論文
http://sglab.kaist.ac.kr/PRISM/prism_www14.pdf
この記事のひとつ前に紹介したPixel-Level Domain Transferと同じ著者
概要
ファッションアイテムから色を抽出するという問題。簡単そうに見えて、やってみるとめっちゃむずい。
ファッションECサイトには色による絞込機能が実装されていることが多いが、大抵の場合単色でしか絞り込めない。
一方で実際のファッションアイテムは複数の色が使われていることが多く、単色だと不便。
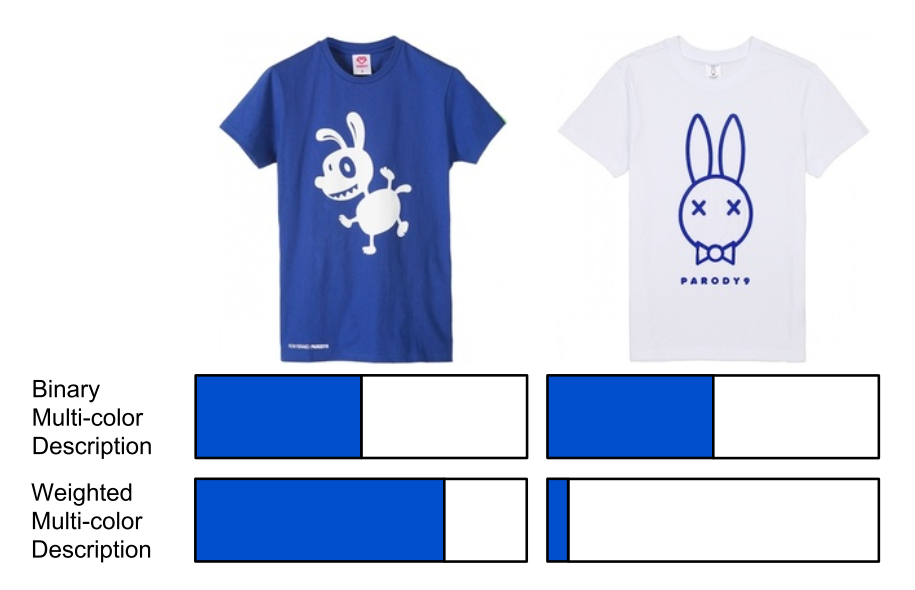
提案手法では、アイテムの色を複数の色を重み付けで表現することで、色の混合をクエリとする検索機能を提供している。
貢献
- 複数の色の重み付けをフィルタとしてファッションアイテムを絞り込む仕組みを提案する
システム構成
クローラー
ドメインに依存する処理を施すレイヤーと共通処理を施すレイヤーの2層になっている。
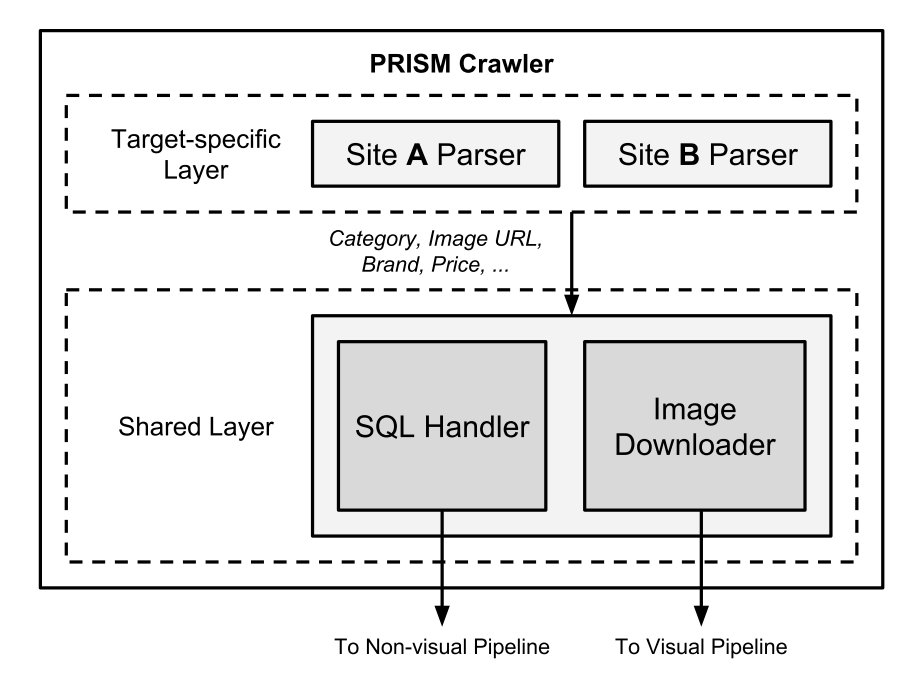
メタデータ等はそのままMySQLに保存して、画像は特徴抽出モジュールに渡す。
輪郭抽出
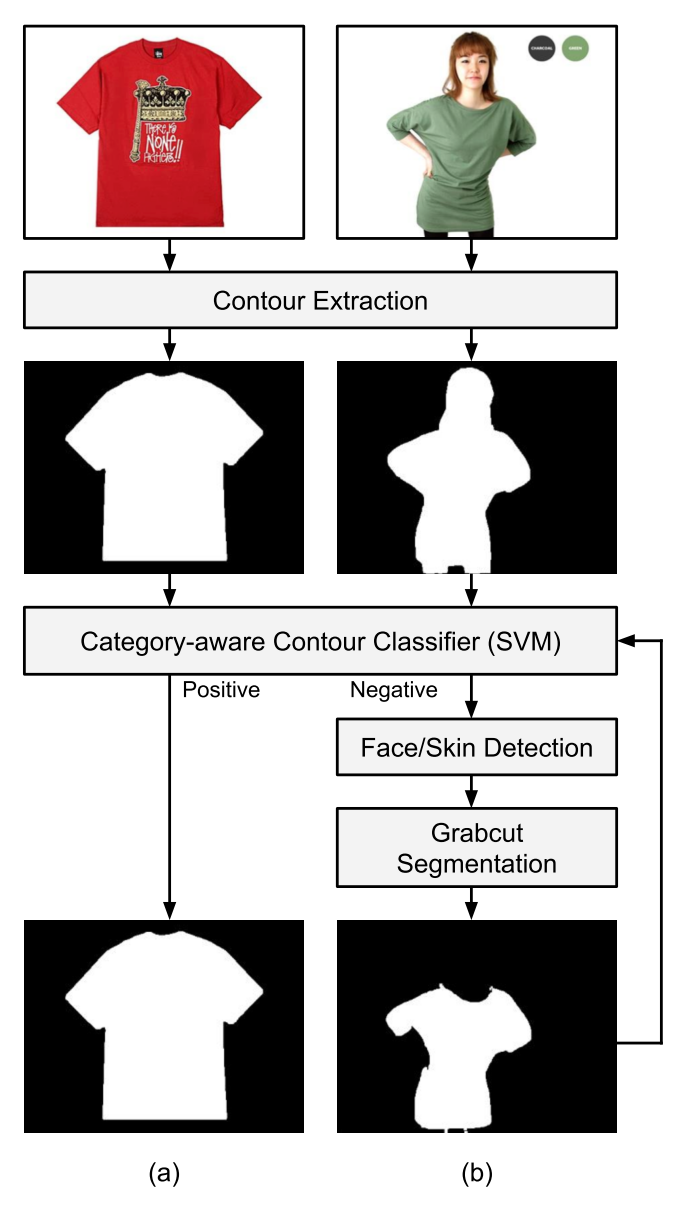
輪郭抽出は3ステージに分かれる。
1st stage
最初はCanny edge detectorという処理を噛ます。OpenCVに実装されている。
outputのうち、面積最大の部分を次の処理に渡す
2nd stage
続いて、抽出した輪郭が正しいか否かの判別をカテゴリ毎に行う。
Bag of Hash Binsという方法で輪郭の特徴を表現するらしい。判別器はSVM。
判別結果が陽であれば、その輪郭をそのままマスクとして用いて色抽出を行う。
陽でなければ次のステージに
3rd stage
失敗の原因はモデルの顔や肌であることが多い(特にトップスの場合は)。そんなときはアプローチを変えて、GrabCutを施す。
segmentation結果は再度SVM。
色抽出
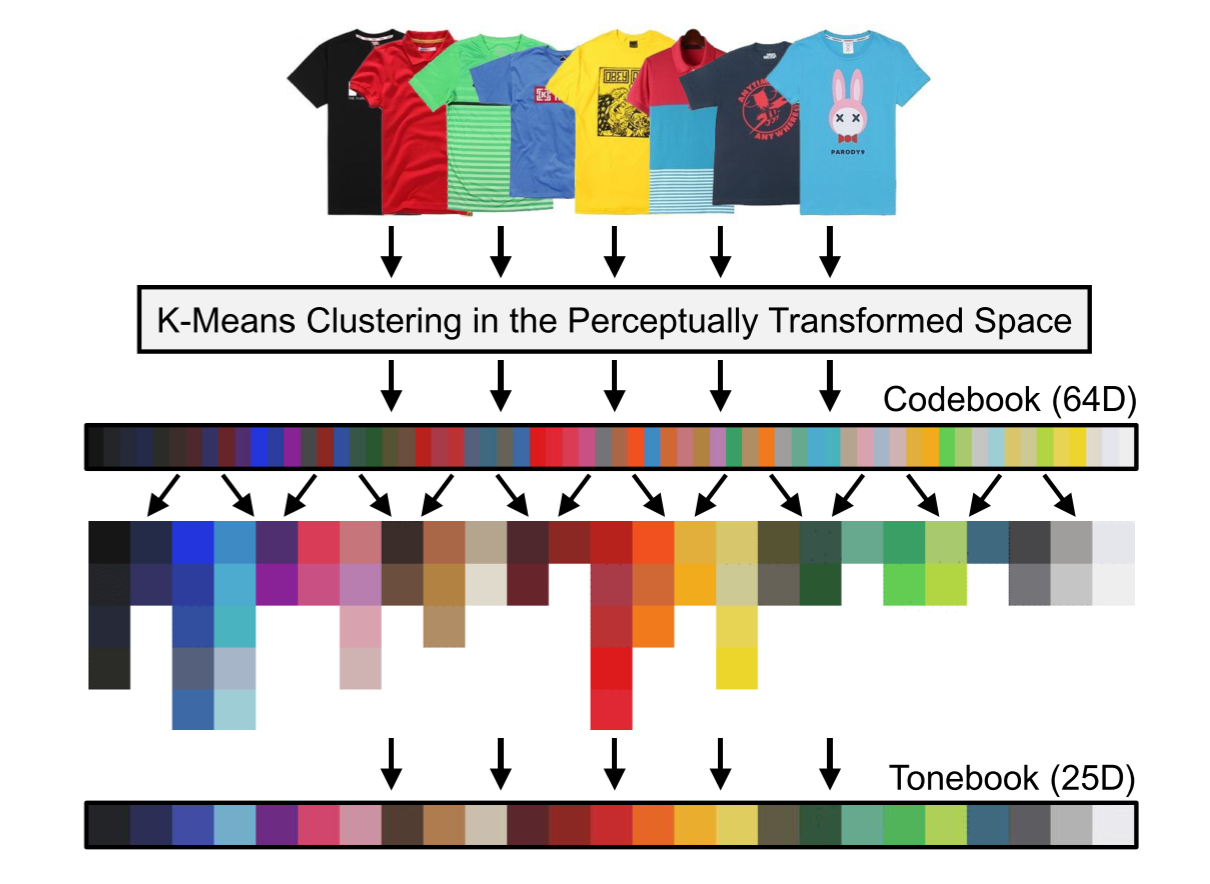
単色ではなくBag-of-Colorで表現する。ということはk-meansか何かで予め色を量子化してコードブックを作成し、その要素を積み上げたヒストグラムで表現するということだろう。
ただ、何も考えずにk-meansするのは良くない。ファッションアイテムに付与される色は、実際のカラーコードとは異なる場合がある。RGB値ではなく、人間の知覚が優先されるということ。
ただk-meansするだけだと、この微妙な色のニュアンスが失われるから、一度人の知覚に近い空間に射影する必要がある。
論文ではこんなアプローチをとっている。
- 知覚に近い歪んだ空間にデータを射影(マッピングは学習する)
- その空間上でk-meansしてコードブックを作成
- コードブックを手作業でグルーピング
知覚空間へのマッピング
マッピングは学習によって獲得する。ここで使われる手法は読んでないけど、おそらくcontrastive lossのように異なるクラスに属するデータをmarginの外に追い出すように学習するのだろう。
使うデータはファッションアイテムのsuper-pixel。手作業によって{Red, Orange, Yellow, Green, Blue, Navy, Purple, Black, Gray, White}のいずれかがラベリングされている。
super-pixelとは、これみたいなpixelの固まり。
自分が画像やってた頃は著者が公開してるライブラリ使ってたけど、今はOpenCVに実装されているようで。

k-means
獲得した空間上で普通にk-means。コードブックを作成する。
tonebook
作成したコードブックを手作業で25色にグルーピングしている。25という数字はおそらくシステムの仕様から決まる。
ちなみに、一連の処理はRGBではなくCIELAB空間で行う。CIELABはRGBよりも人の感覚に近い色空間。
実験
色の混合とアイテムカテゴリを指定して、検索を実行する。色はtonebookから複数選択した後、各色の割合を調整して決定する。
ぱっとみうまくいっている。
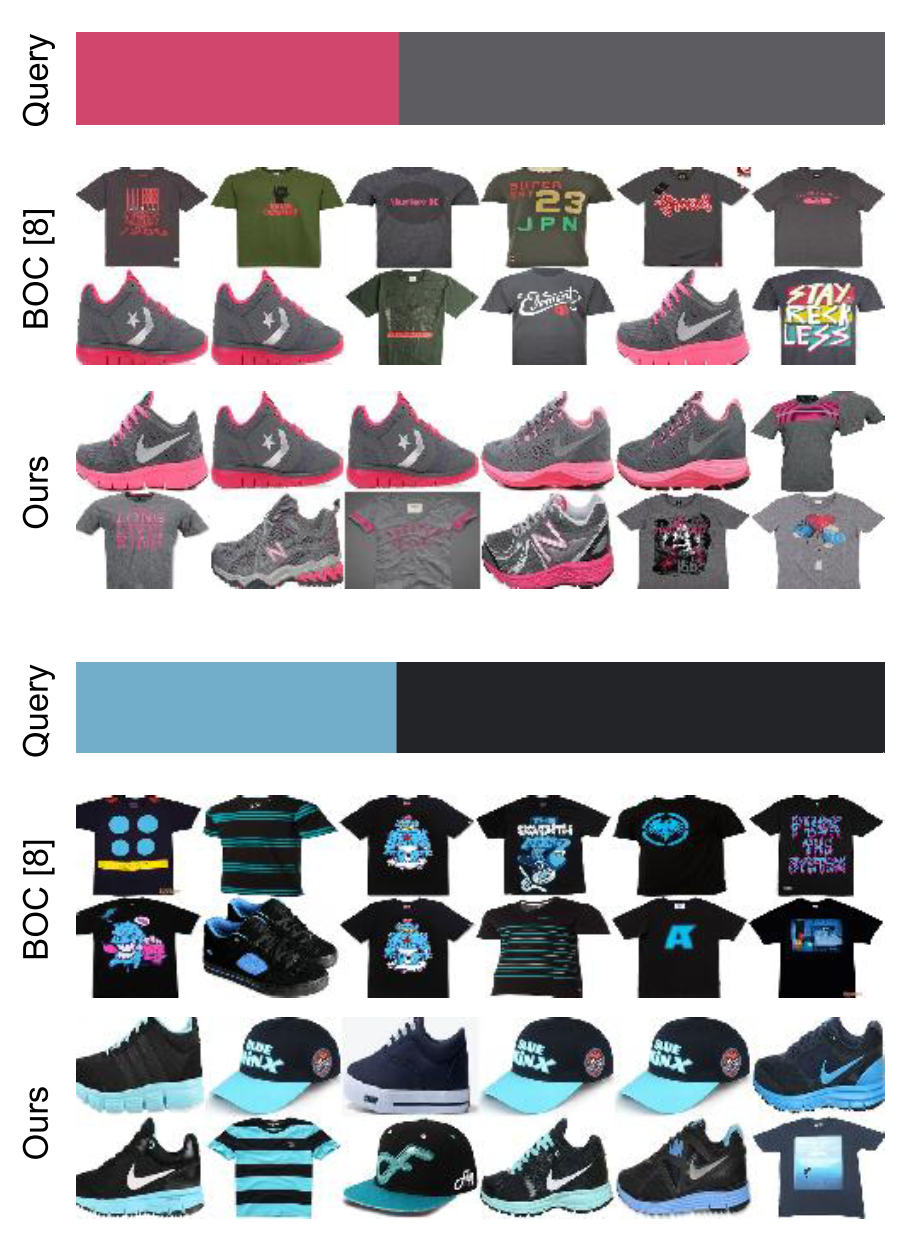

色の混合を手作りするだけじゃなくて、ファッションアイテムの画像自体をクエリにすることも可能らしい。食わせた画像から色を抽出して、あとは同じ処理を実行してくれる。
議論
輪郭抽出の精度はどれほどのものだろう?
図だとだいぶ易しい問題を解いているけど、実際は背景がうるさかったり2人以上のモデルが写ってたりするので、そういう場合は難しそう。
このあたりは教師情報があればdeepにしても良いのかもしれないけど、そもそも輪郭の情報は得られない場合がほとんど。
感想
実際に色の混合でアイテムを検索するというシーンがイメージできなかったけど、輪郭検出やBoCの抽出方法は参考になることが多かった。