この記事の目的
Google colaboratoryを使って、Alibaba Cloudサイトからプロダクト一覧を取得してみます。
Google colaboratoryはGoogleが提供しているJupyterNotebook環境で、Googleアカウントさえあれば誰でも利用することが可能です。また、一時的ですがGPUリソースを利用することもできます。
無料かつ環境構築のハードルもなくすぐに使えて性能も良いので、使っておいて損はないです!
対象のサイト(Alibaba Cloud国際サイト)
https://www.alibabacloud.com/ja/product
WEBサイトによってはスクレイピングを禁止しています。
事前に利用規約を読み問題ないかを確認してみましょう。
htmlからプロダクト名称とプロダクト詳細を見つける
chromeのデベロッパーツールからhtmlを解析します。
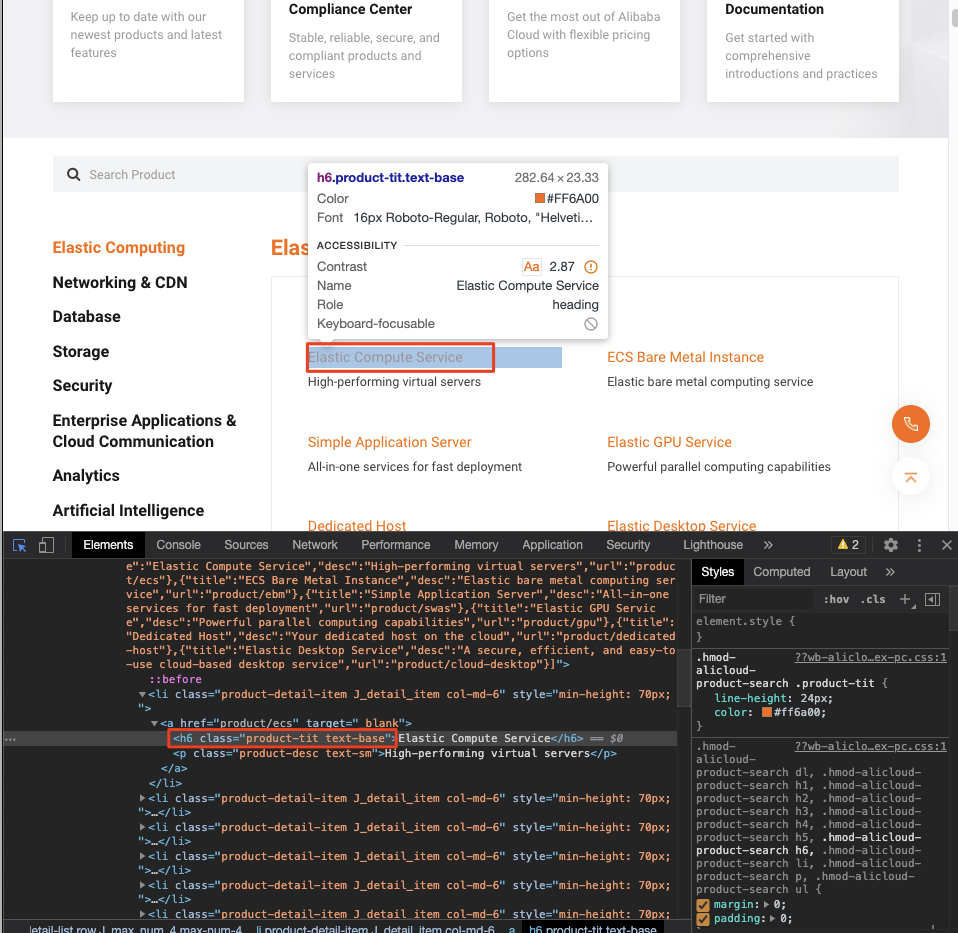
プロダクトの名称
h6、class="product-tit text-base"が判別できました。
したがって、pythonのコードでは以下の通りにタグを指定します。
product_name = soup.find_all("h6", class_="product-tit text-base")
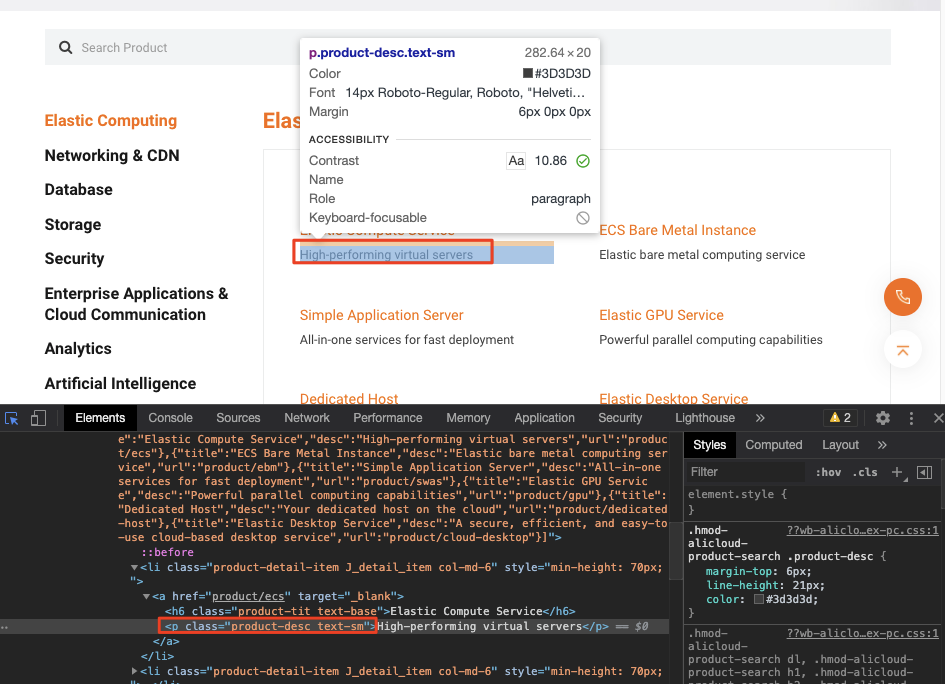
プロダクトの詳細
p、class="product-desc text-sm"が判別できました。
したがって、pythonのコードでは以下の通りにタグを指定します。
product_detail = soup.find_all("p", class_="product-desc text-sm")
実行コード
# モジュールのインポート
import re
import csv
import requests
import time
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
# 関数
def albb():
# スクレイピング対象の URLに リクエストを贈り HTML を取得する
res = requests.get("https://www.alibabacloud.com/ja/product")
time.sleep(1)
# レスポンスの HTML から BeautifulSoup オブジェクトを作る
soup = BeautifulSoup(res.text, "html.parser")
# プロダクト名称
product_name = soup.find_all("h6", class_="product-tit text-base")
# プロダクト詳細
product_detail = soup.find_all("p", class_="product-desc text-sm")
# 辞書とリストの空箱を用意
result = []
result_2 = []
# find_allで取得したものはリストオブジェクトなのでループ文で1つずつリスト内にappendする
for i in product_name:
result.append(i.text)
for x in product_detail:
result_2.append(x.text)
# pandasのデータフレームに格納する
df_result = pd.DataFrame({'product':result, 'detail':result_2})
# nullセルをdrop
df_notnull = df_result.dropna(how='any')
# csvに出力
df_notnull.to_csv('output.csv',index=False)
return df_notnull
# 関数の呼び出し
albb()
結果
データフレームに格納されたものを、csvに出力することができました。
csvは、googleのcolaboratory内に保存されます。
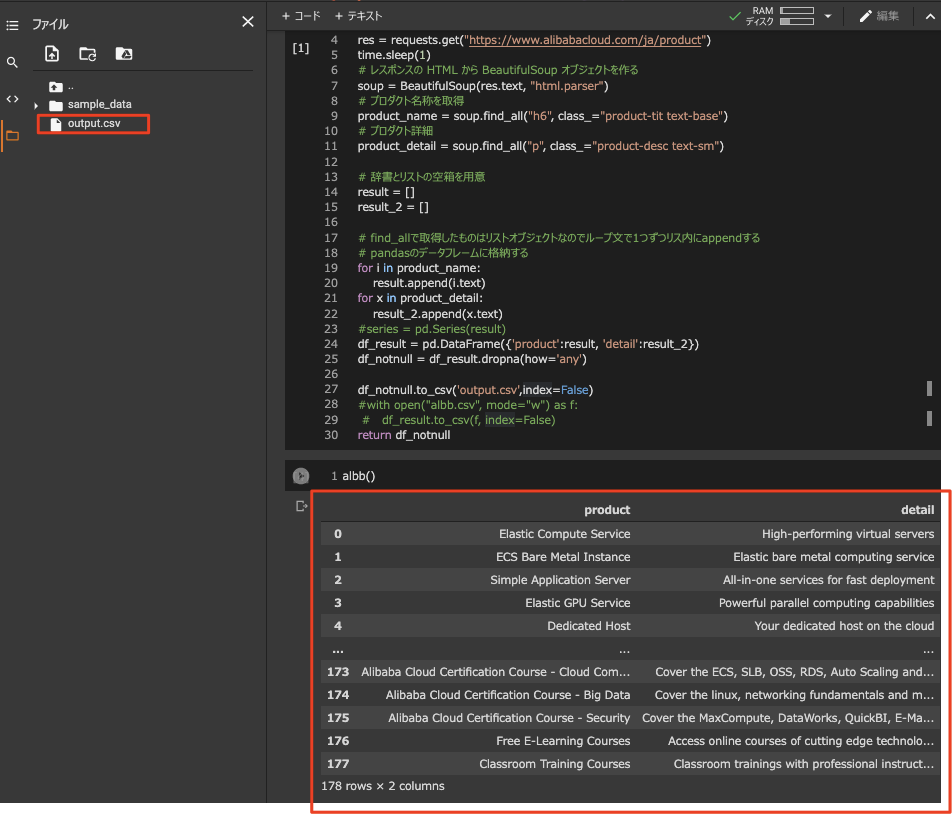
CSVファイルを見てみる
プロダクト以外の余計なサービスを除くと、164種類のプロダクトがありました。
めっちゃ増えてる。
