はじめに
ChatGPTを使い倒された皆さんが次に思うのは「ChatGPTが社内のナレッジを学習して答えてくれたらどんなに便利だろうか」ではないでしょうか?私もよくお客様の質疑応答のExcelシートに回答を埋めていくというタスクを依頼されますが、過去に同じような回答をした場合も多く、ChatGPT良い感じに回答しておいてくれ~~、と日々思うわけです。今回はLangChainで質疑応答タスクを実装してみようと思います。
質疑応答のデータ
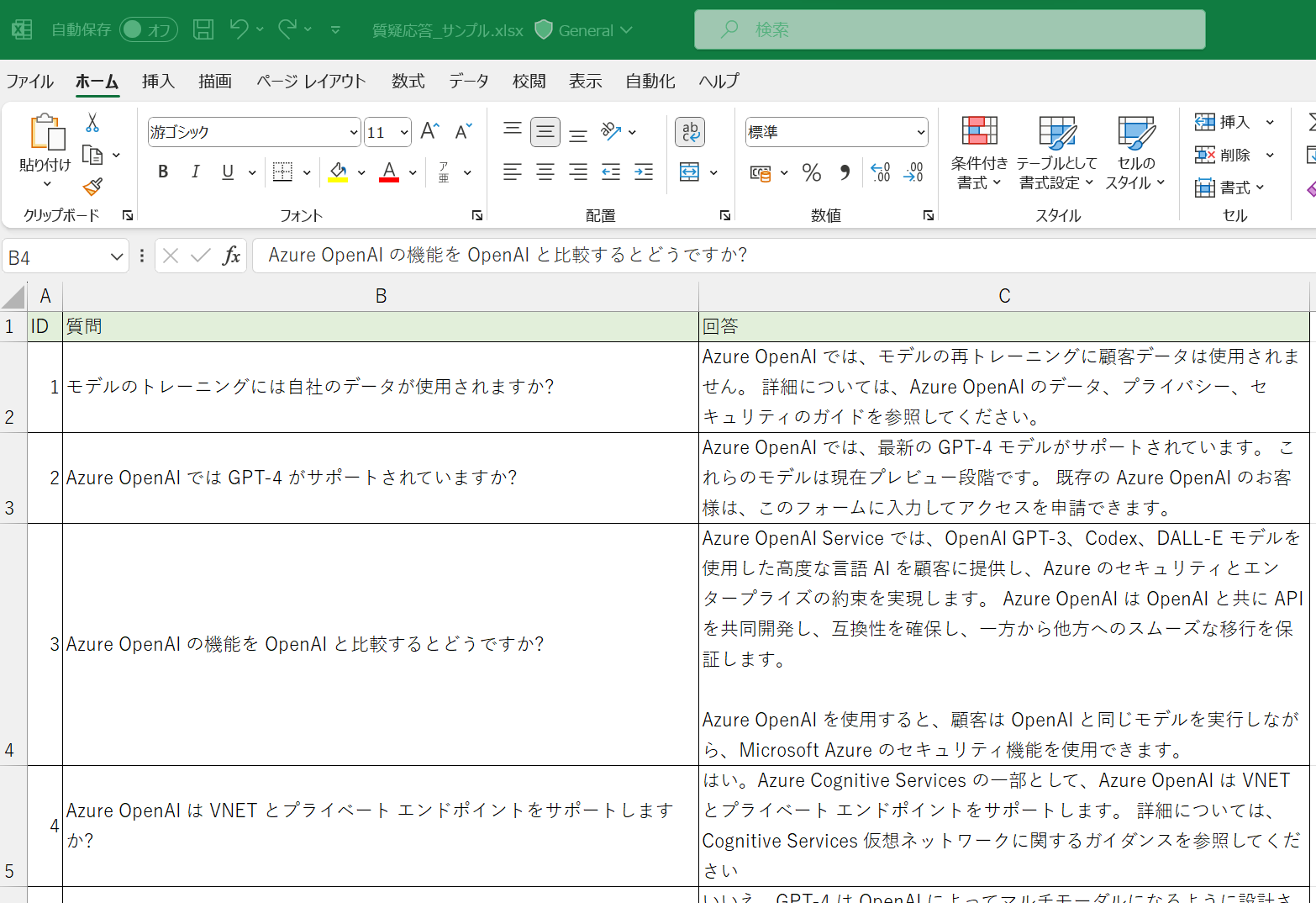
Azure OpenAIの公式ドキュメントのよくある質問をExcelに転機して、質疑応答のデータを作りました。レコード数は21行あります。
公式ドキュメントはこちら。
事前準備
今回はAzure OpenAIのGPTモデルを利用していきますので、OpenAIのリソース作成とLLMs/Embeddingsのモデルをデプロイしておいてください。もちろん、OpenAI社のAPIをお使いいただくことも可能です。LangChainとAzure OpenAIの連携部分はこちらのブログをご参照ください。
質疑応答タスク
用意した質疑応答データをデータソースとし、そのデータソースの範囲内でどれだけ質疑応答に対応できるのか、検証してみたいと思います。コードは下記の通りになります。コードの解説は後ほどします。
import os
import pandas as pd
from langchain.document_loaders import DataFrameLoader
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_KEY"] = "XXXXXXXXXXXXXXXXXXXXXX"
os.environ["OPENAI_API_BASE"] = "https://openai-handson.openai.azure.com"
df = pd.read_excel ("./data/質疑応答_サンプル.xlsx")
loader = DataFrameLoader(df, page_content_column="回答")
llm = OpenAI(model_name='text-davinci-003', model_kwargs={"deployment_id":"test-davinci"})
embeddings = OpenAIEmbeddings(
model='text-embedding-ada-002',
deployment="test-embedding-ada",
chunk_size=1
)
index = VectorstoreIndexCreator(embedding=embeddings).from_loaders([loader])
retriever = index.vectorstore.as_retriever()
query ="OpenAIを閉域網で構成するには?"
ans = index.query(llm=llm, question=query)
docs = retriever.get_relevant_documents(query=query)
print("回答:"+ ans)
for doc in docs:
print(doc)
出力結果は下記の通りです。「OpenAIを閉域網で構成するには?」という質問に対して、「Azure Cognitive Servicesの一部として、Azure OpenAIはVNETとプライベートエンドポイントをサポートします。詳細については、Cognitive Services仮想ネットワークに関するガイダンスを参照してください。」という回答になりました。
回答: Azure Cognitive Servicesの一部として、Azure OpenAIはVNETとプライベートエンドポイントをサポートします。詳細については、Cognitive Services仮想ネットワークに関するガイダンスを参照してください。
page_content='Azure OpenAI トレーニング コースの概要を確認してください。' metadata={'ID': 12, '質問': 'Azure OpenAI に関する基本的な学習とスキルの習得のためのトレーニングはどこで受けられますか?'}
page_content='Azure OpenAI の使用可能なモデルに関するガイドを参照してください。' metadata={'ID': 15, '質問': '使用可能なモデルは何ですか?'}
page_content='どのリージョンで使用できるかについては、Azure OpenAI の使用可能なモデルに関するガイドを参照してください。' metadata={'ID': 16, '質問': '\nモデルがどのリージョンで使用できるかはどこで確認できますか?'}
page_content='はい。Azure Cognitive Services の一部として、Azure OpenAI は VNET とプライベート エンドポイントをサポートします。 詳細については、Cognitive Services 仮想ネットワークに関するガイダンスを参照してください' metadata={'ID': 4, '質問': 'Azure OpenAI は VNET とプライベート エンドポイントをサポートしますか?'}
回答の下に表示されている4行は、この質問に関連するドキュメントです。得られた回答は、一番下のID=4の質疑応答に該当するものであり、期待通りの出力結果が得られました。与えた質問に「VNET」や「プライベート」という単語を使わなくても「閉域化」の意味を推測し、ベクトル検索できていることが確認できます。
次に意味不明な質問をしてみます。
query ="誕生日は?"
ans = index.query(llm=llm, question=query)
print("回答:"+ ans)
分からない時は分からない、と答えてくれます。
回答: I don't know.
コードの解説
ここからはコードの解説をしていきます。
Excelを直接ベクトルDBにインデックス化できないので、一度pandasのDataFrameで読み込み、LangChainのDataFrameLoaderでデータをロードします。DataFrameLoaderでは、コンテントのカラムをpage_content_columnとして指定してあげる必要があります(今回、質問のカラムはインデックス化されない)。
import pandas as pd
from langchain.document_loaders import DataFrameLoader
df = pd.read_excel ("./data/質疑応答_サンプル.xlsx")
loader = DataFrameLoader(df, page_content_column="回答")
回答生成などのためにLLMsのモデル、ベクトルDBにインデックス化するためにEmbeddingモデルを使います。
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
llm = OpenAI(model_name='text-davinci-003', model_kwargs={"deployment_id":"test-davinci"},temperature=0)
embeddings = OpenAIEmbeddings(
model='text-embedding-ada-002',
deployment="test-embedding-ada",
chunk_size=1
)
VectorstoreIndexCreatorで回答カラムをインデックス化します。また、関連ドキュメント検索用に、作ったインデックスをretrieverとして定義しておきます。Retrieverはちょっと分かりにくい概念ですが、インデックスなどからドキュメントを取得するためのインターフェースです。
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator(embedding=embeddings).from_loaders([loader])
retriever = index.vectorstore.as_retriever()
インデックスに対して質問を投げます。get_relevant_documentsで、質問に関連するドキュメントを取得できます。
query ="OpenAIを閉域網で構成するには?"
ans = index.query(llm=llm, question=query)
docs = retriever.get_relevant_documents(query=query)
回答の精度
回答の精度を定量的に図るのは難しいですが、ベクトルDBにインデックス化されているのは「回答」だけです(質問に関してはインデックス化されていません)。従って、質疑応答に記載される質問をクエリとしてそのまま投げて、質疑応答に記載されている回答と近い回答が返ってくるか、その精度を測ることはできます。こちらのコードで、質疑応答に記載されている質問(=投げるクエリ)と回答、AIに生成された回答を並べてみました。
for i, row in df.iterrows():
print("ID:"+ str(row['ID']))
print("質問:"+ row['質問'])
print("回答:"+ str(row['回答']))
query = row['質問']
ans = index.query(llm=llm, question=query)
print("AI:"+ str(ans))
結果は以下の通りです。
ID:1
質問:モデルのトレーニングには自社のデータが使用されますか?
回答:Azure OpenAI では、モデルの再トレーニングに顧客データは使用されません。 詳細については、Azure OpenAI のデータ、プライバシー、セキュリティのガイドを参照してください。
AI: いいえ、モデルの再トレーニングには顧客データは使用されません。
ID:2
質問:Azure OpenAI では GPT-4 がサポートされていますか?
回答:Azure OpenAI では、最新の GPT-4 モデルがサポートされています。 これらのモデルは現在プレビュー段階です。 既存の Azure OpenAI のお客様は、このフォームに入力してアクセスを申請できます。
AI: いいえ、GPT-4 はテキストの入出力のみでサポートされています。
ID:3
質問:Azure OpenAI の機能を OpenAI と比較するとどうですか?
回答:Azure OpenAI Service では、OpenAI GPT-3、Codex、DALL-E モデルを使用した高度な言語 AI を顧客に提供し、Azure のセキュリティとエンタープライズの約束を実現します。 Azure OpenAI は OpenAI と共に API を共同開発し、互換性を確保し、一方から他方へのスムーズな移行を保証します。
Azure OpenAI を使用すると、顧客は OpenAI と同じモデルを実行しながら、Microsoft Azure のセキュリティ機能を使用できます。
AI: Azure OpenAI では、OpenAI と同じモデルを実行しながら、Microsoft Azure のセキュリティ機能を使用できます。
ID:4
質問:Azure OpenAI は VNET とプライベート エンドポイントをサポートしますか?
回答:はい。Azure Cognitive Services の一部として、Azure OpenAI は VNET とプライベート エンドポイントをサポートします。 詳細については、Cognitive Services 仮想ネットワークに関するガイダンスを参照してください
AI: はい、Azure OpenAI は VNET とプライベート エンドポイントをサポートします。詳細については、Cognitive Services 仮想ネットワークに関するガイダンスを参照してください。
ID:5
質問:GPT-4 プレビュー モデルでは現在、画像入力がサポートされていますか?
回答:いいえ、GPT-4 は OpenAI によってマルチモーダルになるように設計されていますが、現在サポートされているのはテキストの入出力のみです。
AI: いいえ、GPT-4 は現在テキストの入出力のみでサポートされています。
ID:6
質問:新しいユースケースを申請するにはどうすればよいですか?
回答:以前は、新しいユース ケースを追加するプロセスで、お客様がサービスに再適用する必要がありました。 現在、サービスの使用に新しいユース ケースを迅速に追加できる、新しいプロセスをリリースしています。 このプロセスは、Azure Cognitive Services 内で確立されている制限付きアクセス プロセスに従っています。 既存のお客様は、こちらからすべての新しいユース ケースを証明できます。 これは、最初に申請しなかった新しいユース ケースでサービスを使用するときに必ず必要になるので注意してください。
AI: Azure OpenAI を使うすべてのソリューションは、運用環境用にリリースする前に、初期アクセスの申請に加えてユース ケース レビューを受ける必要があります。 初期アクセスまたは運用レビューについては、こちら (今すぐ申請) から申請してください。
ID:7
質問:埋め込みを使用しようとしていますが、「InvalidRequestError: 入力が多すぎます。 入力の最大数は 1 です。」というエラーが表示されました。 これをどのように修正すればよいですか?
回答:このエラーは通常、テキストのバッチを送信して単一の API 要求に配列として埋め込もうとしたときに発生します。 現在、Azure OpenAI では、埋め込み要求によるバッチ処理はサポートされていません。 埋め込み API 呼び出しは、要求ごとに 1 つの文字列入力で構成する必要があります。 text-embedding-ada-002 (バージョン 2) モデルを使用する場合、文字列の長さは最大 8191 トークンです。
AI: text-embedding-ada-002 (バージョン 2) モデルを使用する場合、文字列の長さは最大 8191 トークンです。 要求ごとに 1 つの文字列入力で構成する必要があります。
ID:8
質問:Azure OpenAI を使用してサービスから必要な応答を取得するより良い方法については、どこで確認できますか?
回答:「プロンプト エンジニアリングの概要」を参照してください。これらのモデルは非常に強力ですが、その動作はユーザーから受け取るプロンプトにも非常に敏感です。 このため、プロンプトの構築が開発のための重要なスキルになります。 概要を理解したら、より高度なプロンプト エンジニアリング手法に関する記事をご確認ください。
AI: Azure Cognitive Services のサポート オプションとヘルプ オプションのガイドを参照してください。
ID:9
質問:Azure OpenAI にアクセスするにはどうすればよいですか?
回答:高い需要、今後の製品の機能強化、Microsoft の責任ある AI へのコミットメントを考慮し、現在、アクセスは制限されています。 現在のところ、Microsoft と既存のパートナーシップ関係があるお客様、リスクの低いユース ケース、軽減策の取り入れに取り組んでいるお客様を対象としています。 Azure OpenAI を使うすべてのソリューションは、運用環境用にリリースする前に、初期アクセスの申請に加えてユース ケース レビューを受ける必要があります。 初期アクセスまたは運用レビューについては、こちら (今すぐ申請) から申請してください
AI: Azure OpenAI にアクセスするには、初期アクセスの申請とユース ケース レビューを受ける必要があります。申請は、Azure OpenAI のウェブサイトから行うことができます。
ID:10
質問:アクセスを申請した後で、承認されるまでにどれくらい待つ必要がありますか?
回答:現在、アクセス承認のタイムラインは提供されていません。
AI: 申請から承認までのタイムラインは提供されていません。Microsoft Q&A に質問を投稿するか、Stack Overflow に質問を投稿することをお勧めします。
ID:11
質問:Azure OpenAI の最新情報はどこで確認できますか?
回答:毎月の最新情報については、新着情報に関するページを参照してください。
AI: Azure OpenAI の使用可能なモデルに関するガイドを参照してください。
ID:12
質問:Azure OpenAI に関する基本的な学習とスキルの習得のためのトレーニングはどこで受けられますか?
回答:Azure OpenAI トレーニング コースの概要を確認してください。
AI: Azure OpenAI トレーニング コースの概要を確認してください。
ID:13
質問:質問を投稿し、他の一般的な質問に対する回答を確認することができるのはどこですか?
回答:Microsoft Q&A に質問を投稿することをお勧めします
または、Stack Overflow に質問を投稿できます
AI: Microsoft Q&A または Stack Overflow に質問を投稿することをお勧めします。
ID:14
質問:Azure OpenAI カスタマー サポートはどこで受けられますか?
回答:Azure OpenAI は Azure Cognitive Services の一部です。 Azure Cognitive Services のすべてのサポート オプションについては、サポート オプションとヘルプ オプションのガイドを参照してください。
AI: Azure Cognitive Services のサポート オプションとヘルプ オプションのガイドを参照してください。
ID:15
質問:使用可能なモデルは何ですか?
回答:Azure OpenAI の使用可能なモデルに関するガイドを参照してください。
AI: Azure OpenAI の使用可能なモデルに関するガイドを参照してください。
ID:16
質問:モデルがどのリージョンで使用できるかはどこで確認できますか?
回答:どのリージョンで使用できるかについては、Azure OpenAI の使用可能なモデルに関するガイドを参照してください。
AI: Azure OpenAI の使用可能なモデルに関するガイドを参照してください。
ID:17
質問:基本モデルと微調整されたモデルの違いは何ですか?
回答:基本モデルは、特定のユース ケースに合わせてカスタマイズまたは微調整されていないモデルです。 微調整されたモデルは、基本モデルのカスタマイズされたバージョンであり、モデルの重みがプロンプトの一意のセットに基づいてトレーニングされます。 微調整されたモデルを使用すると、完了プロンプトの一部としてコンテキスト内学習のために詳細な例を提供しなくても、より多くのタスクでより良い結果を得ることができます。 詳細については、微調整のガイドを参照してください。
AI: 基本モデルは特定のユース ケースに合わせてカスタマイズまたは微調整されていないモデルです。微調整されたモデルは、基本モデルのカスタマイズされたバージョンであり、モデルの重みがプロンプトの一意のセットに基づいてトレーニングされます。
ID:18
質問:作成できる微調整されたモデルの最大数はいくつですか?
回答:100
AI: 不明です。
ID:19
質問:Azure OpenAI での API 応答の SLA はどのようになっていますか?
回答:現時点では、API 応答時間サービス レベル アグリーメント (SLA) は定義されていません。 Azure OpenAI Service の全体的な SLA は、他の Azure Cognitive Services の場合と同じです。 詳細については、「Online Services のサービス レベル アグリーメント (SLA)」ページの Cognitive Services セクションを参照してください。
AI: Azure OpenAI Service の全体的な SLA は、他の Azure Cognitive Services の場合と同じです。詳細については、「Online Services のサービス レベル アグリーメント (SLA)」ページの Cognitive Services セクションを参照してください。
ID:20
質問:微調整されたモデル デプロイが削除されたのはなぜですか?
回答:カスタマイズされた (微調整された) モデルが 15 日間を超えてデプロイされ、候補呼び出しやチャット候補呼び出しが行われなかった場合、デプロイは自動的に削除されます (そのデプロイに対するホスティング料金は発生しません)。 基になるカスタマイズされたモデルは引き続き使用でき、いつでも再デプロイできます。 詳しくは、操作方法に関する記事をご覧ください。
AI: 15日間を超えてデプロイされ、候補呼び出しやチャット候補呼び出しが行われなかったためです。
ID:21
質問:REST API を使用してモデルをデプロイするにはどうすればよいですか?
回答:現在、モデル デプロイが可能な 2 つの異なる REST API があります。 モデルのデプロイ時に text-embedding-ada-002 Version 2 のようにモデル バージョンを指定する機能などの最新のモデル デプロイ機能については、Cognitive Services の Create または Update REST API 呼び出しを使用してください。
AI: Cognitive Services の Create または Update REST API 呼び出しを使用してください。
質疑応答の回答とAIが生成された回答を私が目視で確認したところ、ID=6,11,18に関して、回答とAIが生成した回答がズレていました。精度は18/21(=約86%)といったところでしょうか。
ここで重要なのは、精度上げるためには回答の質を上げなければならない、ということです。例えば、ID=18の質疑応答に記載されている回答は「100」のみになっていて、ベクトルDBにはそれがそのままインデックス化されています。検索する側からすると、何が100なのか分からないですよね。この場合「微調整されたモデルの最大数は100です」と回答を修正すれば良いと思います。
まとめ
今回はLangChainを使って自分が用意したデータに対して質疑応答タスクを実装する方法について解説しました。回答の質と量を上げて、回答の精度を上げてあげれば、実用的になりそうですね!