Deel Learning初心者が勉強のため初心者向けに書いてみてます。
目標は各種画像解析をCNNなど使って解ける様になること。
deeplearning.aiが提供するCourseraのコースを学んで、
画像認識(講談社)を感動しながら一通り読み終えていよいよスタート!
0.利用する環境
Google Colabolatoryというサービスを利用します。Googleのアカウントを持っていればなんと無料で使えます!これを使うと環境構築を自分のPCにしなくても、Chromeさえあれば始められるという...なんと便利な時代なんでしょう。提供されているCPUも私の2011年版MACより上ですし、かつGPUまでモード変更で使えます。仕組みはブラウザ上でpythonコードを記述/実行していくJupyterの様な仕組みです。
1.MNISTデータの取得
sklearnを利用してhttp://mldata.orgから取得します。
import numpy as np
from sklearn import datasets
mnist = datasets.fetch_mldata('MNIST original') # この命令だけでデータダウンロードされます
2.データの確認
データの中身を確認してみましょう。
MNISTデータは画像データ、ラベルデータ(画像に描かれた数字が何か)の組み合わせが、学習用に60000個、検証用に10000個含まれています。
imagedata, labeldata = mnist.data,mnist.target
print("画像データ数:"+str(imagedata.shape))
print("ラベルデータ数:"+str(labeldata.shape))
結果:
画像データ数:(70000, 784)
ラベルデータ数:(70000,)
画像データ、ラベルデータとも合計70,000データあることが分かりました。画像データの2つ目の項目が784とあるのは、各画像には28*28=784pixel分の輝度データがあるということです。下記で画像データを画像化してみます。
import matplotlib.pyplot as plt
for i in range(1,11):
plt.subplot(1,10,i) # 横並びに表示するためのおまじない
plt.imshow(imagedata[(i-1)*6500].reshape(28,28),cmap='gray_r')
# データ内から適当な間隔(6500)で拾って、gray_rで白黒反転して表示してます
plt.show()
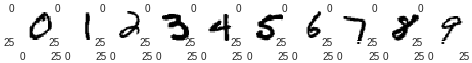
ところで、含まれているデータは各数字ぴったり同じではないんですね。ラベルデータ内の度数を見てみると各数字の個数にはばらつきがあります。5のデータが一番少なくて、1が一番多いんですね...約1500枚もの開きがあります。
whatsinlabel = set(labeldata)
print("ラベルデータに含まれる情報の種類: "+ str(whatsinlabel))
howmanylabels = { key: list(labeldata).count(key) for key in whatsinlabel} # 辞書として度数分布表を作る
print("ラベルデータに含まれる情報の頻度: "+ str(howmanylabels))
結果:
ラベルデータに含まれる情報の種類: {0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0}
ラベルデータに含まれる情報の頻度: {0.0: 6903, 1.0: 7877, 2.0: 6990, 3.0: 7141, 4.0: 6824, 5.0: 6313, 6.0: 6876, 7.0: 7293, 8.0: 6825, 9.0: 6958}
3.訓練データと検証データに分割
4/5を訓練データ、1/5を検証データとしてみます。データは頭から0のデータが6903個、1のデータが7877個...と並んでいますので、ランダムにシャッフルして利用します。sklearnの便利な関数でデータ分割が1行で済んじゃいます。
from sklearn.model_selection import train_test_split
imagedata_training,imagedata_validation,labeldata_training,labeldata_validation = train_test_split(imagedata,labeldata,test_size=0.2)
print("訓練画像データ数:"+str(imagedata_training.shape))
print("検証画像データ数:"+str(imagedata_validation.shape))
print("訓練ラベルデータ数:"+str(labeldata_training.shape))
print("検証ラベルデータ数:"+str(labeldata_validation.shape))
結果:
訓練画像データ数:(56000, 784)
検証画像データ数:(14000, 784)
訓練ラベルデータ数:(56000,)
検証ラベルデータ数:(14000,)
あたまから拾ってみてみましょう。
for i in range(1,11):
plt.subplot(1,10,i) # 横並びに表示するためのおまじない
plt.imshow(imagedata_training[i-1].reshape(28,28),cmap='gray_r')
plt.show()
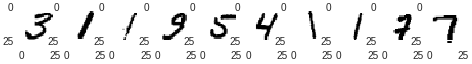
お、ちゃんとシャッフルされてますね。
4.学習と評価
4.1準備
# 256階調の輝度値を0-1の値に変換しておきます
imagedata_training = imagedata_training/255.
imagedata_validation = imagedata_validation/255.
4.2学習
import os
from sklearn.svm import SVC
import time
start = time.time() # かかった時間の計測のため計算開始時刻保存
clf = SVC()
clf.fit(imagedata_training, labeldata_training) # 学習
elapsed_time = time.time() - start # 計算終了時刻から計算時間算出
print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
結果:
CPUモードで948[sec]、GPUモードで661[sec]でした!
ちなみに手元のMacBook Pro 2011年モデル、Intel Core i7-2620M dual core 2.7GHzのCPUでは635[sec]でした。あ、なんだ、CPU対決なら自分のPCも負けてないんだ...でもファンがシャカリキ回って騒々しくなるので、他所で計算してくれるってのは有り難いです。
4.3評価
start = time.time()
predict = clf.predict(imagedata_validation) # 評価用データで予測
elapsed_time = time.time() - start
print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
print("結果")
ac_score = metrics.accuracy_score(labeldata_validation, predict) # 予測結果の答え合わせ
cl_report = metrics.classification_report(labeldata_validation, predict)
print("正解率 = ", ac_score)
print(cl_report)
結果
正解率 = 0.9377142857142857
precision recall f1-score support
0.0 0.97 0.98 0.97 1340
1.0 0.95 0.98 0.97 1620
2.0 0.93 0.93 0.93 1372
3.0 0.94 0.90 0.92 1453
4.0 0.92 0.95 0.93 1361
5.0 0.91 0.91 0.91 1261
6.0 0.96 0.97 0.96 1361
7.0 0.95 0.94 0.94 1461
8.0 0.93 0.90 0.92 1369
9.0 0.92 0.92 0.92 1402
avg / total 0.94 0.94 0.94 14000
正解率は約93.8%でした。5の正解率が低いのはデータ数の少なさなのか、それとも形のせいでしょうか...?4と9は判別が難しいと別の記事で読みました。
さぁて次回からはこれをパーセプトロンに置き換えたり、色々楽しんでみようと思います!
5.終わりに
ColaboratoryのファイルはGoogle Driveに保存されるのですが、GitHubにも連携してコピーを保存することが出来ます。Colaboratoryのメニューからファイル->GitHubにコピーを保存、でGitHubに作成したファイルが保存されます。
参考にさせて頂いたページを列挙します。
素晴らしい情報共有の数々に深く感謝致します。
- 【秒速で無料GPUを使う】深層学習実践Tips on Colaboratory
- MNIST手書き数字データをnumpyで書いたロジスティック回帰で学習して結果を分析する
- 手書き数字データ(MNIST)をSVMで分類してみた
この本は画像認識の前処理からディープラーニングまで全部の仕組みが書いてあって良書です。お勧めします。
