はじめに
Azure Data ExplorerはWEBサイトやIoTデバイスなどからの大量のストリーミングデータをニアリアルタイムに分析するためのプラットフォームです。ログ分析のシナリオで良く使われるサービスとなります。今回はテスト用WEBサイトのアクセスログをData Explorerに流し込んで、どれだけ簡単に、かつリアルタイムに分析できるか検証します。
アーキテクチャ
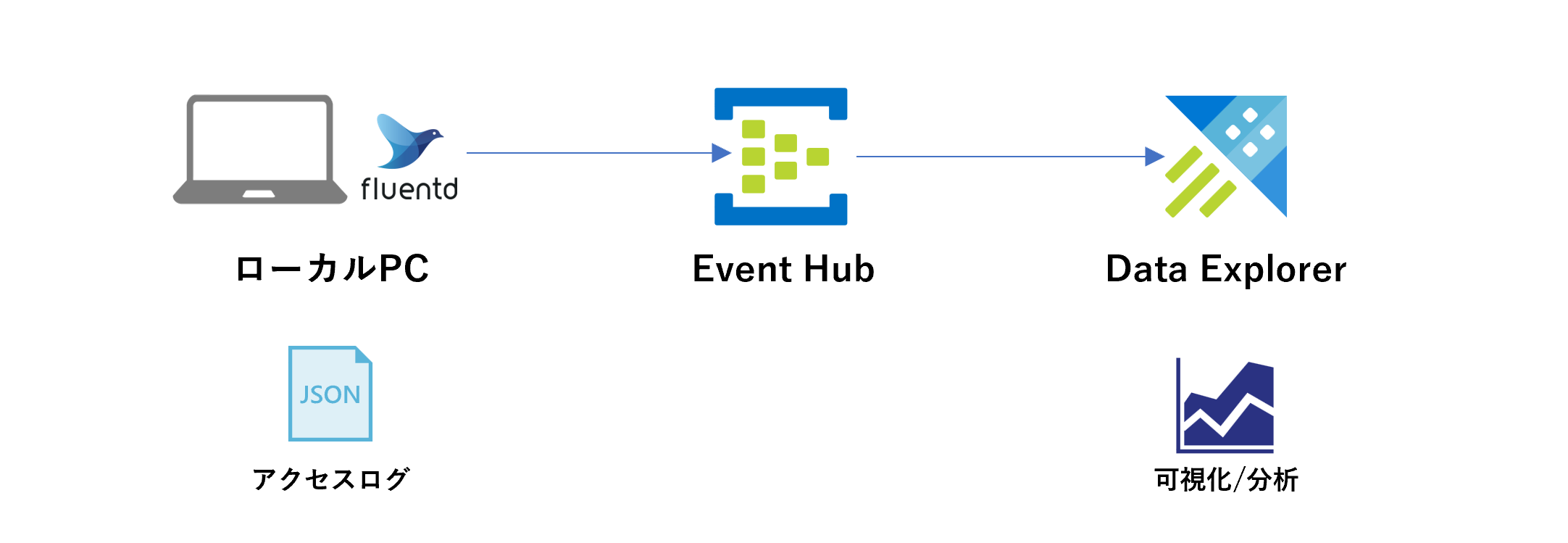
簡単ですが、アーキテクチャは下記の通りです。ローカルPCのnginxからfluentd経由でEvent Hubsにログを送信します。Event HubsからData Explorerにログを蓄積して、ログを分析します。
Event Hubsのリソース作成
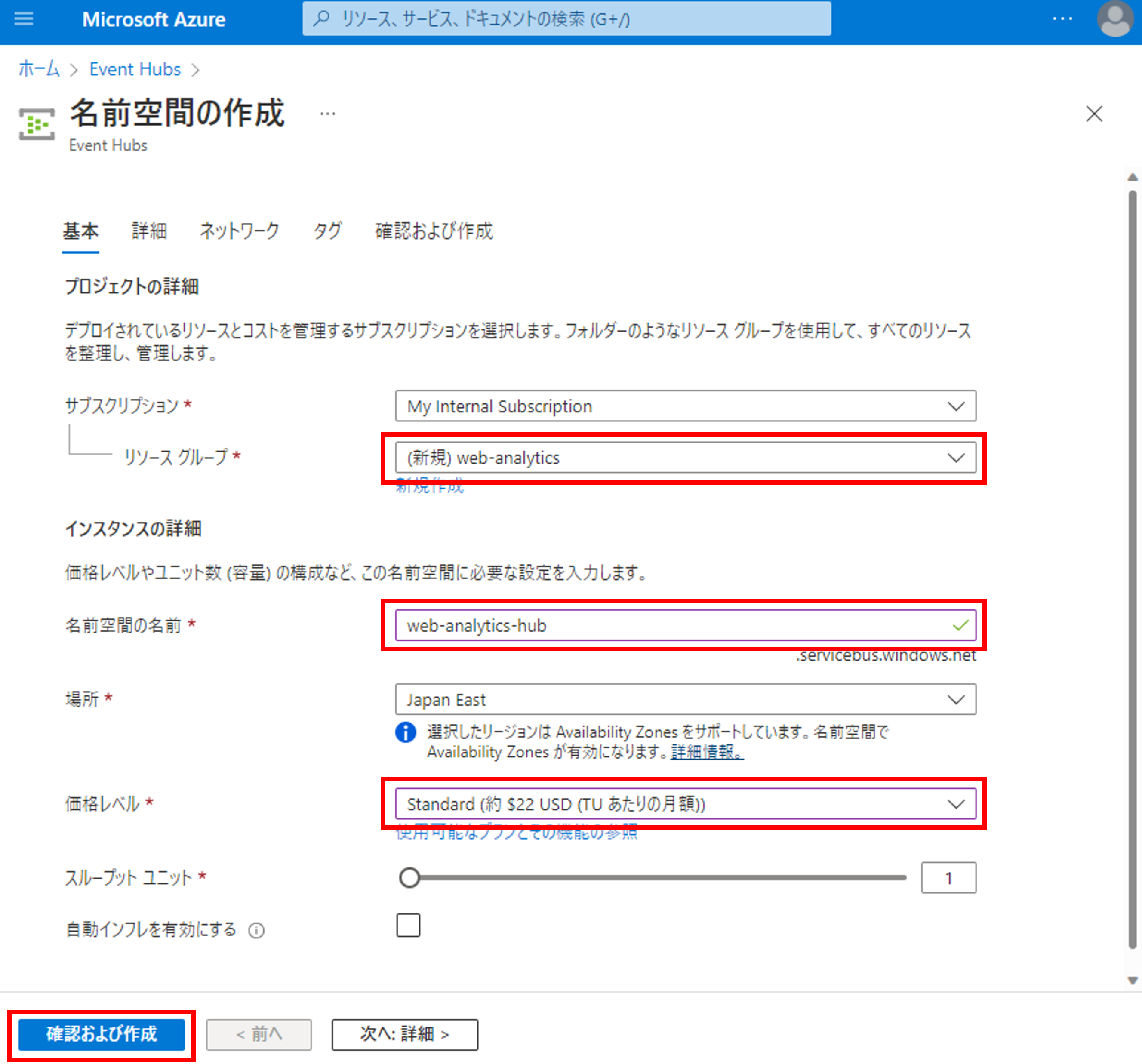
まずはストリーミングデータの受け口であるEvent Hubsのリソースを作成します。
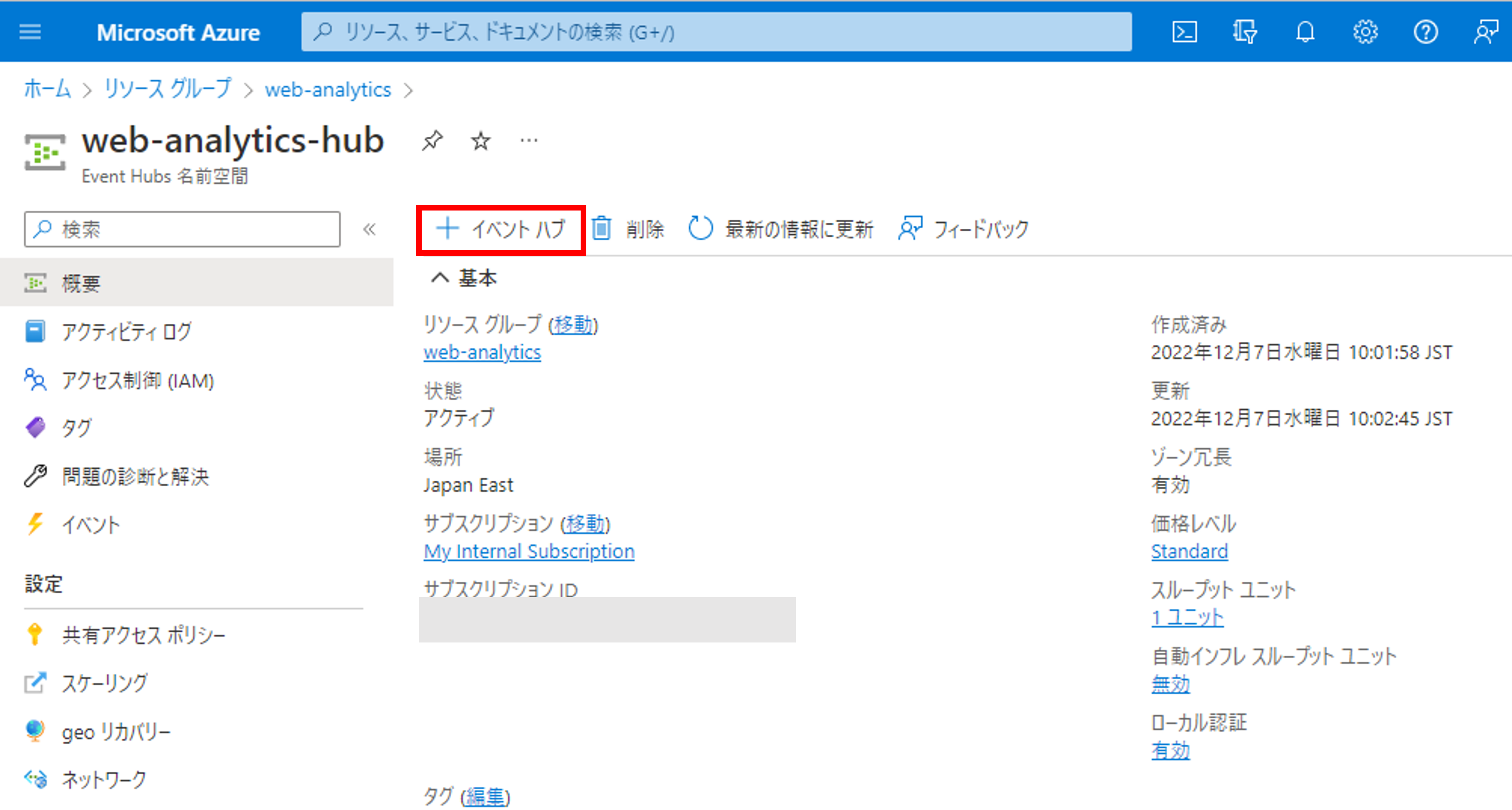
次にリソースの中にハブを作ります。上部の[概要]->[イベントハブ]をクリックしましょう。
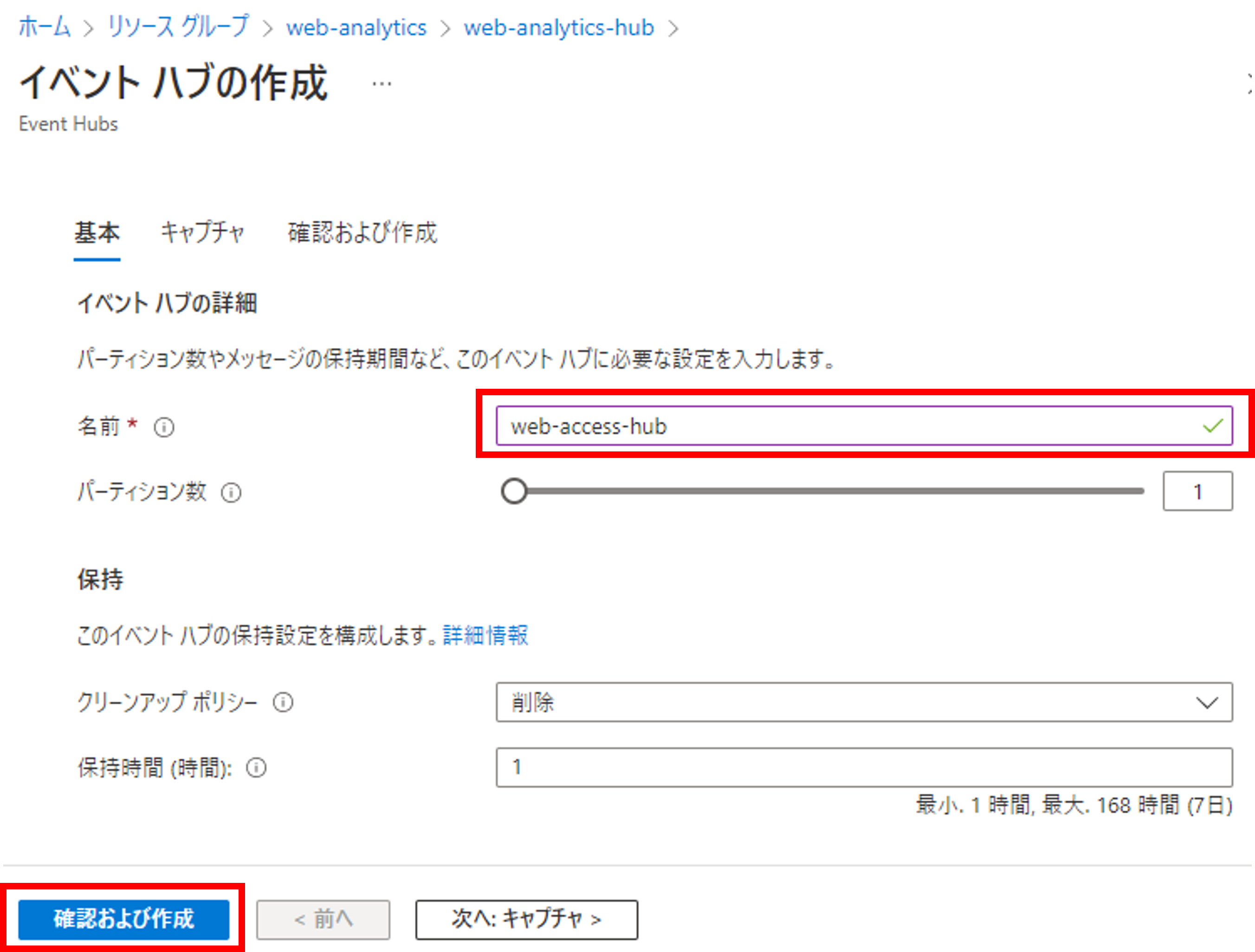
名前を入力し、確認および作成をクリックします。
次にリソースに対してアクセスポリシーを作成します。[共有アクセスポリシー]->[追加]をクリックし、ポリシー名を入力、送信を選択し、作成をクリックしましょう。
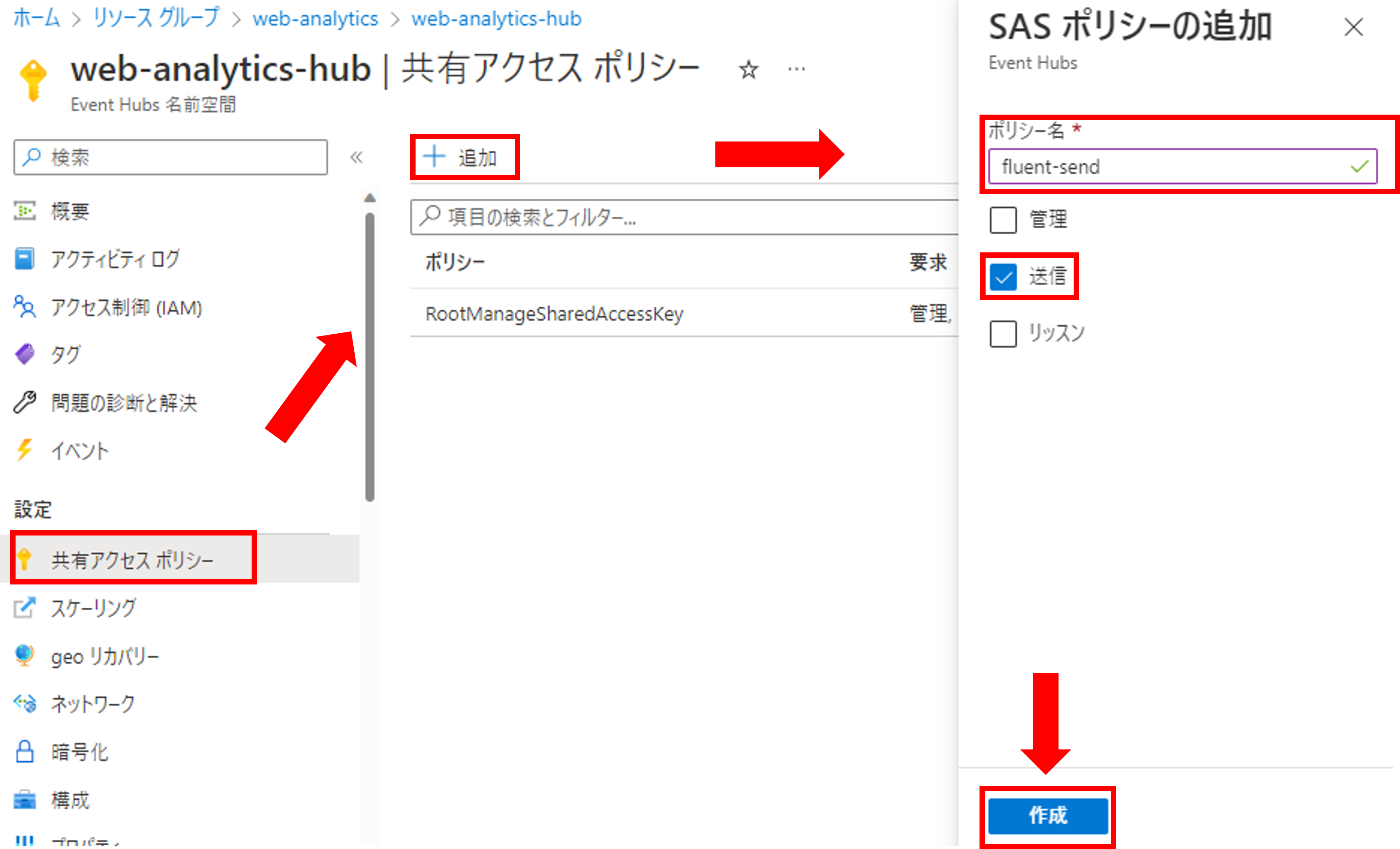
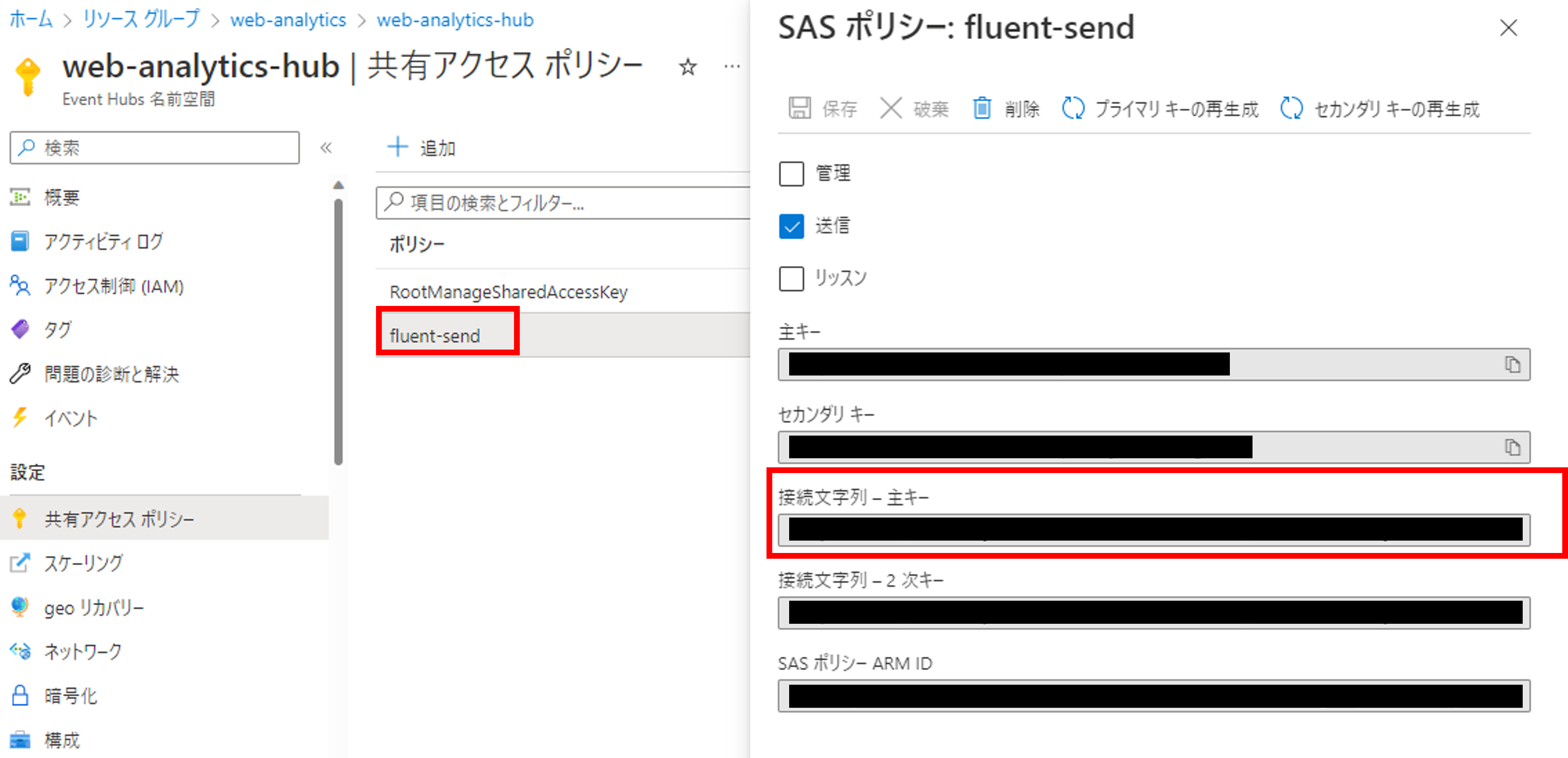
作成したポリシーを確認すると、「接続文字列-主キー-」という項目が確認できます。fluentdからログを送る時はこの接続文字列を使います。
Webサーバとfluentdの準備
次にローカルPC上でWebサーバの準備とfluentdの設定を行います。今回はnginx/fluentd/elasticsearch/kibanaを丸ごと構築できる便利なdockerファイルがGitに公開されていたので、こちらを改造して使わせていただきます。
今回elasticsearchとkibanaは使わないのでdocker-compose.ymlから除外します。
version: "3"
services:
web:
image: httpd
ports:
- "80:80"
links:
- fluentd
logging:
driver: "fluentd"
options:
fluentd-address: localhost:24224
tag: httpd.access
fluentd:
build: ./fluentd
volumes:
- ./fluentd/conf:/fluentd/etc
ports:
- "24224:24224"
- "24224:24224/udp"
次にfluentdにeventhubへログを送るためのプラグインインストールの設定をDockerfileに加えます。プラグインのリファレンスはこちらになります。
https://github.com/htgc/fluent-plugin-azureeventhubs
FROM fluent/fluentd:v1.12.0-debian-1.0
USER root
RUN ["gem", "install", "fluent-plugin-elasticsearch", "--no-document", "--version", "5.2.4"]
RUN ["gem", "install", "fluent-plugin-azureeventhubs", "--no-document"]
USER fluent
最後にfluentdのconfに先ほど作成したEvent Hubsの接続情報を書きます。connection_stringには先ほど取得したEvent Hubsの接続文字列を、hub_nameにはリソース内で作成したハブ名(今回は「web-access-hub」)を入力しましょう。
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
<match *.**>
@type azureeventhubs_buffered
connection_string Endpoint=<endpoint>;SharedAccessKeyName=<SharedAccessKeyName>;SharedAccessKey=<SharedAccessKey>
hub_name web-access-hub
<buffer>
flush_thread_count 1
flush_interval 1
</buffer>
</match>
<buffer>~</buffer>の部分でfluentdのログのバッファリング間隔を1秒に設定しています。
最終的なフォルダー構成は下記の通りとなります。
.
├── docker-compose.yml
└── fluentd
├── Dockerfile
└── conf
└── fluent.conf
それでは実際にdockerを起動させて、ログを送信します。
$ docker-compose up
ブラウザからlocalhostにアクセスし、何回か更新ボタンを押しましょう。
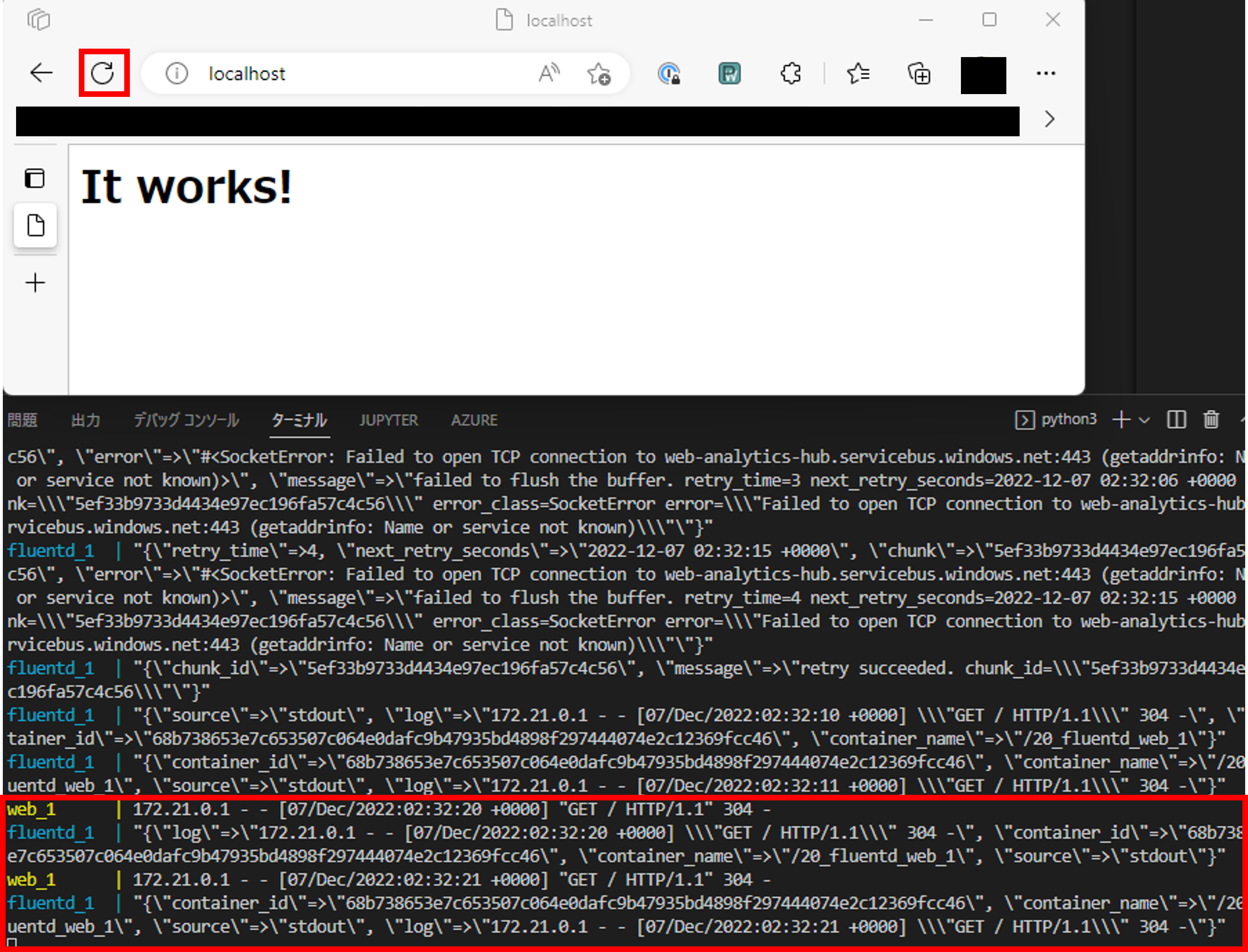
ログが送信されていることが確認できていますね。
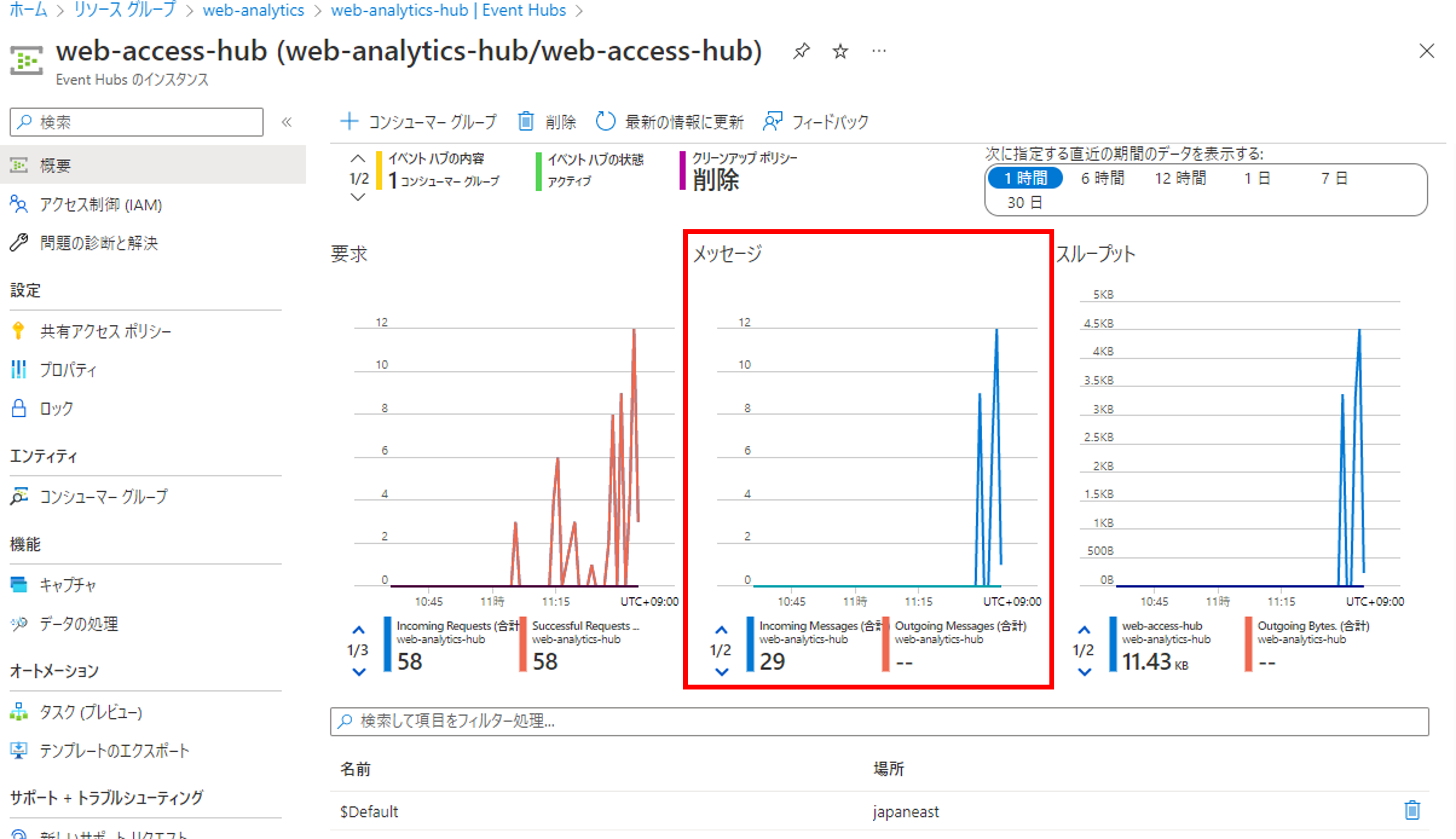
Event Hubs側からもログが受信できているか確認してみましょう。[エンティティ]->[Event Hubs]から先ほど作成したハブをクリックします。
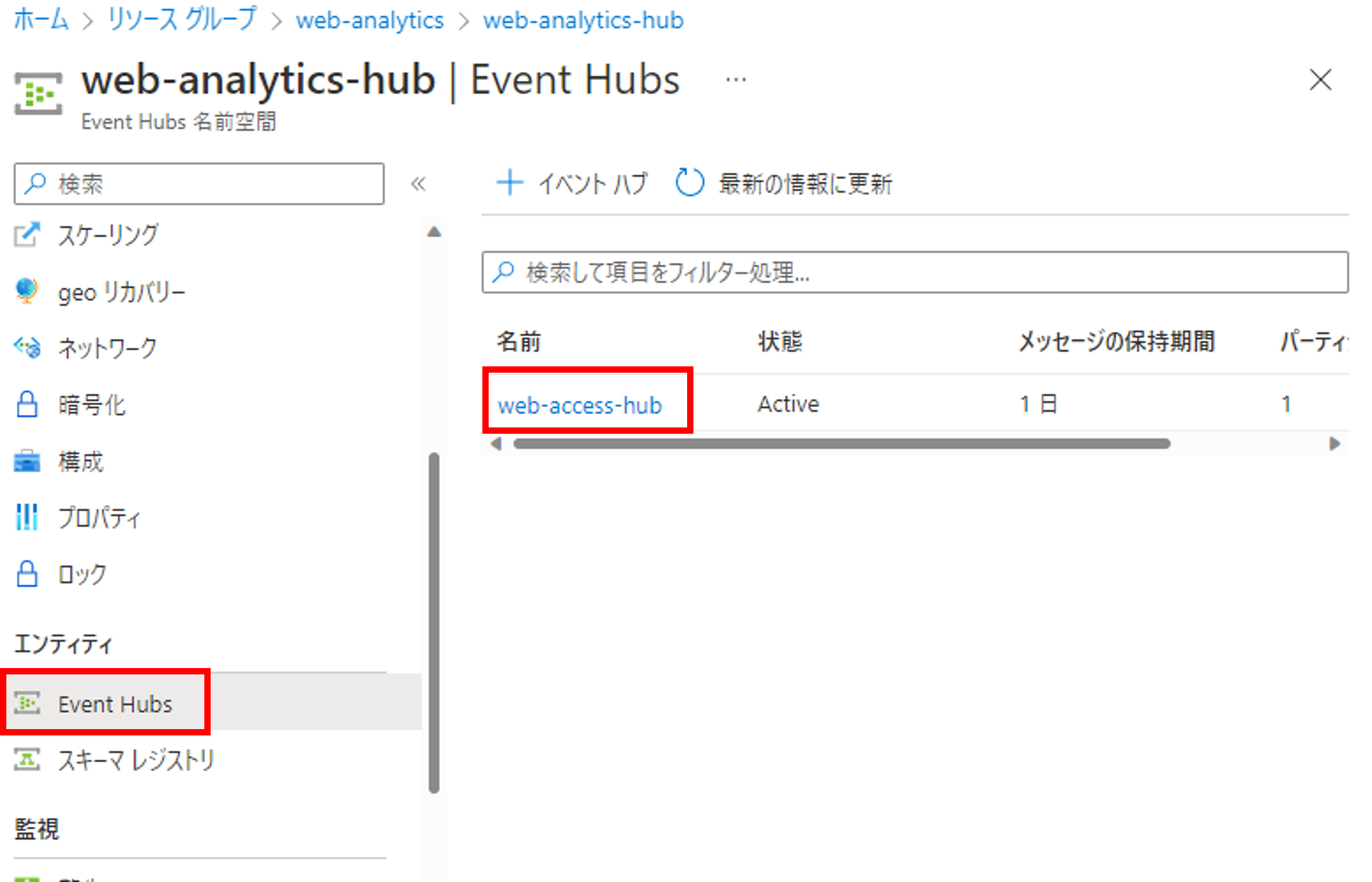
メッセージのグラフを確認すると何かしらのメッセージを受信できていることが確認できます。
Data Explorerの準備
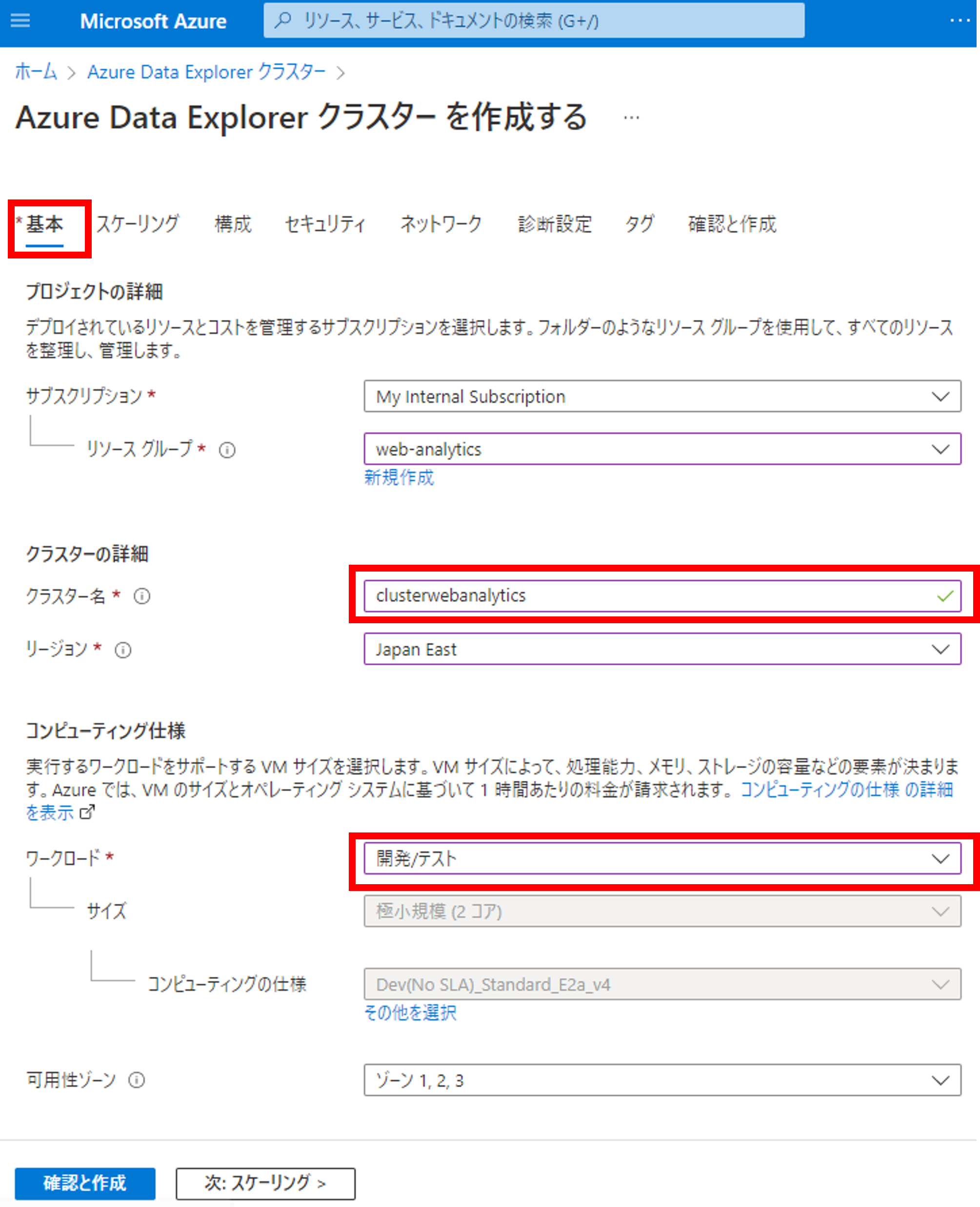
次にData Explorerのクラスターを準備します。クラスター名を入力し、ワークロードを選択しましょう。
次に構成タブを開きます。今回はData Explorerのリアルタイム性を検証するためにストリーミングインジェストをオンにします。デフォルト(オフ)の場合は、数分間データをバッファリングしてからData Explorerに蓄積する仕様です(数分程度)。
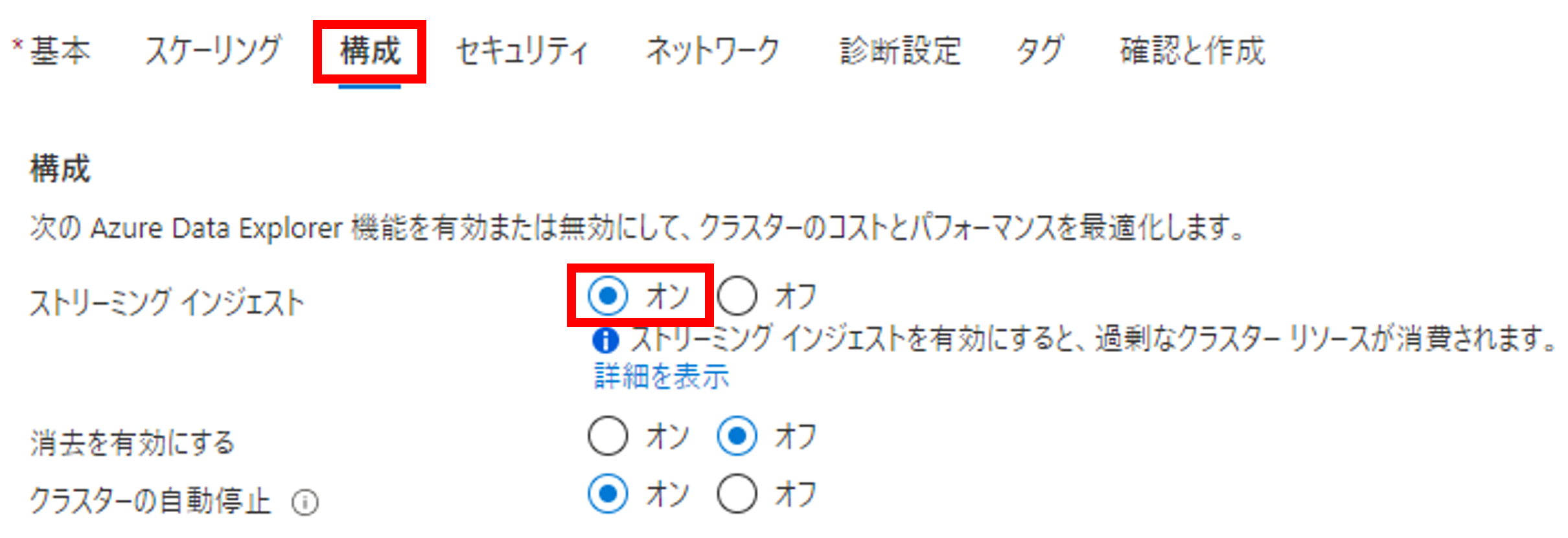
ストリーミングインジェストの設定は、インジェストを1秒未満に抑えられる代わりに、クラスターへの負荷が増大するため、本番環境ではワークロードのサイズを増やす、といった対応が必要になるかもしれません。ストリーミングインジェストの詳しい制約は公式ドキュメントをご参照ください。
https://learn.microsoft.com/ja-jp/azure/data-explorer/ingest-data-streaming?WT.mc_id=Portal-Microsoft_Azure_Kusto&tabs=azure-portal%2Ccsharp
クラスターの作成が完了したら、次にデータベースを作成します。
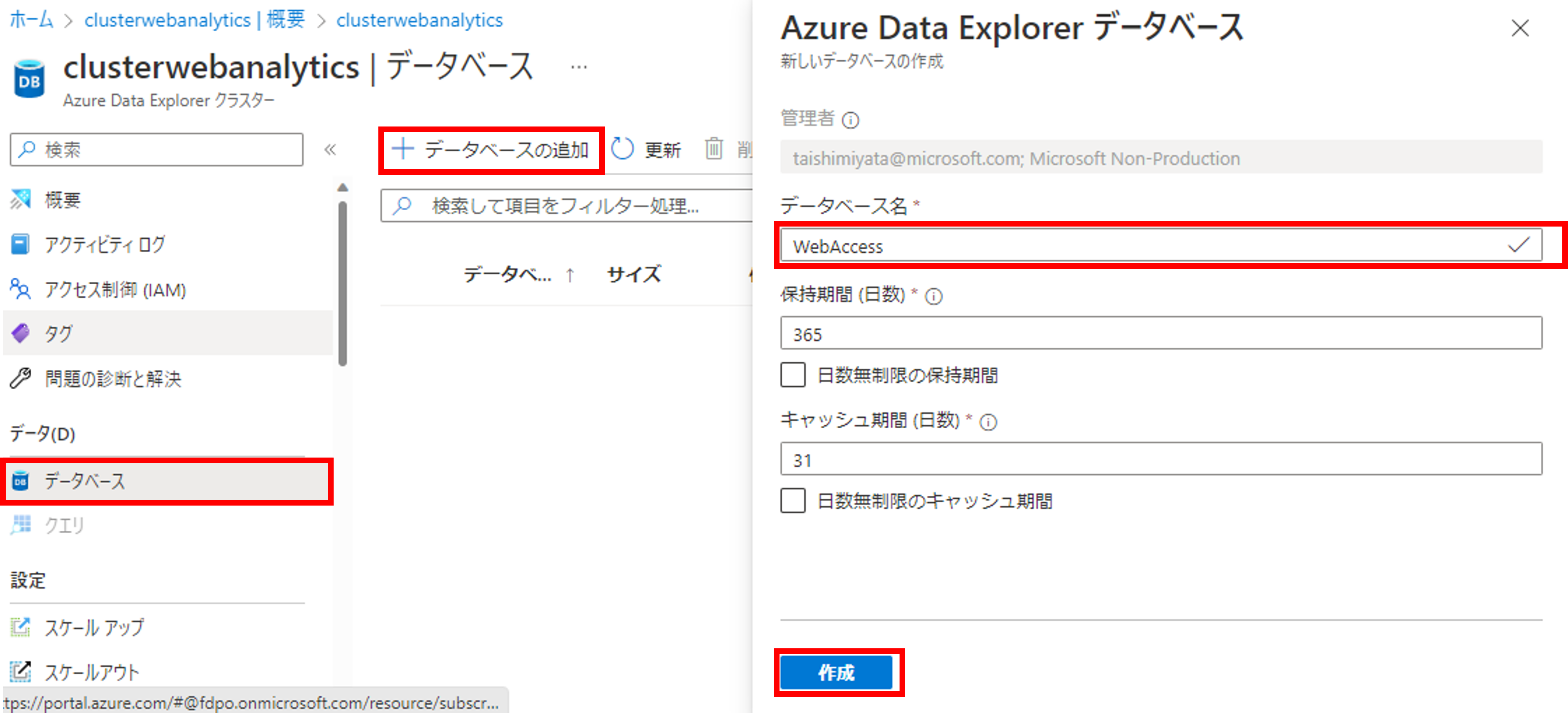
次にテーブルの作成とEvent Hubsの接続の設定を行います。[概要]->[データインジェスト]->[取り込み]をクリックしましょう。Data ExplorerのWebアプリが表示されます。
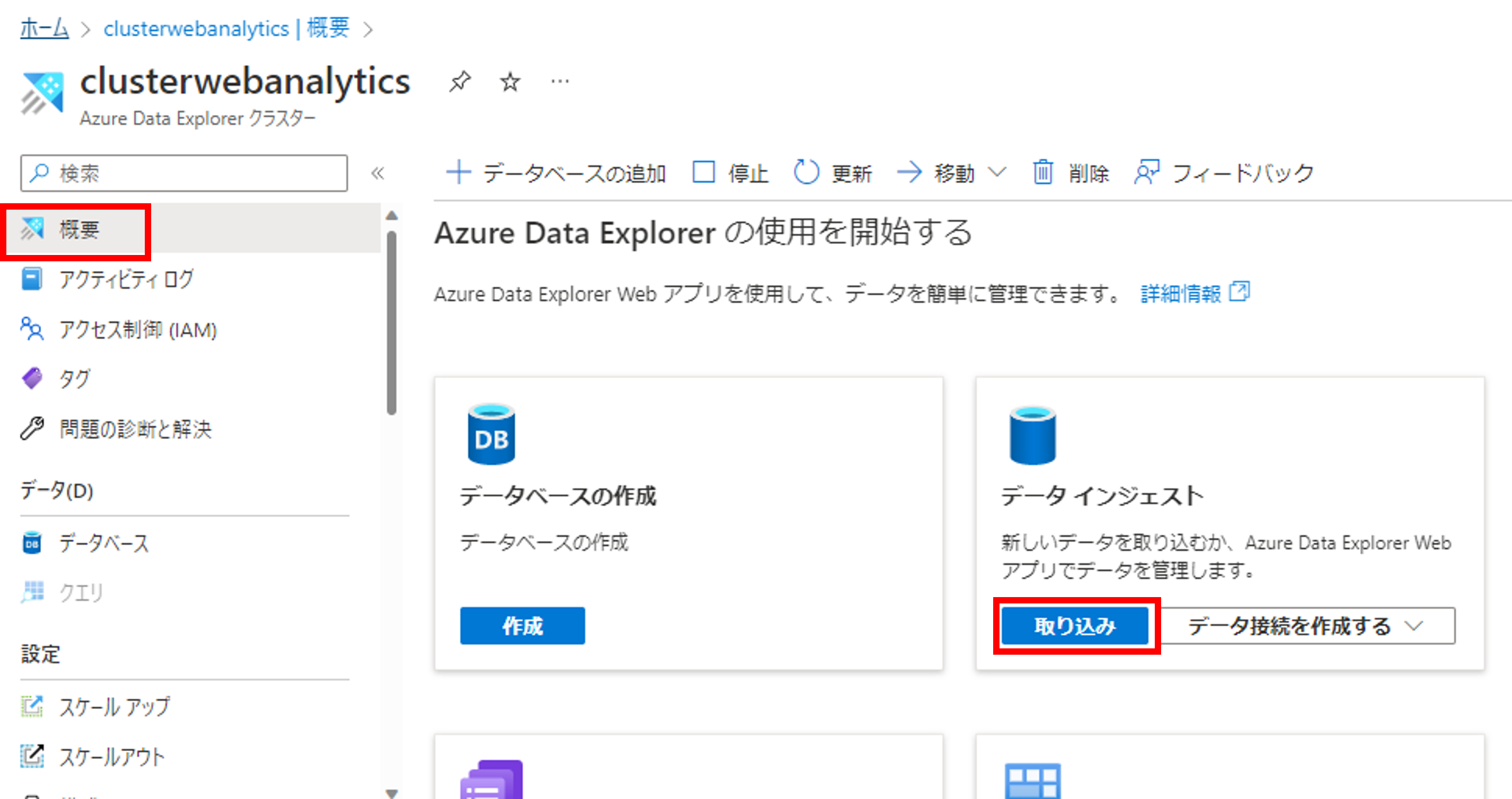
データの取り込みの画面に遷移するので、テーブル名を入力して、次へをクリックしましょう。
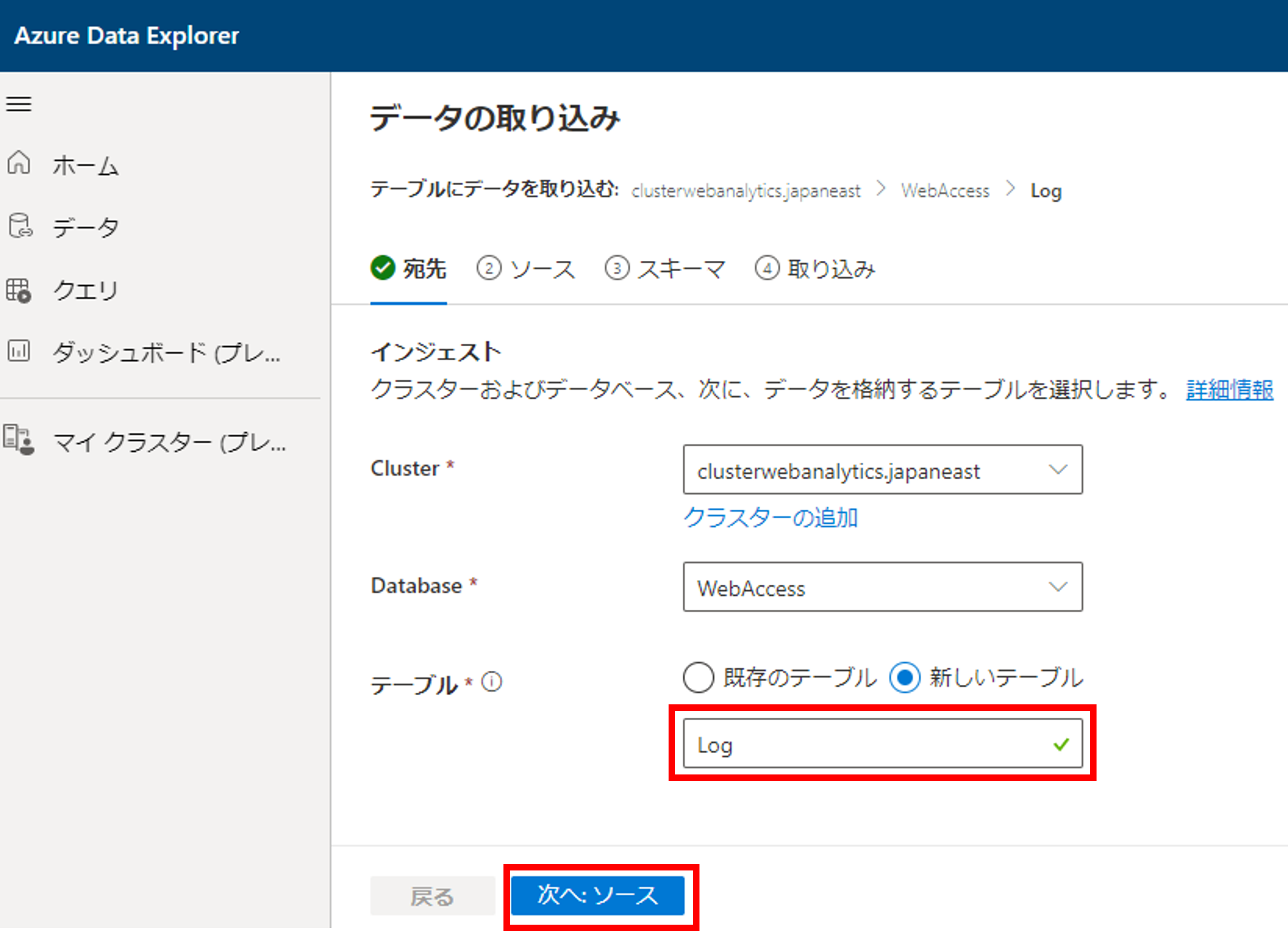
ソースタイプにイベントハブを選択すると、接続情報を選択できます。作成したEvent Hubsの情報を選択していきましょう。コンシューマーグループは$DefaultでOKです。
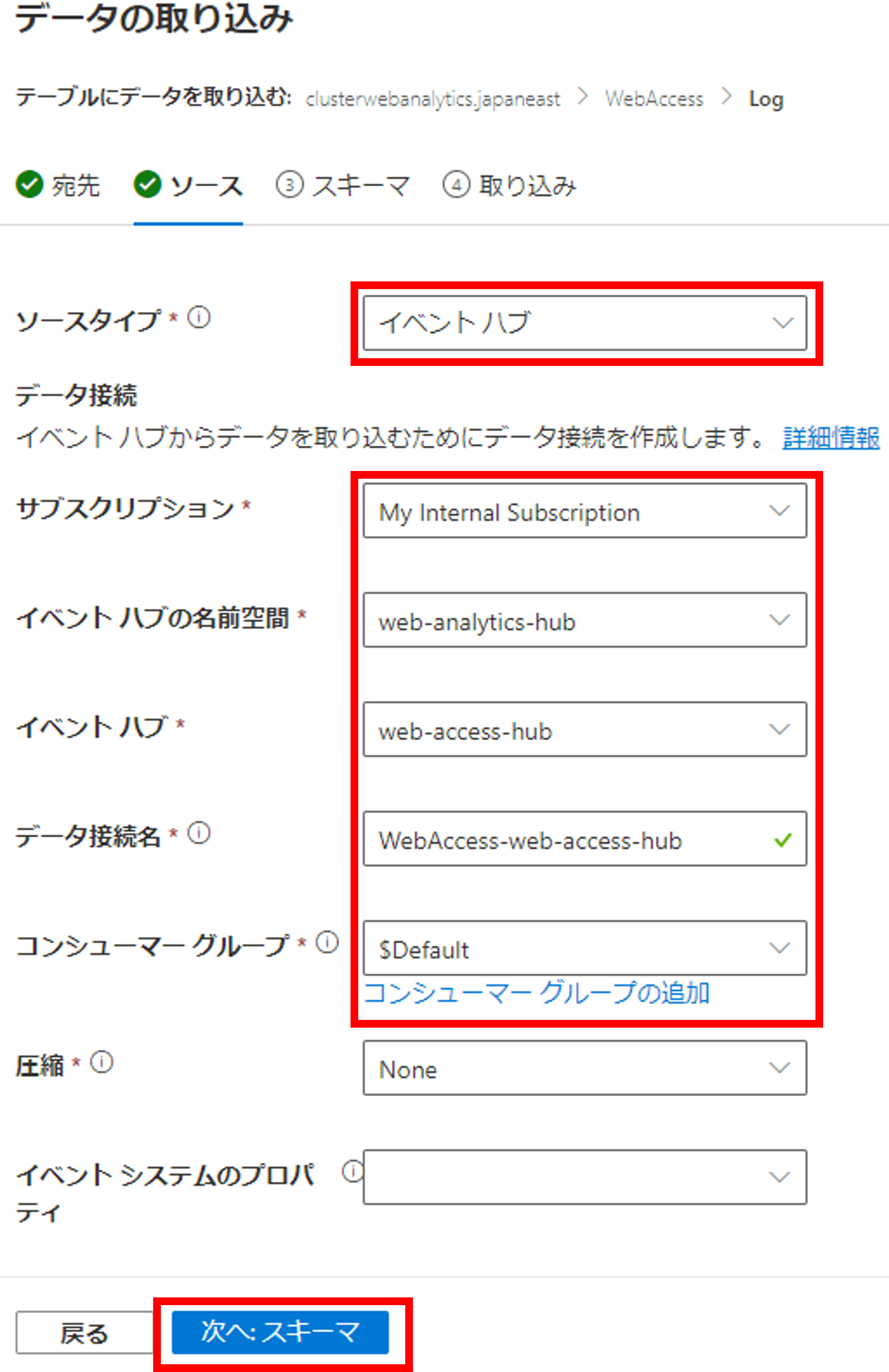
Event Hubsにデータを送信済みの場合は自動でスキーマを読み取ってくれます。データ形式が最初TXTになっていると思うので、JSONに変更しましょう。すると下記の画像のようにJSONのKeyをテーブルのカラムに設定してくれます。また、ストリーミングインジェストを有効にするにチェックを入れましょう。
インジェストの設定が完了したら、再びlocalhostにアクセスし、ログを流してみます。[クエリ]->[WebAccess]->[Log]のテーブルを選択し、テーブル名を入れて実行してみましょう。クエリ結果が返ってきていることが確認できると思います。
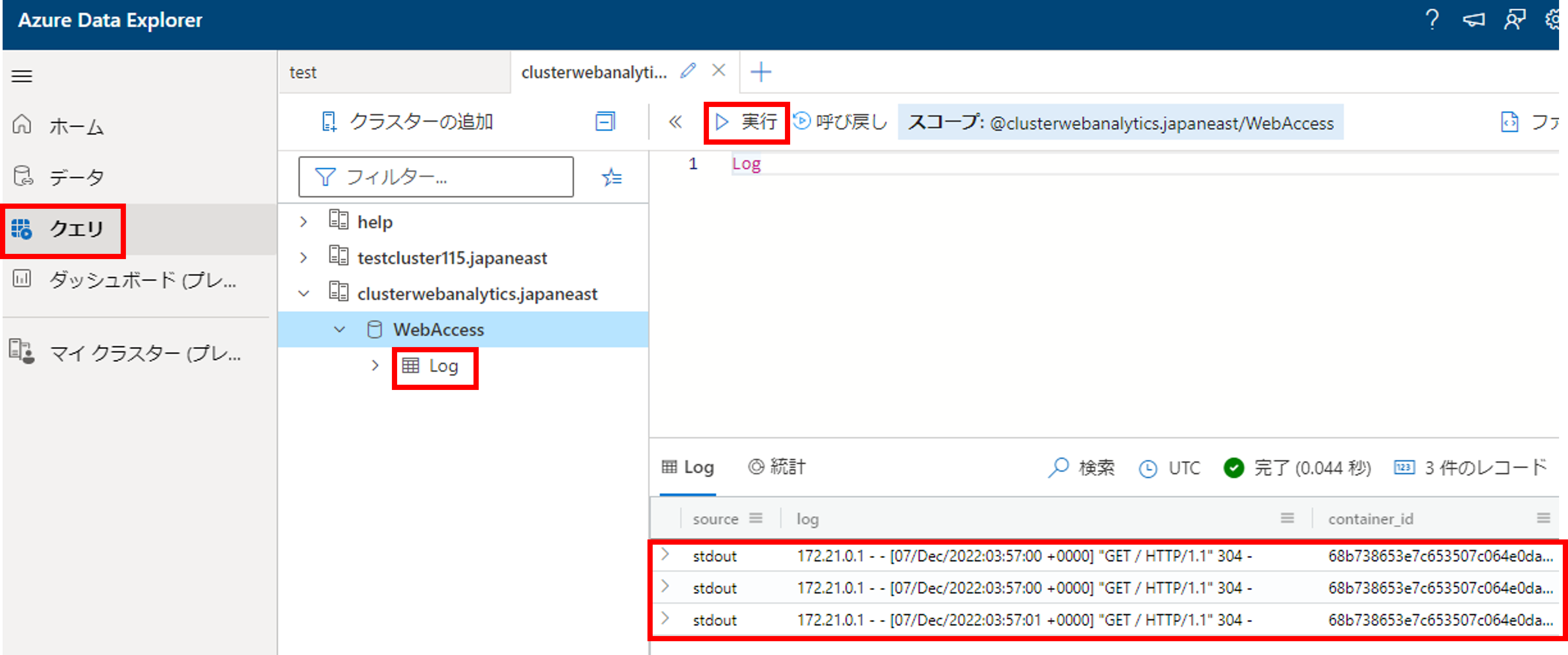
リアルタイム性の検証
さて、無事アクセスログをData Explorerに蓄積するところまで完成したので、次はどれくらいリアルタイムにインジェストされるのか検証してみたいと思います。
Data ExplorerではKustoクエリを用いて分析を行います。データベースで良く使われるSQLクエリはデータ処理全般をこなせるように最適化されていますが、Kustoクエリはデータマイニングに特化されたクエリです。処理を|でつなげるので、1行1行デバッグしながら処理を実行できます。SQLよりも簡単なので、早くなれることができると思います。
下記Kustoクエリを実行しました。
Log
| project source, log
| extend ingestionTime = ingestion_time()
| extend DAY = toint(extract(@'.*\[(.*)/.*/.*:.*:.*:.*\].*', 1, log))
| extend MONTH = extract(@'.*\[.*/(.*)/.*:.*:.*:.*\].*', 1, log)
| extend YEAR = substring(extract(@'.*\[.*/.*/(.*):.*:.*:.*\].*', 1, log),2,2)
| extend TIME = extract(@'.*\[.*/.*/.*:(.*:.*:.*) .*\].*', 1, log)
| extend DATETIME = strcat(DAY, " ", MONTH, " ", YEAR, " ", TIME)
| extend accessTime = todatetime(DATETIME)
| project source, log, accessTime, ingestionTime
| where not(isempty(log))
| extend duration = datetime_diff('millisecond', ingestionTime, accessTime)/1000.0
ingestion_time()を使うことで、Data Explorerにインジェストされた時刻を取得することができます。4行目~9行目はWebアクセスのログからアクセス時刻を抽出するクエリです。代表的な時刻表記であれば1行で書けるのですが、今回は表記がパースしにくく、苦労しました。。。
クエリの実行結果は下記の通りとなります。
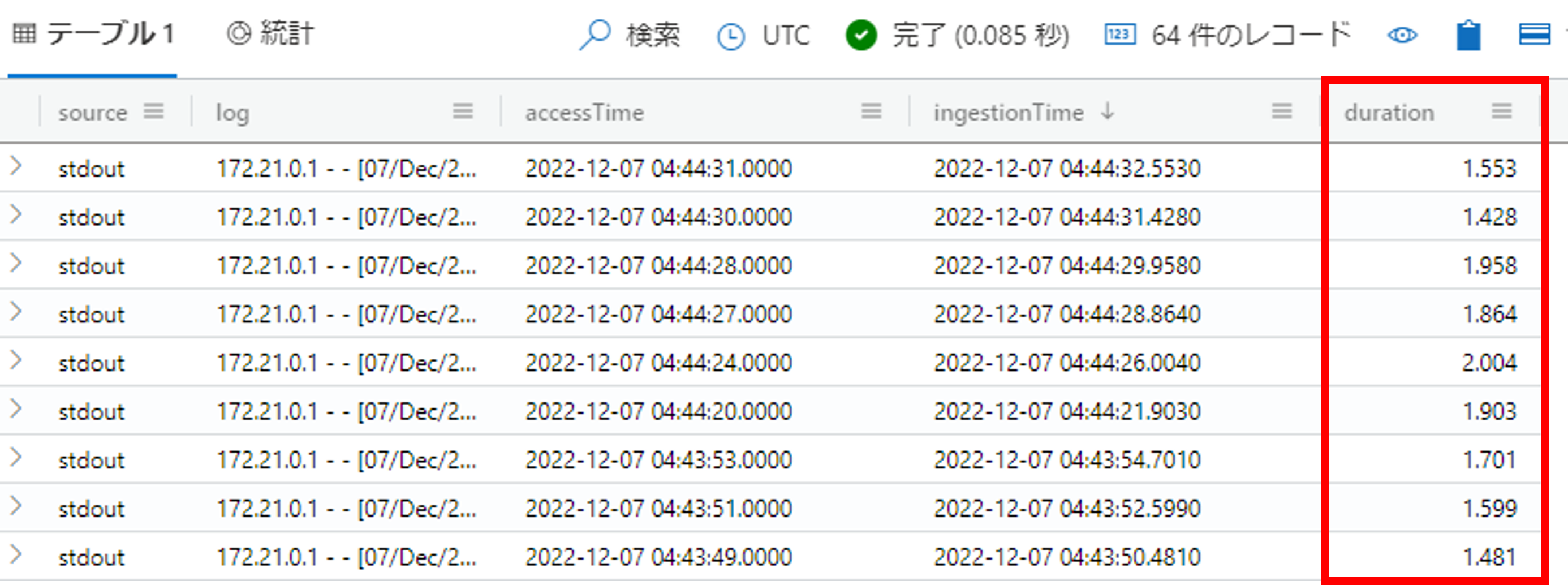
accessTimeがWebサイトの更新をクリックした時刻、ingestionTimeがData Explorerにインジェストされた時刻、durationが両時刻の差分(ミリ秒)となります。accessTimeが1秒刻みの表記、かつ、fluentdに1秒のバッファー間隔のため、最大2秒ほどのラグが生じることを考慮すると、公式記載の通り待機時間1秒未満で分析ができそうです。
アクセス数の可視化
次にログからアクセス数の可視化を行います。次のようなクエリで可視化することができます。
Log
| project source, log
| extend ingestionTime = ingestion_time()
| extend DAY = toint(extract(@'.*\[(.*)/.*/.*:.*:.*:.*\].*', 1, log))
| extend MONTH = extract(@'.*\[.*/(.*)/.*:.*:.*:.*\].*', 1, log)
| extend YEAR = substring(extract(@'.*\[.*/.*/(.*):.*:.*:.*\].*', 1, log),2,2)
| extend TIME = extract(@'.*\[.*/.*/.*:(.*:.*:.*) .*\].*', 1, log)
| extend DATETIME = strcat(DAY, " ", MONTH, " ", YEAR, " ", TIME)
| extend accessTime = todatetime(DATETIME)
| project source, log, accessTime
| where source == "stdout"
| summarize count() by bin(accessTime,1m)
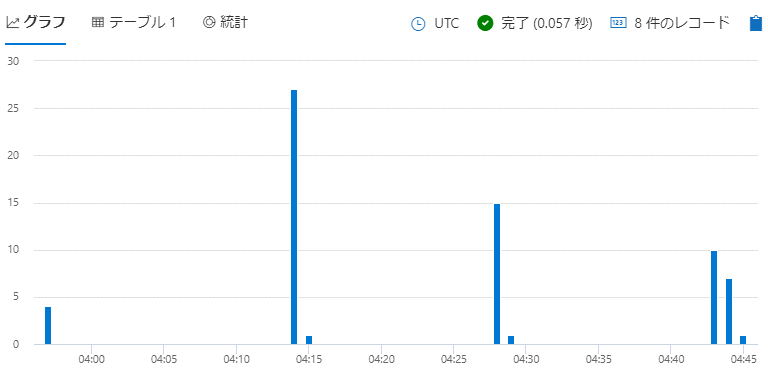
| render columnchart
ポイントは下から2行目で各時刻におけるカウントを集計している部分と最後の行で縦棒グラフを表示させている部分です。実行した結果は下記の画像のようになります。
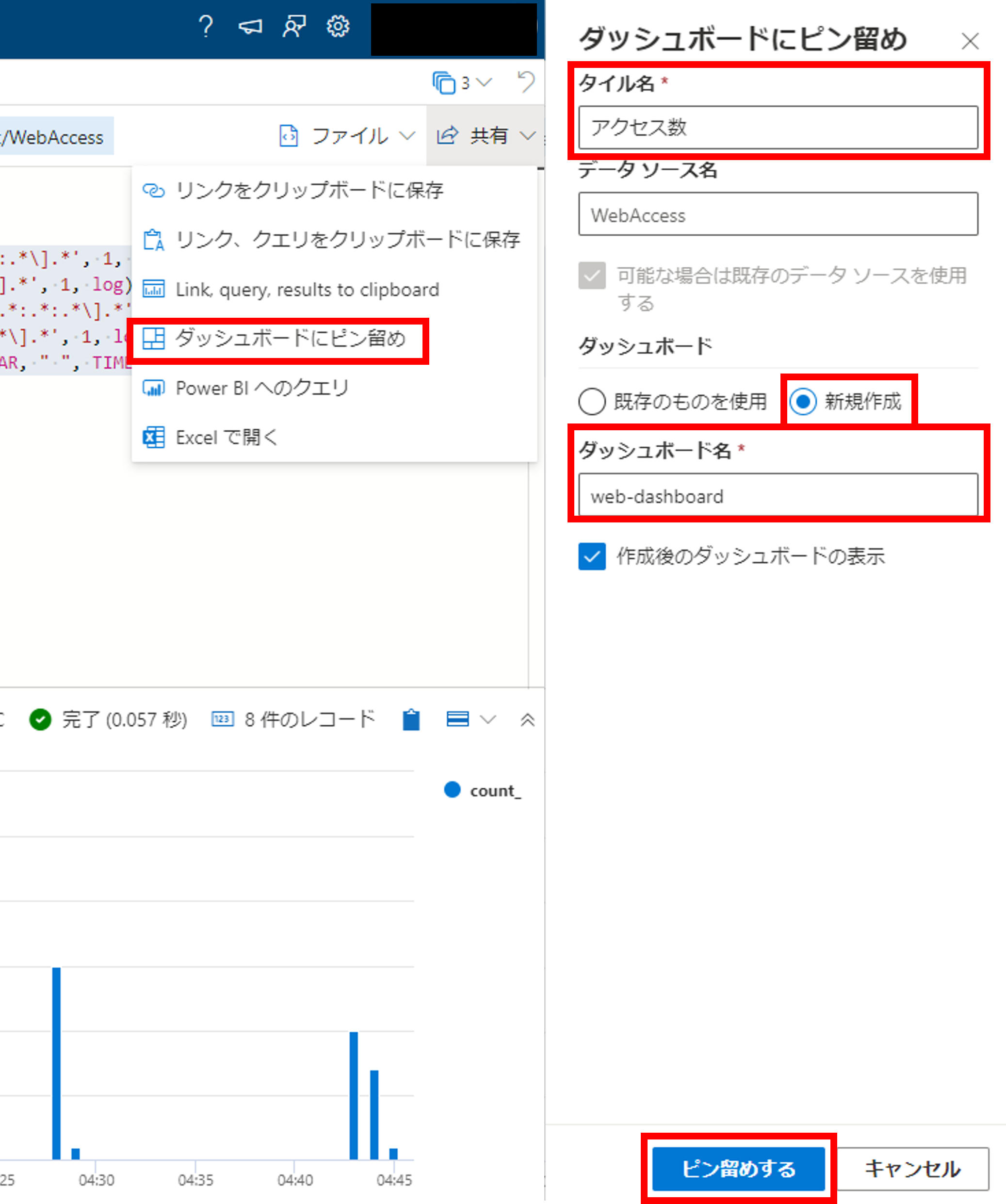
一度作成したグラフはダッシュボードへピン止めできます。右上の[共有]->[ダッシュボードへピン留め]をクリックし、タイル名(グラフ名)とダッシュボード名を埋めましょう。
すると、ダッシュボードに作成したグラフが埋め込まれました。
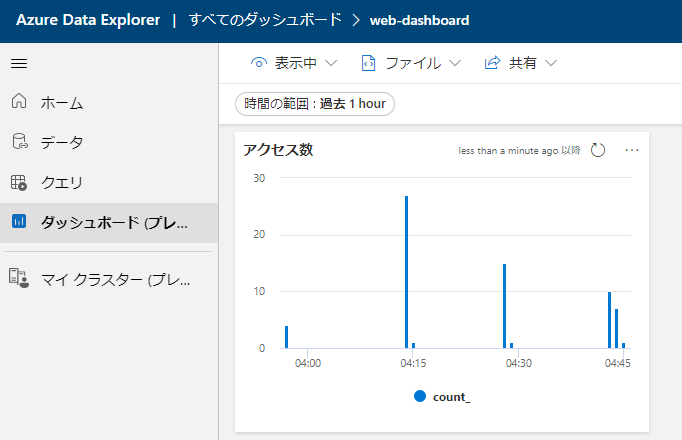
グラフは作成した後は随時更新できるようにしたいですね。ダッシュボードにて上部の[編集中]をクリックしましょう。
右上のボタンから[自動更新]をクリックします。
こちらで更新間隔を設定します。最小が30sとなります。
以上でグラフの自動更新の設定は完了です。
まとめ
今回はログ分析におけるData Explorerの使い方とリアルタイム性について解説しました。Data ExplorerはMicrosoftのAzureやXboxのログ基盤にも利用されており、ビッグデータとリアルタイム性においてかなりのポテンシャルを秘めています。是非、一度お試しください。
(2022年12月21日)続編としてAzure Metrics Advisorを使った異常検知の記事も書きましたので、良ければご一読ください!