Disclaimer
私はネットワークの勉強もちゃんとしたことないし、Linux のソース読むのもはじめてな素人です。
何かおかしなところなどあれば、遠慮なくコメント欄でまさかりをお願いいたします。
ソースコードの引用に関して
本文中で Linux のコード/ドキュメントを引用している箇所がありますが、すべてタグ v4.11 のものです。また、日本語のコメント・翻訳文は筆者が入れたものです。
TL; DR
Linux のカーネルパラメータ net.ipv4.tcp_tw_recycle は、バージョン4.12から廃止されました。
今後はこの設定は行わないようにしましょう(というかできません)。
一方、net.ipv4.tcp_tw_reuse は安全であり、引き続き利用できます。
…というだけの話なのですが、自分用にメモがてら経緯・背景などを記録しておきます。
なんで気がついたか
このパラメータは多数の Fluentd インスタンスを扱うときの推奨設定として公式ドキュメントでかつて紹介されていた 1 ものでした。
For high load environments consisting of many Fluentd instances, please add these parameters to your
/etc/sysctl.conffile. Please either typesysctl -por reboot your node to have the changes take effect. If your environment doesn’t have a problem with TCP_WAIT, then these changes are not needed.net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.ip_local_port_range = 10240 65535
自分のチームでもこれに倣ってこの設定を Ansible のプレイブックに記載していました。
- name: update sysctl to avoid TCP_WAIT problem
sysctl:
name: "{{ item.key }}"
value: "{{ item.value }}"
sysctl_set: yes
with_dict:
net.ipv4.tcp_tw_recycle: 1
net.ipv4.tcp_tw_reuse: 1
net.ipv4.ip_local_port_range: 10240 65535
ところがあるとき、そのプレイブックをもとに新しいマシンイメージを作ろうとしたら、下記のようなエラーが出てプロビジョンが失敗してしまったのです。
sysctl: cannot stat /proc/sys/net/ipv4/tcp_tw_recycle: No such file or directory
何が起きていたのか
Linux のカーネルバージョン v4.12 から、この設定項目がそもそも廃止されていました。
コミット:
tcp: remove tcp_tw_recycle 4396e46
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=4396e46187ca5070219b81773c4e65088dac50cc
自分のケースでは Ubuntu 16.04 LTS (Xenial) をずっと使っていたのですが、急に新しいイメージのビルドができなくなり、原因が全然分からず数時間溶かしました。
まさか Ubuntu の同じバージョン (16.04.3) の中でカーネルバージョンが変わる 2 なんて思っておらず……(おそらく LTS だけだと思いますが)
ちなみにお使いの Linux のバージョンの確認には、uname コマンドが使用できます。
$ uname -r
4.13.0-1002-gcp
なぜ廃止されたのか
廃止の経緯を理解するためには、そもそも net.ipv4.tcp_tw_recycle というのが何を調整するパラメータなのかを知る必要があります。
順を追って見ていきましょう。
TCP の TIME_WAIT
まずは典型的な TCP の接続終了方法を見てみます。
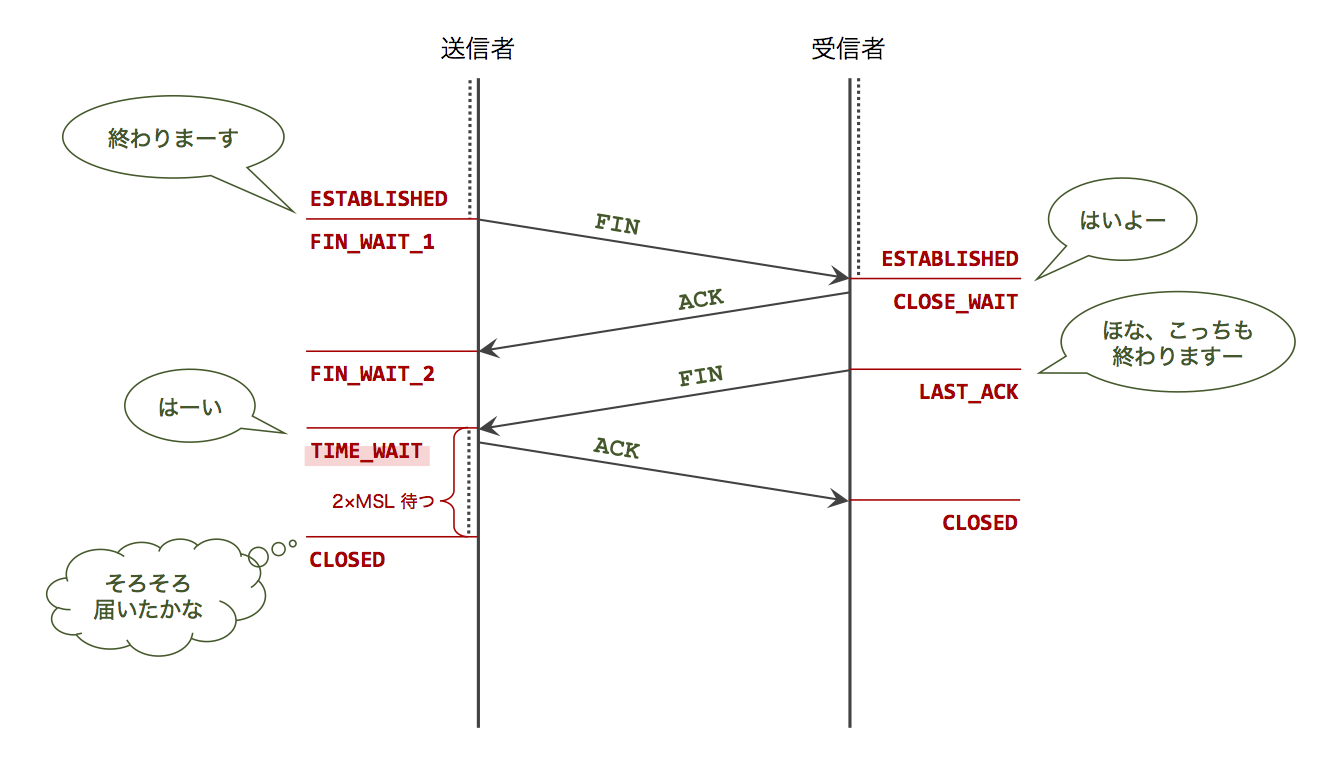
注目してほしいのは送信者側(アクティブクローズ側)です。受信者側の FIN (=「こっちも終わりまーす」)に対して ACK を返したあと、すぐに CLOSED 状態に移ってはならず、しばらく(具体的にはMST(最大セグメント生存時間)の2倍)待つことが定められています。
これは、ネットワーク上で起きうるパケットロストや遅延に対し、同じ送信者・受信者間で行われた別の接続が混ざらないようにするための工夫です。
しかしこの TIME_WAIT 状態というのはただの「待ち」状態であるため、高負荷環境下ではできるだけ減らしたいという気持ちになりますね。
net.ipv4.tcp_tw_{reuse,recycle}
問題はここからです。
Linux にはこの挙動を変えるための独自の設定項目が2つあります。
それが net.ipv4.tcp_tw_reuse と net.ipv4.tcp_tw_recycle です。
どちらも、「ある特定の条件を満たせば、 TIME_WAIT 状態のソケットをすぐに新しい接続に使いまわす」という設定です。
net.ipv4.tcp_tw_reuse: より安全な設定
マニュアルには下記のように書かれています。
Allow to reuse TIME-WAIT sockets for new connections when it is safe from protocol viewpoint. Default value is 0. It should not be changed without advice/request of technical experts.
プロトコル的観点から見て安全な場合に、TIME-WAIT ソケットを新しい接続に再利用することを許可する。既定値は0。 専門家からのアドバイス・要請なしには変更すべきではない。
ポイントは "when it is safe from protocol viewpoint" という箇所でしょうか。
これがどういうことか、具体的に見ていきましょう。
net.ipv4.tcp_tw_reuse を有効にすると、 TIME_WAIT 状態のソケットでもタイムスタンプが1秒でも新しければ、新しい接続で再利用できるようになります。
int tcp_twsk_unique(struct sock *sk, struct sock *sktw, void *twp)
{
/* ……省略…… */
if (tcptw->tw_ts_recent_stamp &&
(!twp || (sock_net(sk)->ipv4.sysctl_tcp_tw_reuse &&
get_seconds() - tcptw->tw_ts_recent_stamp > 1))) {
/* ……省略…… */
return 1;
}
return 0;
}
ただしすぐに再利用されるというわけではなく、外向きの接続で、なおかつ接続先が同じ場合に限られます。
In net/ipv4/inet_hashtables.c:
static int __inet_check_established(struct inet_timewait_death_row *death_row,
struct sock *sk, __u16 lport,
struct inet_timewait_sock **twp)
{
/* ……省略…… */
sk_nulls_for_each(sk2, node, &head->chain) {
if (sk2->sk_hash != hash)
continue;
if (likely(INET_MATCH(sk2, net, acookie,
saddr, daddr, ports, dif))) {
if (sk2->sk_state == TCP_TIME_WAIT) {
tw = inet_twsk(sk2);
if (twsk_unique(sk, sk2, twp))
break;
}
goto not_unique;
}
}
/* ……省略…… */
}
接続が外向きに限られること、なおかつ比較対象のタイムスタンプを付与しているのが自マシンであることから、この処理は "safe from protocol viewpoint" になっているんですね。
net.ipv4.tcp_tw_recycle: よりアグレッシブな設定
マニュアルには下記のように書かれています。
Enable fast recycling TIME-WAIT sockets. Default value is 0. It should not be changed without advice/request of technical experts.
TIME-WAIT ソケットの高速なリサイクルを有効にする。既定値は0。専門家からのアドバイス・要請なしには変更すべきではない。
これだけ読んでもよく分かりませんね。
先ほどとの違いでいえば、safe かどうかに関する記述がなくなったのと、"allow to reuse" が "enable recycling" に変わったくらいでしょうか。
こちらもソースで具体的な動きを確認してみましょう。
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
/* ……省略…… */
if (!want_cookie && !isn) {
/* ……コメント省略…… */
if (net->ipv4.tcp_death_row.sysctl_tw_recycle) {
bool strict;
dst = af_ops->route_req(sk, &fl, req, &strict);
if (dst && strict &&
!tcp_peer_is_proven(req, dst, true,
tmp_opt.saw_tstamp)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED);
goto drop_and_release;
}
}
/* ……省略…… */
isn = af_ops->init_seq(skb, &tcp_rsk(req)->ts_off);
}
/* ……省略…… */
drop_and_release:
dst_release(dst);
drop_and_free:
reqsk_free(req);
drop:
tcp_listendrop(sk);
return 0;
}
ざっくり言うと、パケットのタイムスタンプを TIME_WAIT に入ったときの最後のものと比較し、古ければパケットをドロップ、新しければ新しい接続にそのまま使うという動きです。
tcp_tw_reuse の場合と違い、内向きのリクエストであっても即、古いと見なされたパケットをドロップしてしまうというのが "recycle" という単語に込めたニュアンスなのでしょうか。
タイムスタンプはリモート側でパケットに付与されるもので、unixtime などの絶対時間ではなく uptime (マシンの起動時間=相対時間)です。
ということは、そのタイムスタンプが単調に増えていくという前提が成り立たない環境では、この処理が "safe" とはとても言えませんね。
この「前提が成り立たない環境」というのは実はそれほど珍しいものではなく、従来で一番多いケースだと NAT や LB の背後にあるサーバと通信する(=1つのソース IP に複数マシンが紐づく)場合が該当します。
(蛇足) net.ipv4.tcp_fin_timeout は TIME_WAIT の待ち時間を調節するものではない
この辺の話を日本語でググると、net.ipv4.tcp_fin_timeout が TIME_WAIT の待ち時間を調節するものだと書かれている記事を見つけられるかもしれません。
ですが、マニュアルにある通りこれは誤りで、実際は FIN_WAIT_2 のタイムアウト設定です。
The length of time an orphaned (no longer referenced by any application) connection will remain in the FIN_WAIT_2 state before it is aborted at the local end. While a perfectly valid "receive only" state for an un-orphaned connection, an orphaned connection in FIN_WAIT_2 state could otherwise wait forever for the remote to close its end of the connection. Cf. tcp_max_orphans Default: 60 seconds
孤立した(どのアプリケーションからも参照されていない)接続が、ローカル側で中断されるまでに FIN_WAIT_2 状態で待ち続ける時間。FIN_WAIT_2 状態は、孤立してない接続にとっては全く問題のない「受信オンリー」状態だが、孤立した接続においてはこの設定なしではリモートが接続を終了するのを永遠に待つことになってしまう。tcp_max_orphans も参照。既定値: 60秒
TIME_WAIT の待ち時間は TCP_TIMEWAIT_LEN という定数で設定されており、ソースをリコンパイルしない限り変更できない定数です。つまり、これは調整すべき値ではないということです。
# define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
timestamp offsets のランダム化
「タイムスタンプが単調に増えていくという前提が成り立たない環境」で、従来一番多かったのは NAT や LB を使っている場合だと前述しました。
この状況は Linux v4.10 から変わりました。
どう変わったか。実は、「あらゆる状況で」その前提が成り立たなくなったのです。
これは、下記の変更によりコネクションごとにタイムスタンプがランダム化されるようになったためです。
コミット:
tcp: randomize tcp timestamp offsets for each connection 95a22ca
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=95a22caee396cef0bb2ca8fafdd82966a49367bb
もはやこうなっては、tcp_tw_recycle はどんな状況でも設定すべきでない項目ですね。
そんなわけで、廃止されるに至ったというわけです。
まとめ
tcp_tw_recycle オプションは従来でも NAT/LB 利用など一部ケースで不適だったが Linux v4.10 からあらゆる状況で不適になり、結局 v4.12 で廃止されました。
また、TIME_WAIT の待ち時間を決める TCP_TIMEWAIT_LEN は調整すべき値ではありません。
一方 tcp_tw_reuse は安全に TIME_WAIT ソケットの再利用効率を高めてくれるので、 TIME_WAIT に悩んでいる場合はこの項目のみを設定しましょう。
(tcp_fin_timeout については危険というわけではないですが、TIME_WAIT とは関係ないため、今回は深入りしませんでした)
参考リンク
-
kernel/git/torvalds/linux.git - Linux kernel source tree
- 今回の変更のコミット
-
Coping with the TCP TIME-WAIT state on busy Linux servers | Vincent Bernat
- TIME-WAIT 周りの詳しい解説記事(英文)
-
ぜんぶTIME_WAITのせいだ! - Qiita
- TIME-WAIT 周りの日本語での解説記事
- tcp_tw_なんとかの違い - Qiita
- 「net.ipv4.tcp_tw_recycle」を有効にするのは(場合によっては)やめた方がいい - pullphone's blog
-
Linuxカーネルの「TCP_TIMEWAIT_LEN」変更は無意味? - Togetter
- tcp_tw_reuse オプションに関する識者の皆さまのツイート(一部元ツイートは削除済みの模様)
-
Transmission Control Protocol - Wikipedia
- Wikipedia 先生の TCP の解説。2018年1月3日閲覧。
-
TIME_WAITに関する話 (2018/01/05 追加)
- TIME_WAIT (というか EADDRNOTAVAIL)にどう対処するかが紹介されている日本語スライド(tcp_tw_recycle の話は載っていないですが)
-
現在、当該ドキュメントからは削除済みです: fluent/fluentd-docs
6ca2a90(2018/01/05 更新) ↩ -
GCE でいうと
ubuntu-1604-ltsファミリーのubuntu-1604-xenial-v20171208から該当します ↩