの方がはやい」って思った経緯があります。
ただ、スクレイピングの場合は、htmlタグの仕様が変更されたらスクリプトを修正する必要あるので、ご注意ください。
アクセストークンの取得
いいねをつけるAPI利用時にQiitaの個人用アクセストークンが必要なので、取得しておきます。
Qiitaアカウントの設定画面を開き、右側のメニューから「アプリケーション」をクリックします。「新しくトークンを発行する」をクリックします。

トークン名と必要な権限をつけます。今回は「read_qiita」と「write_qiita」を選択します。

「発行」をクリックするとトークンが表示されます。一回しか表示できないのでメモしておきましょう。
Organizationの記事情報の取得
ではPythonスクリプトを書いていきます。外部ライブラリですが、requestsとbs4というライブラリを使いますので、インストールされていない場合は事前インストールが必要です。
まず記事情報取得時に以下のURLが必要になります。
https://qiita.com/organizations/OrganizationのID/items
さらにクエリパラメータでpage数を指定する必要もあります。
こんな感じです。
https://qiita.com/organizations/xxxxxxxx/items?page=1
以下の属性のscriptタグから記事情報jsonを取得できます。
type="application/json"
data-component-name="OrganizationsItemsPage"
該当情報を取得してみます。
import json
import requests
from bs4 import BeautifulSoup
url = "https://qiita.com/organizations/xxxxxxxx/items?page=1"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
items = soup.find(
"script",
{"type": "application/json", "data-component-name": "OrganizationsItemsPage"},
).get_text()
print(items)
以下のjsonが出力されます。
{
"organization": {
"paginatedOrganizationArticles": {
"items": [
{
"encryptedId": "xxx",
"isLikedByViewer": false,
"isStockableByViewer": true,
"isStockedByViewer": false,
"likesCount": 1,
"linkUrl": "xxx",
"publishedAt": "xxx",
"title": "xxx",
"uuid": "xxx",
"author": {
"profileImageUrl": "xxx",
"urlName": "xxx",
"name": ""
},
"organization": {
"name": "xxxxxxxx",
"urlName": "xxxxxxxx"
},
"followingLikers": [],
"recentlyFollowingLikers": [],
"tags": [
{
"urlName": "xxx",
"name": "xxx"
},
{
"urlName": "xxx",
"name": "xxx"
}
]
},
{
...省略...
},
{
...省略...
}
]
}
}
}
いいねAPIを叩く時、記事ID(uuid)を取り出せばOKです。
いいねをつける
以下のAPIを使います。
PUT /api/v2/items/:item_id/like
こんな感じです。
headers = {"Authorization": "Bearer アクセストークン"}
data = json.loads(items)
items = data["organization"]["paginatedOrganizationArticles"]["items"]
for item in items:
item_id = item["uuid"]
like_endpoint = f"https://qiita.com/api/v2/items/{item_id}/like"
response = requests.put(like_endpoint, headers=headers)
実際すべての記事を取得していいねをつける際に、すべてのページ(クエリパラメータの「page」で調整)に対して行う必要があります。
完成したスクリプト
ORG_ID(Organization ID)とACCESS_TOKEN(個人用アクセストークン)の値はハードコーディングではなく、環境変数から取得するようにしています。
bashなどの場合は、以下のコマンドで環境変数をセットします。
$ export ORG_ID=xxx
$ export ACCESS_TOKEN=xxxxxxxx
スクリプトを実行すると
$ python3 main.py
記事IDとレスポンスが出力されます。
5a60e7dc4b43654181f9
{"message":"Already liked","type":"already_liked"}
147ba578b83b8d7a8c93
{"message":"Already liked","type":"already_liked"}
2da21e6e3ee3bd542e92
ebae7787546716957ff0
6dfa48ee22c724f408c6
f4295840833156f0af29
16f1712580c2e7c81080
6638dea4521c8f50517f
...
...
以下、完成したスクリプトです。
※API実行制限があるため、記事が多い場合実行しきれない場合があります。
import json
import os
import requests
from bs4 import BeautifulSoup
ORG_ID = os.environ["ORG_ID"]
ORG_URL = f"https://qiita.com/organizations/{ORG_ID}/items"
ACCESS_TOKEN = os.environ["ACCESS_TOKEN"]
HEADERS = {"Authorization": f"Bearer {ACCESS_TOKEN}"}
def main():
params = {"page": 1}
while True:
items = get_items_of_organization(ORG_URL, params)
if not items:
break
for item in items:
item_id = item["uuid"]
print(item_id)
like_items(item_id, HEADERS)
params["page"] += 1
def get_items_of_organization(url, params):
response = requests.get(url, params=params)
soup = BeautifulSoup(response.text, "html.parser")
items = soup.find(
"script",
{"type": "application/json", "data-component-name": "OrganizationsItemsPage"},
).get_text()
data = json.loads(items)
items = data["organization"]["paginatedOrganizationArticles"]["items"]
return items
def like_items(item_id, headers):
like_endpoint = f"https://qiita.com/api/v2/items/{item_id}/like"
response = requests.put(like_endpoint, headers=headers)
if response.text:
print(response.text)
if __name__ == "__main__":
main()
終わりに
今回は自動で記事にいいねをつけるスクリプトを作って動かしてみたわけですが、やはり時間があるときに、ちゃんと記事を読んでから手動でいいねをつけるようにしましょう!