Azure Machine Learning を勉強しはじめました。
Microsoft Learn はよい教材なのですが、文章と知識チェックだけ進めると途中からサッパリになってしまいました。そこで演習の方もちゃんとしておこうと思います。
今回は、Learn のコンテンツの一つ、Azure Machine Learning デザイナーを使用して分類モデルを作成するの中の演習課題をやってみようと思います。
この演習では被験者の身体データと糖尿病の有無が含まれたサンプルデータが用意されており、この身体データをモデルに学習させて糖尿病の有無を予測します。糖尿病の有無データと予測との一致率がどの程度かを評価するまでを行います。
答えとなる糖尿病の有無データがあるので、機械学習の種類としては「教師データあり」の「分類」になります。
演習のページはこちらです。
Explore classification with Azure Machine Learning Designer
Azure Machine Learning の準備
まずは Azure Portal を使えるようにします。そのあと、Machine Learning 用のサイト https://ml.azure.com にアクセスします。
まず最初に、作業するためのワークスペースを用意する必要があります。ワークスペースには、サブスクリプション、リソースグループ、リージョンを入力します。作成には数分かかります。

作成できると、Azure Machine Learning Studio のメインページに切り替わります。

これで事前準備が完了しました。
ちなみに、初回だとツアー機能がありますので、ざっと見ておきます。

Compute の設定
ワークスペースができたら、次に機械学習に使うコンピュータの設定を行います。コンピュータの設定は、左ペインのManage下にある Compute から行います。
「+New」をクリックして作成を開始します。

クリックすると、Compute の管理画面に移ります。Compute の名前、タイプ(CPU or GPU)、サイズ(スペックのこと)を指定します。
ちなみにサンプルでは、マシンタイプは CPU、スペックは Standard_DS11_v2 が指定されています。演習では、次の追加設定が記載されています。
- Minimum number of nodes(最小ノード数): 0
- Maximum number of nodes(最大ノード数): 2
- Idle seconds before scale down(スケールダウンするまでのアイドル秒): 120
- Enable SSH access(SSHアクセスの有効/無効): Clear
ちなみに compute の費用ですが、この Standard_DS11_v2 は1時間あたり $0.23 になります。今(2022/12/17現在)の為替だとドル円が 136.7円ですので、1時間あたり31.441円(税抜)というところです。

ちなみにいうと、virtual machine size のラジオボタンで「Select from all options」を選択すると、さらに多くのマシンが選べます。最小サイズは「Standard_A1_v2」で $0.05/hr です。ドル円 136.7円だと1時間あたり 6.835 円です。
税込みでも1時間10円いかないですね。最初はこれで十分な気がします。
ただ、スペックを下げると処理時間も長くなりますので、そのあたりデータセットの大きさとかからバランスを見ながら選んでいくといいと思います。
パイプラインの作成
いよいよデザイナーを使ってパイプラインの設定を行っていきます。
まずパイプラインを作成し、データセットの追加を行います。
左ペインから、Designer をクリックします。

Designer のメインページに遷移します。
「+」を押して新しいパイプラインを作成します。

新しいパイプラインの画面が表示されたら、まず、左上にある Setting をクリックし、Select Compute Type に「Compute instance」を指定し、先ほど作成した compute を指定します。

※サンプルでは最安の Standard_A1_V2 でやってますw
ちなみに大量データを処理することになって1台ではマシンパワーが足りない時のために、 compute cluster も選択できるようになっています。
Setting の画面の下の方に、Draft details という設定があります。デフォルトだと「Pipeline-Created-on-日付」となっていますが、冗長なので短くてわかりよいものに変えておきます。

演習の記載の通り「Diabetes Training」にしておきます。
データセットの登録
パイプラインの準備が終われば、次にデータセットを登録します。左ペインから「Data」を指定します。

データアセットの登録画面に移ります。「+Create」から新規登録を行います。

データアセットに名前、説明、タイプを指定します。
名前と説明はなんでもいいのですが、サンプルに従うなら名前にdiabetes-data、説明にDiabetes dataを入力します。

なお、名前には個人情報や機密といったものは入れないように注意しましょう。この名前は Azure の管理ログで永続的に保管され、機密保持対象外の扱いとなります。
データアセットのタイプには Azure ML v2 APIs と Azure ML v1 APIs の2種類があります。
- Azure ML v2 APIs
- File(uri_file)
- Folder(uri_folder)
- Table(mltable)
- Azure ML v1 APIs
- Tablar
- File
現時点では v1 の方が選べるデータソースも多く、メインはまだ v1 という感じです。
演習で提供されるサンプルデータを利用するには、タイプに Azure ML v1 APIs の「Tabular」を指定します。「Next」をクリックします。
次に、データアセットのソースを指定します。

ソースとして、5つのタイプが指定できます。
- From Azure Storage
- From local files
- From SQL databases
- From web files
- From Azure Open Databases
URL で公開されていますので、From web files を選びます。「Next」を押します。
次の画面では URL を指定します。

https://aka.ms/diabetes-data を指定します。
Skip data validation はどちらでもいいです。有効にするとちょっと早くなるかもしれません。
データの取り込みが終われば、次にデータの細かな設定を行います。

提供されているデータは、ヘッダ付きの CSV です。エンコーディングには UTF-8 を指定します。
- File format: Delimited
- Delimiter: Comma
- Encoding: UTF-8
- Column headers: Only first file has headers
- Skip rows: None
- Dataset contains multi-line data: do not select
正しく設定できると、下半分にデータのプレビューが表示されます。
次にスキーマ設定を行います。項目ごとにデータタイプを指定する作業を行います。

ある程度自動で型を識別されますので、間違いがないかをチェックします。
問題なければ「Next」をクリックします。レビュー画面で再度チェックして、問題なければ「Create」を押します。
今登録したデータの詳細が表示されます。

これで学習用データの準備が完了しました。
パイプラインのキャンバスにデータをロードする
左ペインの designer をクリックし、下半分にある「Piplelines」から、作成した「Diabetes Training」をクリックします。

次にデータアセットを登録します。下の図の赤い矢印を上から順番にクリックしていきます。

- アセットライブラリのアイコンをクリックします
- 「Data」を指定します
- 作成したデータアセットにマウスカーソルを合わせます
- ポップアップで表示されるフレームの「Use data」をクリックします
中央のキャンバスに、「diabetes-data」が登場します。

ここでデータの確認を行います。キャンバスにある「diabetes-data」を右クリックし、メニューから「preview data」を選びます。
画面右にデータのプレビュー画面が現れます。
表の項目は、管理番号、身体データ、Diabetic(糖尿病)が続きます。
Diabetic 項目の値は、0 もしくは 1 の値が入っています。1 が糖尿病であることを示しています。

モデルには身体データを学習させるのですが、それぞれの項目のスケール(値の範囲)に注意する必要があります。
Age(年齢)は 21から77、DiabetesPedigree(糖尿病血統)は 0.078 から 2.3016 となっています。各項目のスケールがバラバラだと、大きい値に結果がひっぱられてしまい、正しい予測ができません。
そこでデータの正規化を行い、各項目のスケールを統一することで項目の強弱をなくします。
データの正規化
データの正規化を行うには、下の図のように操作します。

- アセットライブラリアイコンをクリックします
- Component を指定します
- 検索枠に「Normalize」と入力します
- 下の候補欄に「Normalize Data」が表示されるのでマウスカーソルを持っていきます
- ポップアップが表示されますので、「Use component」ボタンをクリックします
キャンバスに Normalize Data が表示されます。
マウスで diabetes data の下部にある Data Output から Normalizer Data の Dataset に矢印を引っ張ります。これで、Normalize Data で diabetes data のデータが扱えるようになりました。
次に Normalize Data の設定を進めていきます。
Normalize Data をクリックします。右に設定画面が表示されますので、次の指示を行います。
- Transformation method: MinMax(最大値最小値の正規化を指定)
- Use 0 for constant columns when checked: true(定数列に0を使用する)
- Columns to transform(変換対象の項目の指定。次の項目を追加する)
- Pregnancies
- PlasmaGlucose
- DiastolicBloodPressure
- TricepsThickness
- SerumInsulin
- BMI
- DiabetesPedigree
- Age

パイプラインを実行してみる
正規化のコンポーネントが正しく処理できているかどうかを試してみます。
右にある「Submit」ボタンをクリックします。

ダイアログでは、上から「Create new」を指定、 Existing experiment に mslearn-diabetes-training と入力し、Submit ボタンをクリックします。
計算にはしばらく時間がかかります。状況を確認するには、左のメニューから「Submitted jobs」ボタンを押すと状況を確認することができます。

より詳細を確認したいなら、左ペインの「Jobs」をクリック、mslearn-diabetes-training をクリックします。

mslearn-diabetes-training ジョブについての詳細画面が表示されます。Running:1 ってなってますので、実行中のようです。
時々リフレッシュボタンで状況を確認します。
Running の値が減り、Completed がカウントアップされれば処理が終了です。
ちなみに最小構成の Standard A1 V2 では 10分ほどかかりました。
実行結果を確認する
実行結果も左ペインの「Jobs」で行います。Complated がカウントアップされたのを確認したら、画面下の「Diabetes Traning」をクリックします。

Designer と同じような画面が表示されます。キャンバス内の「Normalize data」を右クリックします。

メニューにある「Preview data」にある「Transformed dataset」をクリックします。画面右に処理後のデータセットが表示されます。

カラムをクリックすると、右のグラフエリアに、拡大されたグラフや中央値、平均、最大値、最小値、偏差、ユニークデータ数などが表示されます。
これでようやくデータの準備が整いました。
次はいよいよトレーニングモデルを追加して機械学習を行います。
トレーニングモデルを追加する
トレーニングモデルの追加も Normalize Data と同じようにキャンバスにコンポーネントを追加し、矢印をつなぎ、パラメータを設定するという流れで進めます。
なお、データアセットの全データをモデルのトレーニングに使うのではなく、半分に割って一方をトレーニング用、もう一方を検証用に使用します。
2つに分割するために、Split Data コンポーネントを使用します。
再び左ペインの「Designer」から「Diabetes Training」を選択し、パイプラインの編集を行います。
Asset library アイコンをクリックし Component を選択したら、検索窓に「Split Data」を入力してコンポーネントを探します。見つかったSplit Dataコンポーネントにマウスカーソルを合わせ、「Use Component」をクリックします。
※Normalize Data コンポーネントの登録方法と一緒です
キャンバスに登録できたら、Normalize Data のアプトプットのうち、Transformed dataset から Split Data のインプットに矢印を引きます。

Split Data のパラメータを設定します。今回は Microsoft Learn で指定されている値をそのまま使うことにします。
- Splitting mode: Split Rows(行分割を指定)
- Fraction of rows in the first output dataset: 0.7
- Randomized split: True
- Random seed: 123
- Stratified split: False
同じように、次の3つのコンポーネントを追加し、図のように矢印を引っ張ります。
- Tran Model(トレーニングモデル)
- Two-Class Logistic Regression(2 クラス ロジスティック回帰)
- Score Model(スコアモデル)

なんかできあがった感がでてきました。
パラメータの設定としては、Train Model のパラメータの Label column に「Diabetic(糖尿病)」を指定します。これは教師データとして扱われます。

ちなみに、この構成について少し説明します。(Microsoft Learn の内容のままですが)
今回、予測結果の範囲は 0 か 1 の二値です。このように範囲内に収束する場合、線形モデルではなくロジスティック回帰モデルを使用します。Azure Machine Learning では Two-Class Logistic Regression を使用します。これを Train Model に接続します。
また、データセットのうちの半分で学習させたトレーニングモデルを、もう半分のデータを使って予測させます。これを Score Model を使って行います。
トレーニングモデルに学習させスコアを計測する
これで構成が整いましたのでトレーニングを開始していきます。Normalize Data を試したのと同じように、Submit ボタンを押します。

名前は前回と同じものを使うことにします。
Submit ボタンで学習開始です。
気長に結果を待ちます。
計算が終わったことを確認したら、Jobs メニューから結果を確認します。
mslearn-diabetes-training を選択し、画面下の計算結果から Diabetes Training を選びます。さっきの Normarize Data のテスト結果が残ってますので、間違えないようにします。

キャンバス上の各モジュールを見ると、左端が緑色になっています。エラーがなく処理が完了したことを示しています。

Score Model モジュールの右メニューから Preview data → Scored dataset を選びます。画面右に表が表示されます。

右にスクロールすると、Diabetic列(糖尿病の有無)があり、その右にモデルが予測した結果の Scored Labels 列と、正解確率を示す Scored Probabilities 列が追加されています。
Diabetic 列と、Scored Labels 列を追っていくと・・・うーん、3行目で早速不一致となってます。一致度合はどうなんでしょうか?よく分かりませんね。
評価モジュールを追加する
予測した結果の評価を行うためのコンポーネントも用意されています。これまでと同じように、左ペインの Designer から Diabetes Traning を選びキャンバスを表示させます。Asset Library アイコンをクリック、Component を選び、検索枠に Evaluate Model と入力します。

マウスカーソルを重ね、表示されたダイアログから Use Component をクリックします。

Score Model の Scored dataset と Evaluate Model の Scored Dataset とを矢印でつなぎます。
これで評価モジュールが有効になりました。
Submit を押して3度目の計算を行います。
またも Jobs メニューから mslearn-diabetes-training をクリックし、計算が終わっていることを確認します。終わっていたら、下にある Diabetes Traning をクリックします。前回、前々回の結果と間違わないように気を付けます。

キャンバスが表示されたら、Evaluate Model にマウスカーソルを合わせ、右メニューから Preview data、Evaluation results をクリックします。
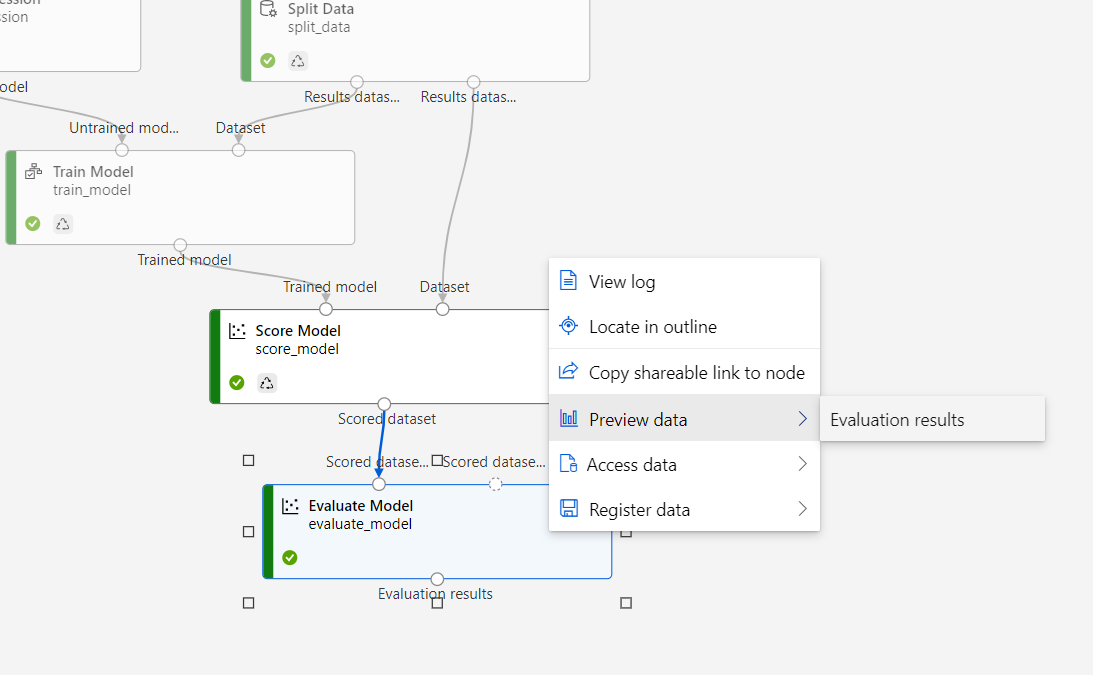
画面右に、評価結果が表示されます。
 結果1
結果1
続き。
 結果2
結果2
続き。
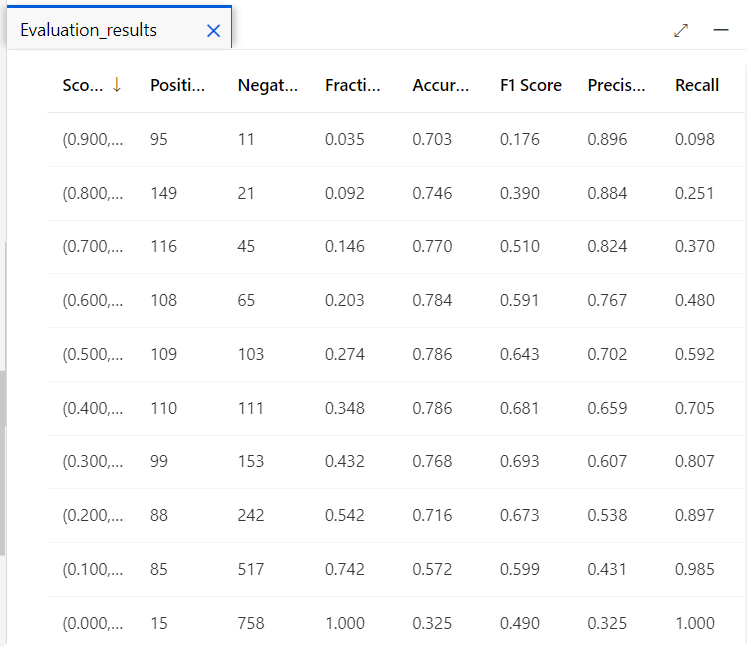 結果3
結果3
結果2には、スライダーと 2×2 のグリッドが表示されています。

グリッドは、列に Actual(実際)、Predicted(予測)の結果件数が表示されていて、それぞれが次のような意味になります。
Actual=1、Predicted=1・・・正解。予測と実際ともに糖尿病判定
Actual=1、Predicted=0・・・間違い。実際は糖尿病だが違う予測
Actual=0、Predicted=1・・・間違い。予測は糖尿病だが実際は違う
Actual=0、Predicted=0・・・正解。予測と実際ともに糖尿病なし
スライダーで 糖尿病判定のThreshold(しきい値)を変えることができます。値を変えると、次のパラメータが変動します。
- Accuracy: モデルの予測の正解率
- Precision: モデルが糖尿病と予測した患者の正解率
- Recall: 実際に糖尿病患者に対してモデルの予測の正解率
- F1 Score: F1 スコア
- AUC: ROC 曲線で塗りつぶされる面積
推論パイプラインを作成する
推論パイプラインを作成します。
Jobs メニューから処理結果を見ていましたが、この画面の上部メニューに「Create Inference pipeline」というボタンがありますので、これをクリックします。

ドロップダウンリストから「Real-time inference pipeline」をクリックします。

少しすると Designer のオーサリング画面に切り替わり、「Diatetics Training real time inference」という新しいパイプラインが表示されます。
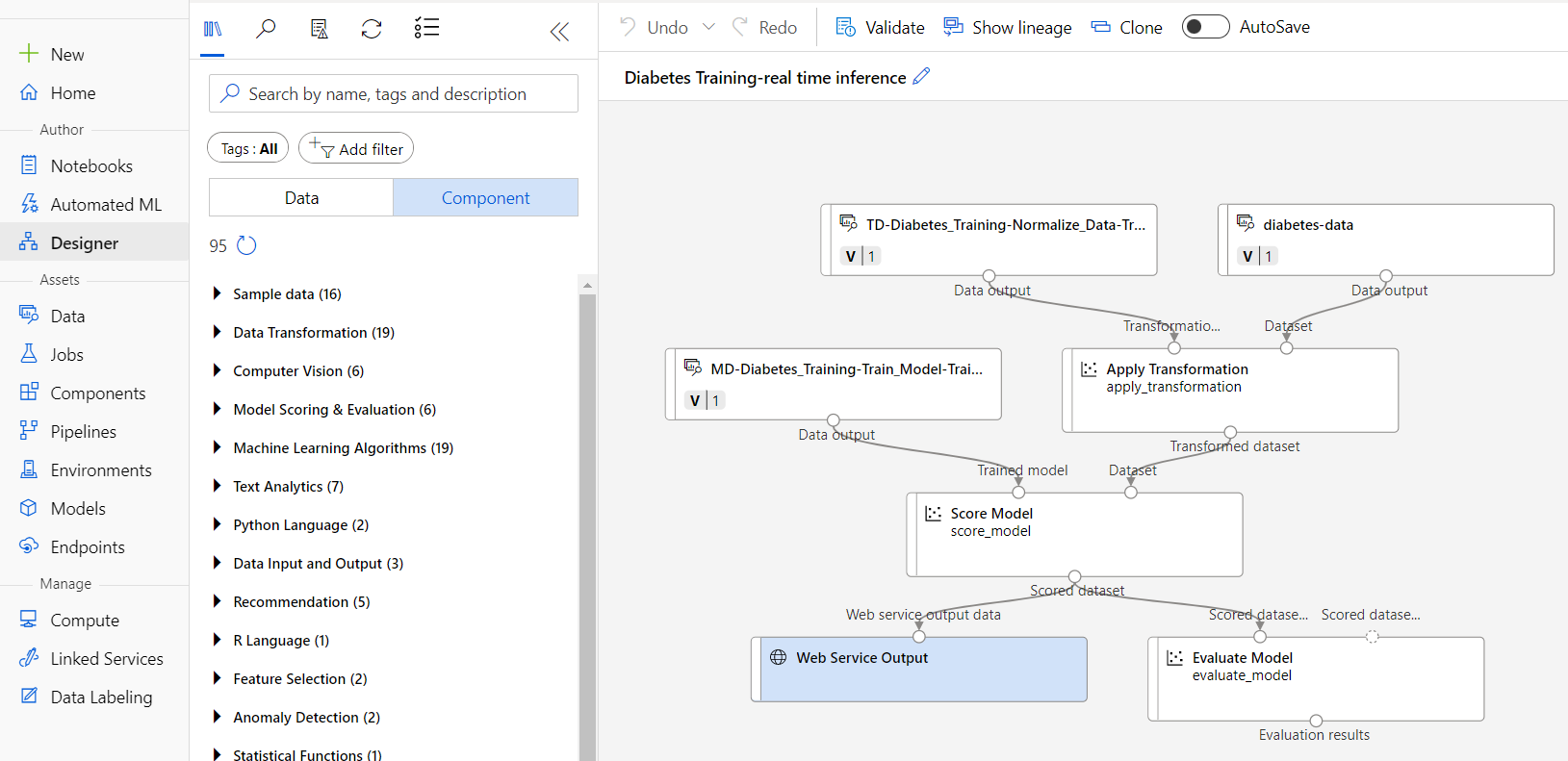
このパイプラインには、元となったデータセットやトレーニング済みモデルが組み込まれています。また、結果表示のための Web サービス出力も含まれています。
このパイプラインに修正を行います。
作成した推論パイプラインには、元のトレーニング データが再利用されるため、diabetics-data には Diabetics 項目(糖尿病の有無の紅毛)が含まれています。推論しようとしているデータには、Diabetics 項目がありませんので、diabetics-data を削除し、手動でデータを投入できるようにするためのモジュールに置き換えます。
また、推論結果のうち、PatientId,予測結果、予測率を Web に出力するようにします。

モジュールの操作は次の通りです。
- Diabetics(糖尿病)項目を持つ diabetics-data を切り離し、Diabetics(糖尿病)項目のないデータを手動で流し込むために、Enter Data Manually を追加します。追加したら出力を Apply Transformation の dataset につなぎます
- Web Service Input を追加し Apply Transformation の dataset 入力に接続します
- Evaluate Model module を削除します
- Web Service Output を追加します
- Execute Python Script module を追加し、Score Model からの出力を受け取り、Web Service Output に接続します
追加したモジュールの設定を行っていきます。
Enter Data Manually に手動で投入する患者データは次の3人分です。
PatientID,Pregnancies,PlasmaGlucose,DiastolicBloodPressure,TricepsThickness,SerumInsulin,BMI,DiabetesPedigree,Age
1882185,9,104,51,7,24,27.36983156,1.350472047,43
1662484,6,73,61,35,24,18.74367404,1.074147566,75
1228510,4,115,50,29,243,34.69215364,0.741159926,59
Enter Data Manually に登録します。

Execute Python Script module に登録するスクリプトは次の通りです。
import pandas as pd
def azureml_main(dataframe1 = None, dataframe2 = None):
scored_results = dataframe1[['PatientID', 'Scored Labels', 'Scored Probabilities']]
scored_results.rename(columns={'Scored Labels':'DiabetesPrediction',
'Scored Probabilities':'Probability'},
inplace=True)
return scored_results
ここまで出来たら処理を開始します。
推論の処理と分かるように、Experiment のラジオボタンを Create new にして、名称を「mslearn-diabetics-inference」を指定します。
4度目の submit を行います。
左ペインの Jobs を見ると、mslearn-diabetics-inference が増えていることが確認できます。

処理が終わって、Execute Python Script のプレビューを見てみます。
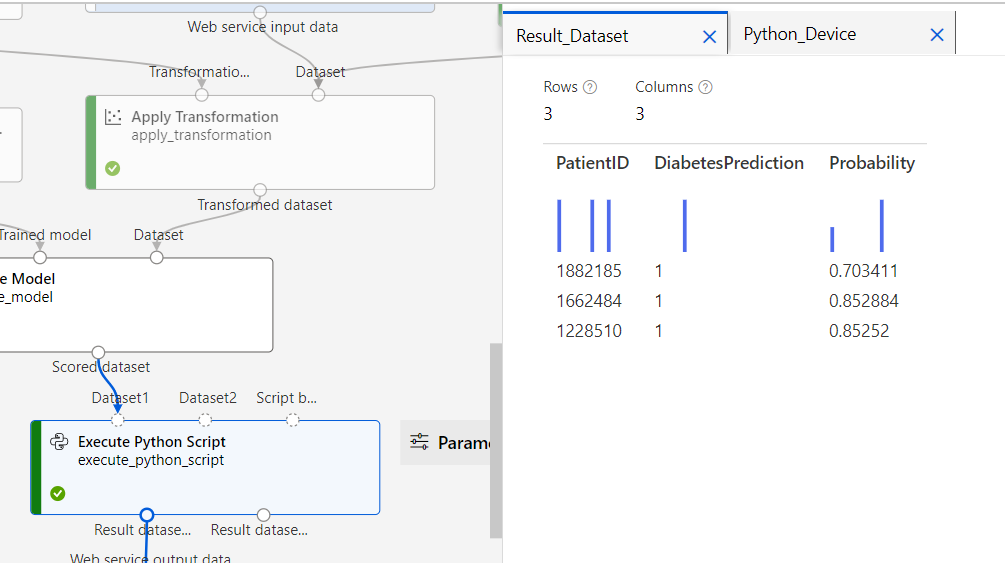
ちゃんと予測が出力されていました。
※残念ながら3人とも糖尿病と予測されてしまいましたが。
まとめ
Microsoft Learn の機械学習の演習を、Azure Machine Learning を使って勉強してみました。
演習では、Azure Machine Learning のセットアップ、パイプラインのオーサリング、機械学習(トレーニング)を行いました。さらに推論パイプラインも作成し、学習させたトレーニングモデルをつかって、3名の被験者データから糖尿病の予測を行いました。
基本機能だけでそこそこの予測結果を出すことができました。事前処理モジュールを追加したり、パラメータ調整をすることで、もっと精度をあげることはできそうです。
今回はやっていませんが、演習では推論パイプラインに Web Service Input と Web Service Output のモジュールを使って、Web サービスとしてデプロイする方法についても紹介しています。
Azure Machine Learning のモデルの予測精度が十分に高まれば、そのまま商用サービスとして展開することもできます。超実用的ですね。
費用感としては、最小構成なら(Standard A1 v2)1時間 0.05ドル、だいたい1日200円弱ぐらいです。(ドル円が 136.7 円)
Azure Machine Learning は、学習開始の敷居も低く、実務への展開も容易であることが分かりました。次は教師ありの分類や、クラスタリングについても学んでいきたいと思います。