PDF等で保存されたドキュメント(非構造化データ)をデータ化して、検索できるようにしたい、という悩みはありませんか?
Azure Cognitive Searchを使えば、様々なドキュメントから情報を抽出・インデックス化し、それらに対して迅速に検索を行うことができます。
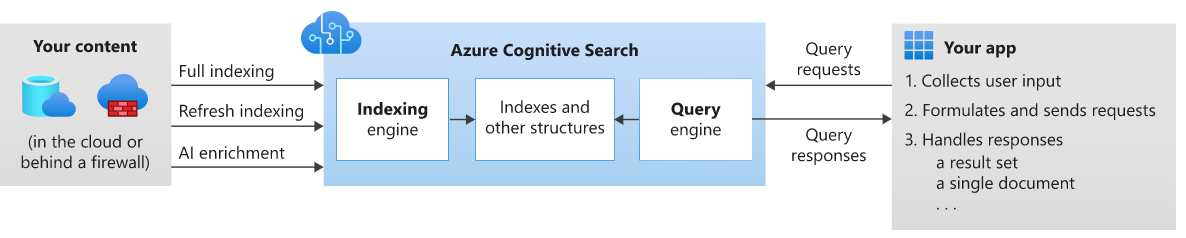
今回お話したいテーマですが、データからテキスト情報を抽出する際、内部では組み込みのOCRが自動でドキュメント抽出を行っているのですが、ドキュメントの種類によっては抽出精度がイマイチなケースがあります。
例えば、下記のように文章が中心のデータはうまく読み取ってくれます。
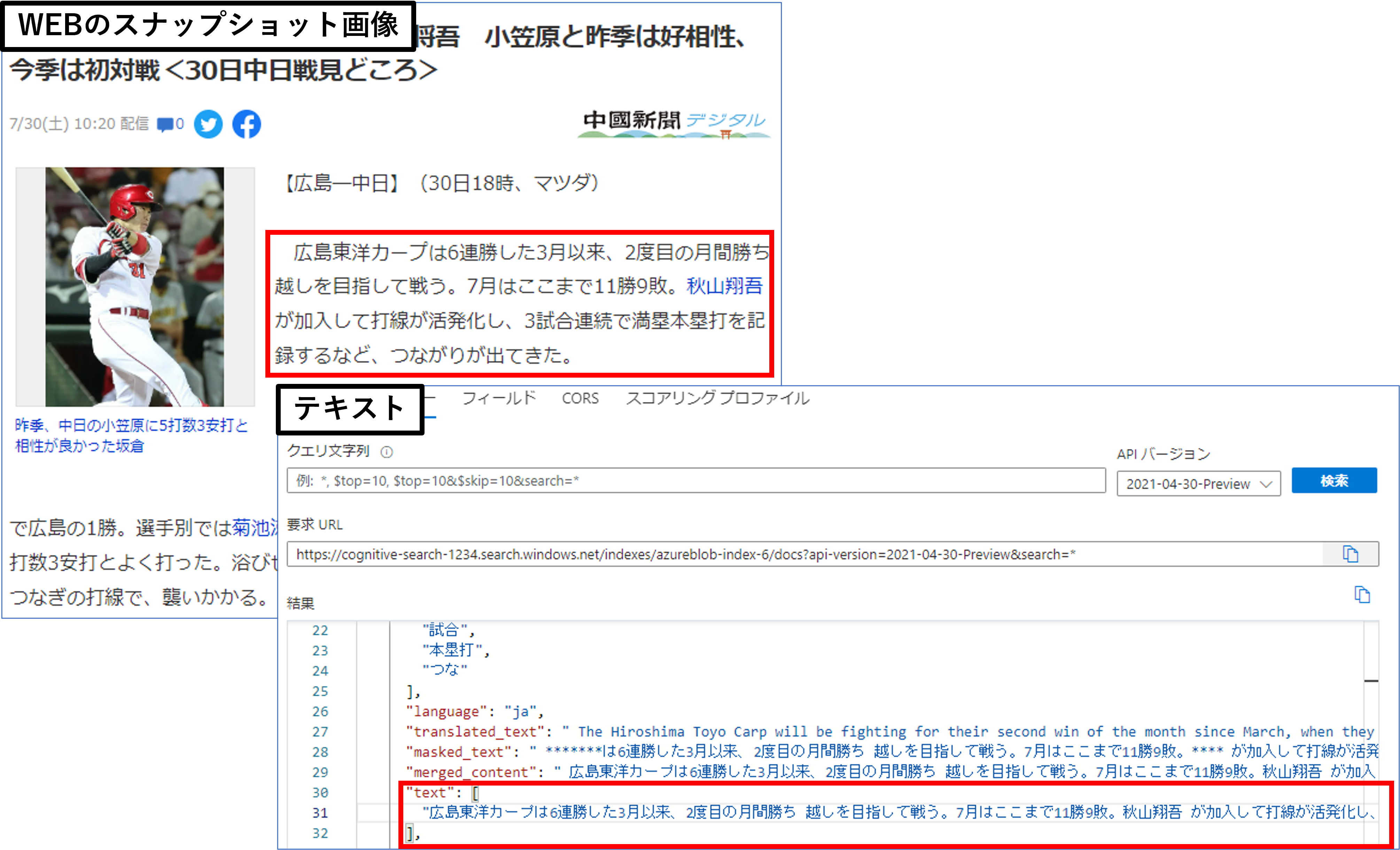
しかし、下記のように請求書や領収書等のフォーム形式のデータは自動抽出でうまく読み取ってくれないことがあります。そもそもこういった請求書はKey-Valueのペアで情報を抽出したいです。
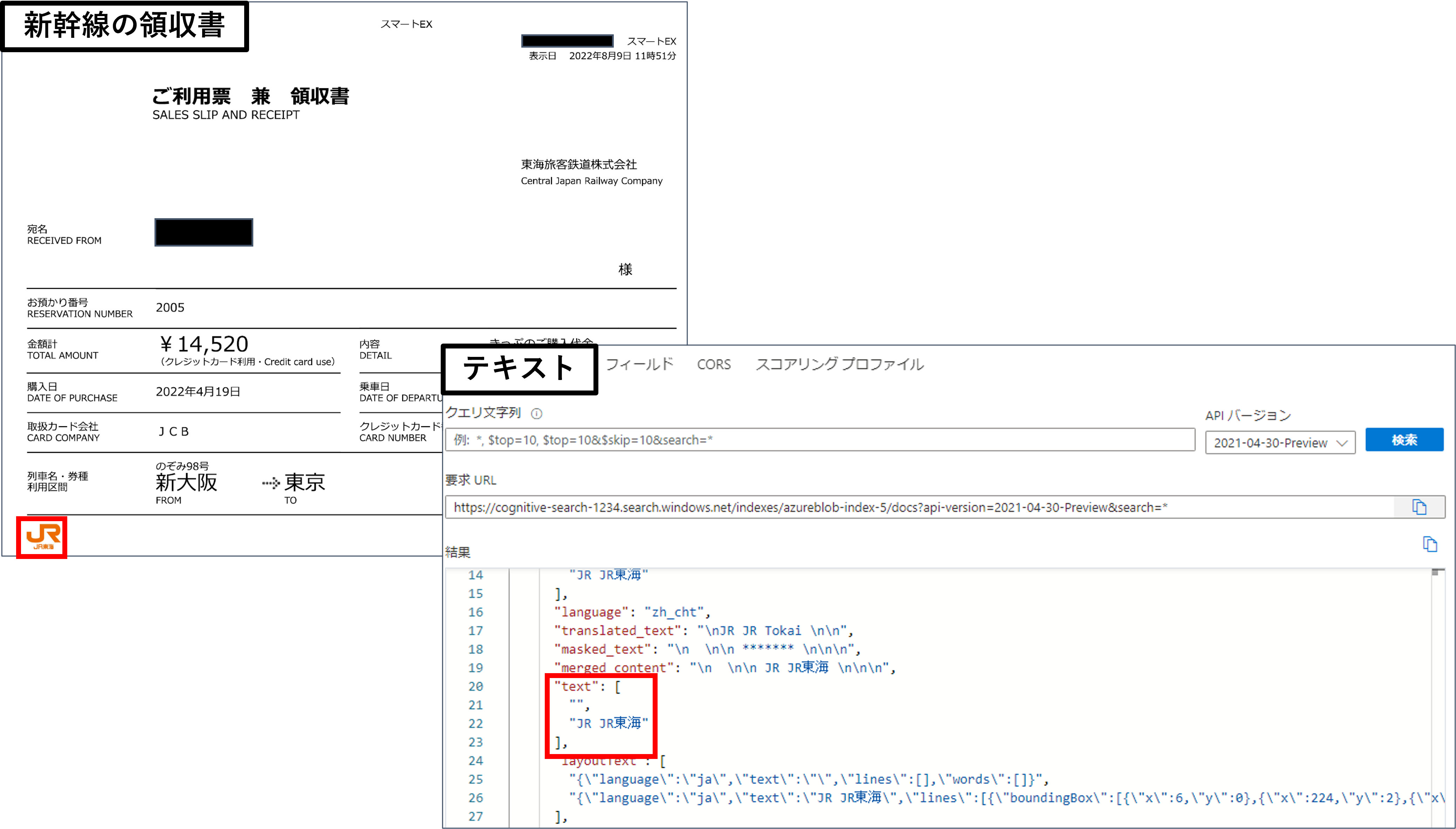
このようにフォーム形式のデータからKey-Valueのペアを抽出・インデックス化したい場合どのようにすればいいのでしょうか?これは「Azure Form Recognizer」と連携させることで実現できます。「Form Recognizer」とは、フォーム形式のデータに対してAIを活用することで高精度にKey-Valueやテーブルを取得できるサービスです。
今回のブログでは、Cognitive SearchとForm Recognizerの連携部分を具体的に解説していきたいと思います。公式ドキュメントはこちらをご参照ください。
インデックス作成時の処理フロー
「Cognitive Search」でドキュメントの検索を行いたい場合は予めインデックスを作成しておく必要があります。「Form Recognizer」と連携したい場合は下記のような処理フローとなります。
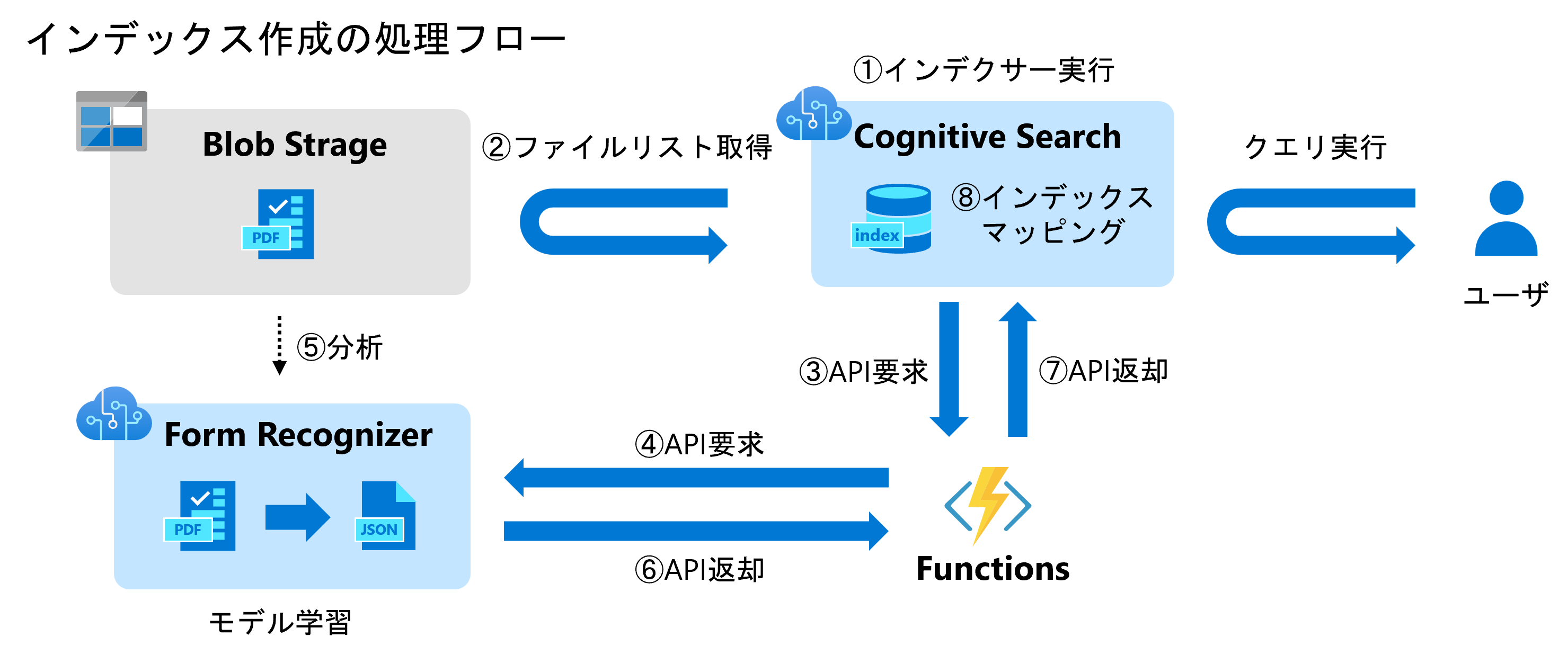
まず「Cognitive Search」からインデクサーを実行するとBlob等のデータソースからファイルリストを取得します。そのリストを入力に「Functions」をキックし、「Functions」はそのファイルリストを順番に「Form Recognizer」に投げます。「Form Recognizer」はドキュメントの抽出を行い、抽出結果を「Functions」に返します。「Functions」は最終的な抽出結果を「Cognitive Search」に返却し、最後に「Cognitive Search」が抽出結果をインデックスにマッピングします。
これらのフローを3回に分けて解説したいと思います。
- Form Recognizer編:ドキュメントからテキストを抽出する方法[フロー④~⑥]
- Azure Functions編:Form RecognizerのAPIラッパーの実装方法[フロー③⑦]
- Cognitive Search編:カスタムAPIとインデックスの設定方法[フロー①②⑦]
今回はForm Recognizer編ということで、ドキュメントからテキスト情報を抽出する方法を解説し、最後はAPIで実行するところまで解説します。
Form Recognizer
それでは「Form Recognizer」の基本的な使い方を見ていきましょう。
データ準備
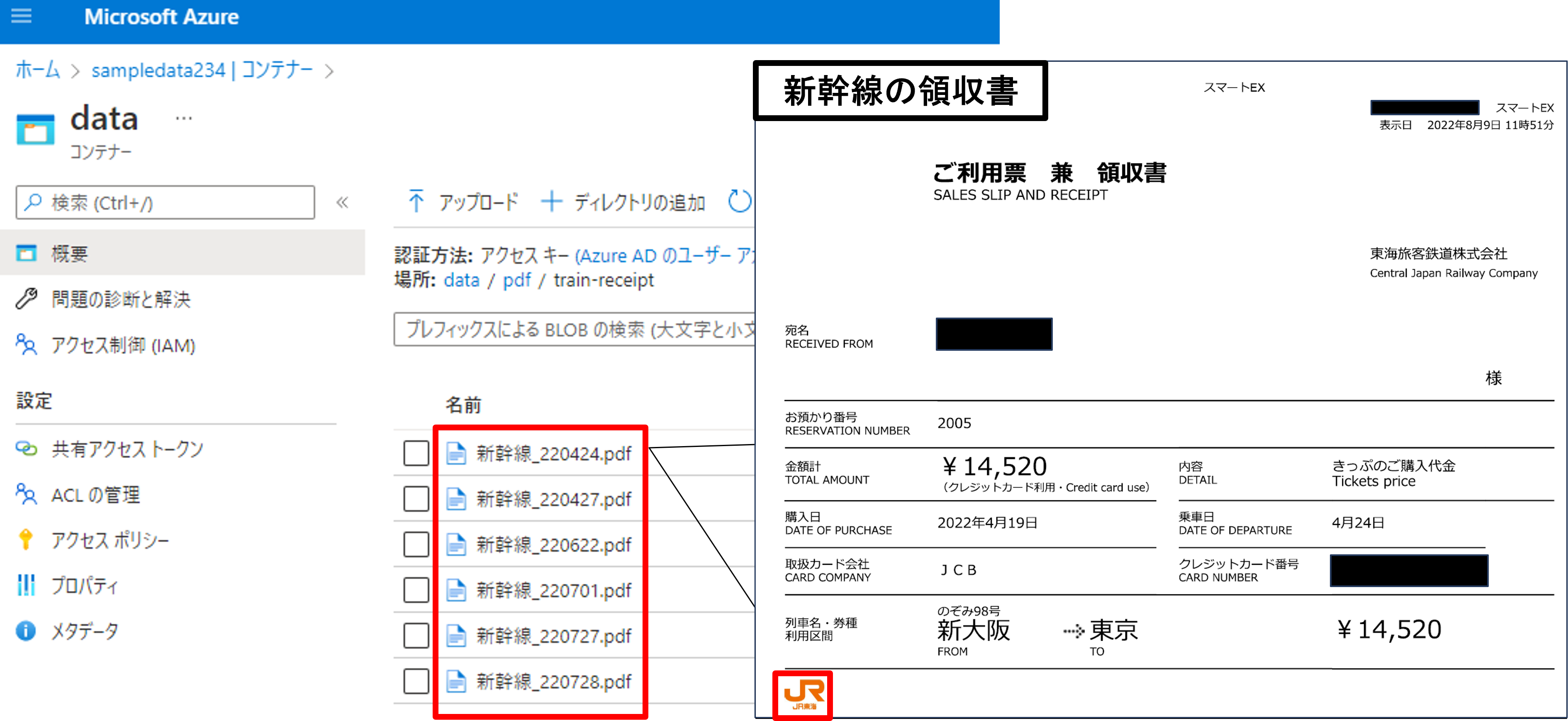
まずは読み取りたいデータをストレージにアップロードします。
今回は「Azure Data Lake Strage」に新幹線の領収書のサンプルをいくつかアップロードしました。
リソースの作成
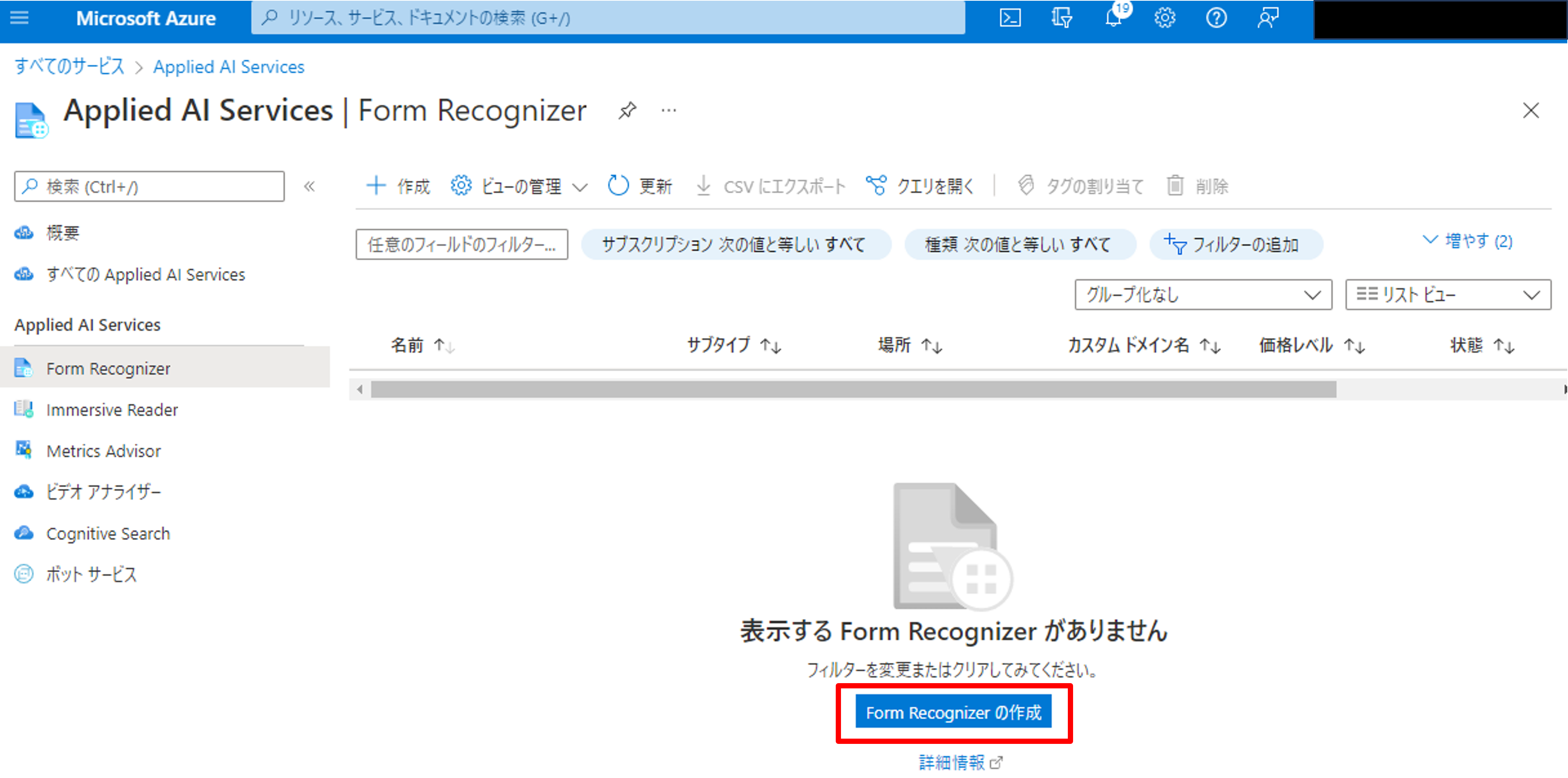
Azure Portalから「Form Recognizer」で検索し、リソースを新規作成しましょう。
リソースグループに指定がなければ新規作成、リージョンを選択、名前を入力しましょう。
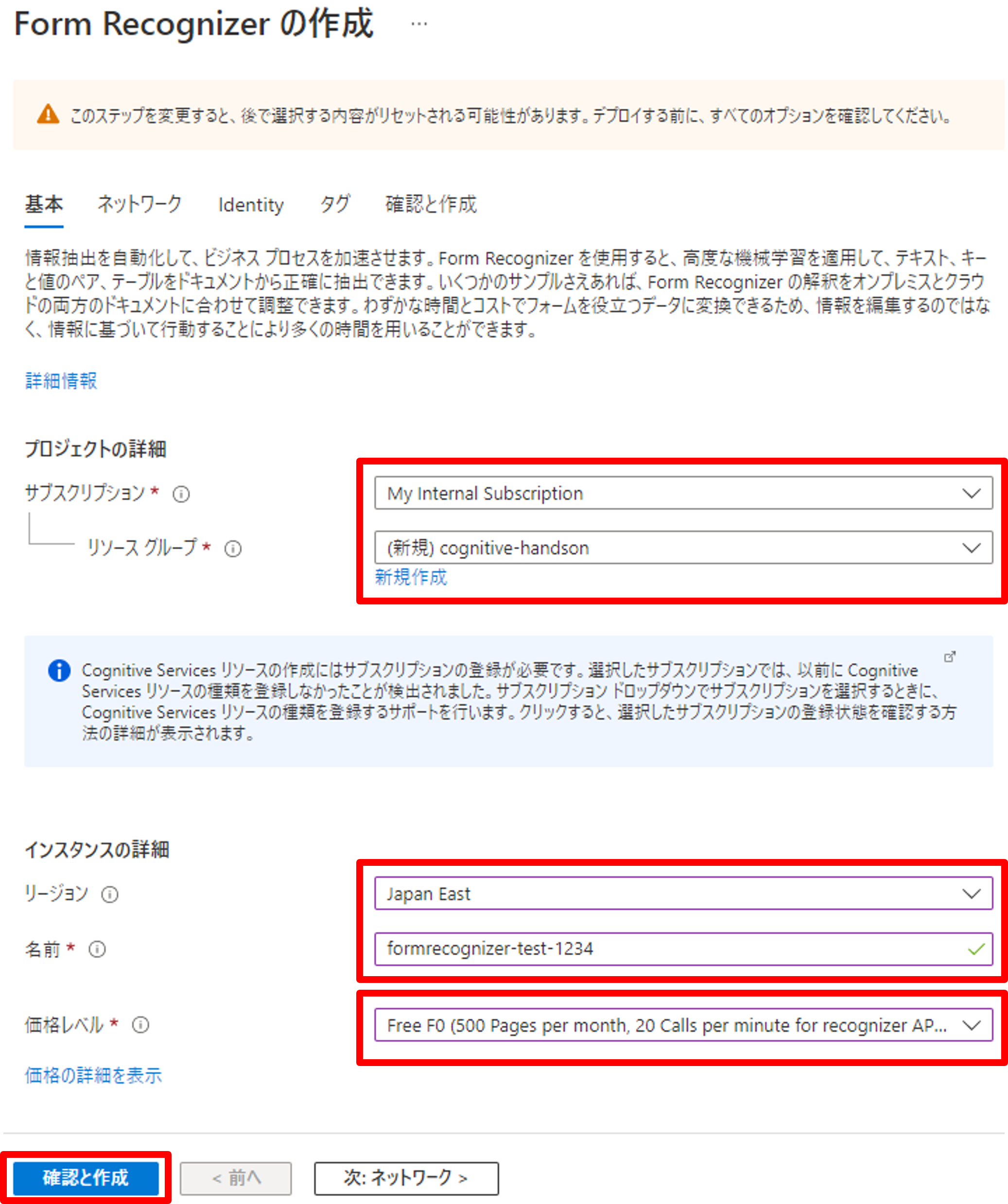
Form Recognizerは分析したドキュメントのページ数で従量課金されます(モデルのトレーニングに課金は発生しません)。価格レベル「Free F0」は月500ページ、1分間に20コールの制限はありますが、無料で使えますので今回はこちらを選択します。料金の詳細は公式をご参照ください。
最後にリソースのデプロイが完了したことを確認しましょう。
ドキュメントの分析
Form Recognizerでは次のモデルを使用してドキュメントの分析ができます。
- ドキュメント分析モデル:一般的なドキュメントや画像からテキストやKey-value、テーブルを抽出
- 事前構築モデル:請求書やレシート、名刺から重要な情報を抽出
- カスタムモデル:フォームとドキュメントからユースケース固有の情報を抽出
詳しくは公式ドキュメントをご参照ください。
今回はまずドキュメント分析モデルで抽出精度を確認し、次にカスタムモデルで分析します。
分析にはForm Recognizer StudioというWEBブラウザでインタラクティブに分析できるサイトを使います。22年8月時点でv3.0がプレビューとなっていますのでこちらを使いたいと思います。リンクに関してはAzure Portalに記載されていないので、こちらの公式からアクセスしてください。
リンクをクリックすると下記のような画面に遷移します。
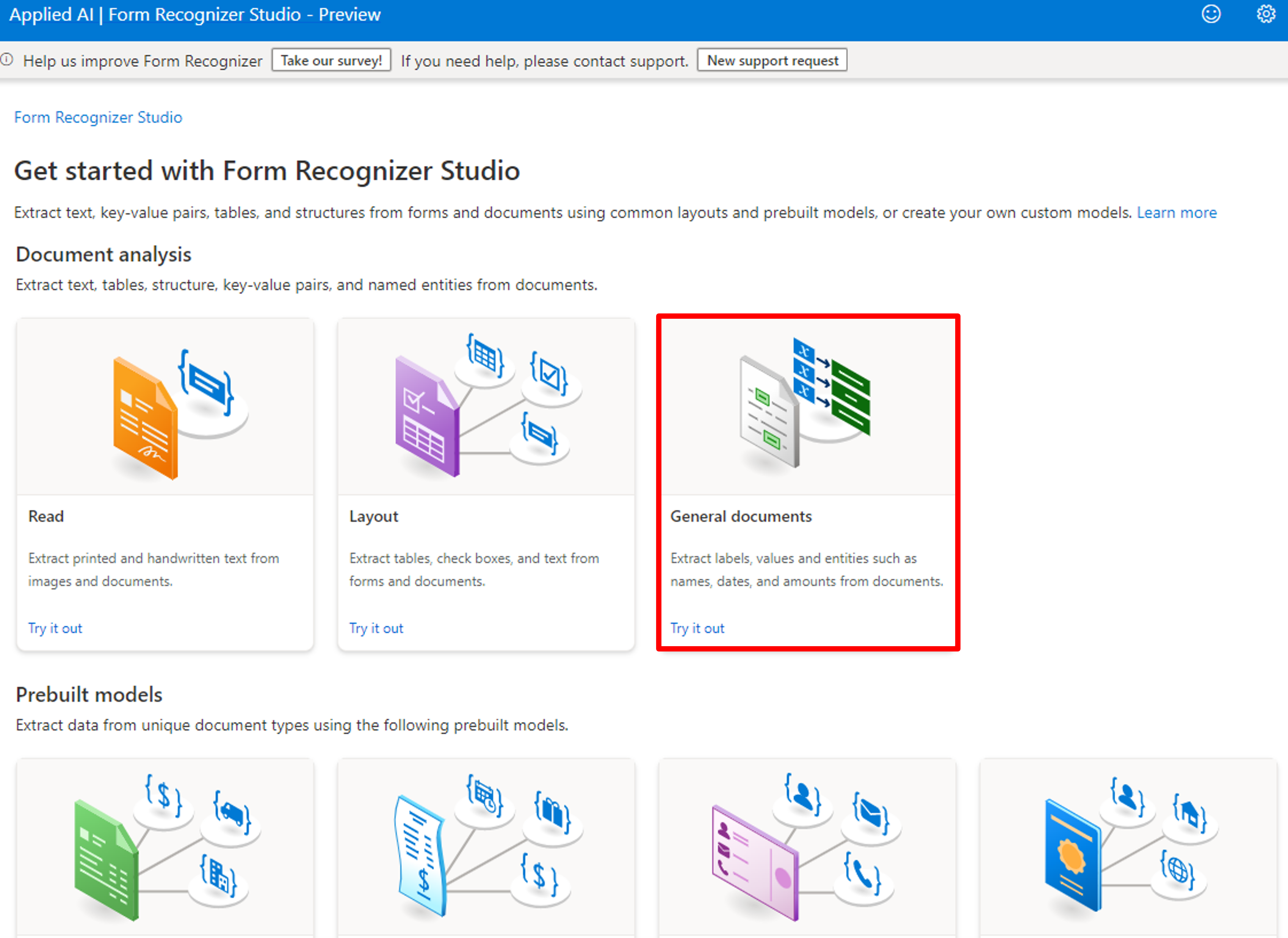
ドキュメント分析の中でも以下の3つが利用できます。
- Read(読み取りモデル):ドキュメントや画像からテキスト行、単語、場所、検出された言語を抽出します。
- Layout(レイアウトモデル):ドキュメントや画像からテキスト、テーブル、選択マーク、構造情報を抽出します。
- General documents(一般的なドキュメントモデル):ドキュメントからキーと値のペア、選択マーク、エンティティを抽出します。
今回はKey-Valueのペアを取得したいので、「General documents」を選択します。
左の「Browse for a file」からファイルをアップロードし、「Analyze」をクリックしましょう。
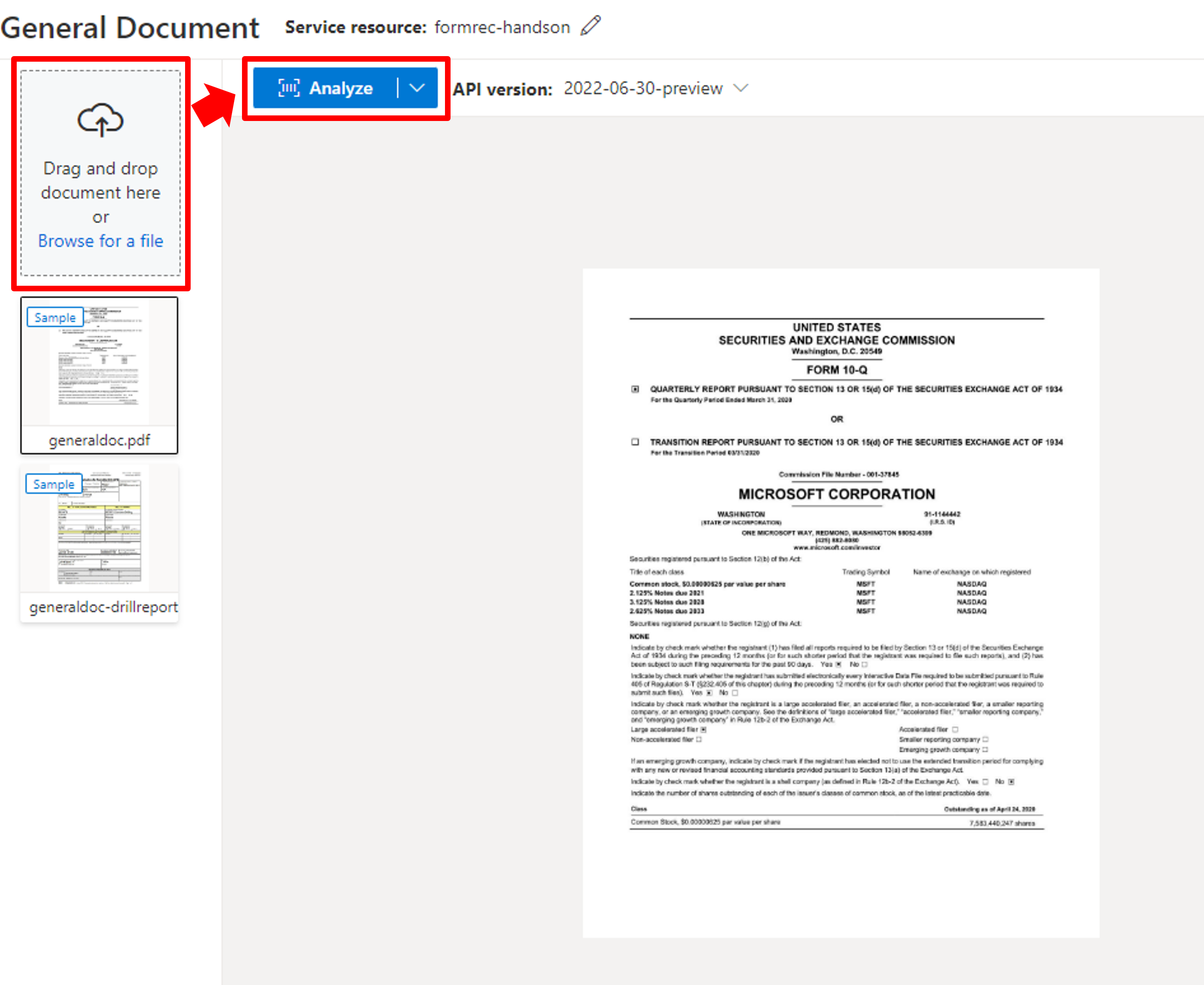
分析が終了すると、分析結果(Key-Value)が右側に表示されました。
今回の領収書は項目名が日本語/英語の両名で書かれていて、Keyは英語で概ね正しく取得できています。しかし、key-valueの組み合わせが正しい項目もあれば、間違っている項目もあります。使わない項目であればそこまで気にする必要はありませんが、名前やTicketPriceが取れていないので、このモデルを使うのはやめた方が良さそうです。
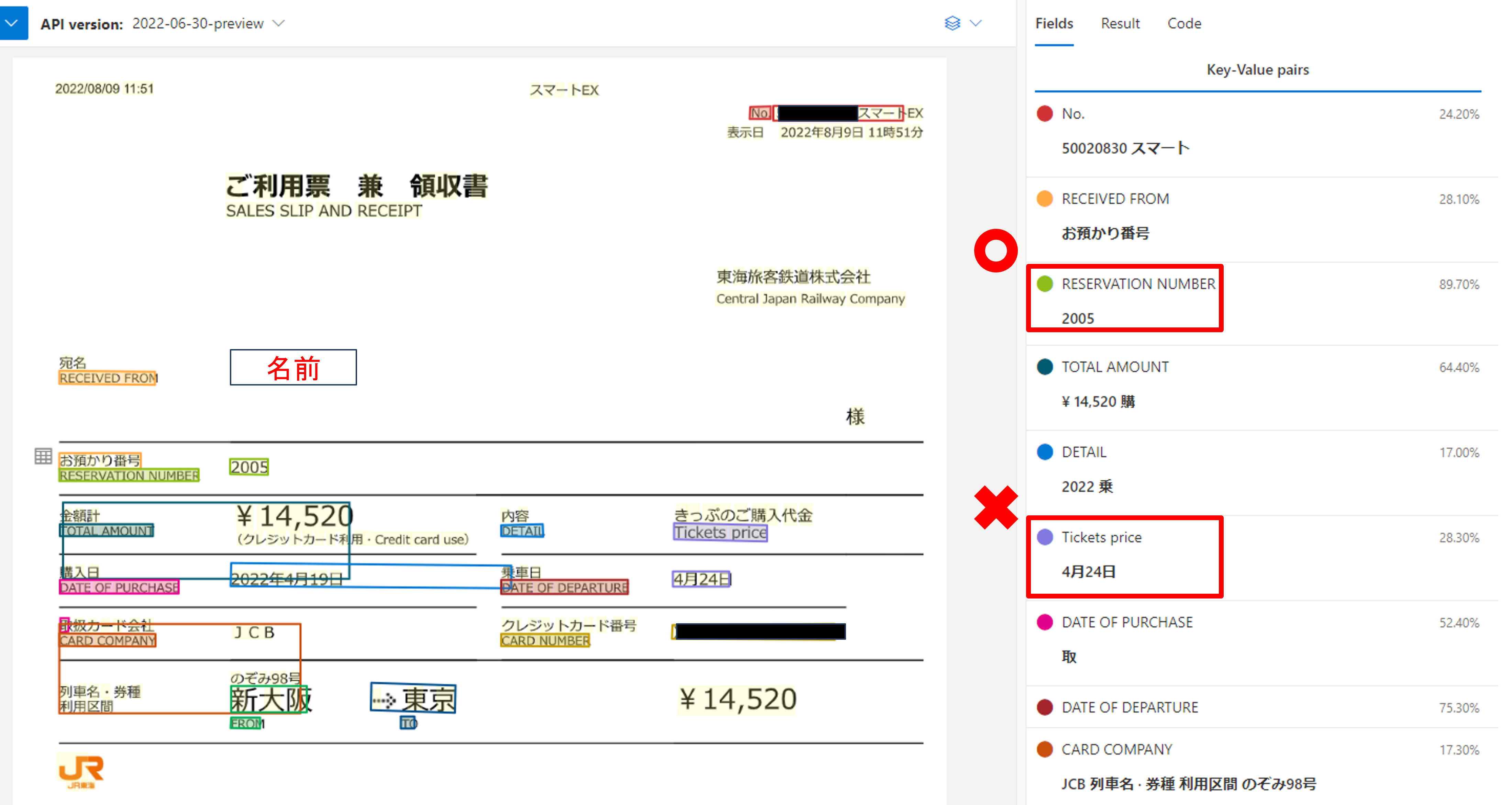
次にカスタムモデルを試してみましょう。Studioのトップページに戻り、一番下の「Custom model」を選択しましょう。
[Create a project]からプロジェクトを新規作成し、プロジェクト名を入力します。
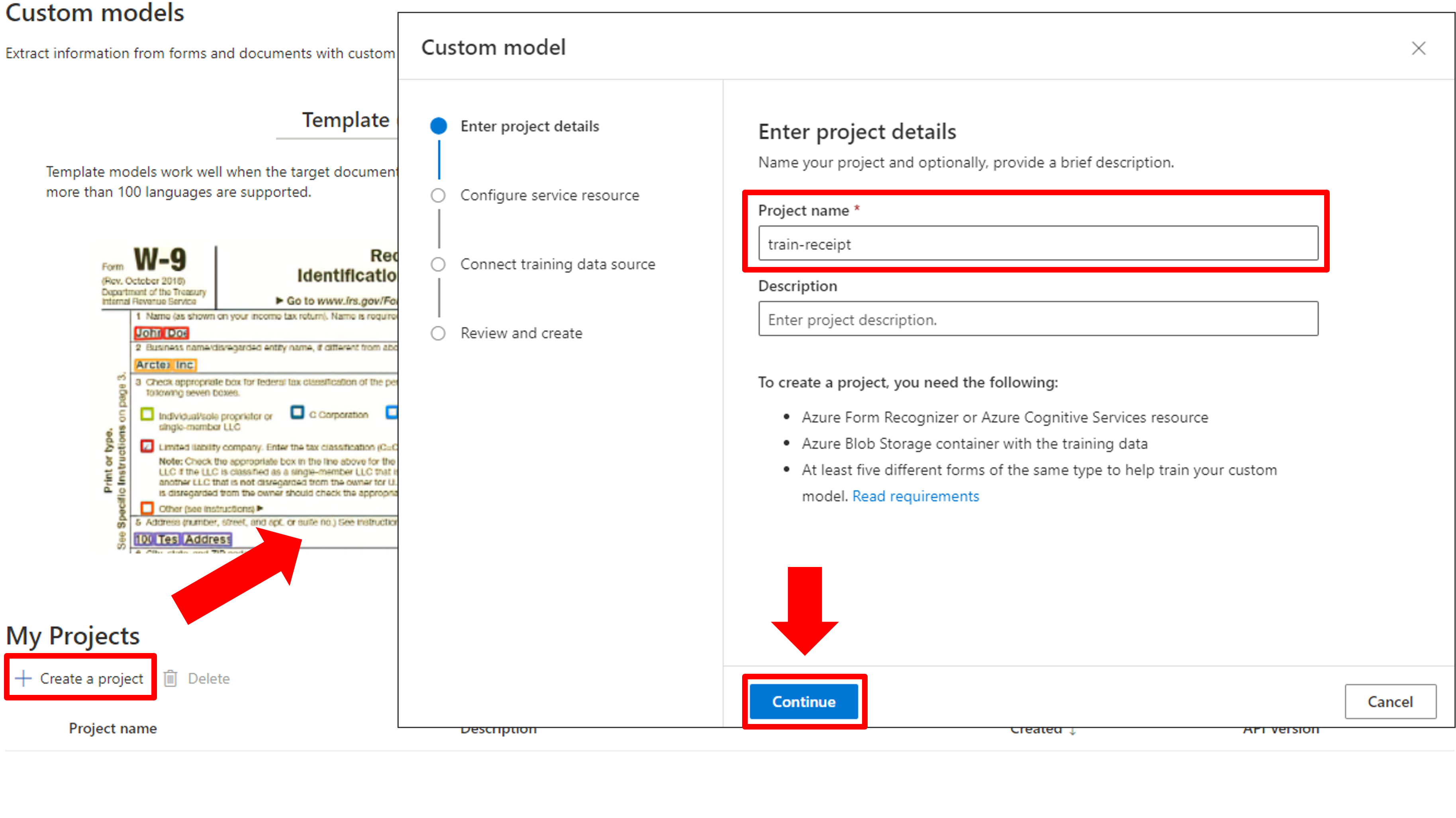
サブスクリプション名・リソースグループ・先ほど作成したForm Recognizerのリソース・APIバージョンを選択します。
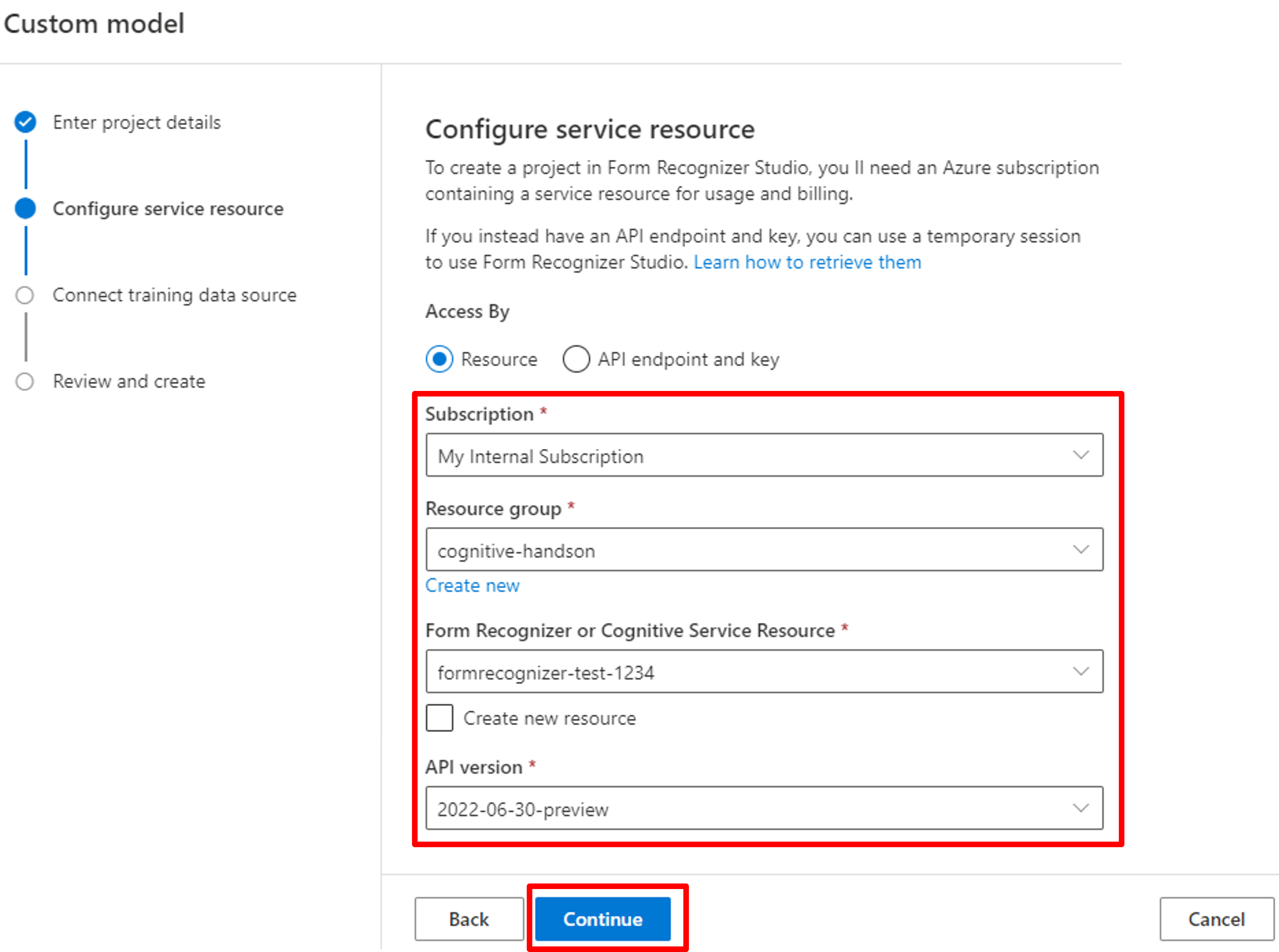
学習データの場所に関して、サブスクリプション名・リソースグループ・ストレージアカウント・コンテナ名を選択し、フォルダーパスを入力します。
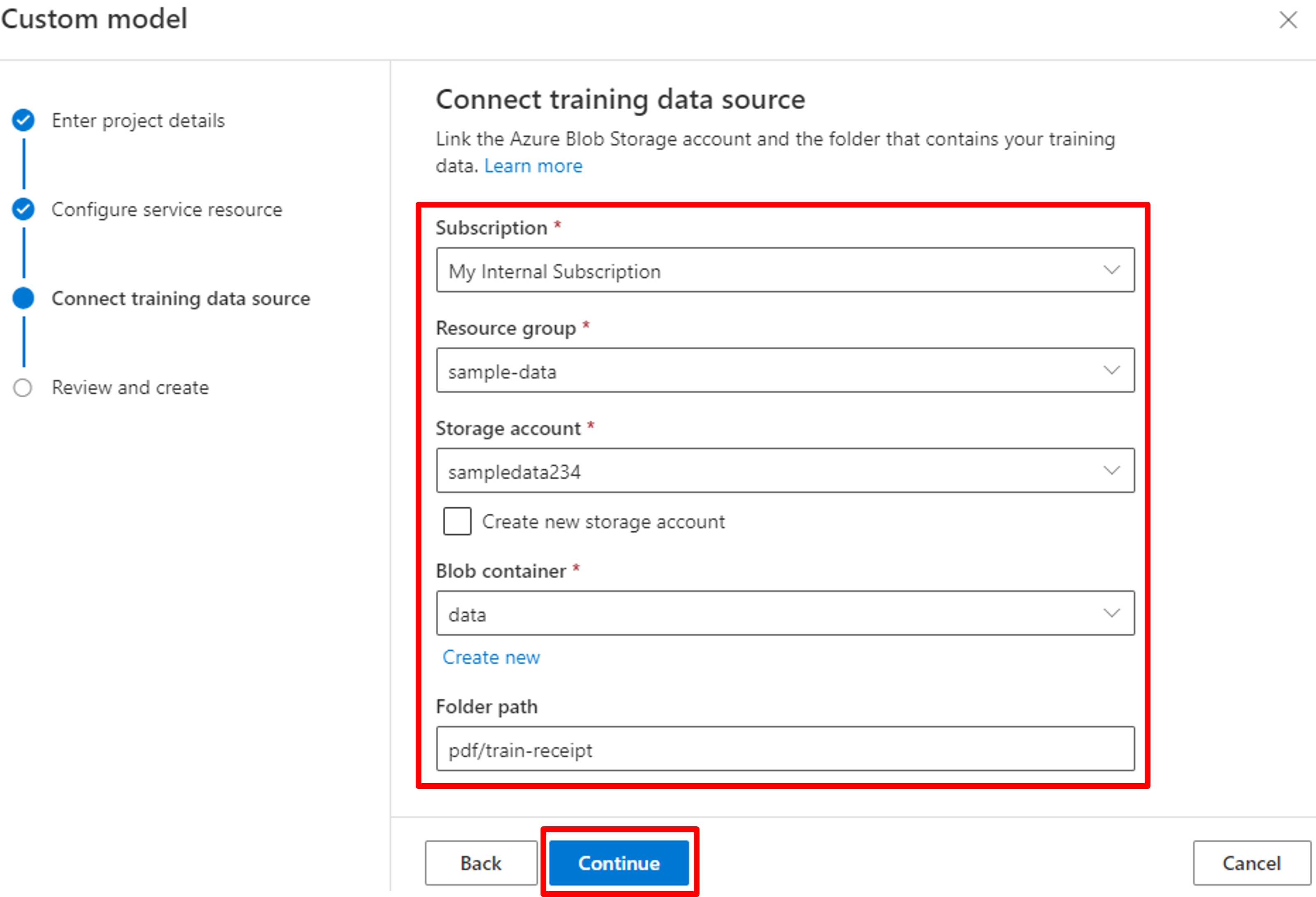
設定を確認し、[Create project]をクリックしましょう。
データラベリングとモデル学習
プロジェクト作成が完了すると下記のような画面に遷移します。
[Label Data]->[Region]からデータにラベル付けしていきます。
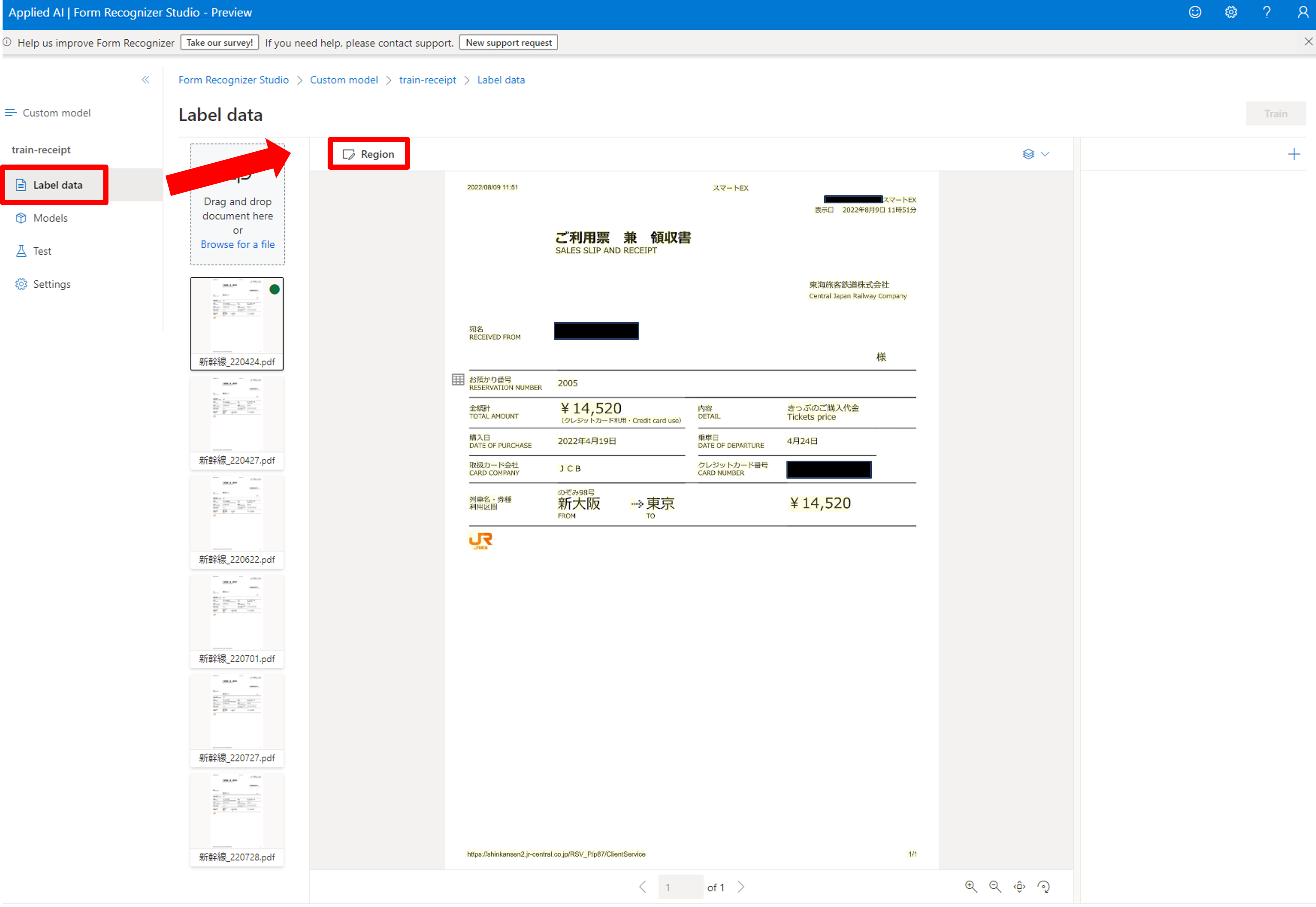
認識させたい部分をボックスで囲み、フィールドの種類を選択、フィールド名を入力します。フィールド名はCognitive Searchでパスに含まれるので英語で空白無しにすることを推奨します。
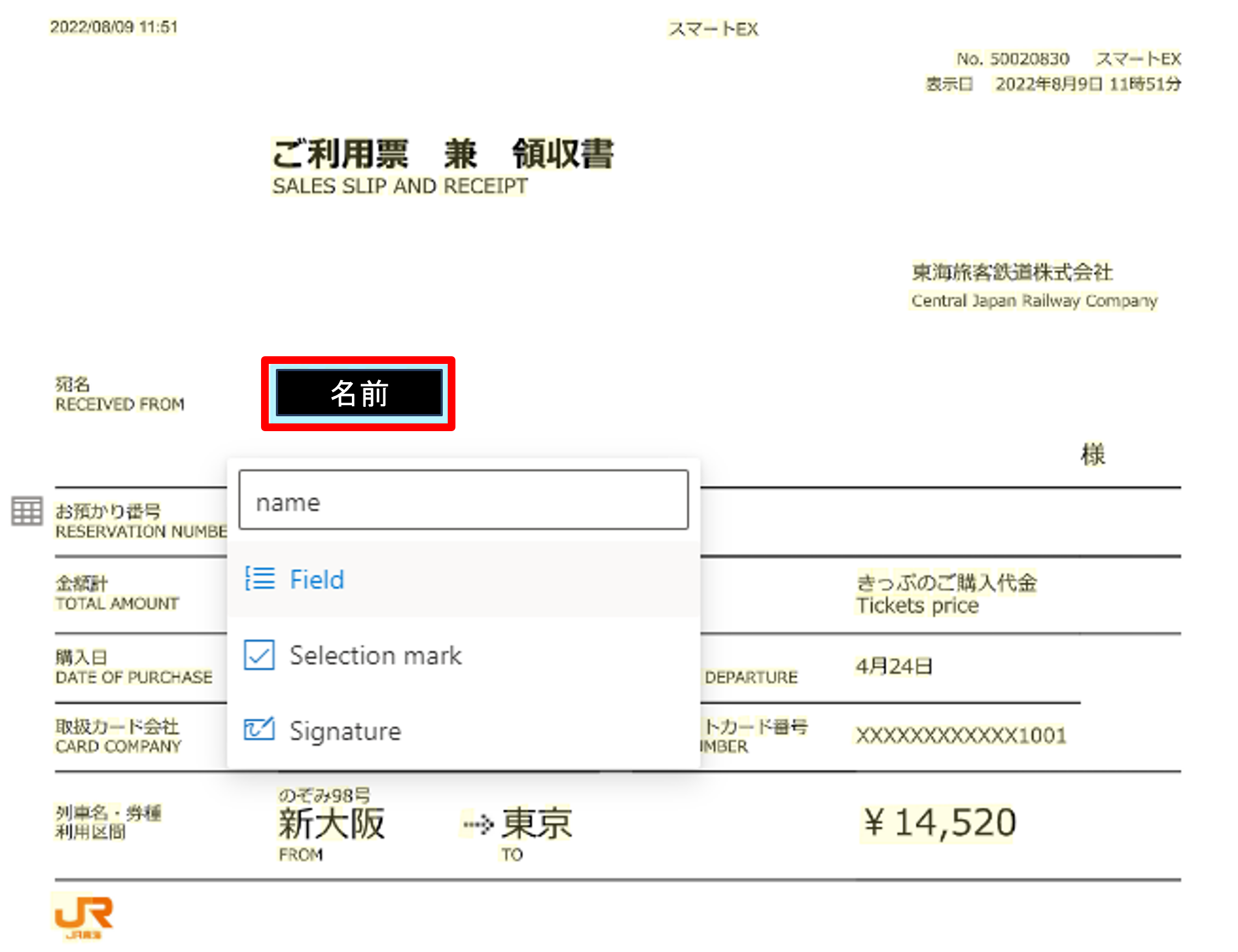
抽出したい部分をすべてラベル付けすると下記のような画面になります。

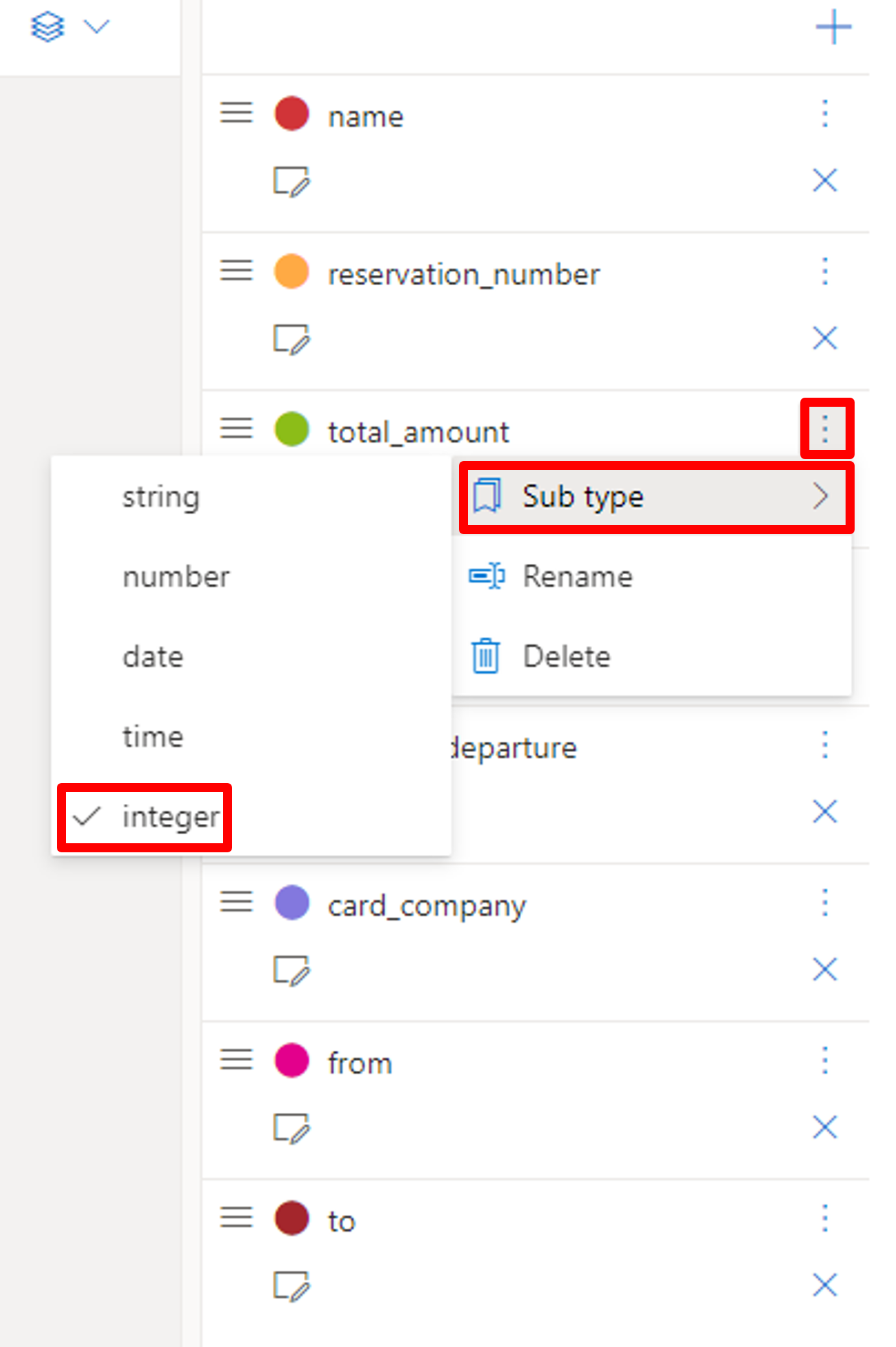
次にフィールドの変数の型を指定しておきましょう。例えば、total_amount(金額)は数値として抽出したいので、「integer」を選択します。
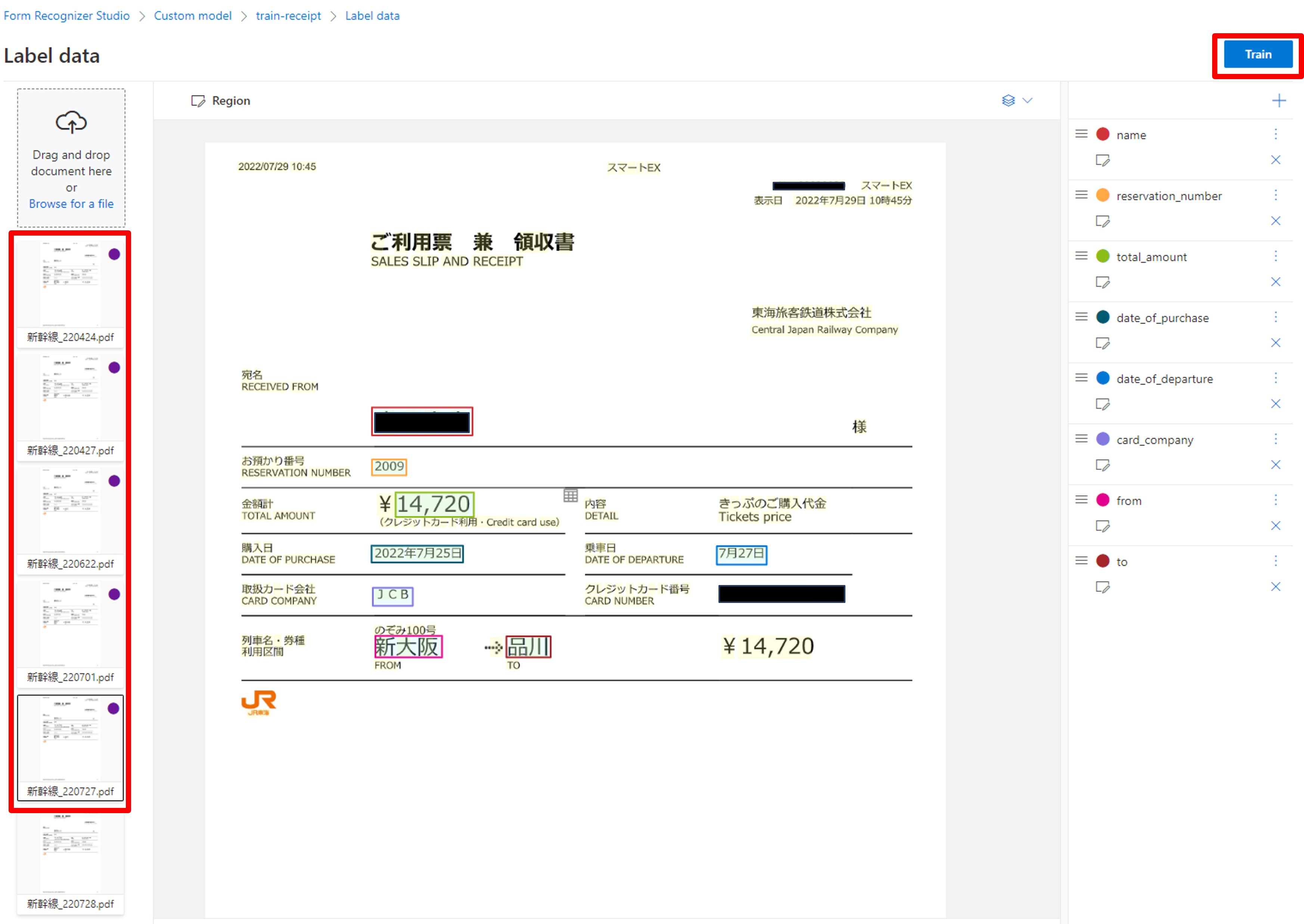
これらのラベル付けを最低5ファイルは行ってください(公式参照)。多ければ多いほど精度は良くなるのですが、今回は最低限の数にしておきます。ラベリングが終わりましたら、右上の[train]をクリックしましょう。
モデルIDを入力し、モデルの種類を選択します。
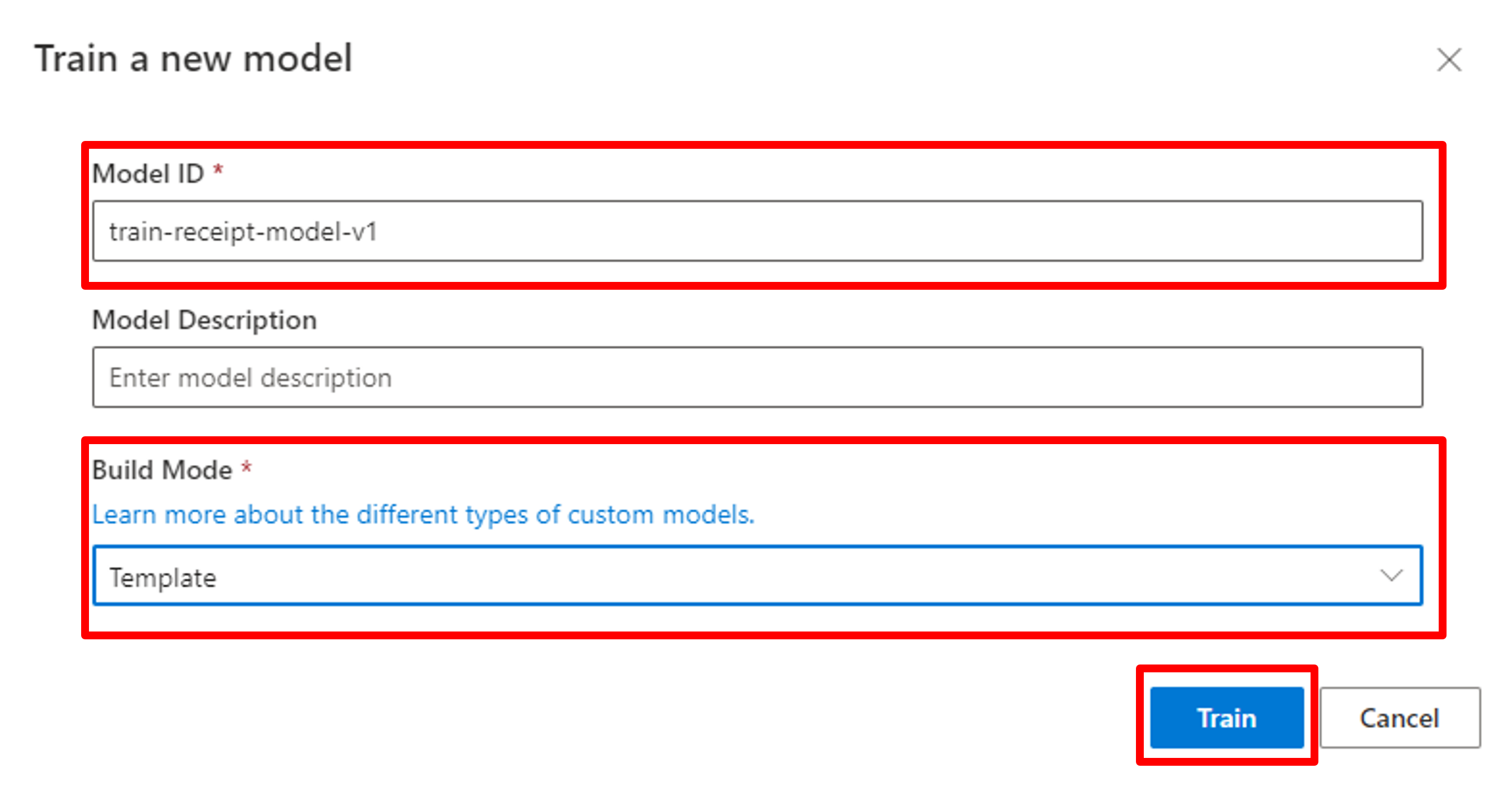
モデルの種類は下記の2種類があります。
- Template model:フォームの形式が固定されていて、決まった位置から情報を抽出したい場合に使います。
- Neural model:ディープラーニングを活用し、フォームが微妙に違う場合も調整して抽出したい場合に使います。
詳しくは公式ドキュメントをご参照ください。
実際のところ、Templateモデルもある程度の位置ずれは考慮して抽出してくれたりするので、今回は両方のモデルで結果がどのように変わるか見ていきます。学習が終了すると下記のようにステータスが「Succeeded」になります。
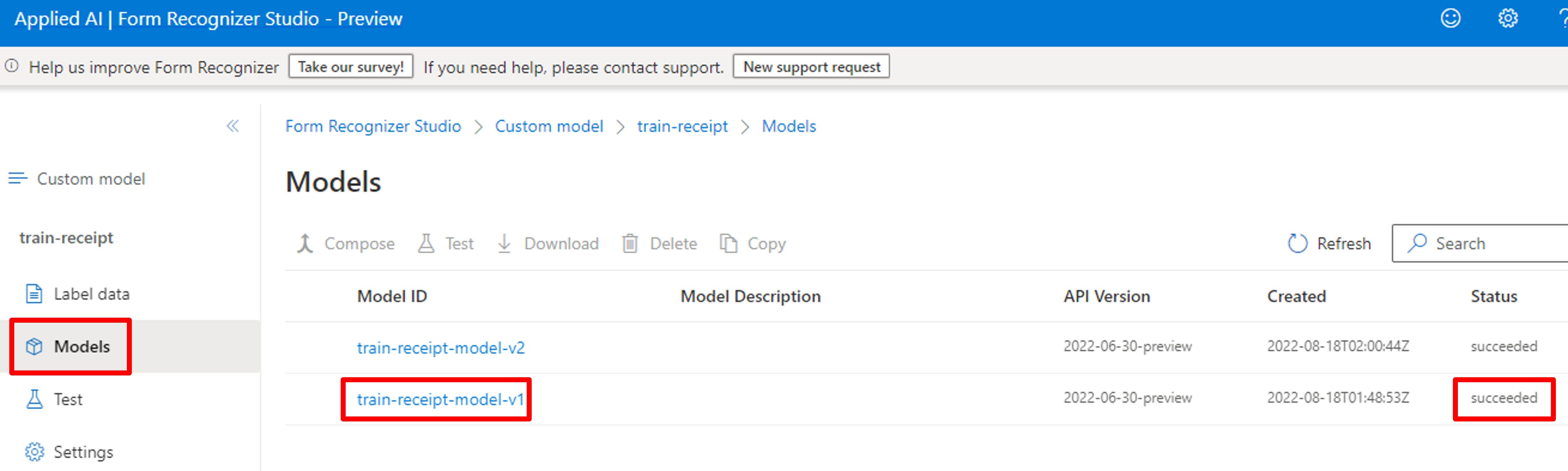
モデル検証
左メニュー[Test]->[Browse for a file]からテストデータをアップロードし、[Analyze]をクリックしましょう。
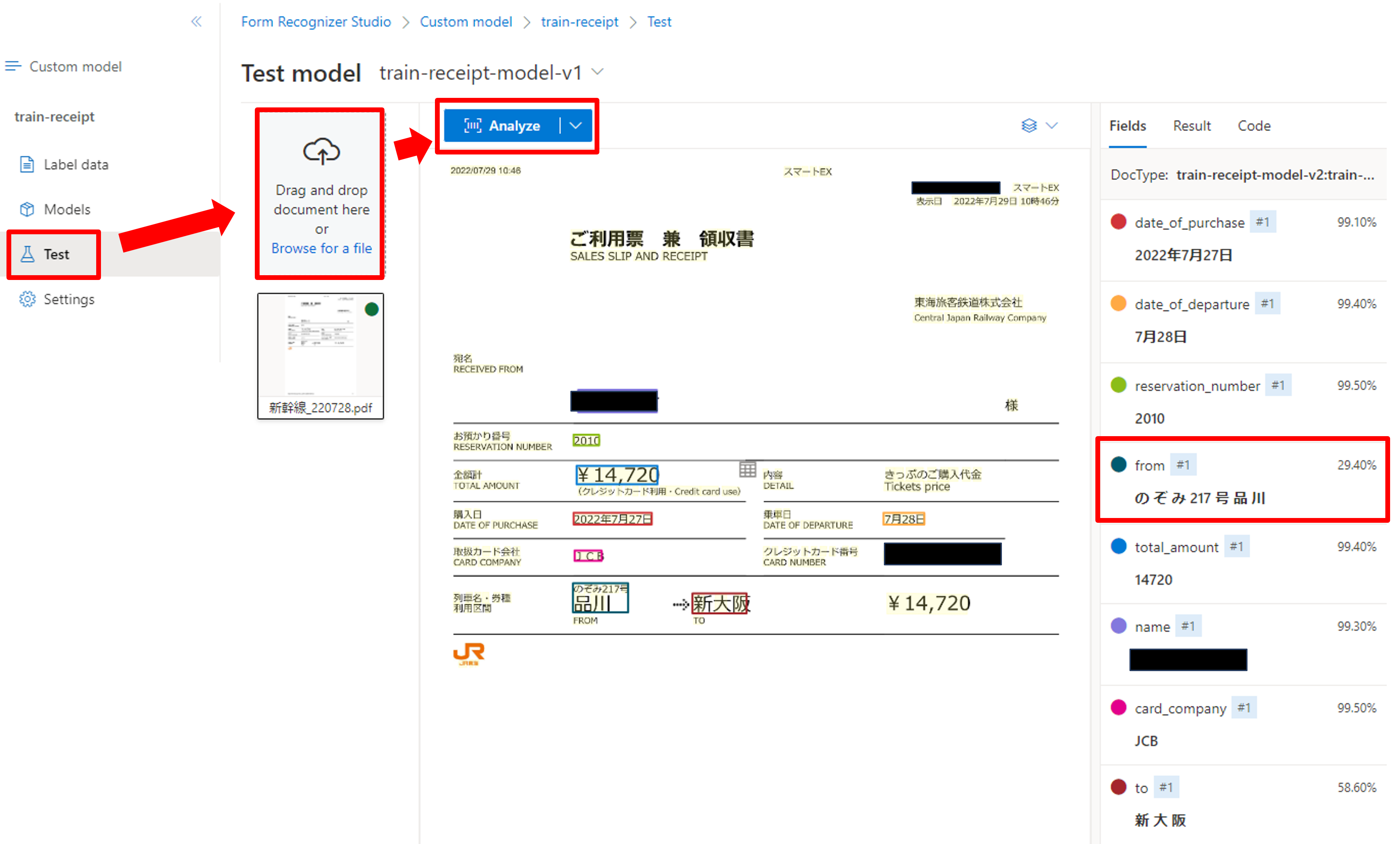
右側に分析結果が表示されます。各項目の右側には信頼度が合わせて記載されています。今回はほとんどの項目が正しく取得できていますが、「from」の項目だけ余計な文字まで拾っていますね。。今回の学習データにはドキュメントが1行改行されるパターンも含まれており、Templateモデル・少量データで抽出位置を正確に割り出すのは難しいかもしれないです。
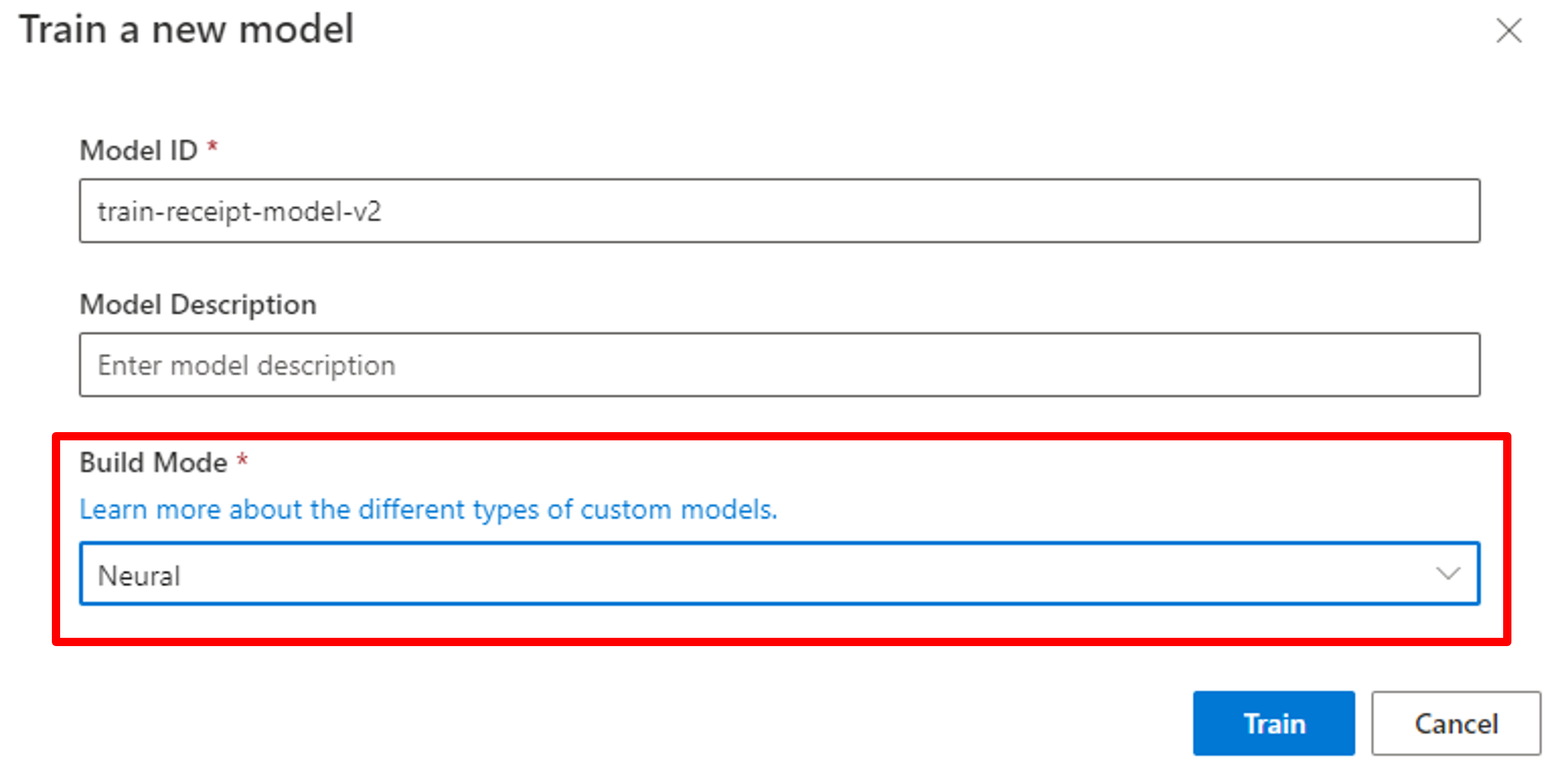
次に「Neural model」で試してみましょう。モデルの学習の部分で[Build Mode]を「Neural」にして学習させます。
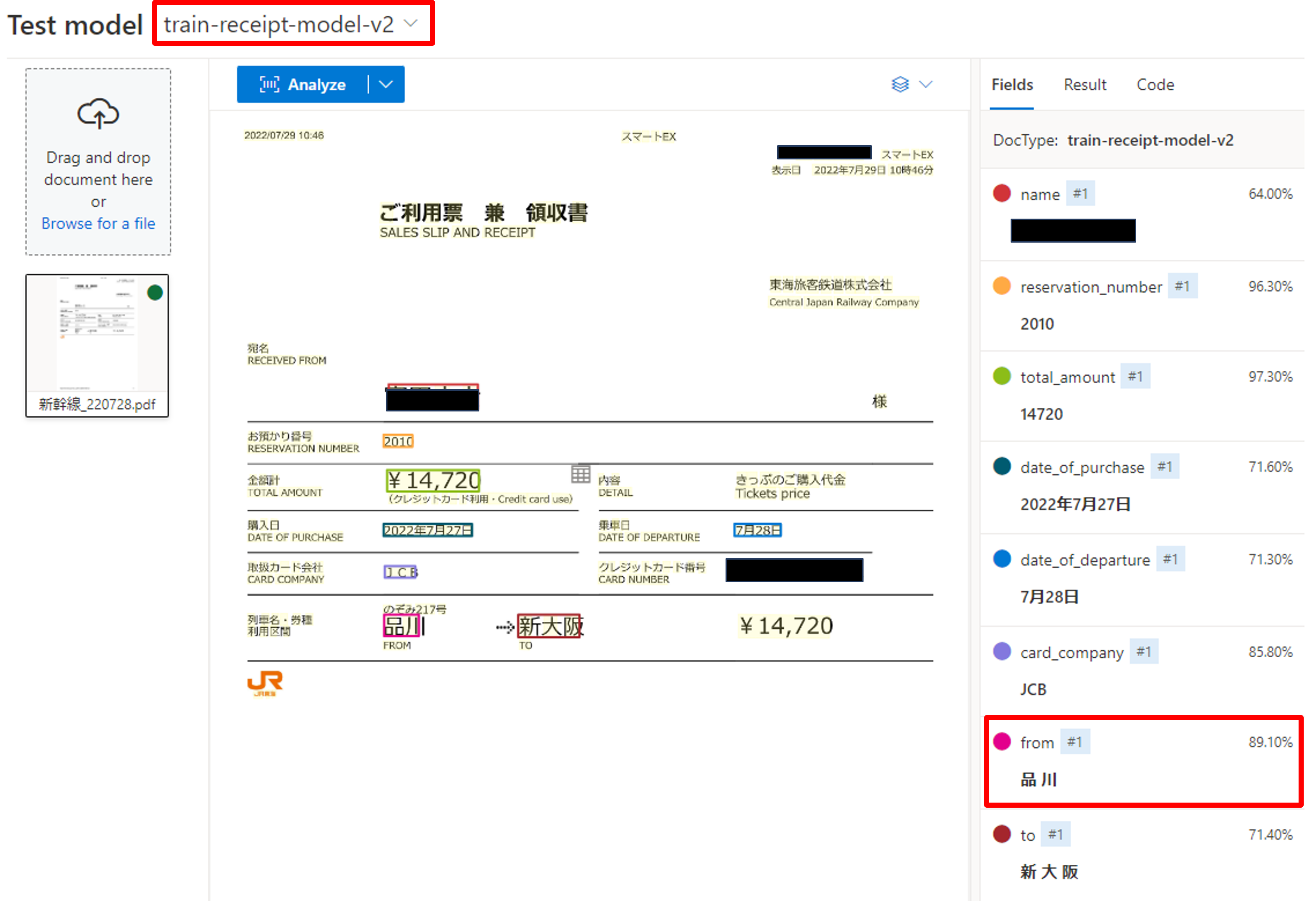
左の[Test]のタブを開き、上の部分でモデルIDを変更し、[Analyze]をクリックしましょう。今回は「from」も値も余分な部分がなく取得できていますね。
API実行
最後に学習したモデルに対してREST API経由でアクセスし、結果が正しく返ってくることを確認しましょう。APIのリファレンスはこちらに詳しく記載されています。
Form Recognizerの分析APIは非同期で実行されます。
従って、1.分析ジョブ実行(POST)->2.分析結果取得(GET)という2段構成でAPIを実行します。
1.分析ジョブ実行に関しては下記のフォーマットになります。
$ curl -v -i POST "{endpoint}/formrecognizer/documentModels/{modelID}:analyze?api-version=2022-06-30-preview" \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: {key}" \
--data-ascii "{'urlSource': '{your-document-url}'}"
「endopoint」と「key」はAzure Portalから取得。
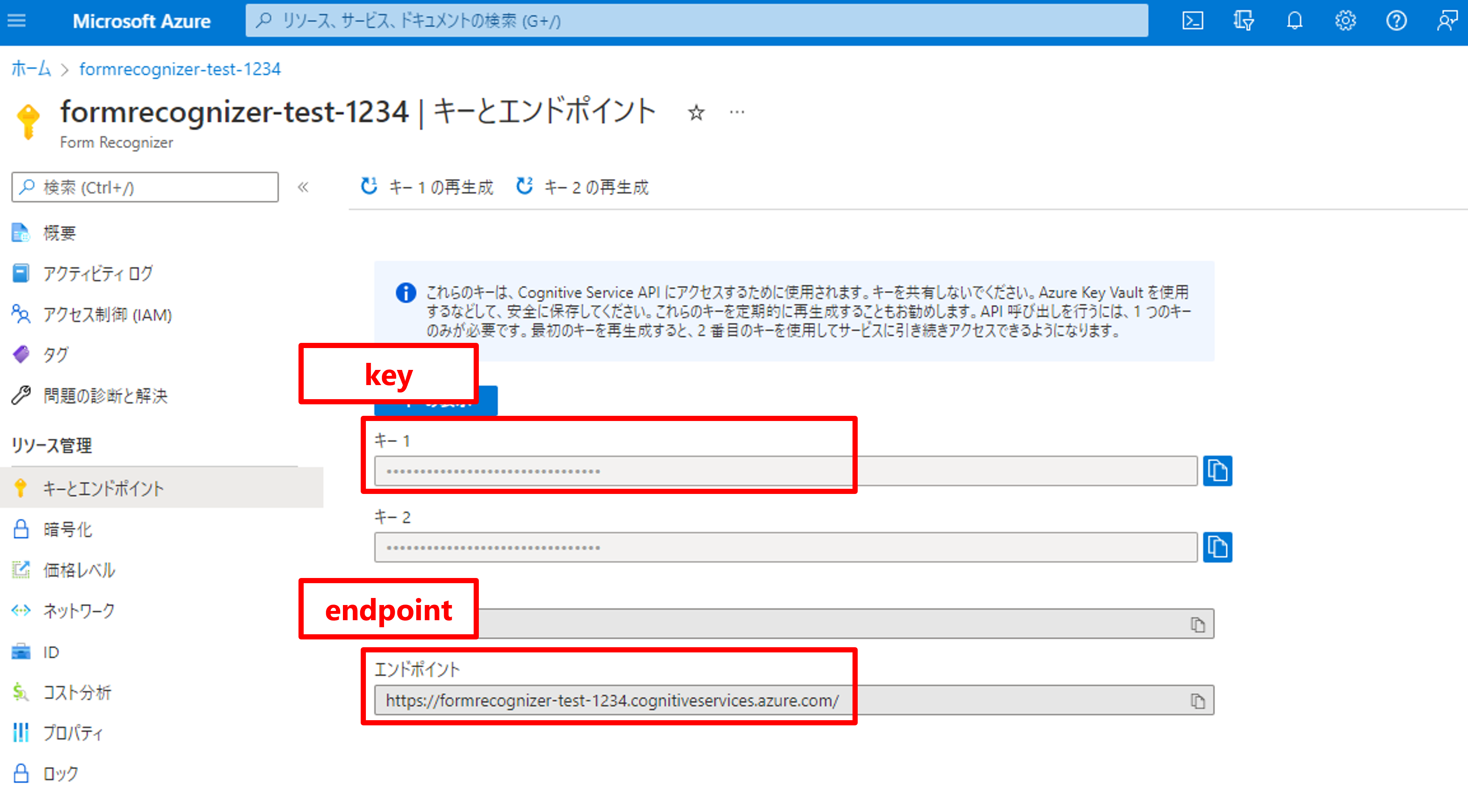
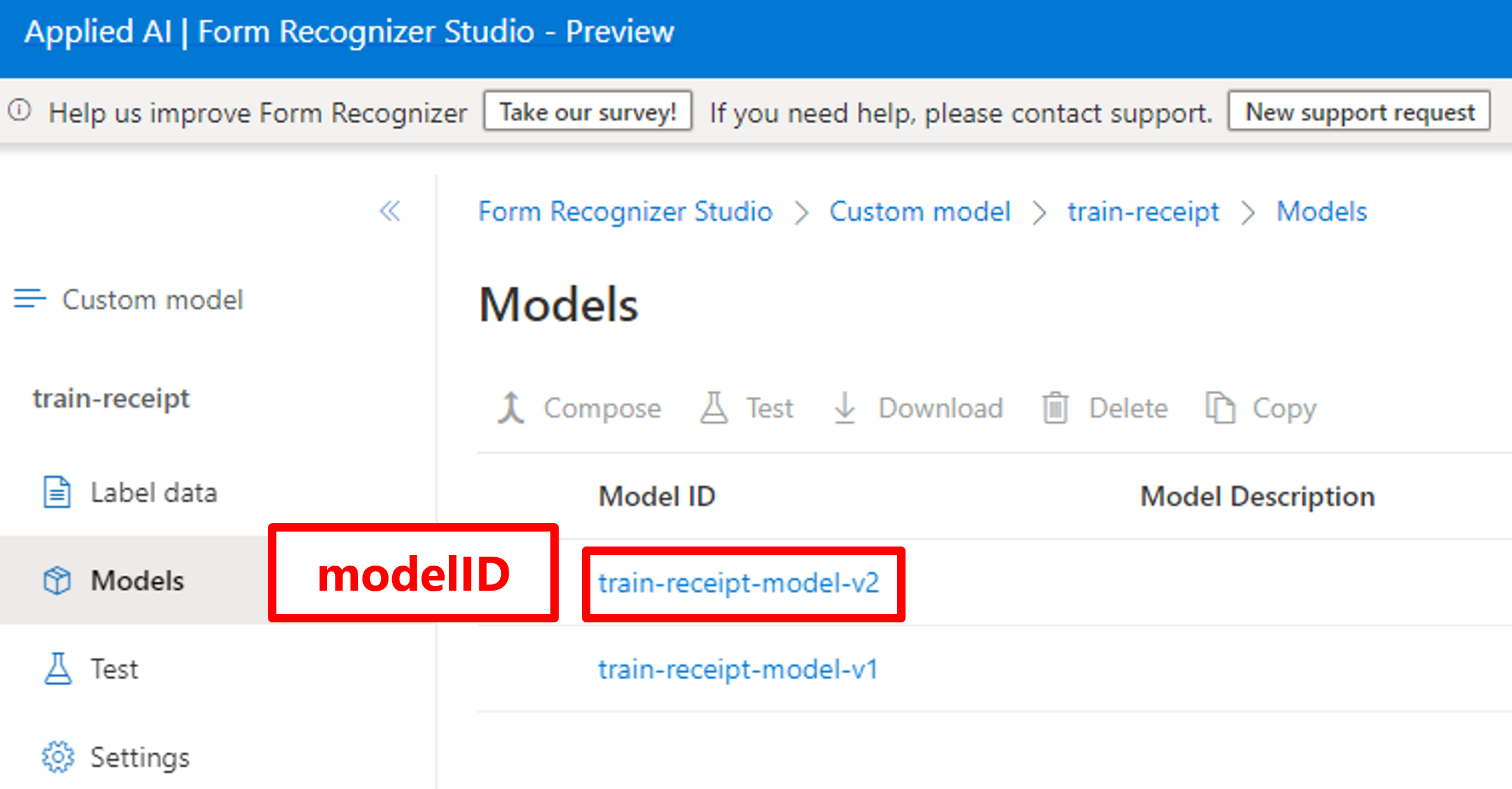
「modelID」はForm Recognizer Studioから取得。
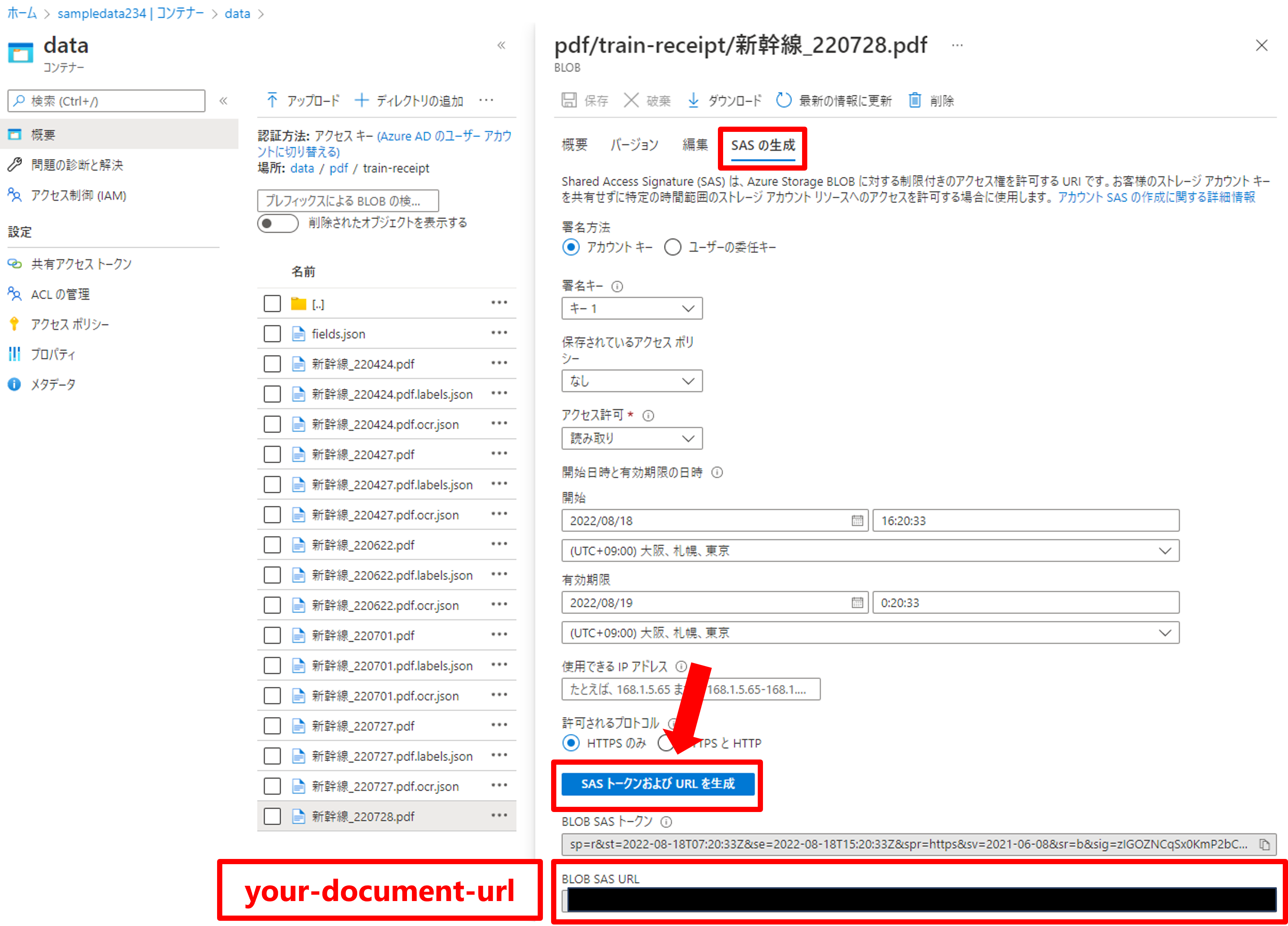
「your-document-url」はAzure Portalのデータへアクセスし、SAS生成から取得。
APIを実行するとレスポンスヘッダーの中に「operation-location」が含まれています。
operation-location: https://formrecognizer-test-1234.cognitiveservices.azure.com/formrecognizer/documentModels/train-receipt-model-v2/analyzeResults/6b7f5999-eaf2-4516-8909-bcf3a1e255a8?api-version=2022-06-30-preview
この値は次の分析結果取得の{POST response}として使われます。{POST response}を置き換えて分析結果を取得してみましょう。
$ curl -v -X GET "{POST response}" -H "Ocp-Apim-Subscription-Key: {key}"
取得した結果は下記の通りとなりました。カスタムモデルの分析結果は「analyzeResult.documents.fields」に格納されています。APIとして利用できることが確認できましたね。
{
"status": "succeeded",
"createdDateTime": "2022-08-18T02:37:30Z",
"lastUpdatedDateTime": "2022-08-18T02:37:37Z",
"analyzeResult": {
"apiVersion": "2022-06-30-preview",
"modelId": "train-receipt-model-v2",
"stringIndexType": "textElements",
"content": "XXXXXXXXXXXXXXXX",
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 8.2639,
"height": 11.6806,
"unit": "inch",
~~~~~~~~~~~~~~~~~~略~~~~~~~~~~~~~~~~~~~~~~~~~~~~
"documents": [
{
"docType": "train-receipt-model-v2",
"boundingRegions": [
{
"pageNumber": 1,
"polygon": [
0,
0,
8.2639,
0,
8.2639,
11.6806,
0,
11.6806
]
}
],
"fields": {
"name": {
"type": "string",
"valueString": "山田太郎",
"content": "山田太郎",
"boundingRegions": [
{
"pageNumber": 1,
"polygon": [
1.9468,
2.981,
2.9101,
2.981,
2.9101,
3.2547,
1.9468,
3.2547
]
}
],
"confidence": 0.712,
"spans": [
{
"offset": 158,
"length": 4
}
]
},
"reservation_number": {
"type": "number",
"content": "2009",
"boundingRegions": [
{
"pageNumber": 1,
"polygon": [
1.886,
3.5336,
2.2003,
3.5336,
2.2003,
3.6705,
1.886,
3.6705
]
}
],
まとめ
今回はCognitive SearchとForm Recognizerの連携部分でForm Recognizerについて解説しました。次回はこのForm RecognizerのAPIをラップするための「Azure Functions」を解説する予定です。