参考資料
- Introduction to Sound Event Detection
-
Faster EfficientNet-B0 SED Model Inference
※ 1 の SED モデルのバックボーンを Timm モデルに置き換えたもの
ポイントの整理
クリップ(入力音声全体)から、フレームごとのイベント発生有無を「弱ラベル」だけで学習できるのがポイント。
- 弱ラベル = クリップ単位のラベル(例:この 10 秒間に犬の鳴き声が含まれる)
- フレーム単位のラベルがなくても、フレームごとのイベント予測が可能
用語の整理
| 用語 | 説明 |
|---|---|
| clip | モデルに入力する音声データ全体(例:10 秒間の音) |
| frame | clip の時間軸を細かく区切った単位(例:1 フレーム = 100ms) |
| segment | バックボーンで時間的にダウンサンプリングされた特徴量のスケール(frame より粗い) |
モデルの動作メモ
Attention Block(AttBlock クラス)
# x: (n_samples, n_class, n_time)
norm_att = torch.softmax(torch.clamp(self.att(x), -10, 10), dim=-1)
cla = self.nonlinear_transform(self.cla(x))
x = torch.sum(norm_att * cla, dim=2)
-
1 行目:各クラスごとに
softmaxを適用し、segmentの中で重要な時間的部分に重みをつけている(= Attention) -
2 行目:各
segmentごとのクラスごとの予測スコアを計算 -
3 行目:
norm_att(重み)とcla(予測スコア)を要素ごとに掛け、時間方向に合計 → clip 全体の予測値を出力
claの情報を通すことで、Attention を通した segment ごとのクラス予測が反映される。ここがこの Block の核心部分か?。
ロス計算
-
AttBlockの出力(x)は clip 全体のクラスごとの確率値 - ラベルは clip 単位の弱ラベルなので、
BCELoss(シグモイド後の確率に対しての 2 値交差エントロピー)を使用 - 出力は確率値なので、
BCEWithLogitsLoss(ロジット入力前提)は使わない
実際に動作させたメモ
冒頭の参考資料の 2 つめ Timm モデルを使ったほうを写経して動作確認を行った。しかし、clip の両端 1,2セグメントの予測精度が低かった。
推論時には、両端のセグメントを除外し、中央部分のみの予測結果を使用するといった工夫が必要かもしれない。
うまくいった推論の様子
適当に 64 クラスを選択して学習・推論をしてみた。以下はうまく予測できていた例。
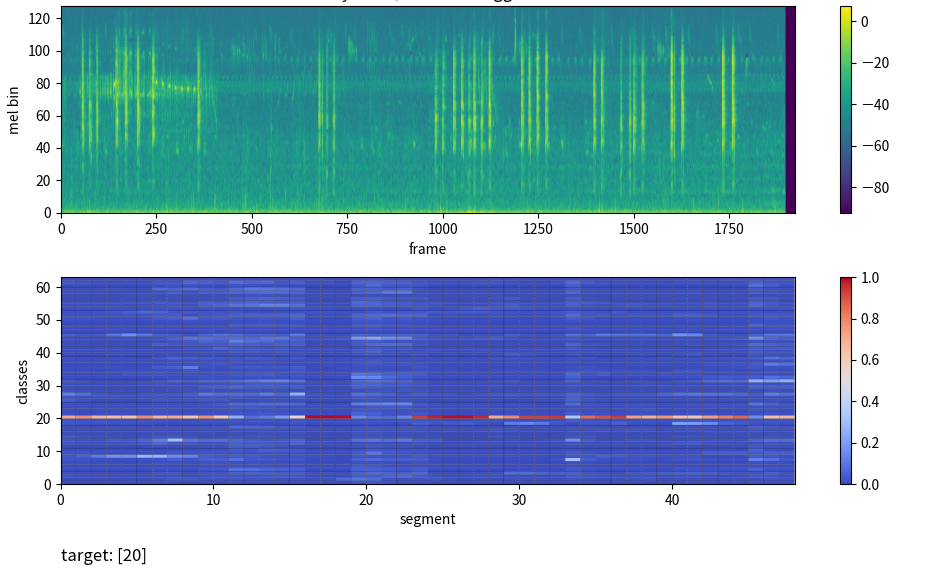
イベントの発生している segment を高く予測できている。
(とっていたメモを ChatGPT に投げて校正してもらった出力です)