この記事の目的
先日あったAWSの大規模障害を受け、
いまいちど、アベイラビリティゾーンの定義と、冗長化の概念をしっかり捉えようと思いったのがきっかけです。
書いてる知識レベルは雑魚なのでチラシの裏書きだと思っていただければ。

8月23日にAWSに何があったの?
- AZ内の冷却装置の故障によって、ネットワークコネクティビティに障害が発生
- 上記にともない、一部の物理サーバがシャットダウン
- 一部のEC2インスタンスやEBSボリュームに影響が生じる
- 冷却システムの安定化、電力システムの復旧により同日午後9時までにEC2の大部分のサービスが回復
被害を受けたサービス・サイト
ほんの一部ですが。
PayPayの基盤ってAlibaba Cloudじゃないんですね。
同じソフトバンクグループだから、勝手にAlibaba Cloudを使っていると思ってた🙃
| 企業名 | 業種 | 原因・発生事象 |
|---|---|---|
| PayPay | 金融 | サービス断続的に使用不可 |
| ファミペイ | 金融 | AWSインフラの障害 |
| mixi | ソーシャルメディア | 接続障害 |
| クリックポスト | サービス | AWSインフラの障害 |
| ラクマ | サービス | システム不具合 |
| 楽天チケット | サービス | システム不具合 |
冗長化の定義
Wikipediaによると、以下の通り。
冗長化(じょうちょうか)とは、システムの一部に何らかの障害が発生した場合に備えて、障害発生後でもシステム全体の機能を維持し続けられるように、予備装置を平常時からバックアップとして配置し運用しておくこと。冗長化によって得られる安全性は冗長性と呼ばれ、英語ではredundancyと呼ぶ。
常に実用稼動が可能な状態を保ち、使用しているシステムに障害が生じたときに瞬時に切り替えることが可能な仕組みを持つ。障害によってシステムが本来の機能を失うと、人命や財産が失われたり、企業活動が大きな打撃を受けるような場合には、冗長性設計が必須となっている。
サーバの利用者に準じて、どこまで冗長構成を検討するかも重要な要素かと思います。
例えば、
| システム用途 | 重要度 | |
|---|---|---|
| 常時リクエストを受けるような幅広いユーザーに提供するサービス | 高 | 冗長化の検討重要度は高い。データ冗長でのロールバックだけではなく、サーバ自体の冗長構成を検討することがほとんどのケースで必要🙃 |
| 企業内でのみ利用するサービス(9-17時稼働とか) | 中 ~ 低 | 影響範囲が企業内なので狭い。(もちろん業務内容にもよるが)障害が発生したとしてもデータさえロールバックできれば可なケースも多い🤫 |
アベイラビリティゾーン(AZ)って美味しいの🍖?
アベイラビリティゾーンとは、AWSの各リージョンに存在するデータセンターのゾーンを指します。
単一AZで障害が発生しても、別AZはその障害を受けないよう設計されています。
どんな堅牢なアプリケーションでも、ホスティングしている単一の物理DCがやられたらシステムはおしまいです。
マルチAZにEC2をデプロイすることで可用性はぐーんと増します。🤫
せっかくおなじAWS料金を支払うなら、冗長化構成を検討しない手はないですよね👾
また、AWSを利用する=クラウドの責任共有モデルに合意することになります。
利用サービスの設定で回避できる問題や障害、マルチAZを利用したアーキテクチャの組み方で回避できるということであれば、
すべてAWS利用者側の責任になります。
| AZの場所 | AZ間の距離 | 単一AZの可用性 | マルチAZの可用性 | AWSが定めているマルチAZにおけるEC2のSLA |
|---|---|---|---|---|
| 非公開 | 数キロ ~ 数十キロ | 99.9% | 99.99% | 99.99% |
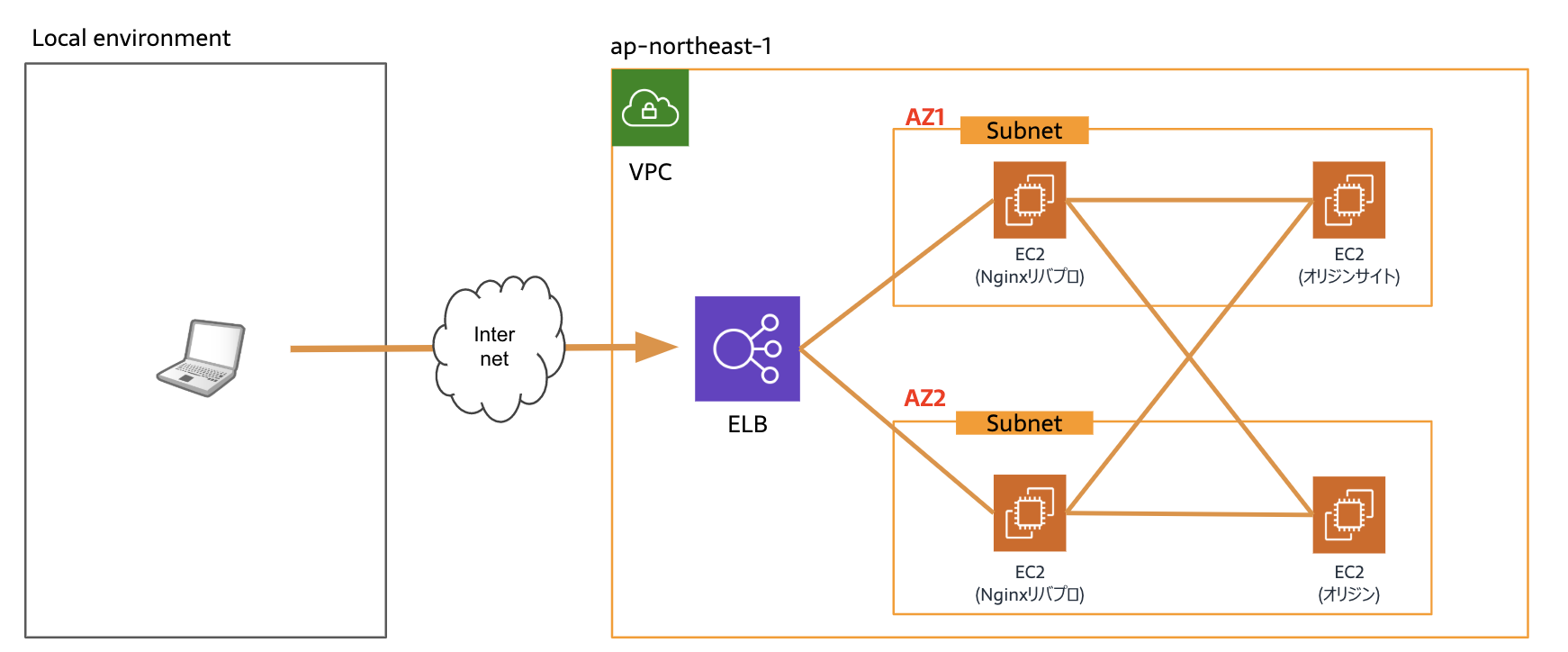
マルチAZを利用した冗長化構成のベストプラクティス(雑です)
Webサーバーのフロントにロードバランサーを置き、異なるAZにEC2をデプロイする構成です。
料金が高い以外、デメリットはありません。最小構成においてもやるべきです🤒
|メリット|デメリット|
|----|----|----|
|LBによる負荷分散|料金が高い|
|異なるAZでのDR対策|料金が高い|
|ホットスタンバイでの自動フェイルオーバー|料金が高い|
「インフラとしてのクラウドはもろい」のか?
先日の大規模障害の際、AWS側が物理障害の復帰に要した時間は**7時間ほど**だったようです。
7時間で全快ってすごくないですか?
オンプレでこの速さで復旧できますか?
かなりの影響範囲だったので、相当数のサーバーがダウンしていたことが想定できます。
それだけの台数をたった7時間で復旧しているのは素直に凄いことだと思います。
経過レポートも5時間の間で**6回報告**があったようです。
Design for Failureの精神
AWSが提唱している設計思想の1つです。
完璧に100%稼働するシステムは存在しません。
サーバは落ちるもの、データセンタは止まるものです。
プロダクトは揃っているのだから、開発環境や、どうでも良いサービスで無い限り、あらかじめ障害を想定した構成を組むべきです。
マルチクラウド化の可能性
今回のAWS大規模障害を通じて、マルチクラウド運用を想起された人も少なくないと思います。
AWSですら(AWSだからなのかもしれないが)障害は避けられないのであれば、
インフラ設計者としてはクラウドは複数使って行かないといけないのだなあと感じます。
複数クラウド利用による可用性向上もそうですが、**AWS一選のベンダーロックインから開放されるのもメリットだなあ**と思います。