本記事は、前回の記事の続きとなります。もし良ければ、前回の記事もご覧ください。
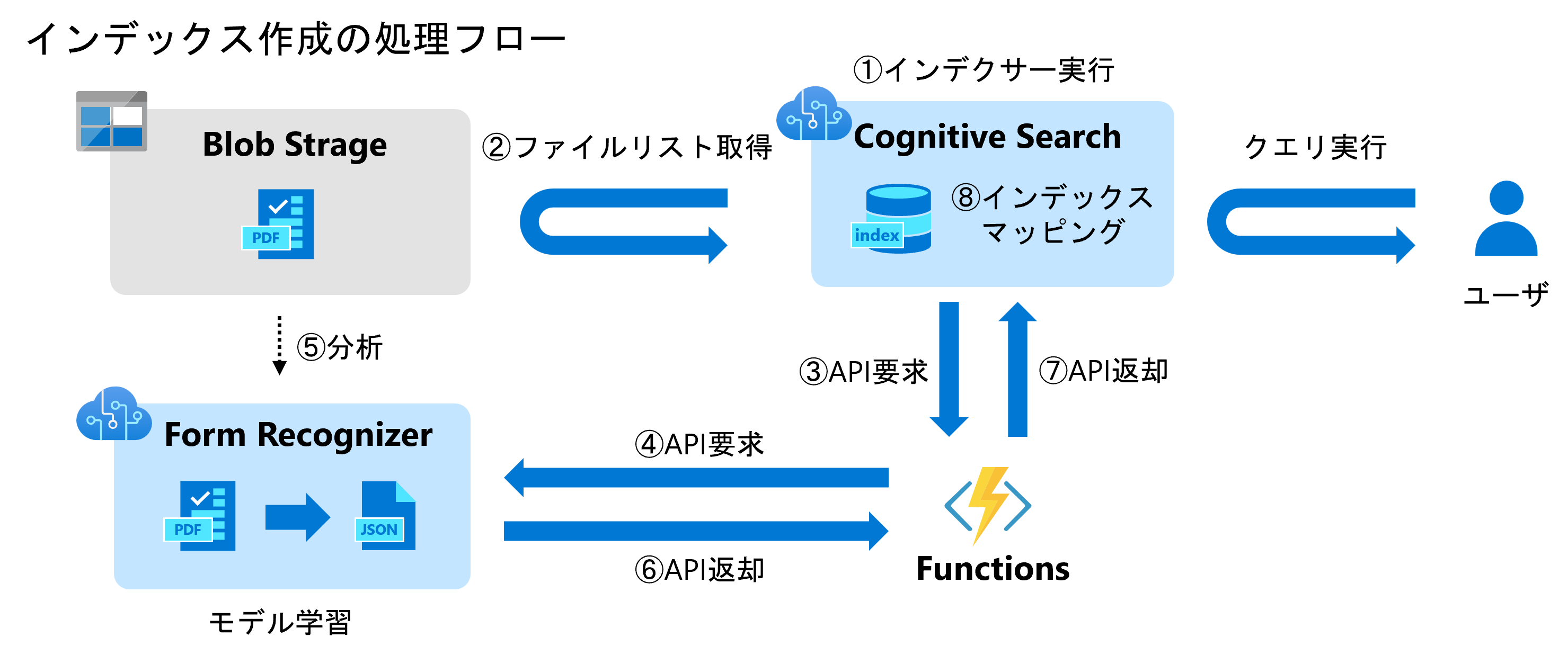
「Azere Cognitive SearchとAzure Form Recognizerの連携を試してみた」の3回目ということでCognitive Searchについて解説していきます(⑧インデックスマッピング)
リソースの作成
まずは、Cognitive Searchのリソースを作成します。Azure Portalの検索からCognitive Searchで検索し、[作成]をクリックしましょう。
[リソースグループ]を選択、[サービス名]を入力、[場所]を選択します。
価格レベルに関しては下記をご参照ください。価格レベルは、検証用なので「Free」で十分です。
全体像の確認
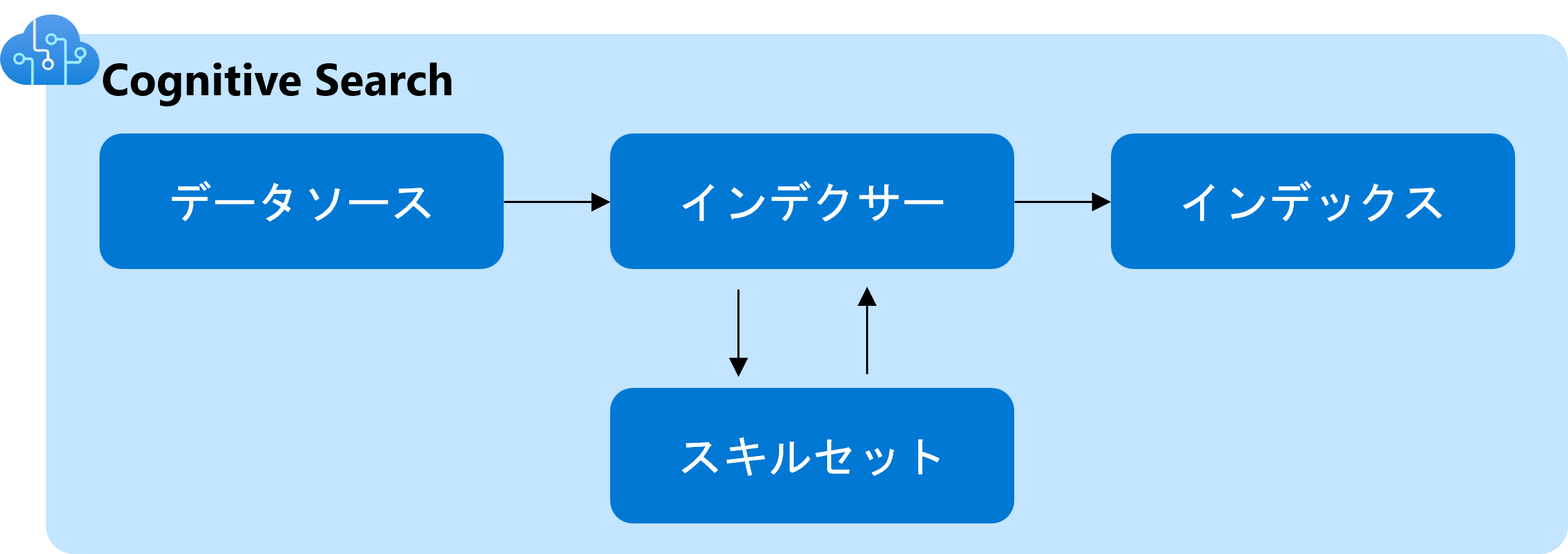
各種設定を行う前にCognitive Searchの重要用語について解説します。Cognitive Searchでは大きく4つの概念(データソース、インデクサー、スキルセット、インデックス)があり、一つずつ設定を行います。
データソースは、Azure Blob StorageやAzure Cosmos DB等の検索したいドキュメントが保存されている場所を指定します。指定できるデータソースは、公式ドキュメントをご参照ください。
インデクサーは、データソースをスキャンし、各スキルセットと連携しながら、インデックスを作成する機能です。スキャンの頻度やスキルセットとインデックスの紐づけはこの機能で行います。インデックスでは、インデックスのスキーマを定義します。インデックスとして使いたい項目の名前やデータ型を定義します。スキルセットは、OCRやキーフレーズ抽出等のドキュメントからメタデータを抽出するための機能を定義します。
データソースの作成
それでは、データソースを作成していきます。[概要]->[データソース]->[データソースの追加]をクリックします。
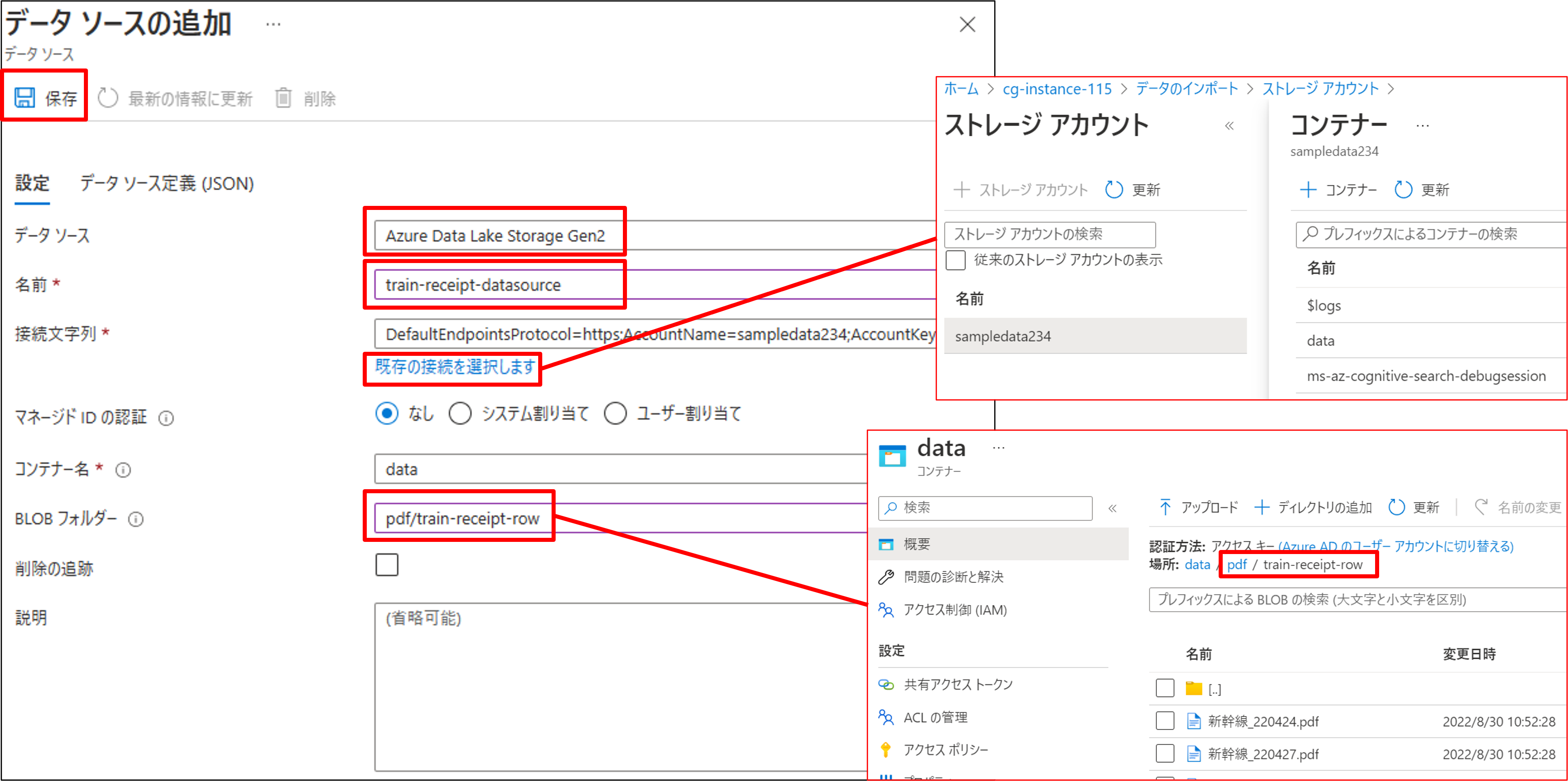
[データソース]は「Azure Data Lake Storage Gen2」を選択し、データソースの名前を入力しましょう。次に、[既存の接続を選択します]をクリックし、スキャンしたいデータが格納されているコンテナを選択すると、接続文字とコンテナ名を自動で入力されます。BLOBフォルダーは、Data Lake Storage Gen2のコンテナ以下のフォルダパスを入力します。今回は、「pdf/train-receipt-row」を入力します。すべて入力したら、左上の保存をクリックします。
インデックスの作成
次に、インデックスを作成します。[概要]->[インデックス]->[インデックスの追加]をクリックしましょう。
最初にインデックス名を入力し、[フィールドの追加]から、今回インデックスに使いたいフィールドを作成していきます。
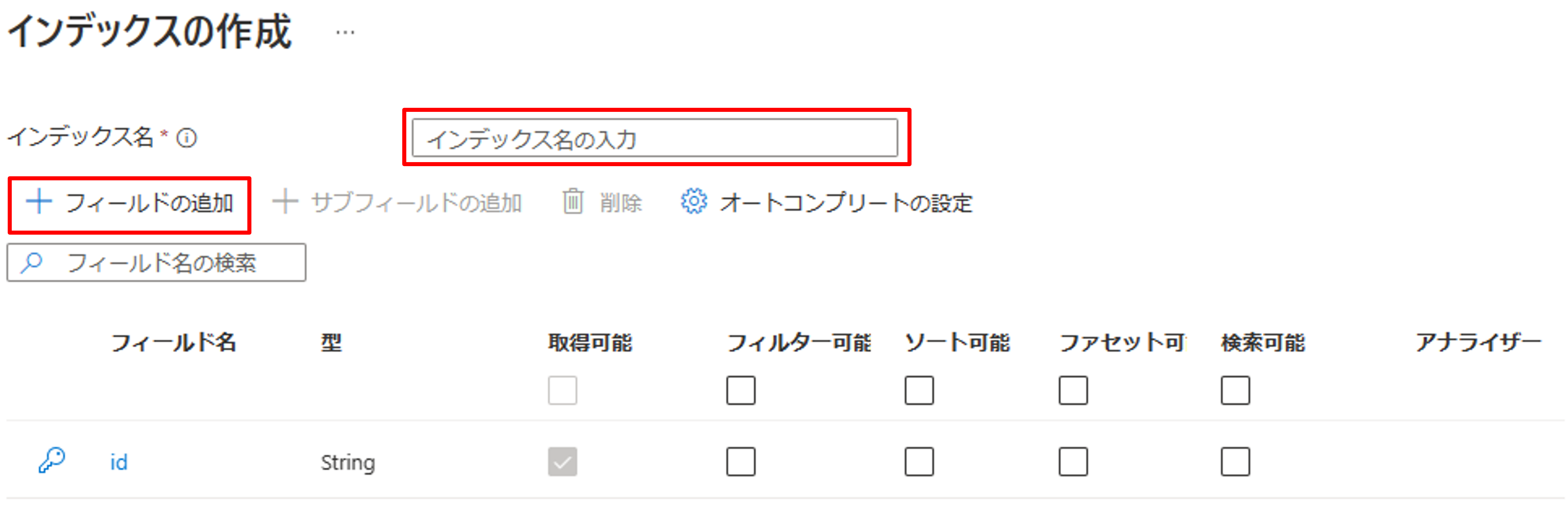
インデックスには、フィールド一つ一つに下記の設定があります。また、インデックスには必ず一意のキーを設定する必要があり、最初にidフィールドが作成されています。
| 用語 | 説明 |
|---|---|
| 取得可能 | 検索結果でこのフィールドを返すかどうかを決定します |
| フィルター可能 | フィルタークエリで参照されます。フィルターを使うとクエリ実行前にレコードを除外でき、検索を高速化できます。 |
| ソート可能 | 評価、日付、場所などドキュメント内のフィールドに基づいて並べ替えを構成できます |
| ファセット可能 | カテゴリごとのヒット カウントを含む検索結果に活用できます |
| 検索可能 | テキスト検索が可能となります |
| アナライザー | テキスト検索可能なフィールド字句を解析するためのアナライザーを設定できます。テキストが日本語の場合は日本語のアナライザーを選択します |
公式サイトも貼っておきます。
今回は簡単のためnameのみを「検索可能」にし、そのほかは「取得可能」という設定を行いました。
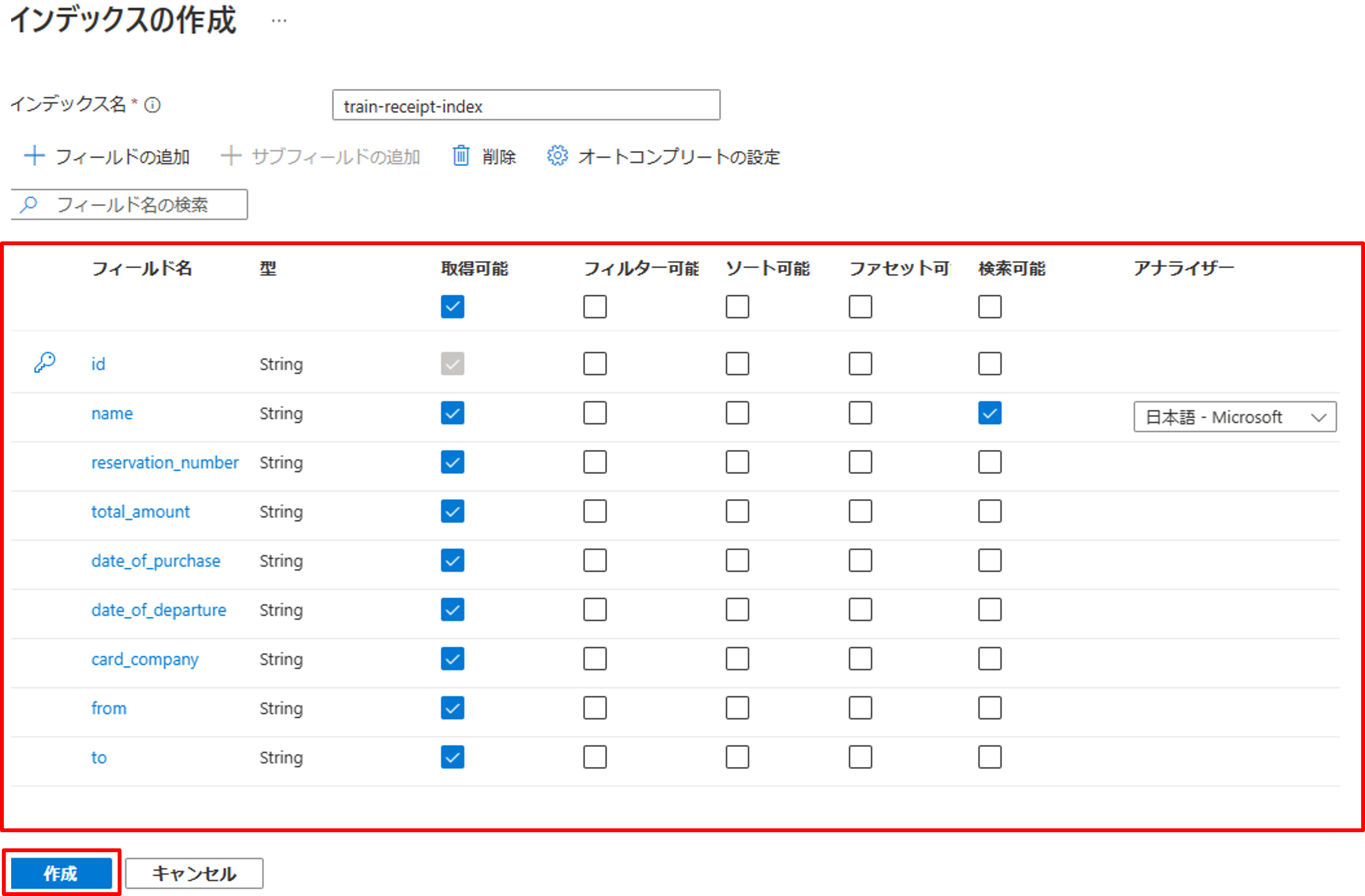
JSONの定義は下記の通りです。
{
"name": "{{index-name}}",
"fields": [
{
"name": "id",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": true
},
{
"name": "name",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
"analyzer": "ja.microsoft"
},
{
"name": "reservation_number",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
},
{
"name": "total_amount",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
},
{
"name": "date_of_purchase",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
},
{
"name": "date_of_departure",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
},
{
"name": "card_company",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
},
{
"name": "from",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
},
{
"name": "to",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": false,
"facetable": false,
"key": false,
}
]
}
スキルセットの概念
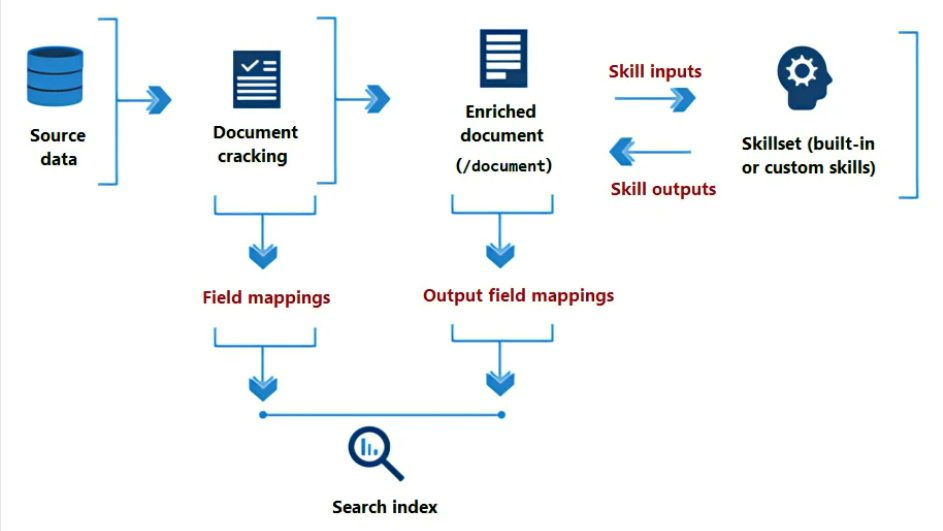
スキルセットを作成する前に、スキルセットの概念を説明します。インデックスのスキャンが走ると、データソースをスキャンし、ドキュメントのメタ情報を取得します(Document cracking)。取得されたメタ情報はそのままインデックスとして使うこともできますし、何らかの処理を加えて別のインデックスとして使うこともできます(Field mappings)。さらに、ドキュメントに対してOCRによる文字認識やドキュメント抽出等のSkillsetを活用することで、Enriched documentを作成できます。Enriched documentでは、/documentをルートディレクトリに、グラフ構造としてデータを保持します。データパスとインデックスの紐づけはOutput field mappingsで行います。
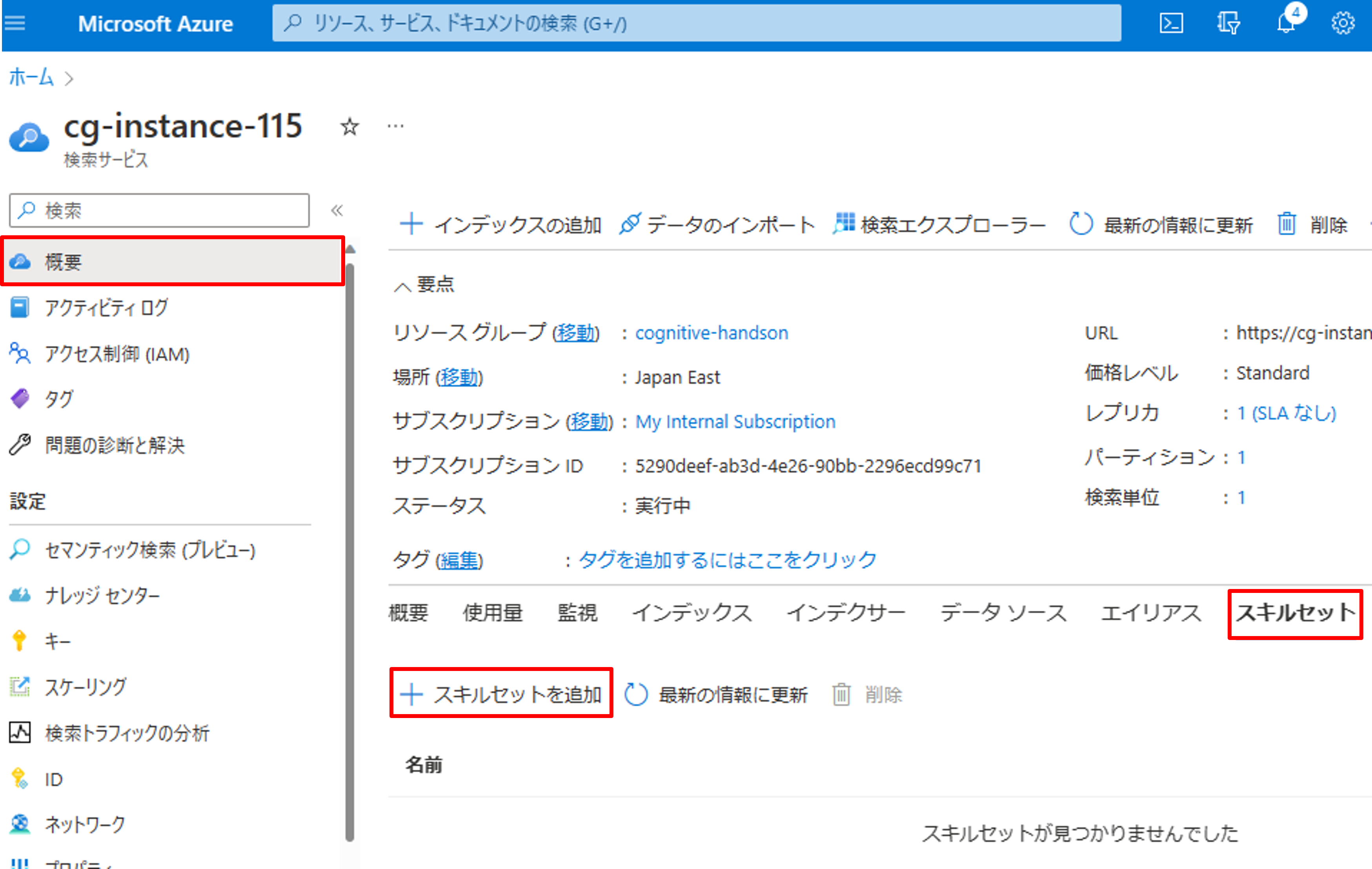
スキルセットの作成
それではスキルセットを作成します。今回は、第2回の時に作成したFunctionsを使いたいので、カスタムWEB APIというスキルを使います。[概要]->[スキルセット]->[スキルセットを追加]をクリックしましょう。
スキルセットでは、右側のスキル定義テンプレートを活用してJSON形式でスキルの設定を書いていきます。
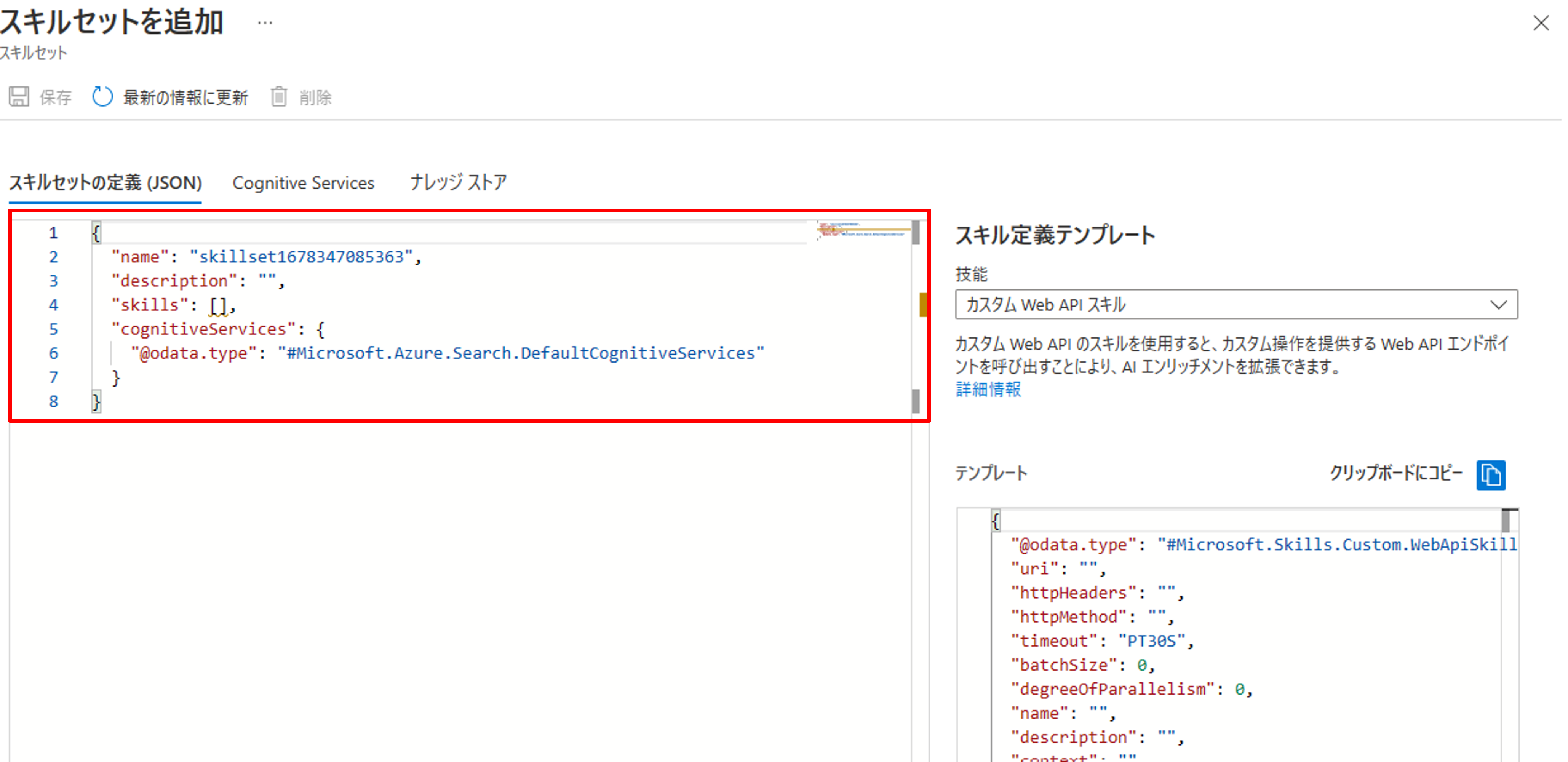
今回は下記の通り設定しました。一つ一つ設定項目を説明していきます。
{
"name": "train-receipt-skills",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "formrecognizer",
"context": "/document",
"uri": "https://form-recog-api-2.azurewebsites.net/api/AnalyzeDocument?code=XXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 2,
"inputs": [
{
"name": "formUrl",
"source": "/document/metadata_storage_path_plain"
},
{
"name": "formSasToken",
"source": "/document/metadata_storage_sas_token"
},
{
"name": "model",
"source": "=\"train-receipt-model-v3\""
}
],
"outputs": [
{
"name": "documents",
"targetName": "analyzed_documents"
}
]
}
],
"cognitiveServices": {
"@odata.type": "#Microsoft.Azure.Search.DefaultCognitiveServices"
}
}
| JSONの項目 | 説明 |
|---|---|
| name | スキルセットの名前 |
| skills -> @odata.type | スキルの種類。今回はCustom.WebApiSkillを選択 |
| skills -> name | 個々のスキルの名前 |
| skills -> context | Cognitive Searchが読み取ったドキュメントのデータパス |
| skills -> uri | FunctionsのURL。前回記事で作成したFunctionsのURLを指定 |
| skills -> timeout | API 呼び出しを行う http クライアントのタイムアウト値。PT30Sは30秒でタイムアウトすることを意味する |
| skills -> batchSize | 1 回の API 呼び出しにつき、どれだけのデータレコードが送信されるか |
| skills -> inputs | FunctionsのAPIを叩く時の入力データ。metadata_storage_path_plainはドキュメントのファイルパス。metadata_storage_sas_tokenはドキュメントのSAS。modelはForm Recognizerのモデル名 |
| skills -> outputs | nameにはFunctionsの出力のdata以下のデータパス。targetNameはCognitive Search内のデータパス |
今回作成したForm Recognizerのカスタムモデルは、一回の呼び出しに約10秒弱かかります。従って、10秒×(batchSize:2)=20秒 < timeout:30秒となるように、batchSizeとtimeoutを設定しています。
プロパティの詳しい説明は公式ドキュメントをご参照ください。
インデクサーの設定
最後にインデクサーの設定を行います。[概要]->[インデクサー]->[インデクサーの追加]をクリックします。
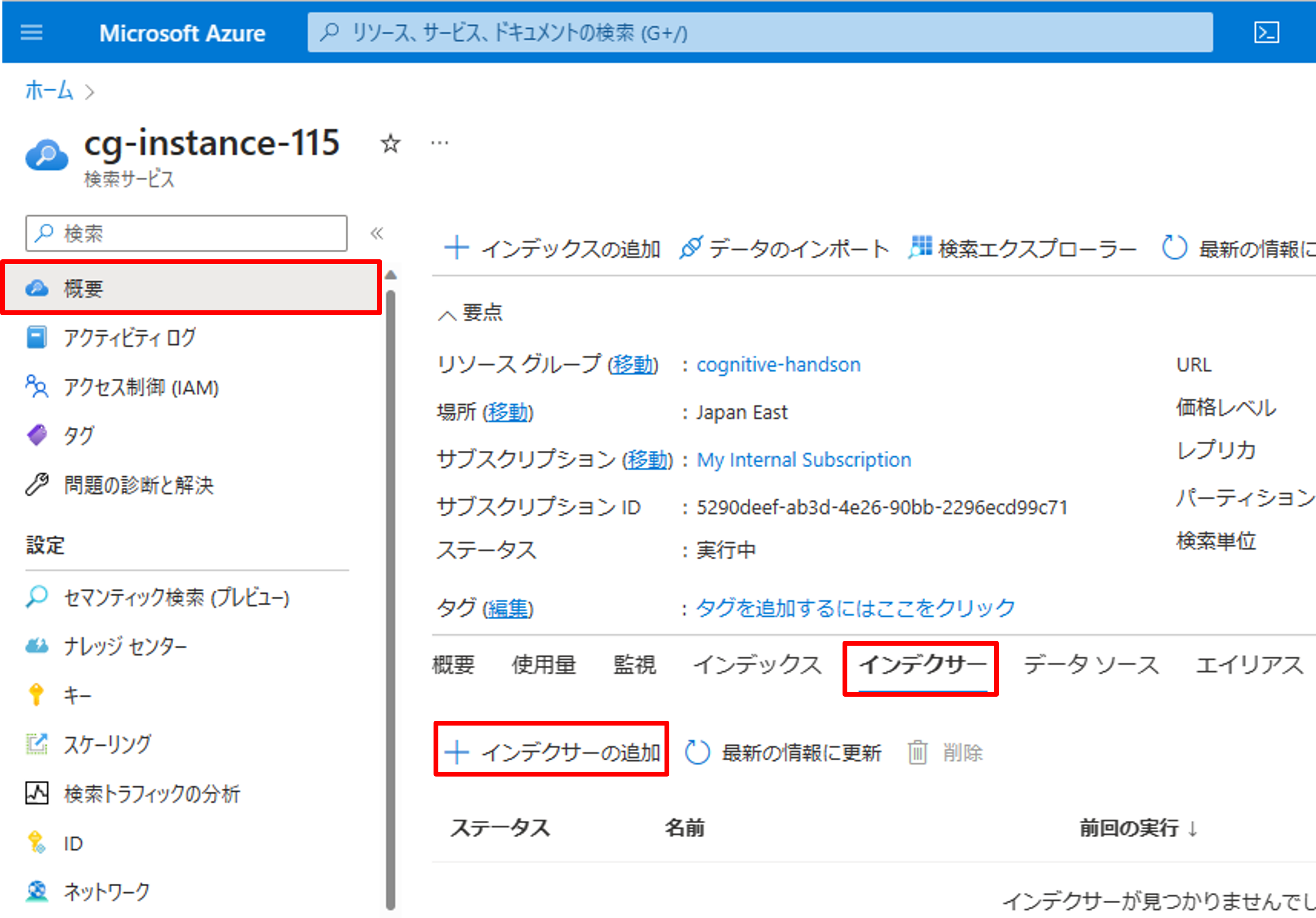
インデクサーの名前を入力し、作成したインデックス、データソース、スキルセットを選択します。
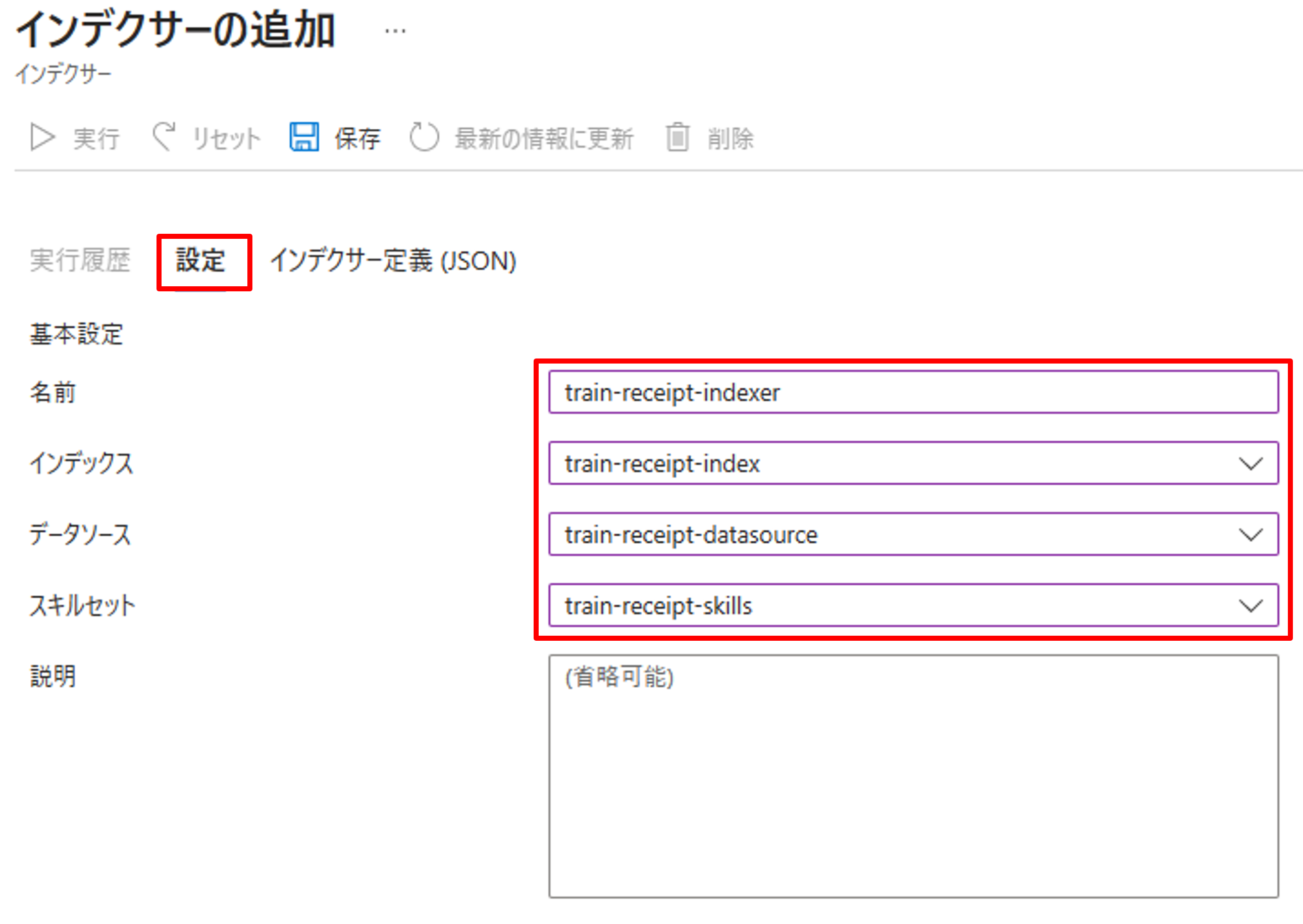
その他の設定はGUIからできない項目も含まれているので、タブから[インデクサー定義(JSON)]をクリックし、JSON形式で設定を書いていきます。
JSONの設定は下記の通りです。
{
"name": "train-receipt-indexer",
"dataSourceName": "train-receipt-datasource",
"skillsetName": "train-receipt-skills",
"targetIndexName": "train-receipt-index",
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "id",
"mappingFunction": {
"name": "base64Encode"
}
},
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "metadata_storage_path_plain"
}
],
"outputFieldMappings": [
{
"sourceFieldName": "/document/analyzed_documents/0/name",
"targetFieldName": "name"
},
{
"sourceFieldName": "/document/analyzed_documents/0/reservation_number",
"targetFieldName": "reservation_number"
},
{
"sourceFieldName": "/document/analyzed_documents/0/total_amount",
"targetFieldName": "total_amount"
},
{
"sourceFieldName": "/document/analyzed_documents/0/date_of_purchase",
"targetFieldName": "date_of_purchase"
},
{
"sourceFieldName": "/document/analyzed_documents/0/date_of_departure",
"targetFieldName": "date_of_departure"
},
{
"sourceFieldName": "/document/analyzed_documents/0/card_company",
"targetFieldName": "card_company"
},
{
"sourceFieldName": "/document/analyzed_documents/0/from",
"targetFieldName": "from"
},
{
"sourceFieldName": "/document/analyzed_documents/0/to",
"targetFieldName": "to"
}
]
}
fieldMappingsではインデックスの処理・追加の設定を行います。metadata_storage_pathにはBlobのストレージパスが格納されているので、それをbase64Encodeした値を一意の値としてidに格納します。ちなみにこのkeyの決め方はCognitive Searchのサンプルで良く使われているみたいです。エンコード前のBlobのストレージパスも必要なので、metadata_storage_path_plainとして退避しておきます。
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "id",
"mappingFunction": {
"name": "base64Encode"
}
},
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "metadata_storage_path_plain"
}
]
outputFieldMappingsではEnriched documentのデータとインデックスの紐づけを行います。
"outputFieldMappings": [
{
"sourceFieldName": "/document/analyzed_documents/0/name",
"targetFieldName": "name"
}
インデクサー定義をすべて書いたら、[保存]をクリックします。
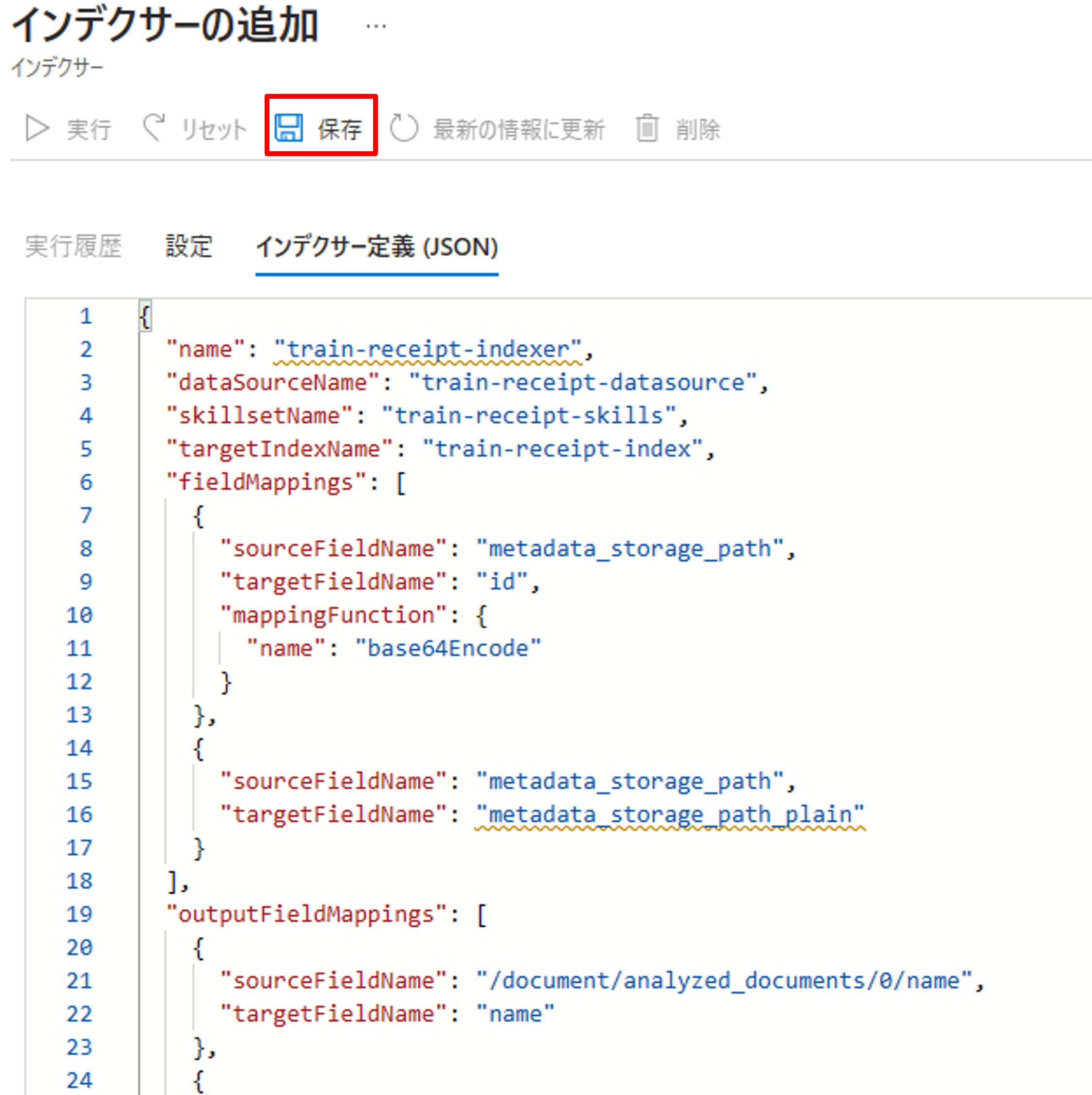
すると、初回は自動的にインデックスの実行が走ります。上手くいくと「成功」のステータスが確認できます。
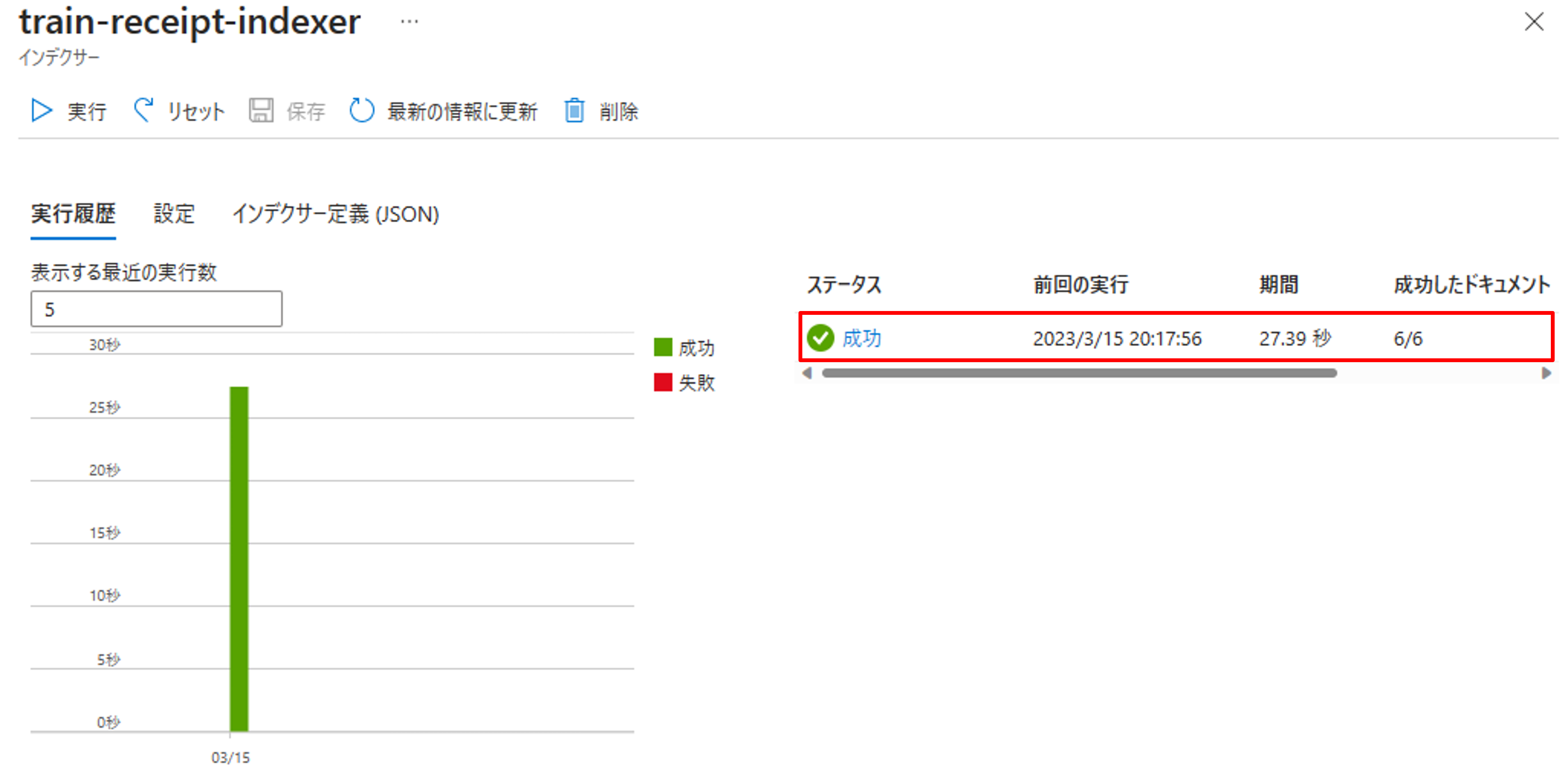
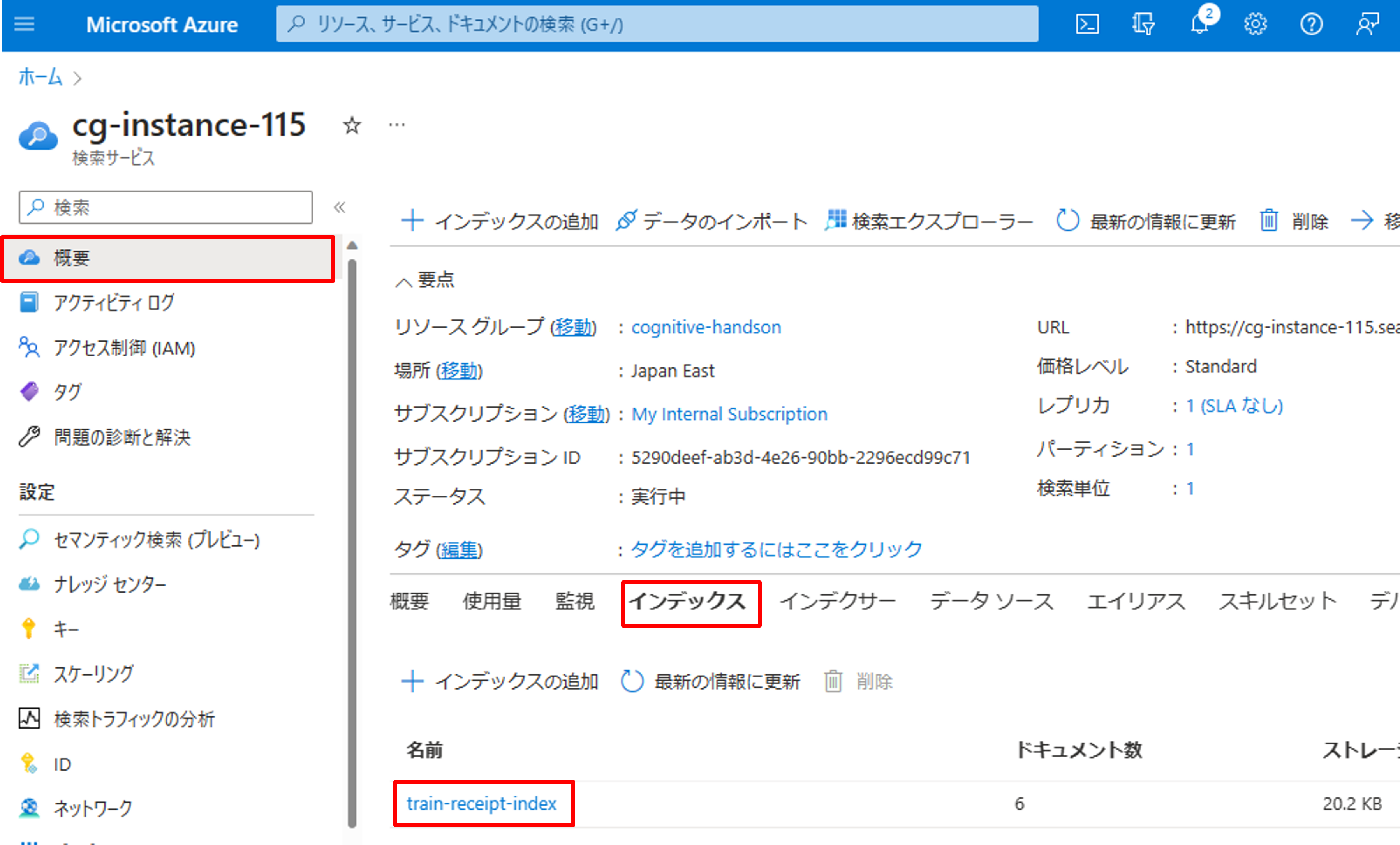
最後にインデックスがきちっと取れているか確認します。[概要]->[インデックス]から先ほど作成したインデックスをクリックします。
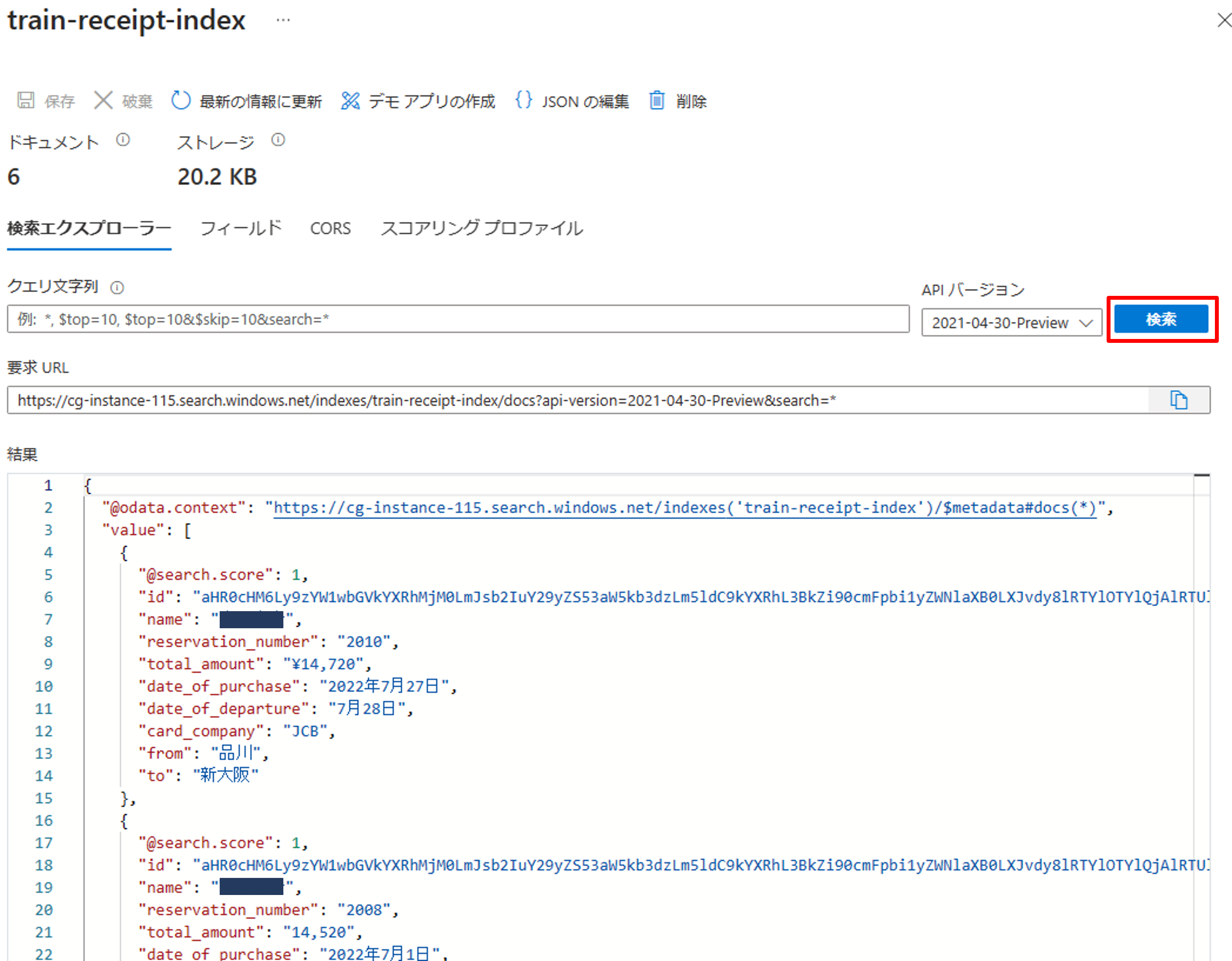
クエリ文字列を空白にして、[検索]を押すと全数検索できます。下記の通り正しくインデックス化できていることが確認できました。
まとめ
3回に分けてCognitive SearchとForm Recognizerの連携を解説しました。サービスの理解とプログラミングが必要なので、システム構築に少し時間がかかりますが、自由度が高く、柔軟にカスタマイズすることができます。是非、ご活用いただければと思います。