はじめに
2023年11月Microsoft IgniteでAzure AI Search(旧:Cognitive Search)の大幅なアップデートがありました。Azure AI Searchでチャンキング+ベクトル化を行うには、Azure OpenAI on your data経由で作ったり、公式が用意したPythonのデータ準備ツールなどを利用する必要がありました。今回、ようやくこの機能がプレビュー版としてAzure AI Searchに統合されたので使ってみたいと思います!
こちらが公式の記事となります。
試してみる
Azure AI Searchのリソースにいくと「概要」に「データのインポートとベクター化」という項目が追加されました。クリックしましょう。
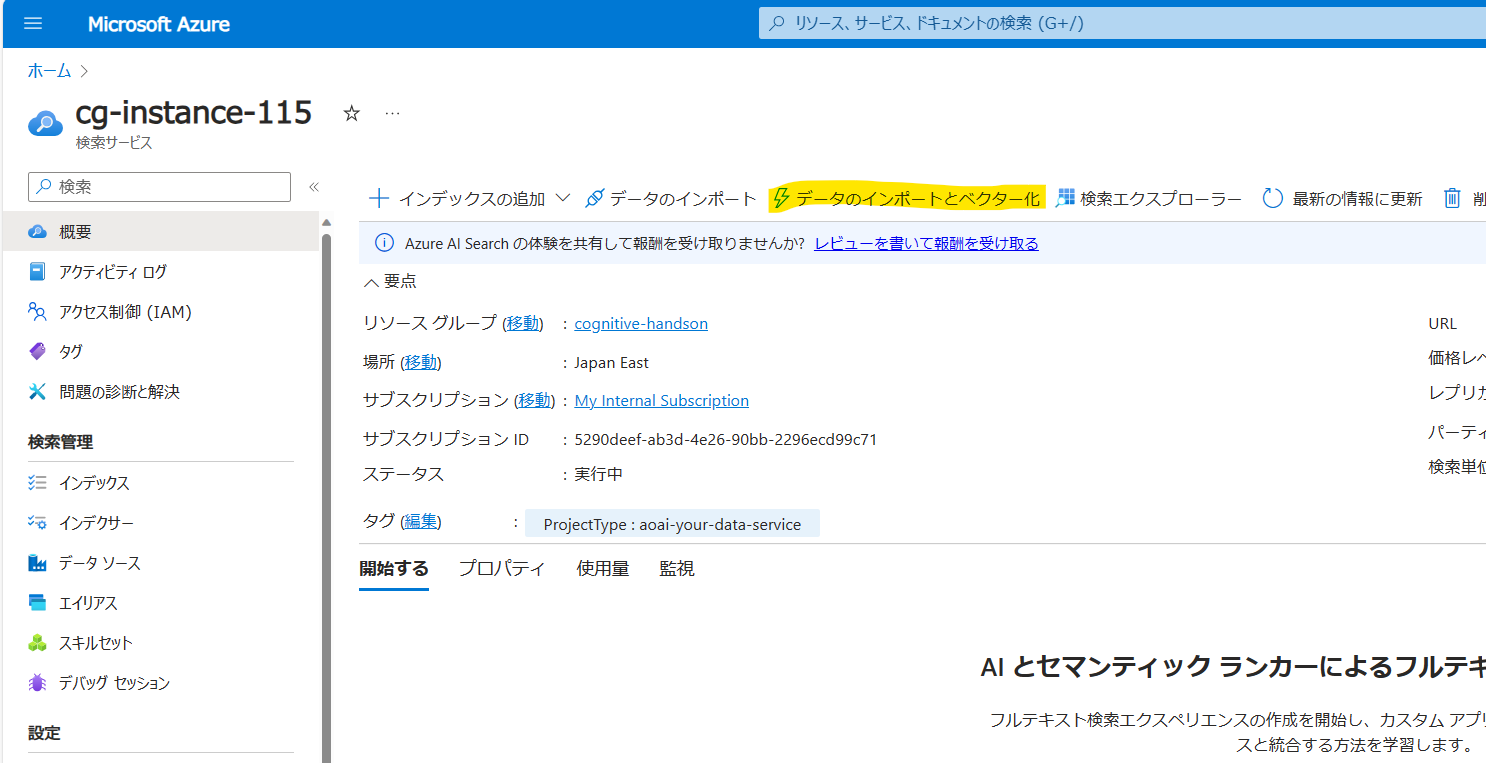
現状データソースは「Azure Blob Storage」もしくは「Azure Data Lake Storage Gen2」のみの対応のようです。
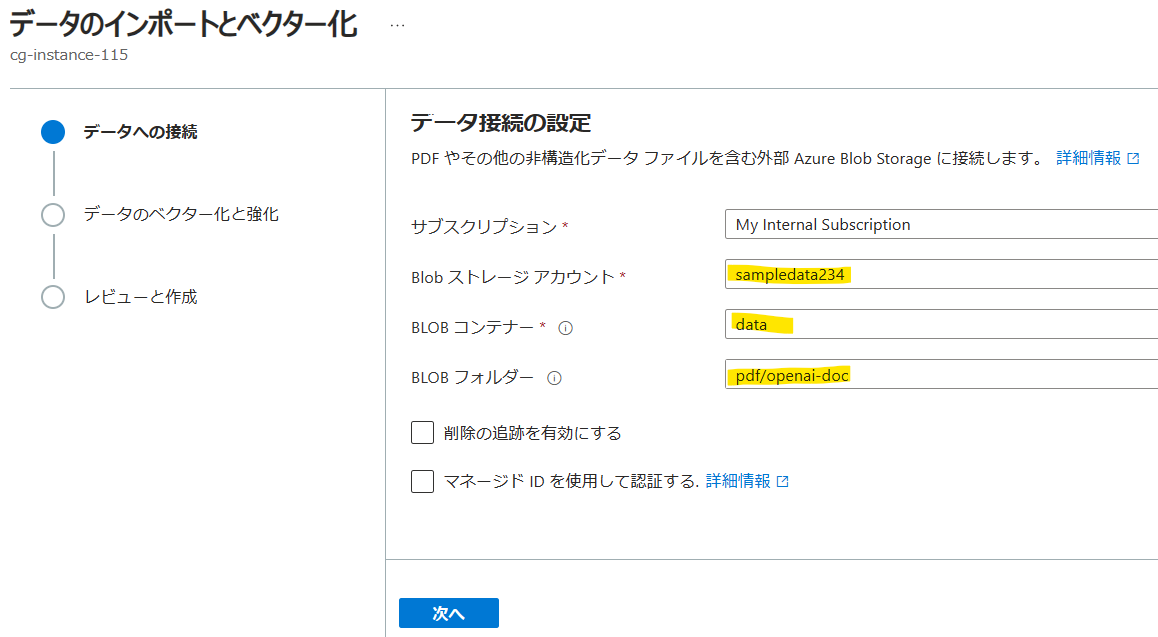
データのフォーマットはPDFを使います。
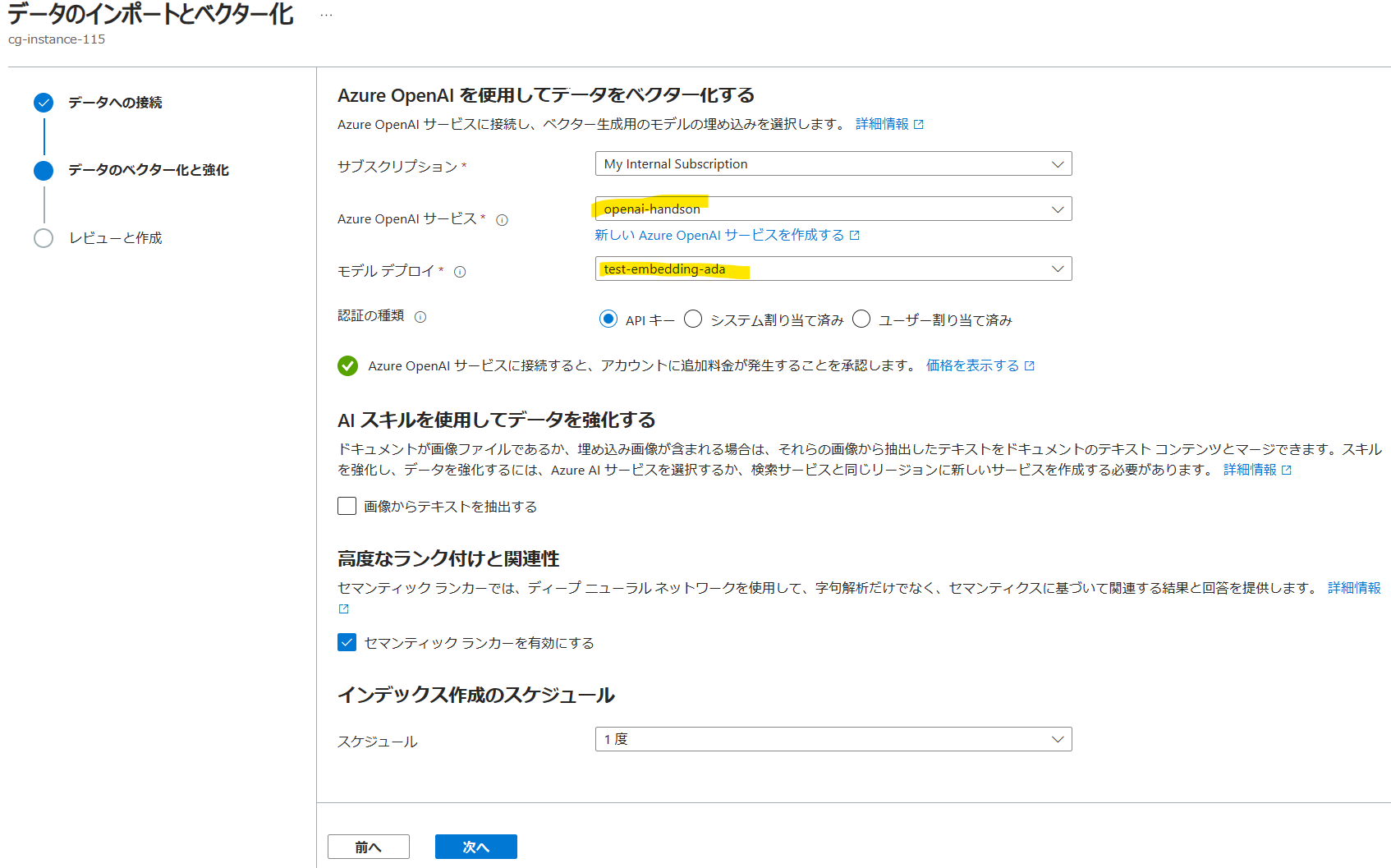
Azure OpenAIのEmbeddingsモデルをあらかじめデプロイしておき、こちらで指定します。ここで言語アナライザーの指定ができないことに絶望します。。少しでも日本語の検索精度を上げたいので、セマンティックランカーを有効にしておきます。
最後にプレフィックスを入力して、作成をクリックします。
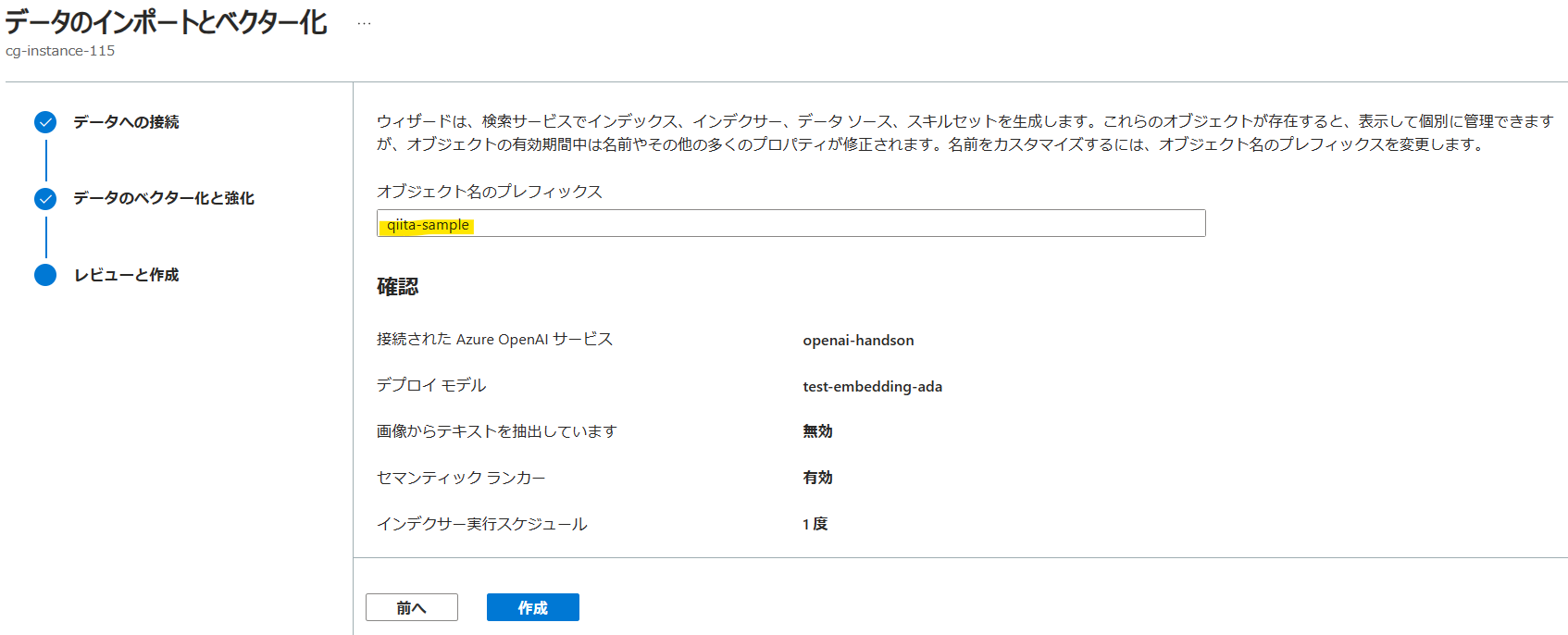
10秒ほどでインデックスが作成されていました。ドキュメント数に関しても、5件のドキュメントに対して、チャンク分割後20レコード作成されたことが確認できます。
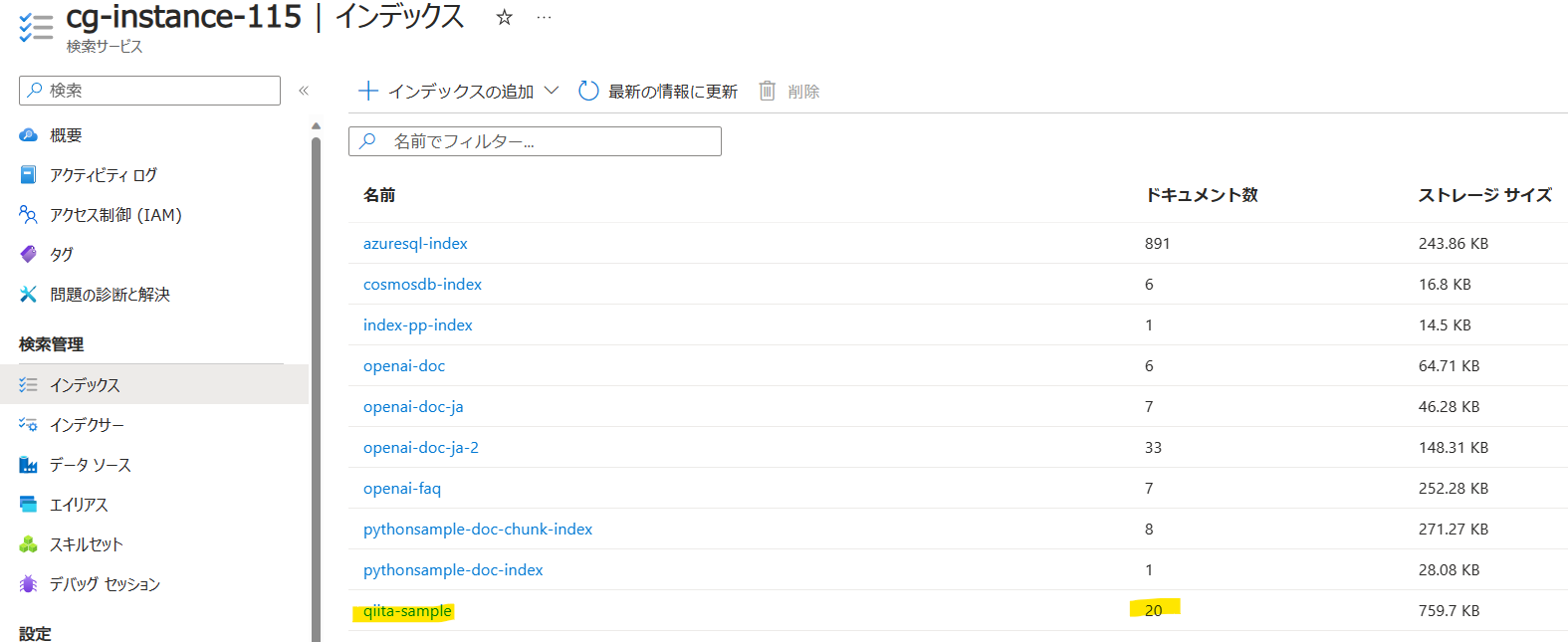
検索を実行してみると確かにインデックスが作成されていることが確認できました!
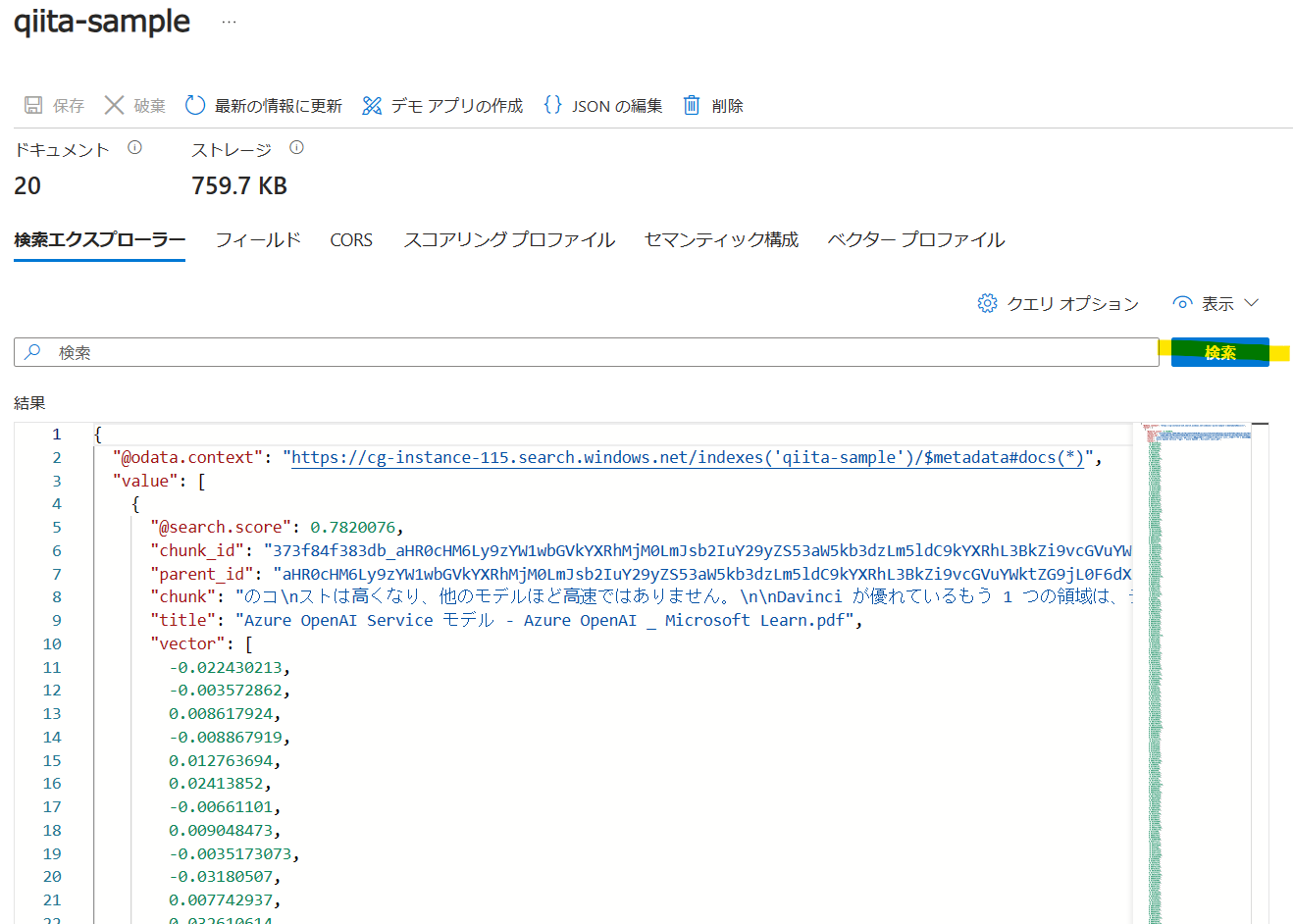
言語アナライザーはデフォルトの英語(泣)
23年12月1日追記
言語アナライザーを日本語にする方法について解説しました!簡単にできるので、希望を捨てずお試しください!
考察
今回GUIからチャンク分割+ベクトル化ができるようになったのでとても便利になりました。個人的に今回の大きなアップデートは1ドキュメントに対して複数レコードをインデックスとして登録できるようになった事です。今までは1ドキュメントに対して原則1レコードしか登録できませんでした。従って、インデクサーを2回使って裏技みたいな形でチャンク分割+ベクトル化を行っていました。
それが、今回「Index projections」機能の登場により、チャンキング後のテキスト情報を複数のレコードにマッピングすることが可能になりました。また、「Azure OpenAI Embedding skill」がネイティブにサポートされたことによりカスタムスキルを自分で作成する必要がなくなりました。「Text Split skill」もチャンク分割ようにアップデートされました。
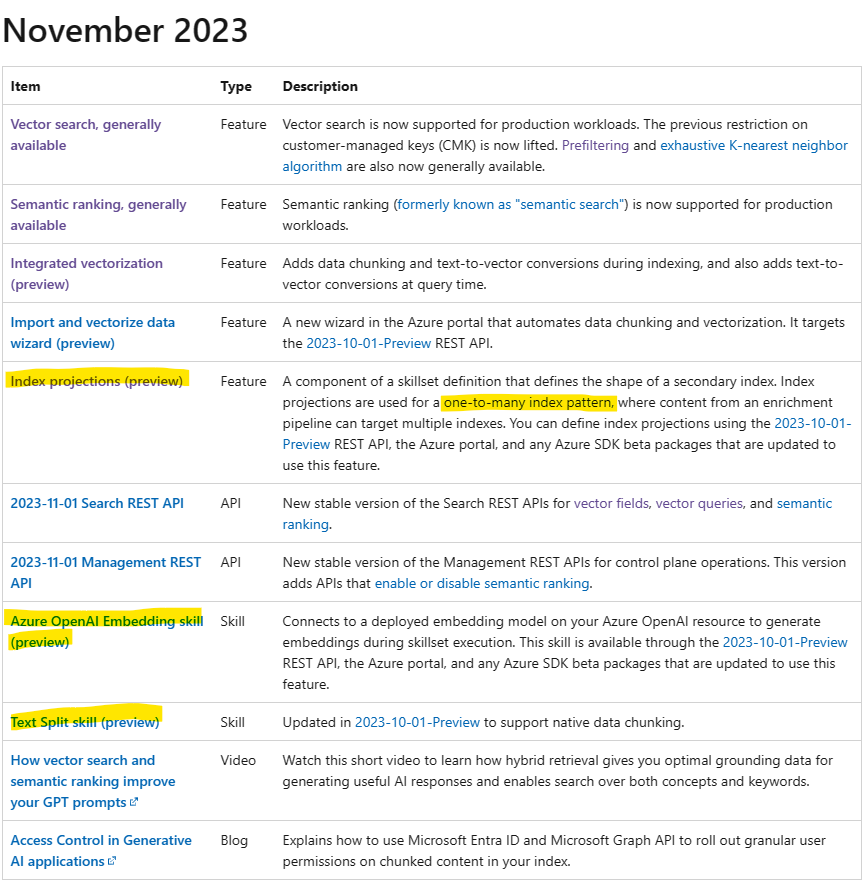
これらのスキルセットを上手く設定してあげれば、言語アナライザー日本語+チャンク分割+ベクトル化を比較的簡単に実現することが可能です。こちらのやり方に関しては次回の記事で紹介したいと思います!
->23年12月1日に記事書きました!