皆さん、AzureのAutoMLは活用していますでしょうか?
データさえ準備しておけば、Azure Machine Learning Studio(WEBブラウザ)からポチポチっとボタンをクリックするだけで、モデルの学習→評価→デプロイまで簡単に実行できます。
以前は「分類」「回帰」「時系列の予測」がWEBブラウザ経由の実行に対応していましたが、今年22年6月に「Computer Vision(画像)」「Natural Language Processing(自然言語処理)」がWEBブラウザ経由の実行に対応しました!
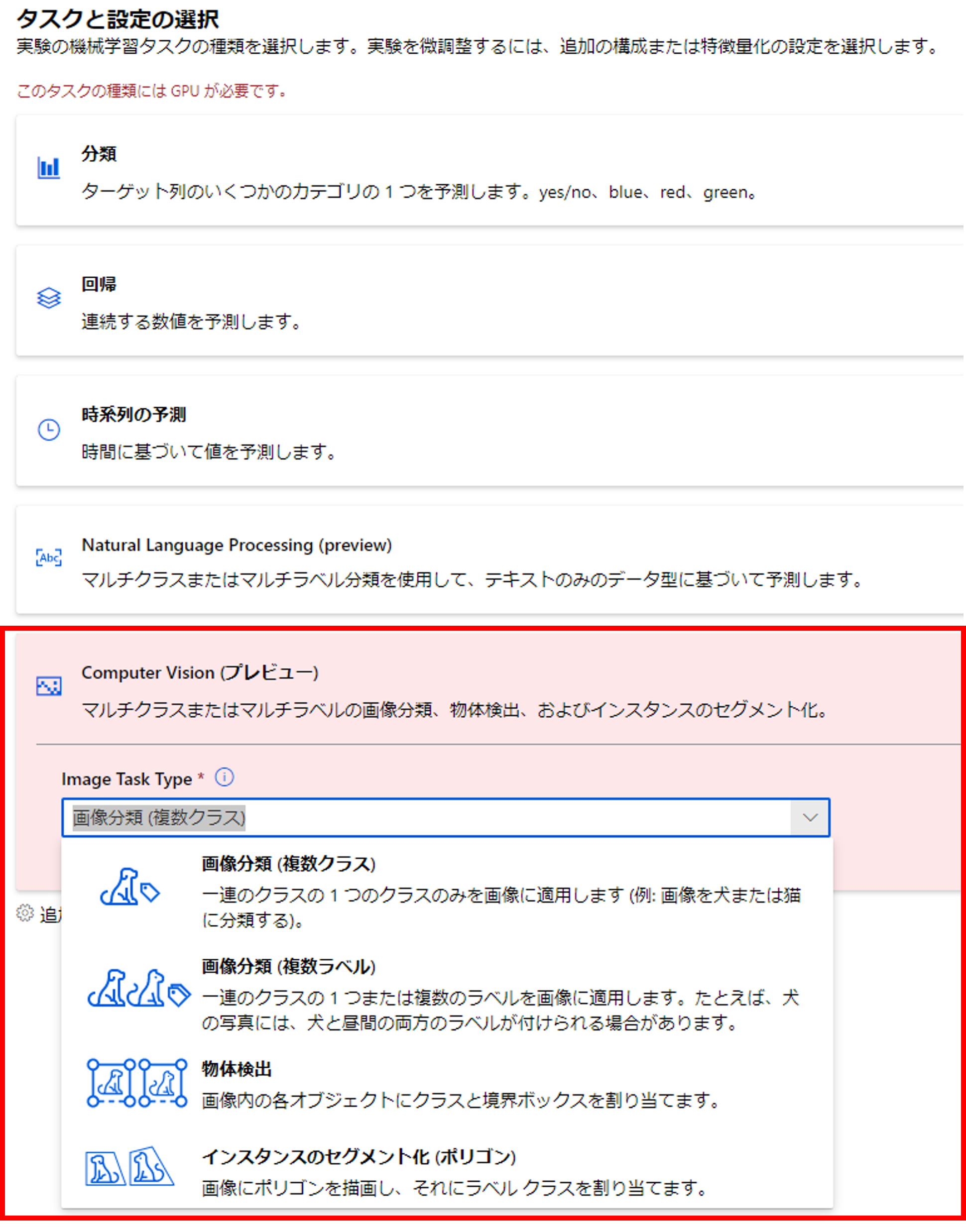
「Computer Vision」のタスクでは、「画像分類(複数クラス)」「画像分類(複数ラベル)」「物体検出」「インスタンスのセグメント化」が利用できます。
今回は「画像分類(複数クラス)」のAutoMLに関して解説していきます。
問題設定
今回は与えられた画像が犬か猫かを判別する分類モデルを作っていきます。
画像は例のごとくkaggleから拝借しました。
画像のラベル付け
まずは、画像の学習データから作っていきましょう。
AutoMLでは、画像のラベルをJSONL形式を準備する必要があります。※
[
{
"image_url":"AmlDatastore://data_directory/../Image_name.image_format",
"image_details":{
"format":"image_format",
"width":"image_width",
"height":"image_height"
},
"label":"class_name",
},
{...}
]
1からJSONLを作るのはめんどくさいですが、Azureのデータラベル付けツールを使えば、簡単にJSONLを作れます。
※自動機械学習を使用してコンピューター ビジョン モデルをトレーニングするためのデータ スキーマ
データセットの登録
ラベル付けツールを使う前に、画像データをデータセットとして登録しておきます。
画像データはAzure Data Lake Storage(ADLS)に下記の通り格納されています。
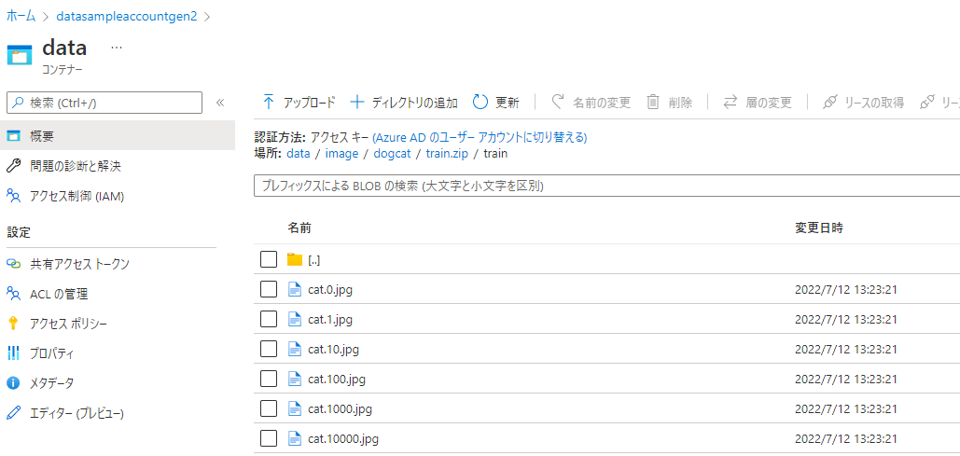
※Azure Machine LearningからADLSにアクセスする方法は下記をご参照ください。
Azure Machine Learning Studioにアクセスし、[データ]->[作成]->[データストアから]をクリックしましょう。
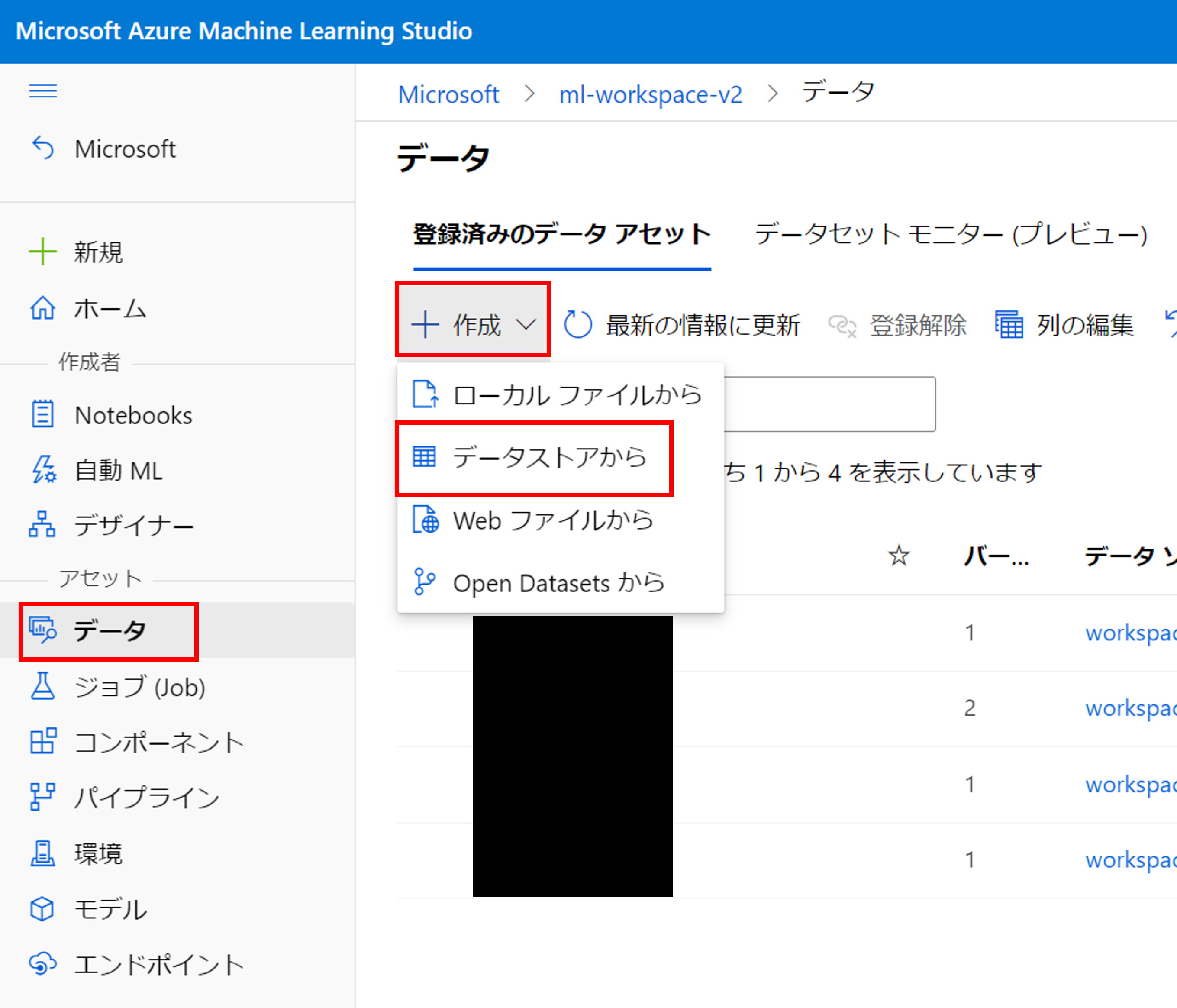
学習用のデータセットから作っていきましょう。
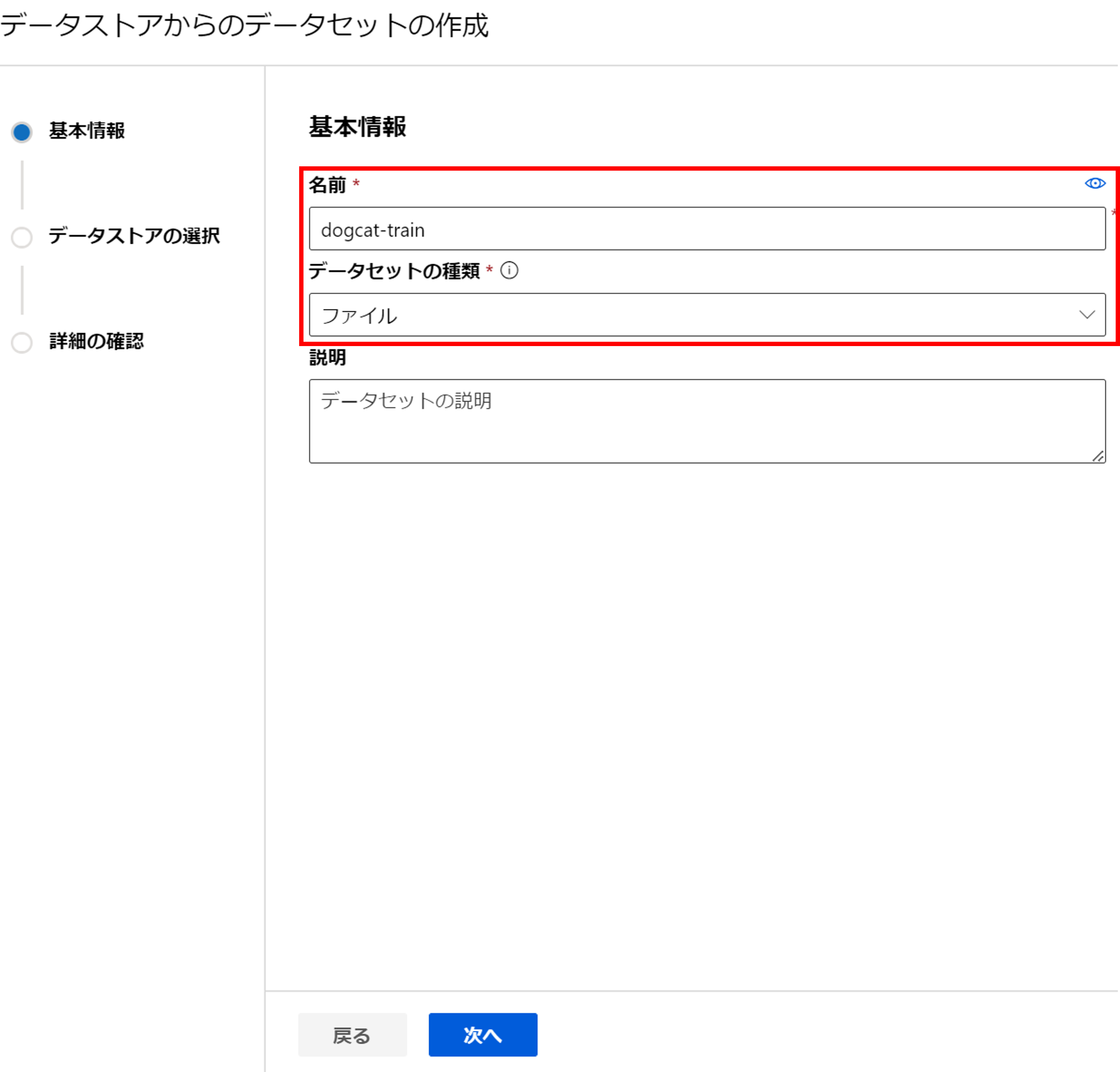
データセット名を入力し、データセットの種類は「ファイル」を選択しましょう。
学習データが格納されているデータストアを選択します。次に、画像データのパスをワイルドカード(*)を駆使して入力します。
今回はデータ量が多いので[データの検証をスキップ]にチェックを入れます※。
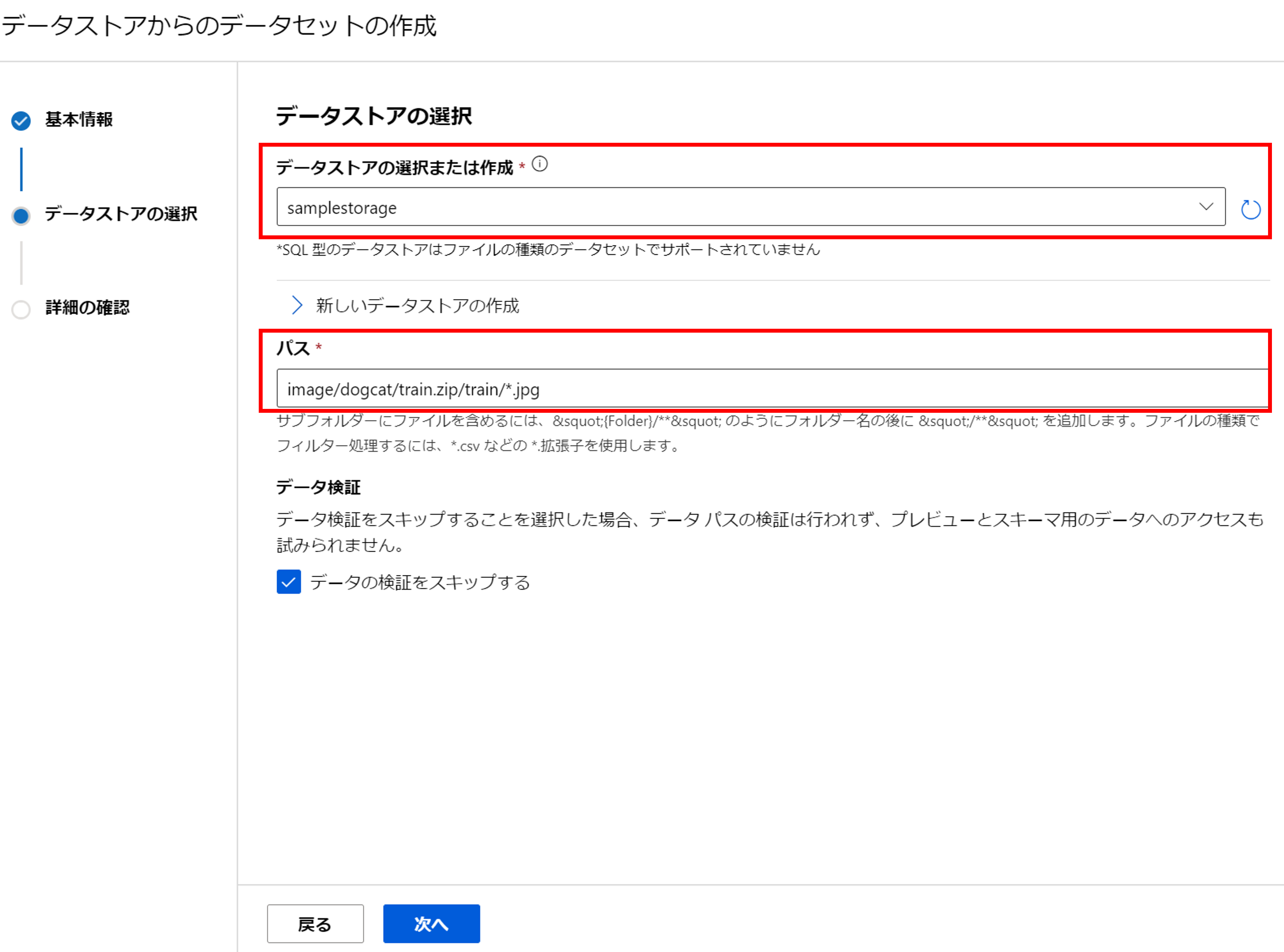
※[データの検証をスキップ]にチェック入れず次に進むと、スキャンするデータが多い場合はタイムアウトエラーが発生します。その場合は、パスをワイルドカードで指定せずに「image/dogcat/train.zip/train/cat.1.jpg」のように具体的に指定して、データ検証だけ行いましょう。そして、特にエラーが出なければ[戻る]をクリックし、再びワイルドカードでパスを指定し、[データの検証をスキップする]にチェックを入れて[次へ]をクリックしましょう。
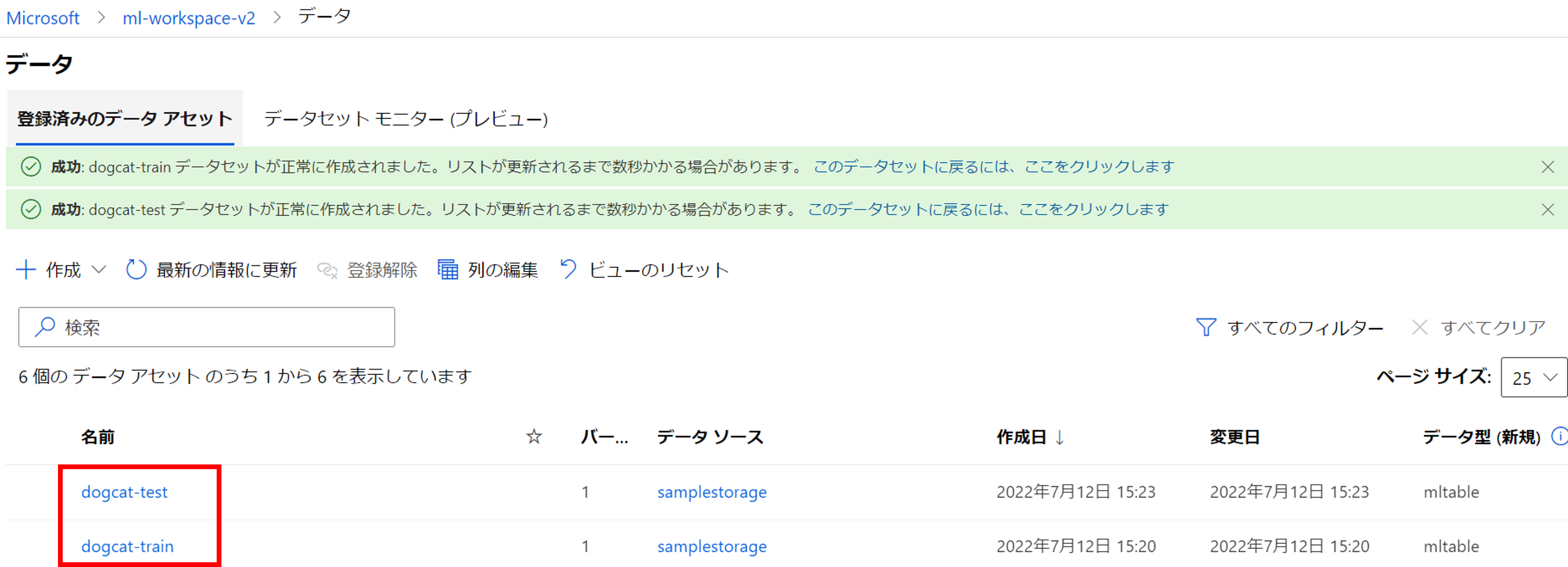
検証用のデータも同様の手順で登録します。すると、下記の通り学習用と検証用の2種類のデータセットが登録された状態になります。
データのラベル付け
次はこれらの画像にラベルを付けていきます。
ラベル付けプロジェクトの作成
左メニューの一番下の[データのラベル付け]->[プロジェクトの追加]をクリックしましょう。
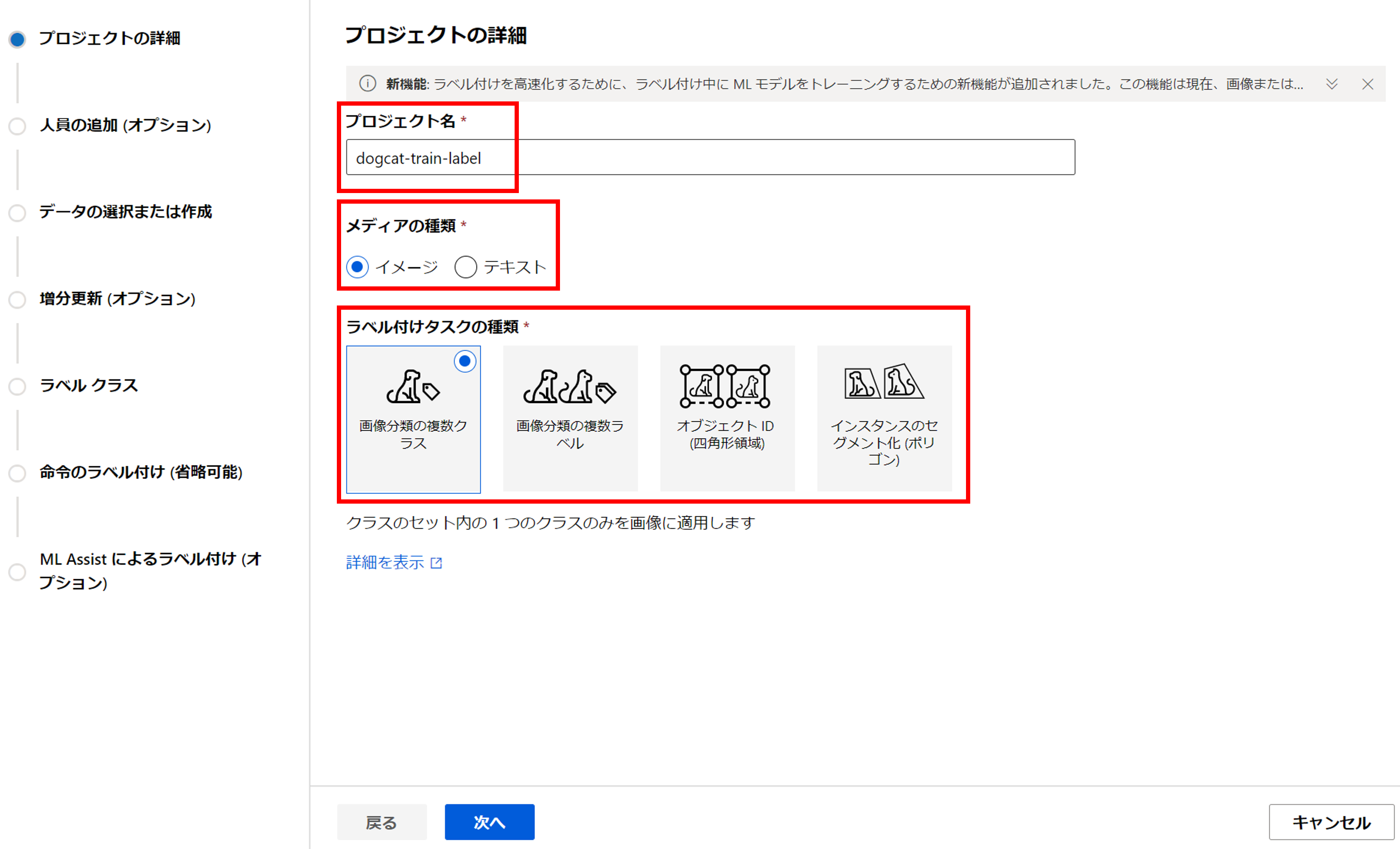
[プロジェクト名]を入力し、[メディアの種類]は「イメージを選択」、[タスクの種類]を「画像分類の複数クラス」を選択しましょう。
人員の追加ではラベル付けタスクを別の会社に委託することができます。
今回必要はないので、[次へ]をクリックしましょう。
先ほど登録したデータセットから「dogcat-train」を選択します。
増分更新を有効にすると、新しく画像データが追加された場合に、ラベリングタスクにその画像データを追加してくれます。
今回は特に必要ないので、[次へ]をクリックします。
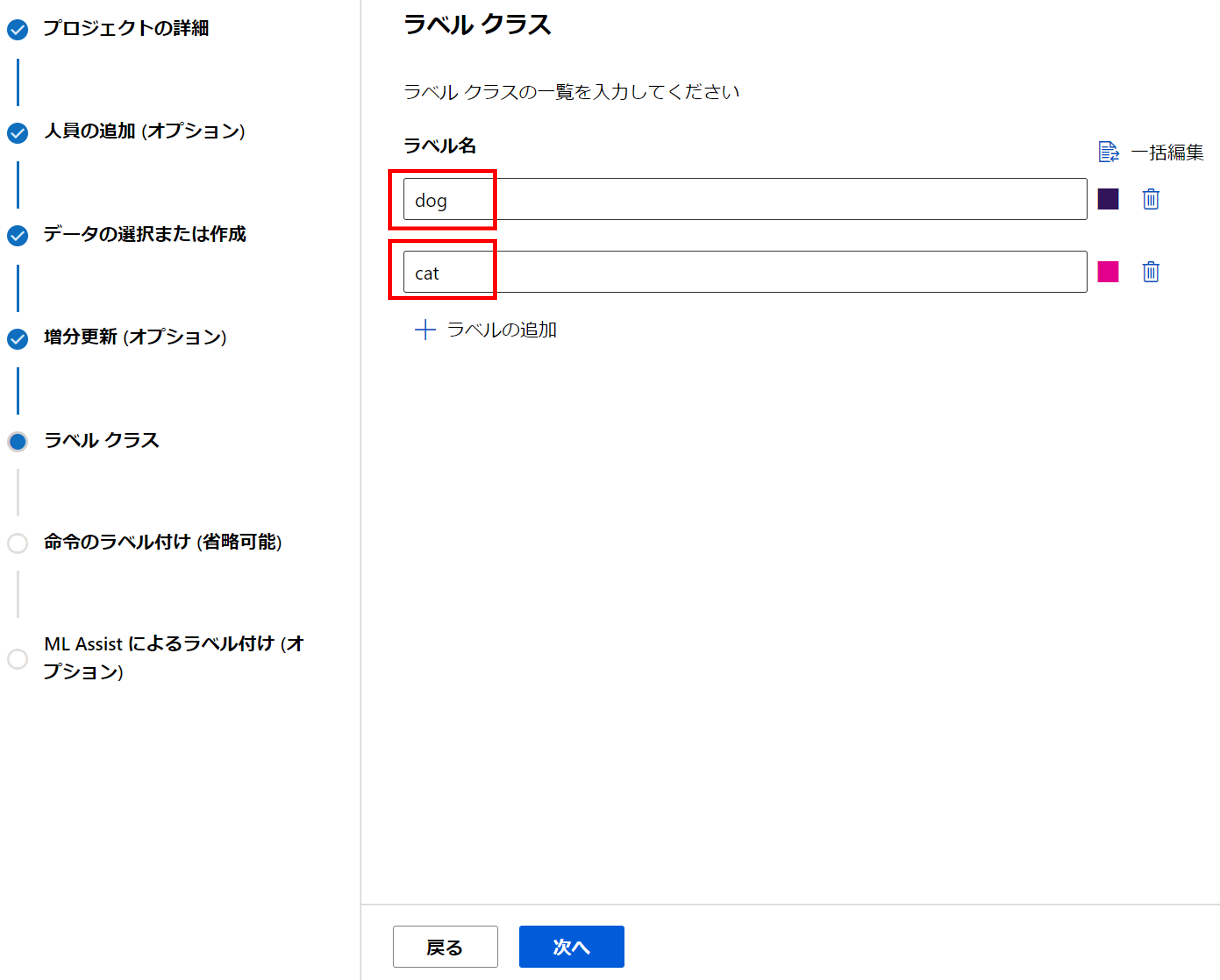
ラベル名を定義します。今回は「dog」と「cat」を入力します。
命令のラベル付けでは、タスク内容を記入することができます。
特に複数人数でラベリングする場合は、ラベルの判定基準を明記しておきましょう。
ML Assistにラベル付けを有効にすると、ラベル付け前のデータに対して機械学習モデルがラベルを予測して付与し、ラベリングの作業を高速化してくれます。今回は話を簡単にするためにあえて「無効」にしますが、便利な機能なのでまたの機会に解説するかもしれません。
最後に[プロジェクトの作成]をクリックしましょう。
画像のラベル付け
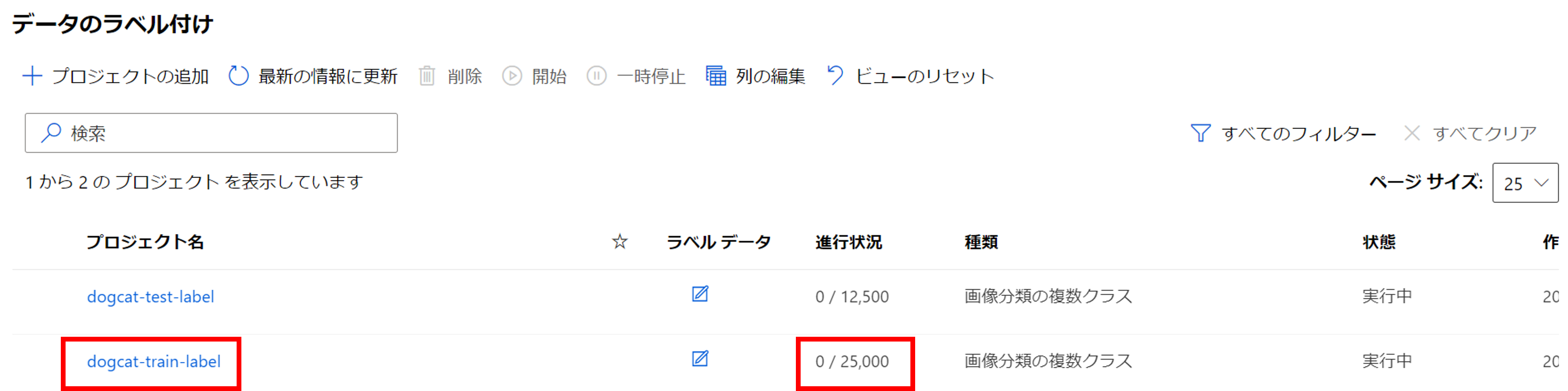
しばらく待つとプロジェクトが作成され、ラベルの進行状況も確認できます。
プロジェクト「dogcat-train-label」をクリックします。
こちらから画面からはタスクの状況を確認できます。
右上の[ラベルデータ]をクリックし、ラベリングしていきましょう。。
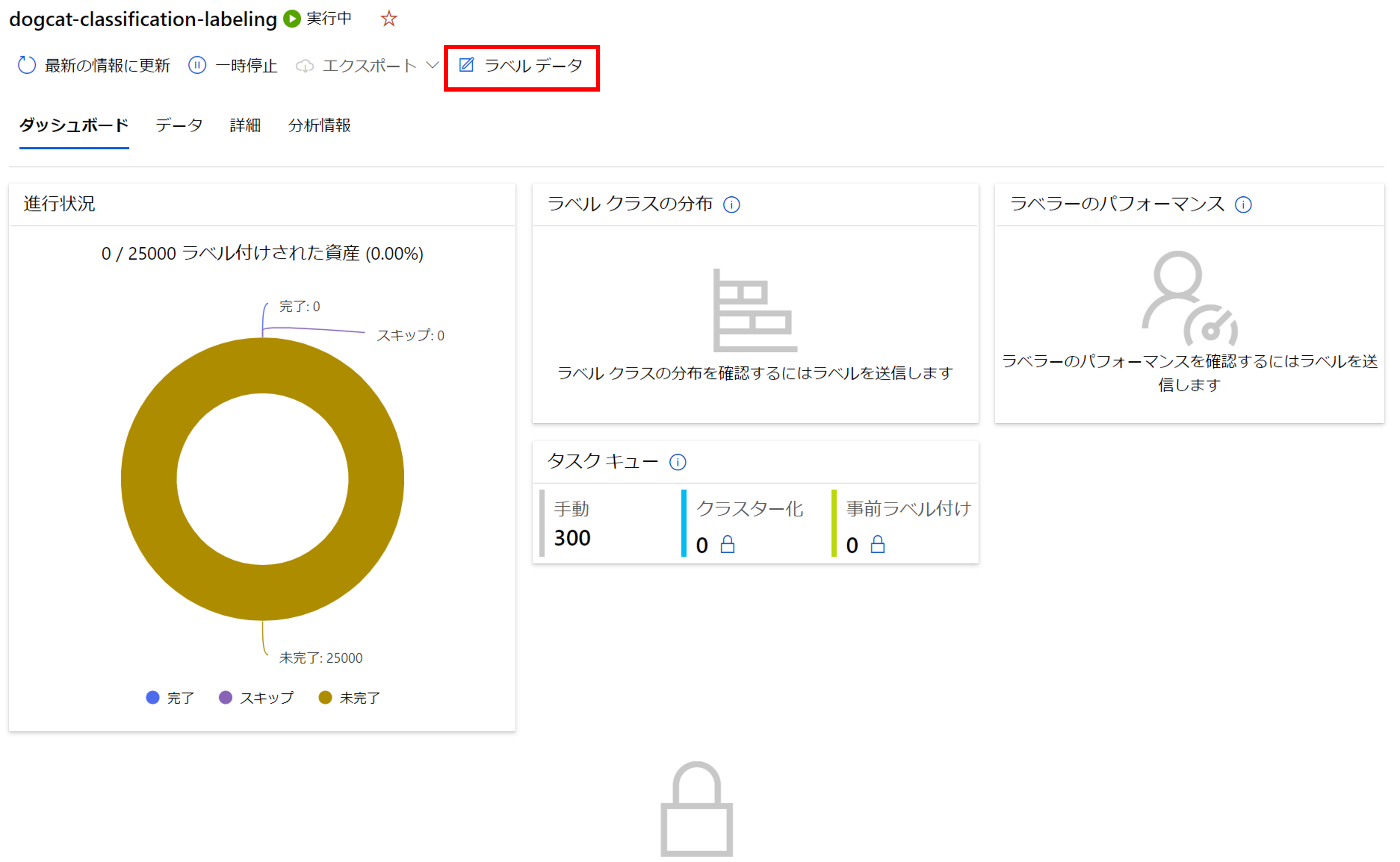
1枚1枚画像を見て、犬か猫かのラベルを付けていきます。マウスではやってられないのでショートカットを使いましょう。
犬の場合は「1」猫の場合は「2」を押して、「E」ボタンでラベルを送信します。
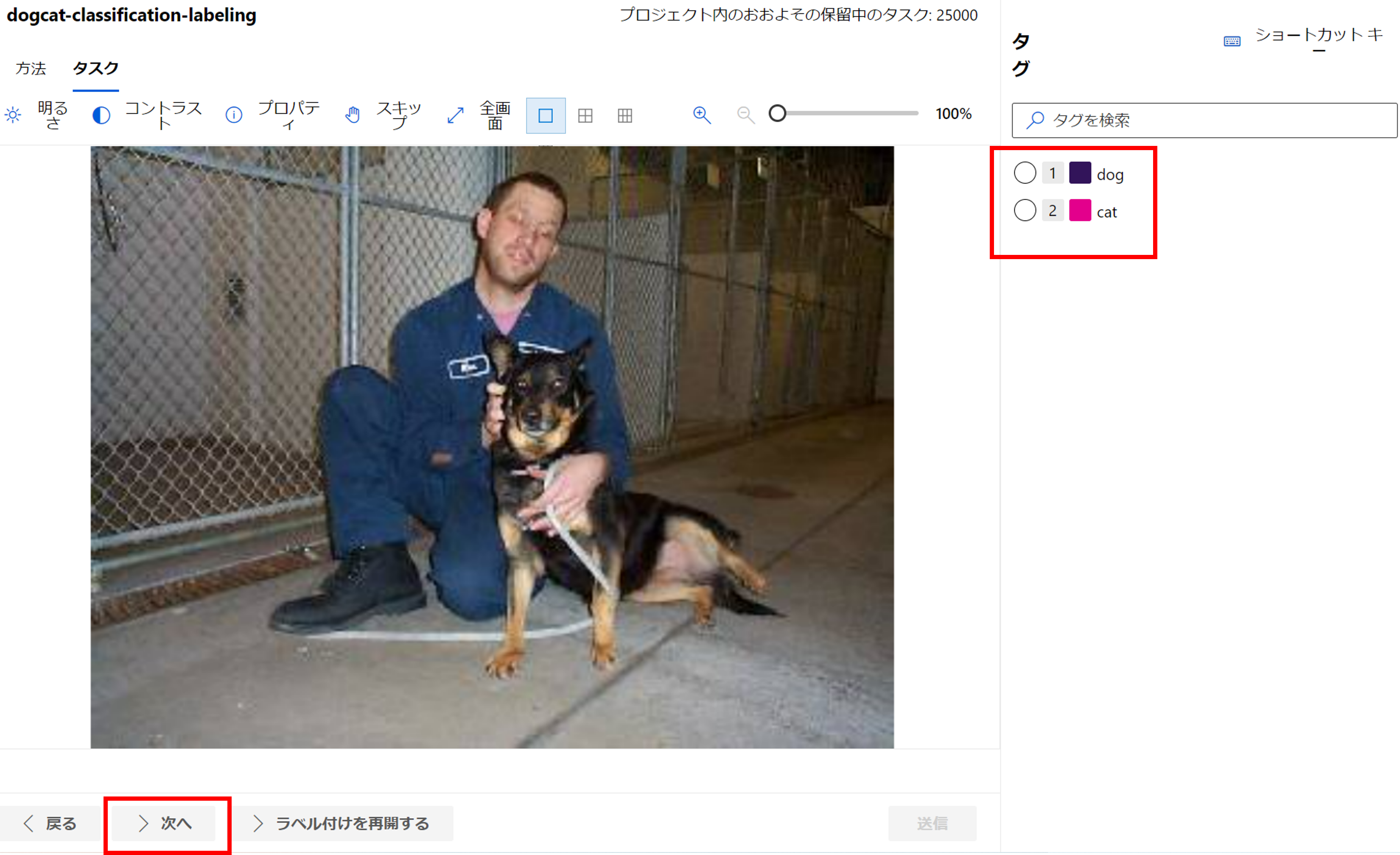
何とか200枚ほどラベルを付け終わりました。10分程とは言え、長く感じます。。
本当は最低1000枚くらい学習データが欲しいところですが、今回はこの200枚を学習データにしようと思います。
[エクスポート]->[Azure ML データセット]をクリックし、ラベリング結果をデータにエクスポートしましょう。
こちらのラベリング結果(JSONL)は[データ]に登録されます。
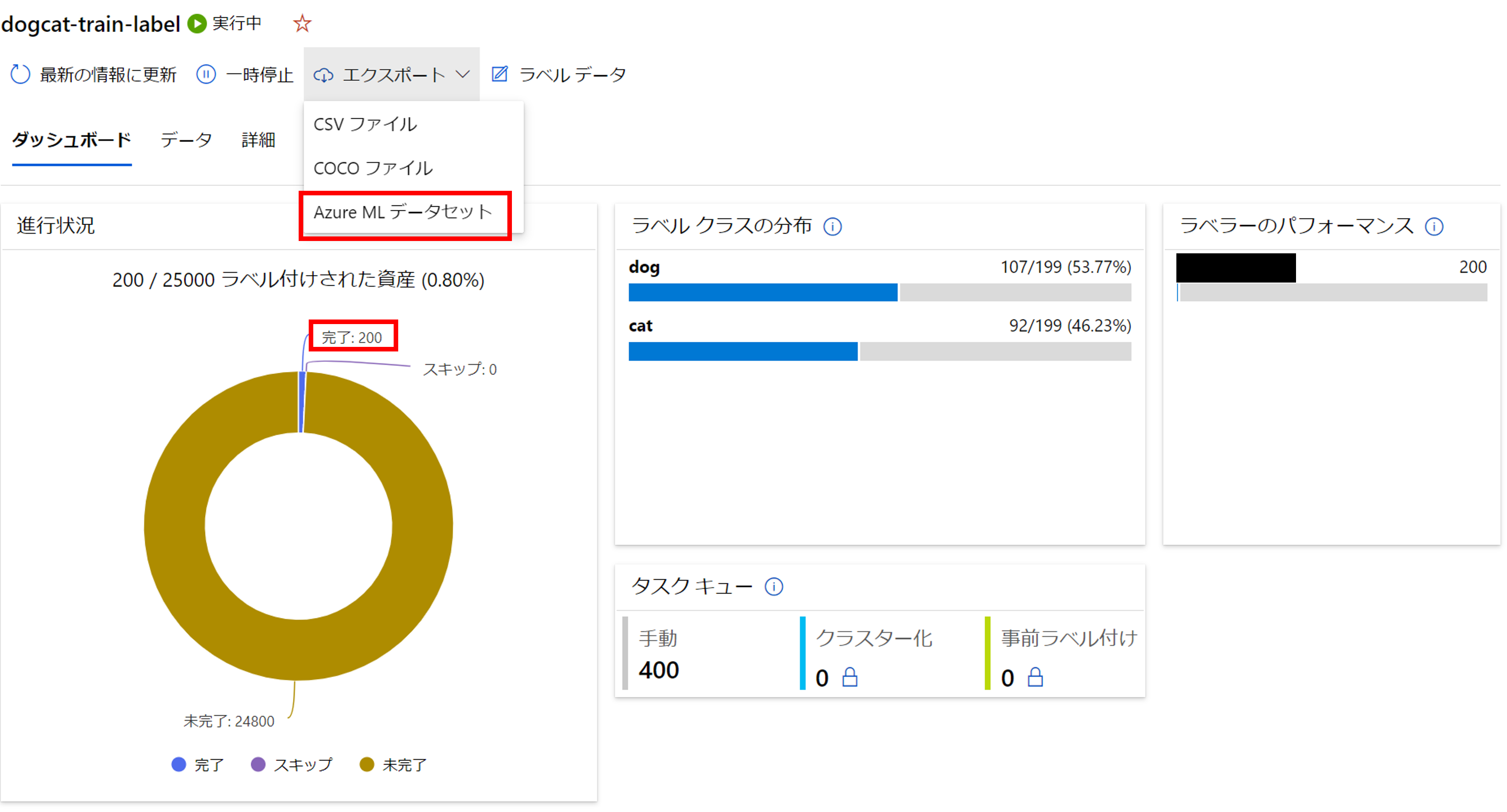
左メニュー[データ]からエクスポートされたラベリング結果が確認できます。
同じように検証用データもラベル付けを行いましょう。今回検証用データとして100枚ラベル付けを行いました。
モデルの学習
AutoMLのジョブ実行
左メニュー[自動 ML]->[新規の自動機械学習ジョブ]をクリックします。
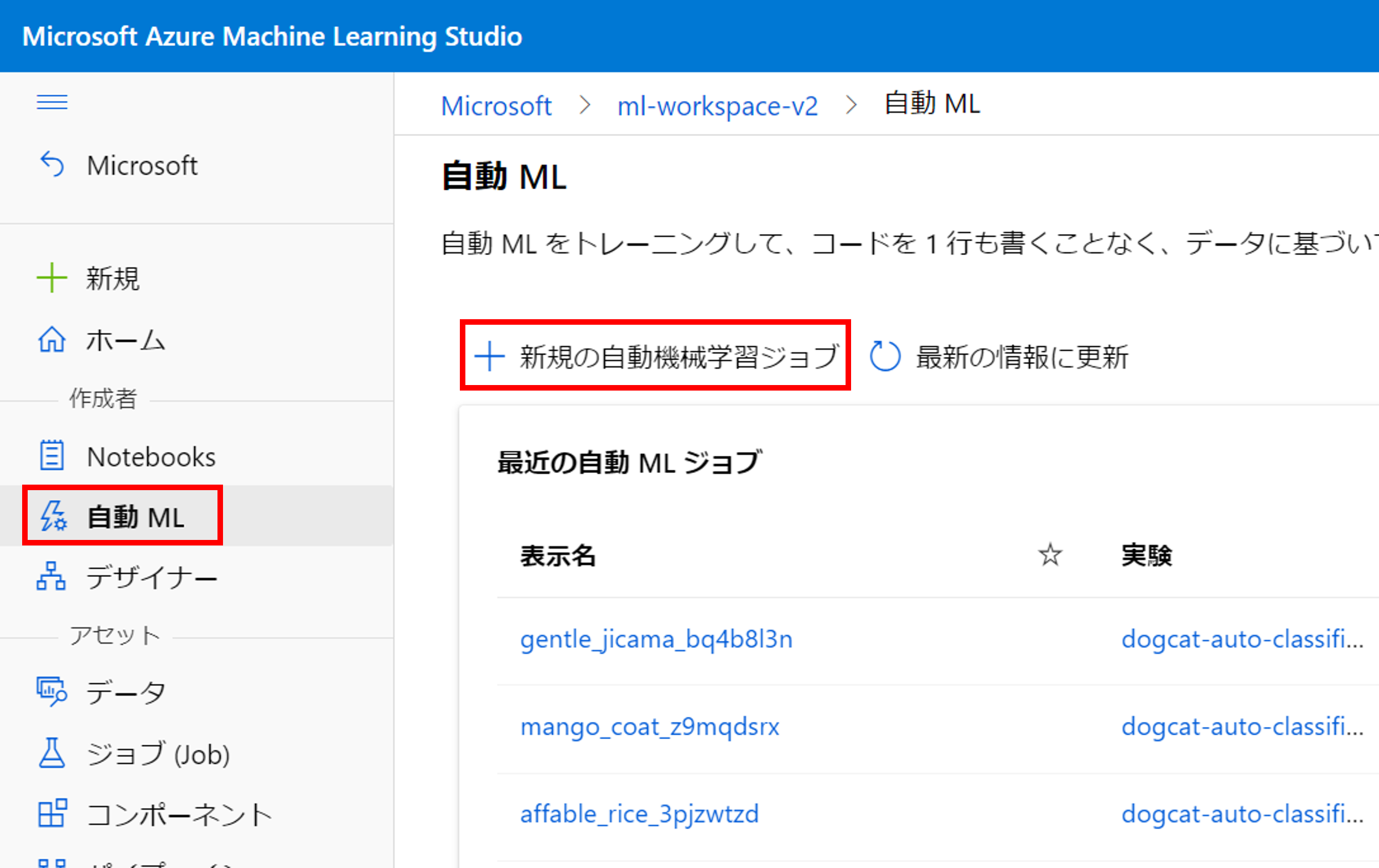
学習データは、先ほど作成したラベリング結果「dogcat-train-label_20220712_063957」を選択します。
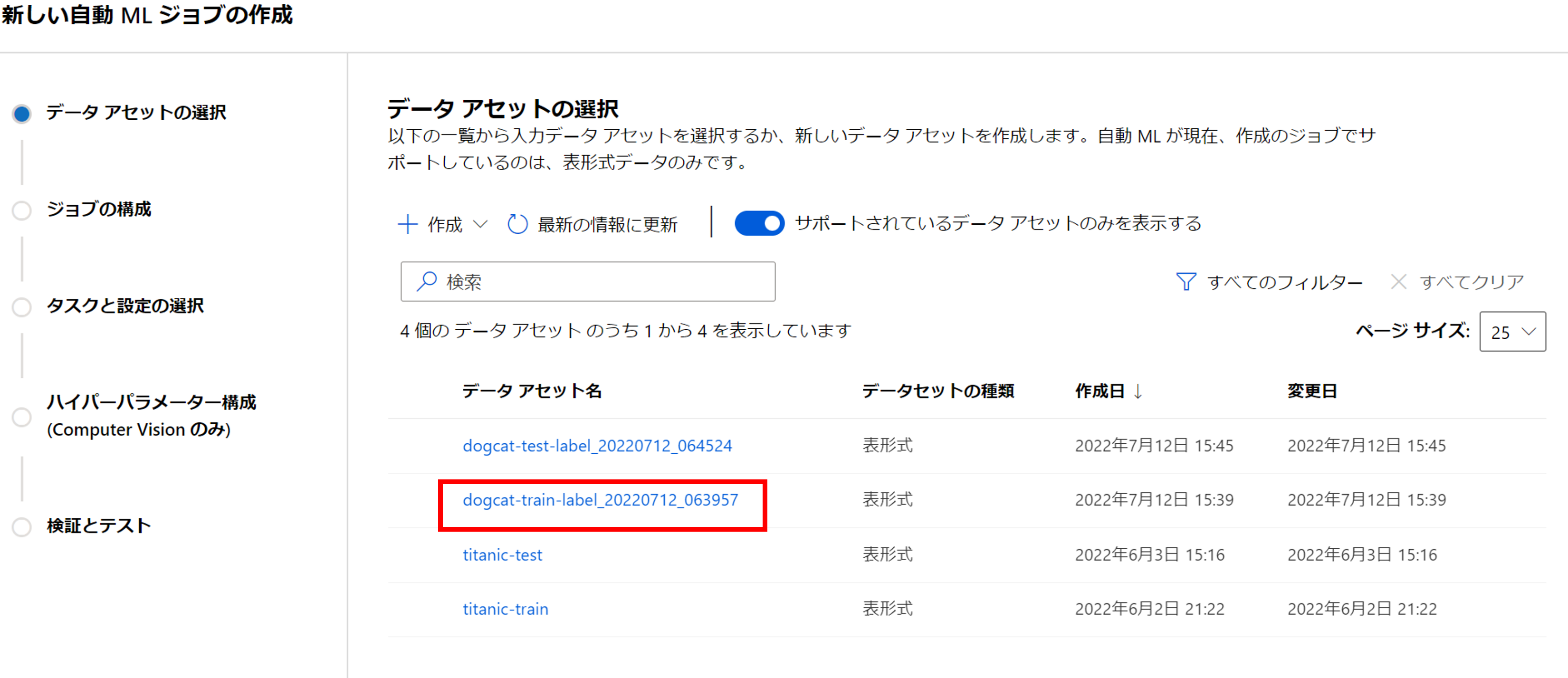
学習データを選択すると、自動的にタスクの種類は「画像分類(複数クラス)」と認識されます。
[新規作成]で実験名を入力し、ターゲット列は「label」を選択します。
コンピューティングは事前に作成してあるGPUクラスター「gpu-cluster-nc24」を選択します。
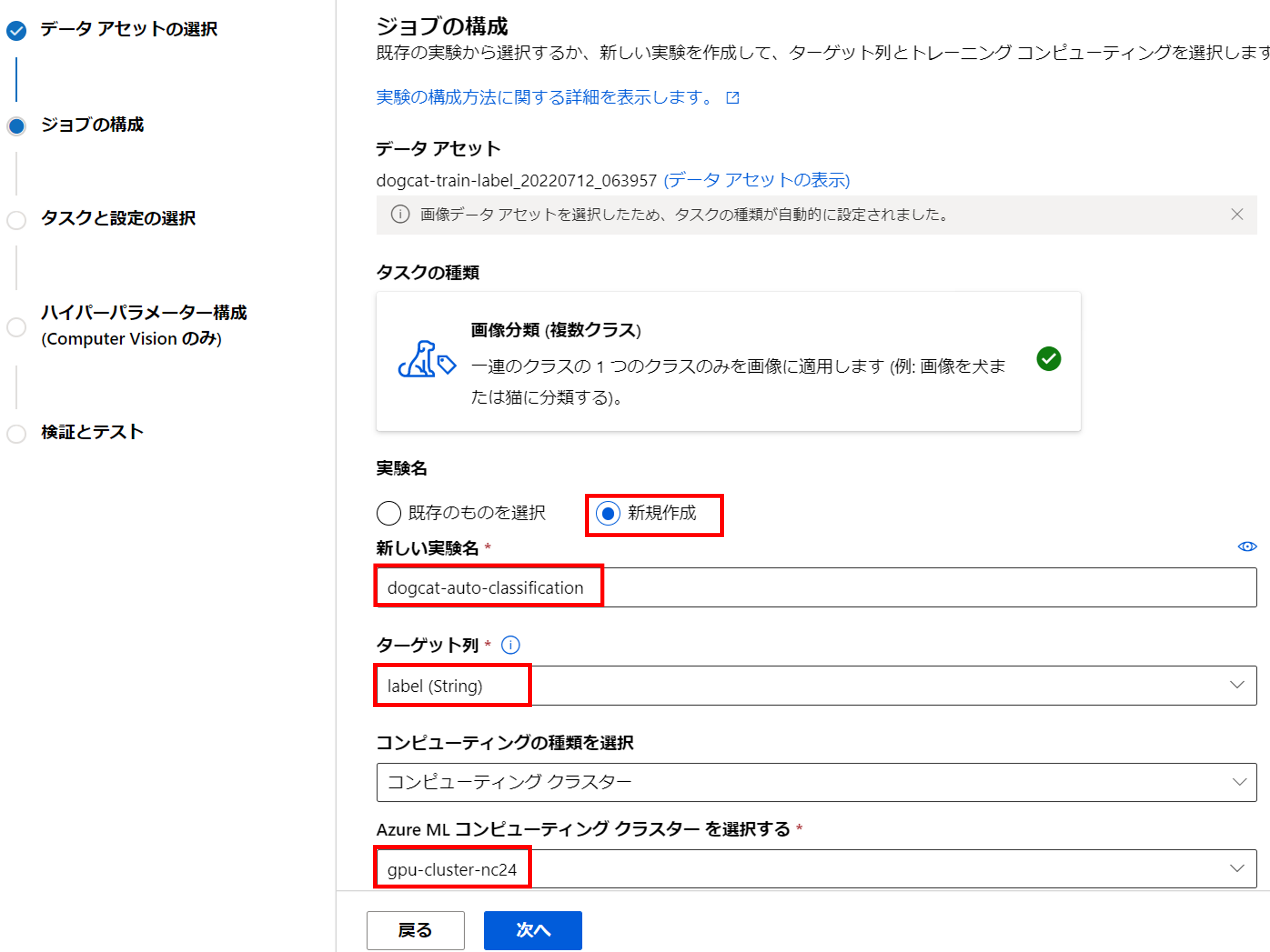
コンピューティングインスタンスの種類はNCファミリーかNDファミリーでないと怒られます。

これらのインスタンスが利用できない場合は、リージョンを変えて作成できないか確認しましょう。
次に、学習アルゴリズムの選択とハイパーパラメータチューニングです。
利用可能な学習アルゴリズムはこちら、調整可能なハイパーパラメータはこちらをご参照ください。
今回はモデルを「mobilenet2」にし、簡単なハイパーパラメータを追加していきましょう。
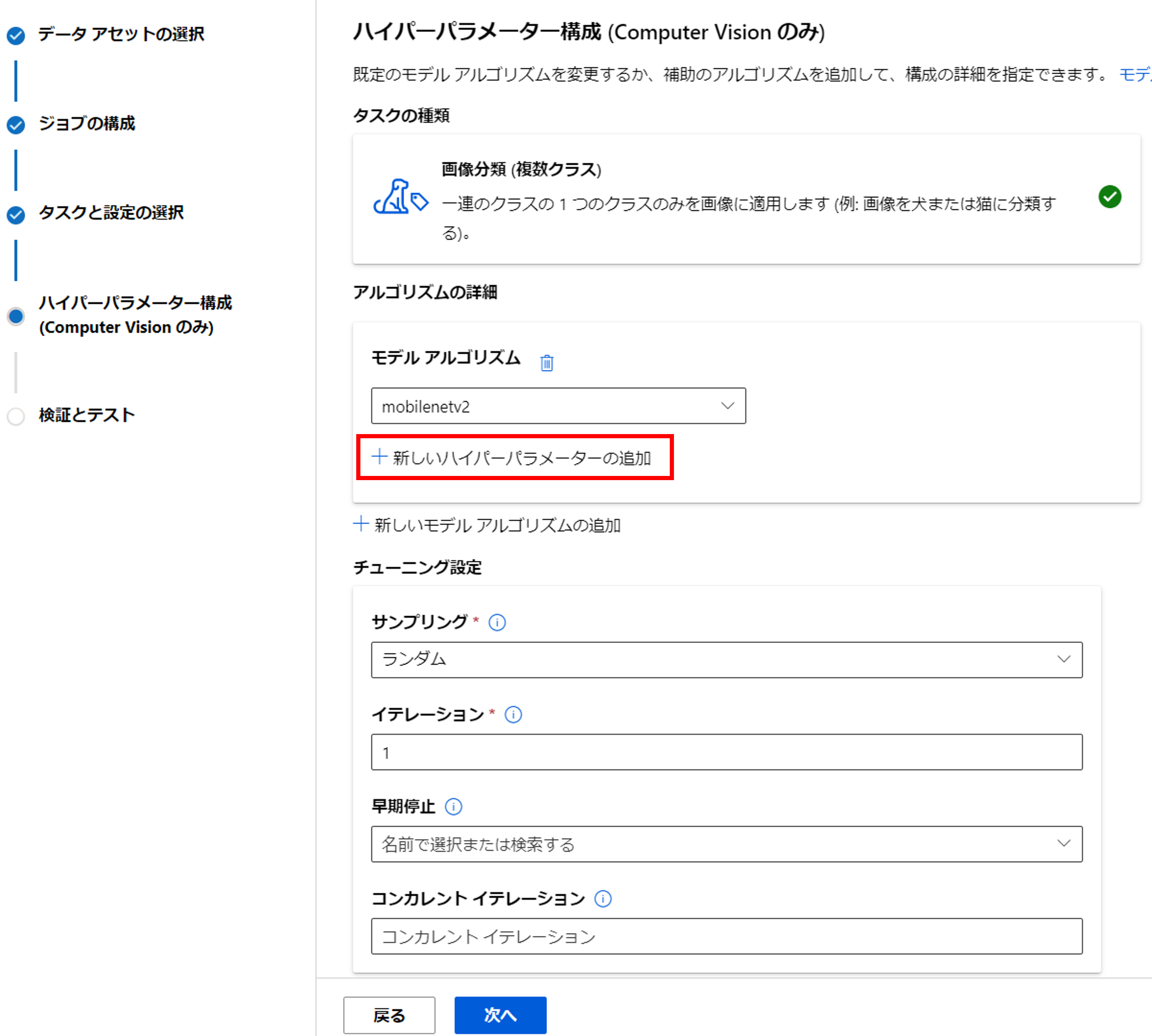
今回はトレーニングのバッチサイズを変更してみましょう。
[ハイパーパラメータ]に「training_batch_size」、[ディストリビューション]に「選択肢」、[値]に「16,32,64」を入力して、下の「保存」をクリックしましょう。

全体としては、下記の通りハイパーパラメータの設定を追加しました。
| パラメータ名 | 説明 | 値 |
|---|---|---|
| number_of_epochs | トレーニング エポックの数 | 100 (Default:15) |
| early_stopping | トレーニング中に早期停止ロジックを有効にします | 0 (Default:1) |
| training_batch_size | トレーニング バッチ サイズ | [16,32,64] (Default:15) |
ポイントとしては、デフォルトで早期停止が有効になっていているので、
学習曲線を見たい場合は早期停止を無効にし、エポック数を多めに取りましょう。
また、パラメータを追加する際、例えばエポック数を固定値で設定したい場合でも、ディストリビューションは「選択肢」を選びましょう。(「固定」を選択するとジョブ実行時エラーが発生しました。)
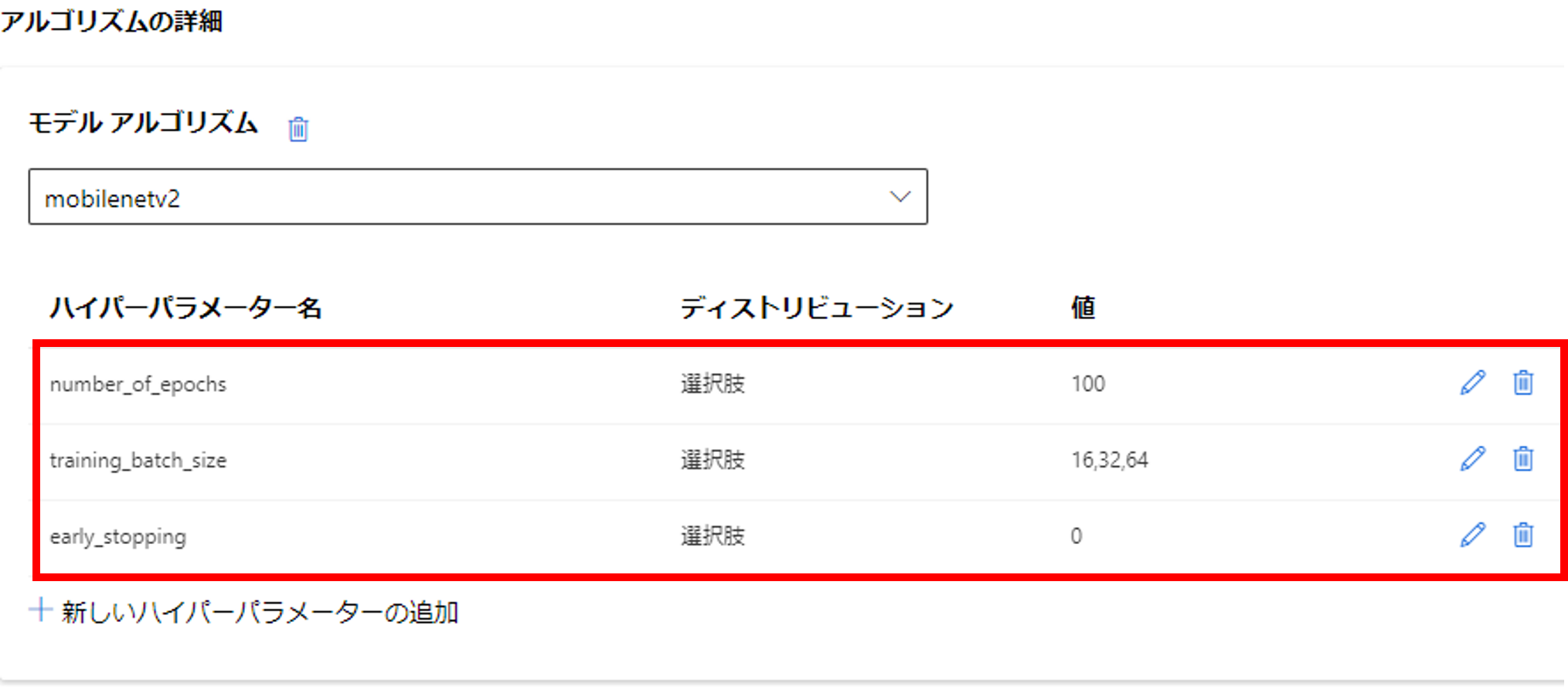
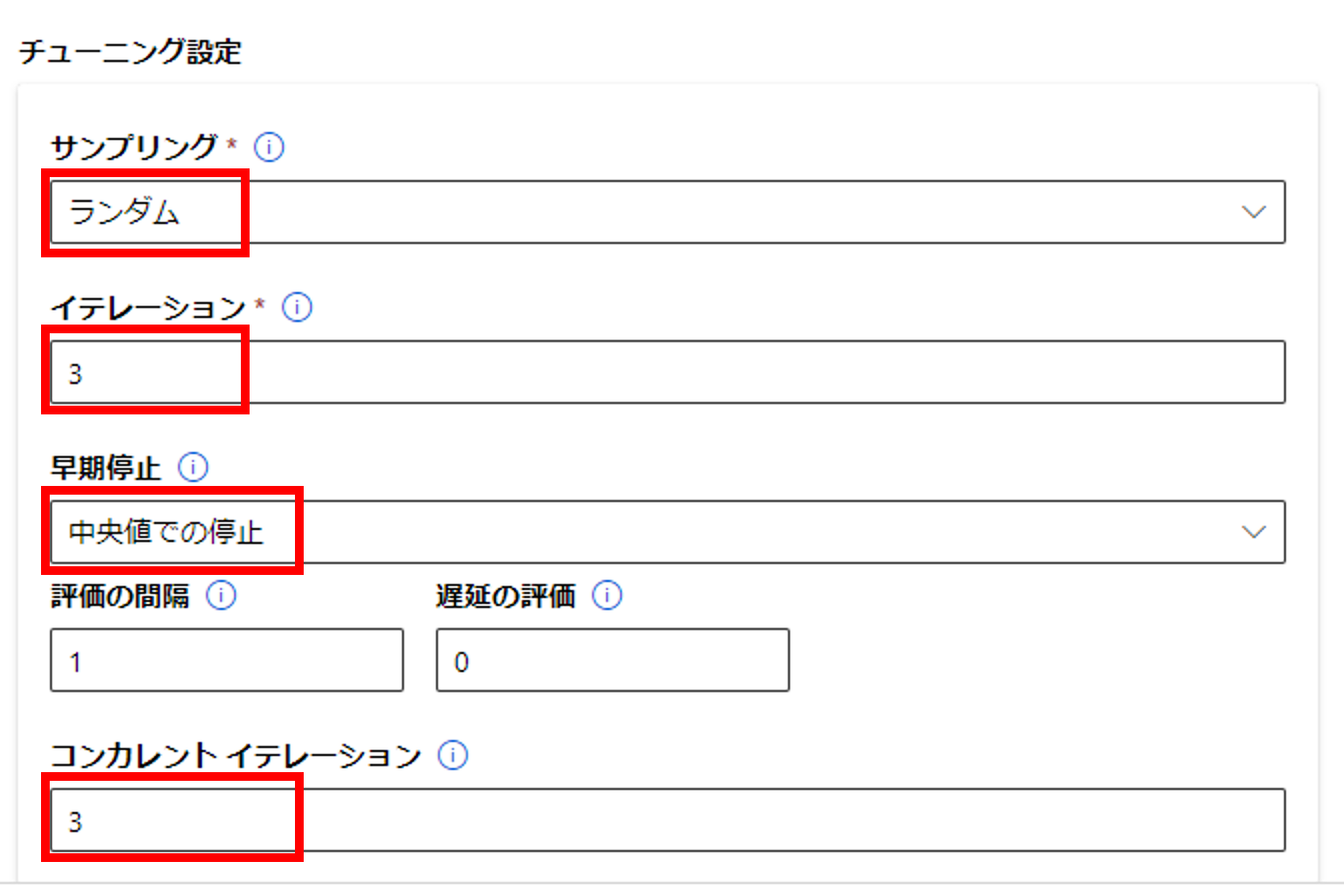
チューニングは下記の通り設定しました。
| パラメータ名 | 説明 | 値 |
|---|---|---|
| サンプリング | パラメータのサンプリング方法 | ランダム |
| イテレーション | パラメータ探索の最大実行数 | 3 |
| 早期停止 | 早期停止方法 | 中央値での停止 |
| コンカレントイテレーション | 同時実行の最大数 | 3 |
イテレーションがDefaultの「1」になっていると、ハイパーパラメータの組み合わせのうち1パターンしか実行してくれませんので、注意しましょう。その他、早期停止ポリシー等の説明はこちらに記載されています。
パラメータの「early_stopping」とチューニング設定の「早期停止」の違いについて
パラメータの「early_stopping」は、学習ジョブ内のエポックに対する早期停止の有無です。
チューニング設定の「早期停止」は、学習ジョブ間のジョブに対する早期停止ポリシーです。
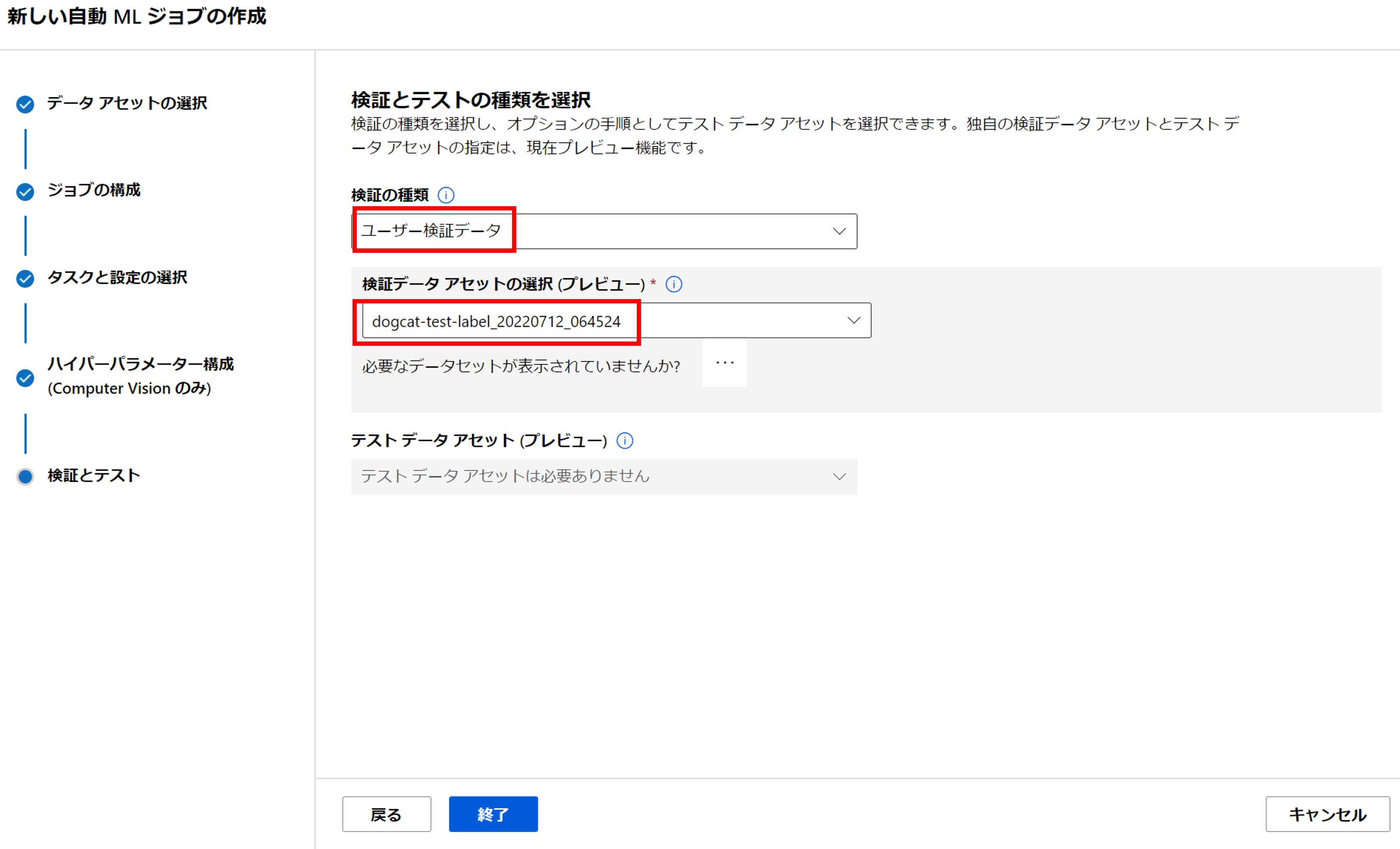
「次へ」をクリックすると、最後に検証の種類を選択します。[検証の種類]を「ユーザ検証データ」に設定し、先ほど作成した検証用データセットを指定しましょう。[終了]をクリックするとジョブが実行されます。
学習結果の確認
左メニュー[ジョブ]をクリックすると「dogcat-auto-classification」が登録されていますね。クリックしましょう。
こちらの画面では「dogcat-auto-classification」のジョブの一覧と各ジョブのベストプラクティスが確認できます。
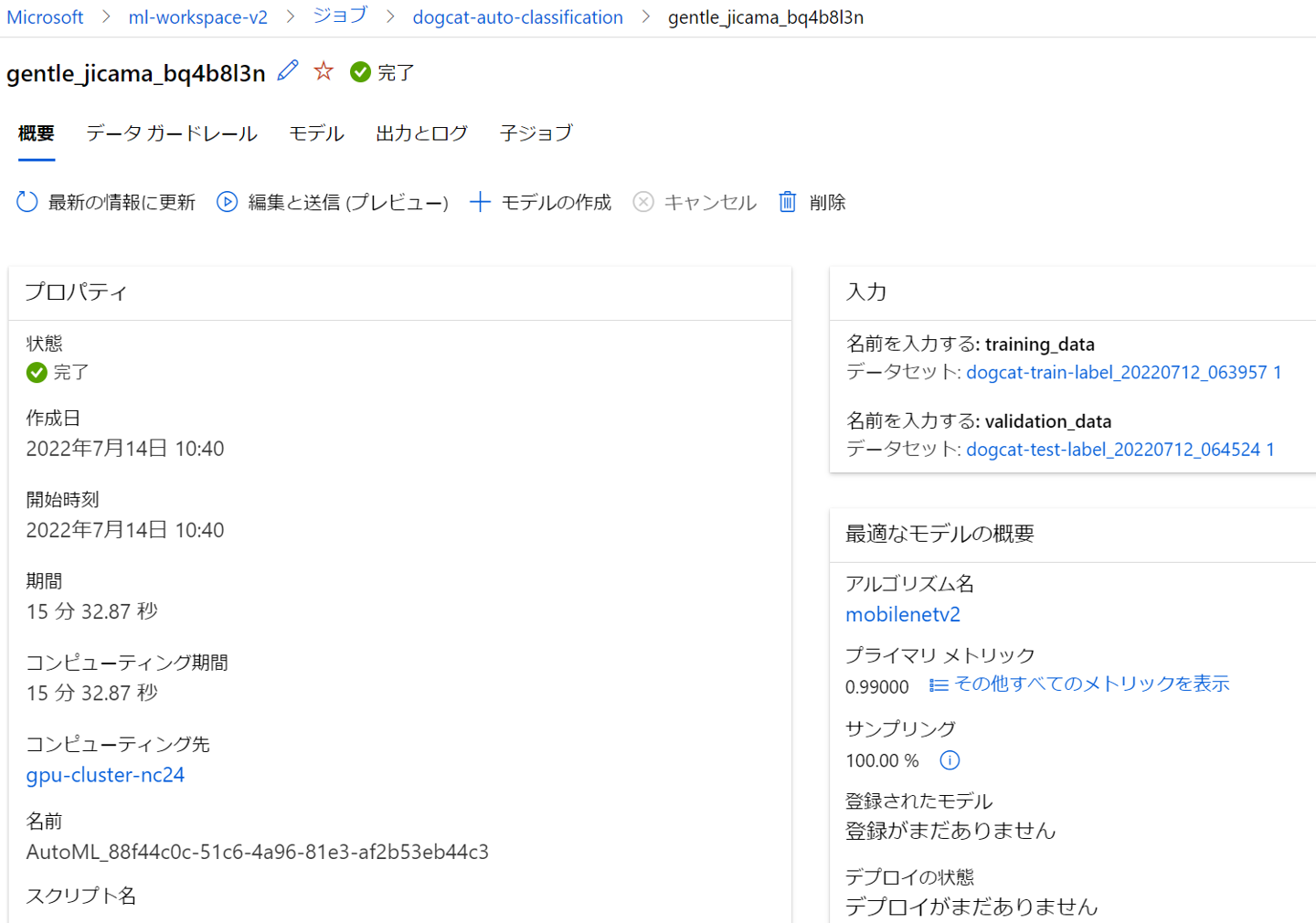
先ほど実行した一番上のジョブ「gentle_jicama_bq4b8l3n」をクリックしましょう。
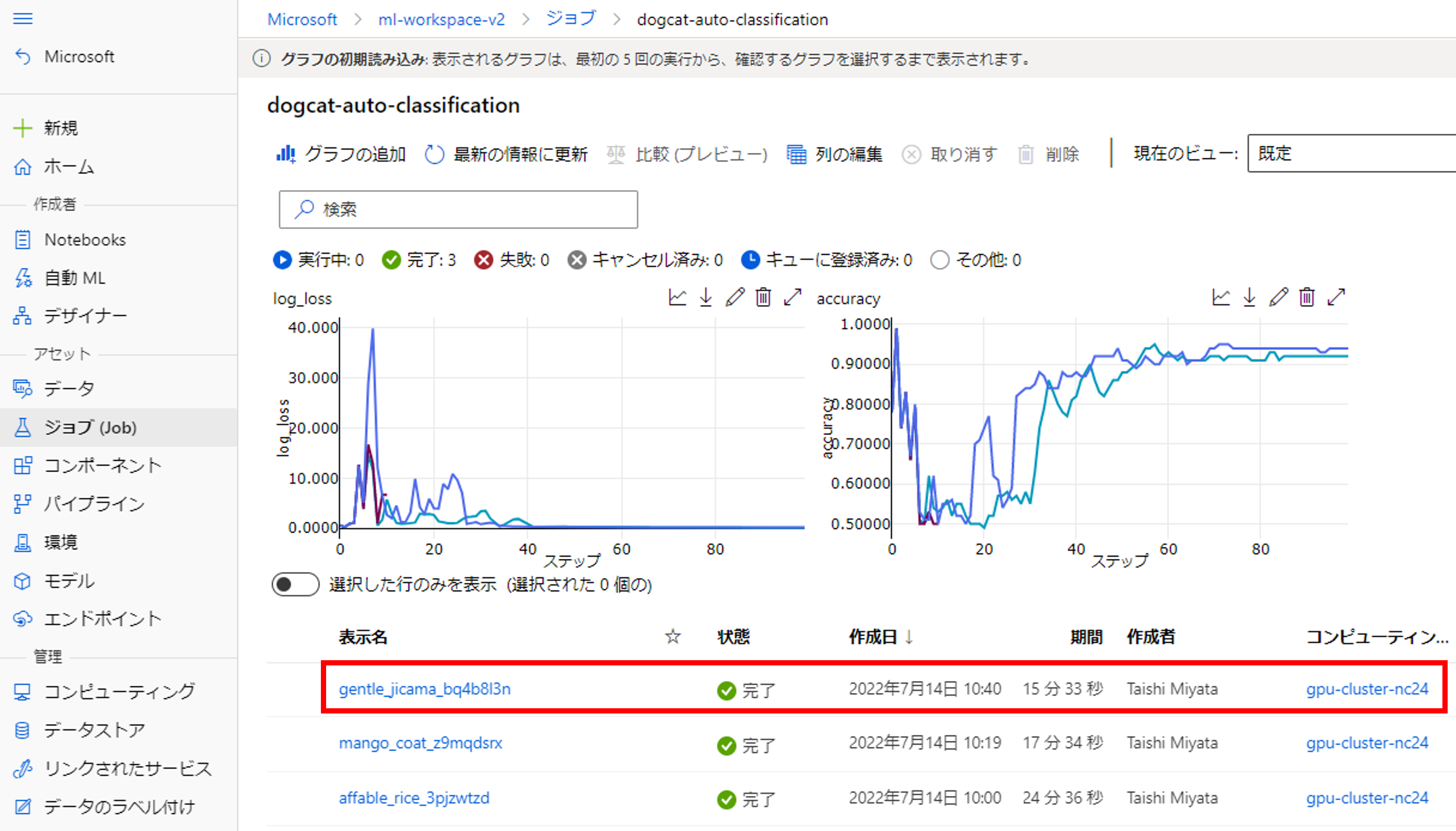
こちらから親ジョブの概要を確認できます。
子ジョブから各ハイパーパラメータの実行結果を確認することができます。
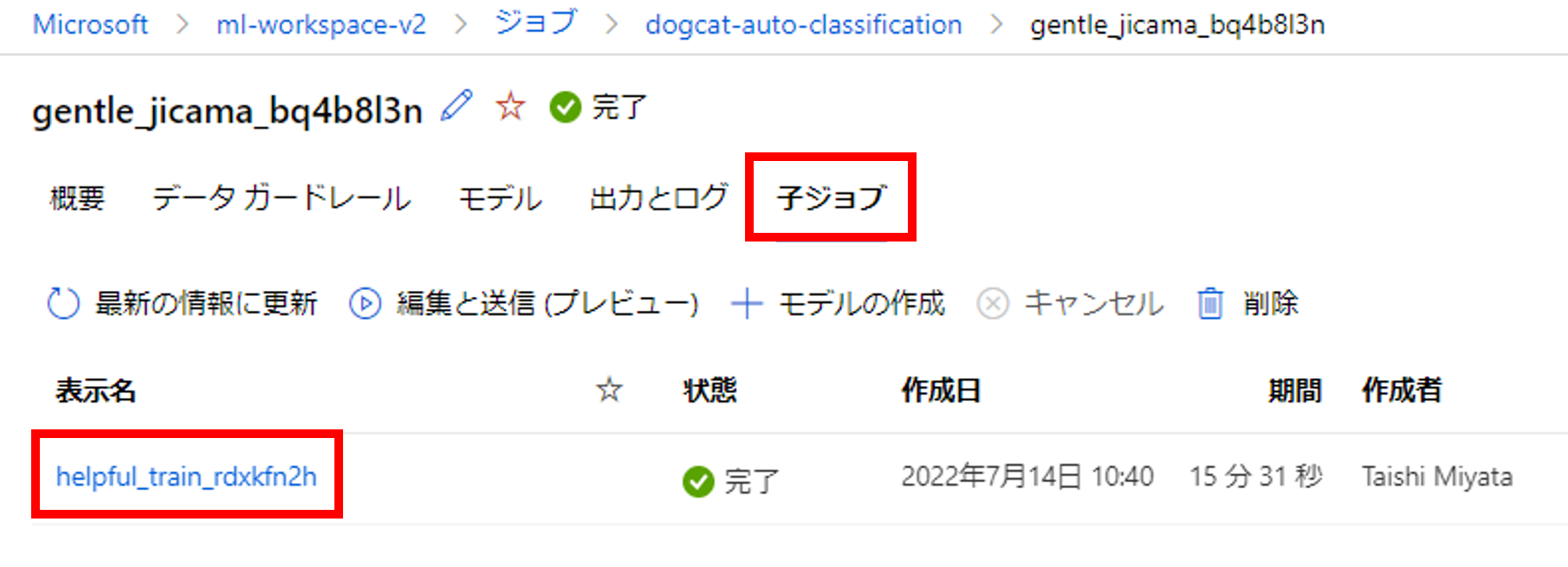
子ジョブの「試用版」をクリックしましょう。
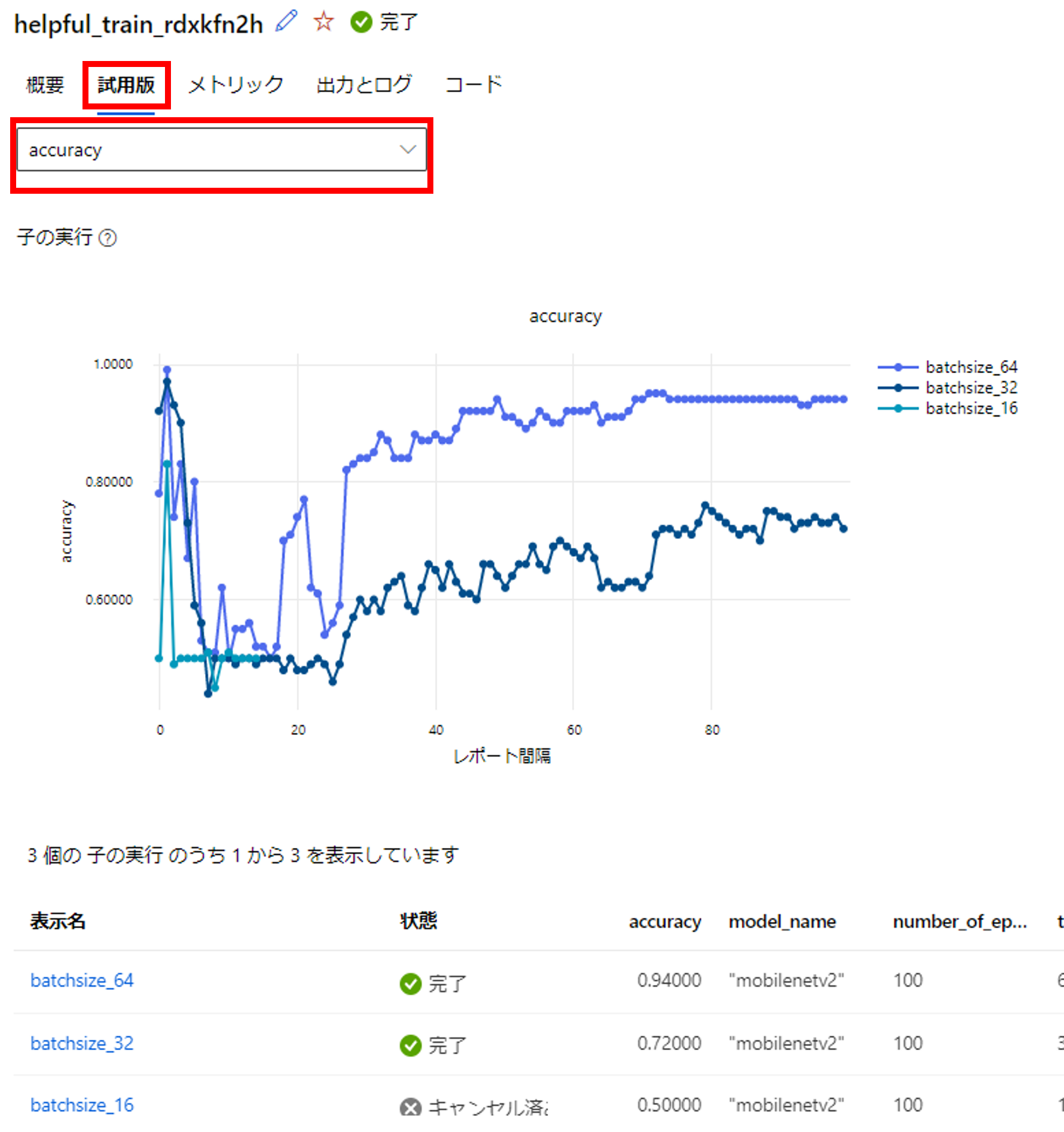
こちらの画面では各パラメータのaccuracyやlossを一覧で確認できます。
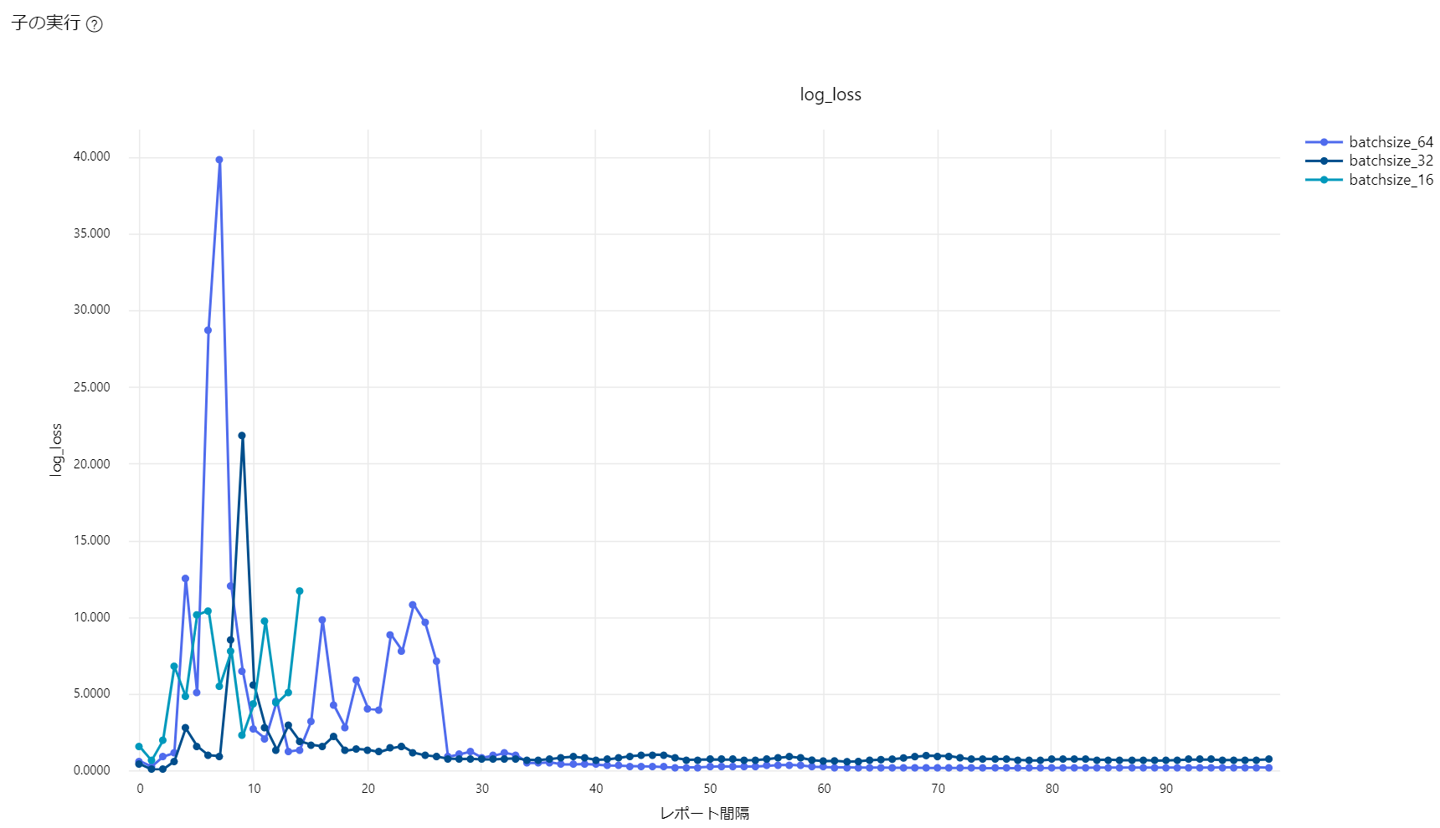
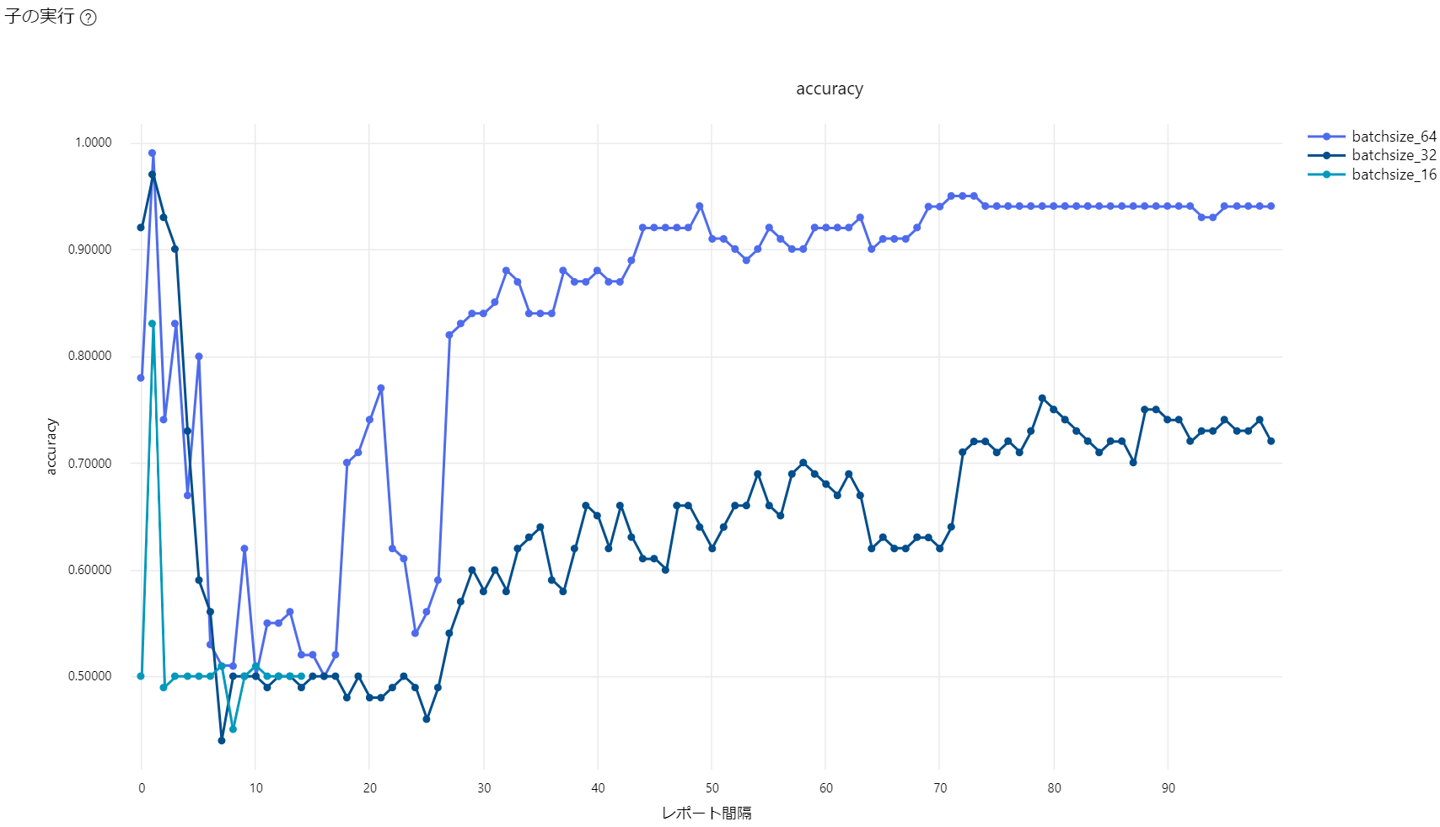
学習曲線
「log_loss」を選択すると、検証用データのロスを確認できます。
バッチサイズ32と64は収束していることが確認できます。バッチサイズ16は早期停止ポリシーが効いて、途中のエポックで終了しています。※子ジョブ名は変更しています。
精度
「accuracy」を選択すると、検証用データの精度(正解数/全データ)を確認できます。
初期値が良かったのか最初のエポックでは精度が高いです。その後下がって学習が進むにつれ精度が安定的に向上していることを確認できます。バッチサイズ64の精度が最も良いですね。
モデルのデプロイ
それでは「batchsize_64」のモデルをマネージドエンドポイントにデプロイしましょう。
先ほどの子ジョブから「batchsize_64」をクリックし、[デプロイ]->[リアルタイムエンドポイントへのデプロイ]をクリックします。
[エンドポイント名]を記入して、[次へ]をクリックします。
[次へ]をクリックします。
[次へ]をクリックします。
[次へ]をクリックします。
今回[インスタンス数]は「1」にして、[次へ]をクリックします。
[次へ]をクリックします。
[作成]をクリックします。
左メニュー[エンドポイント]から先ほど作成したエンドポイントが確認できます。
エンドポイントの新規作成時はDockerのイメージ作成等に時間が掛かり、10~15分程かかります。
作成が完了すると、プロビジョニングの状態が「成功」に変わります。
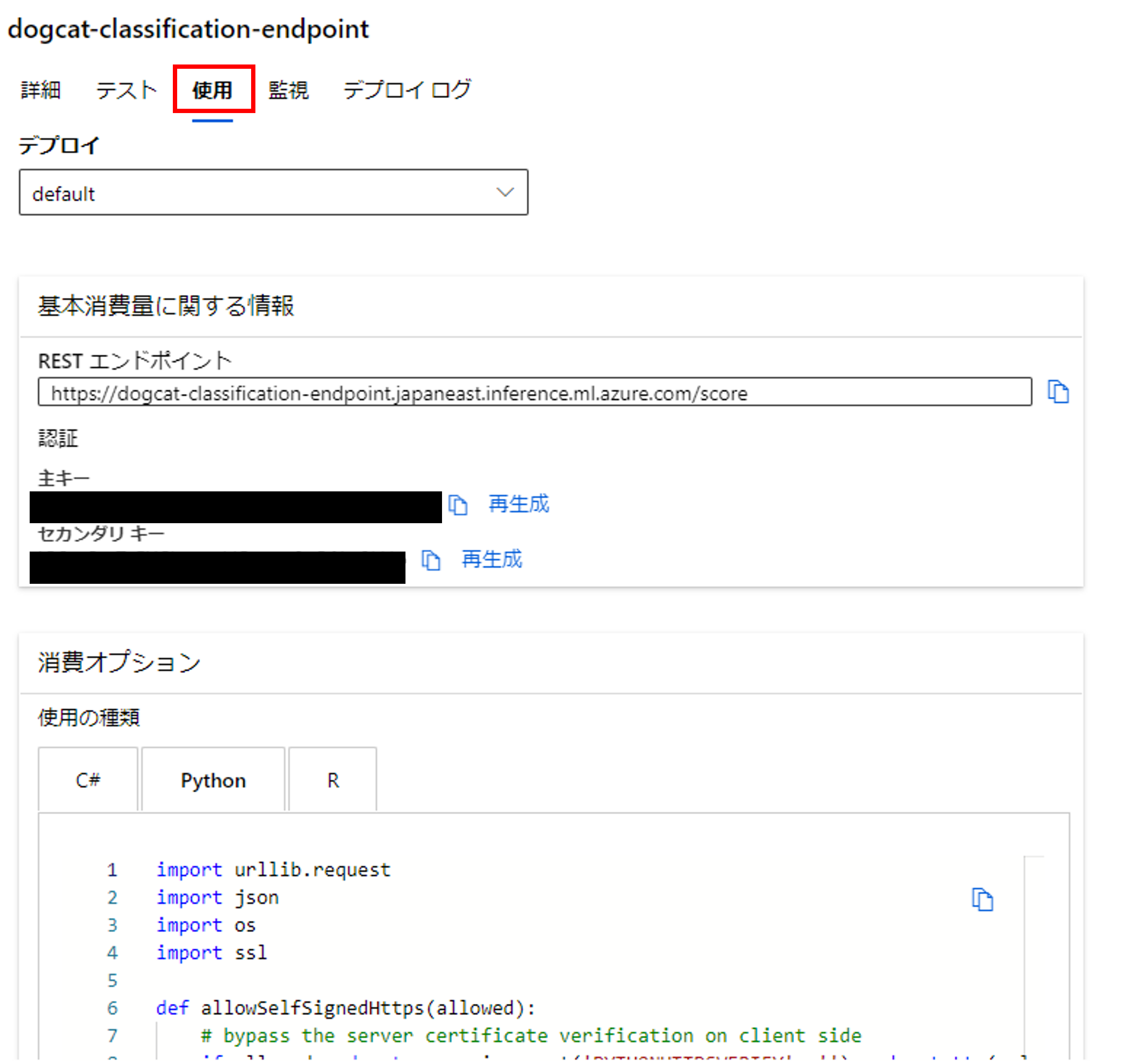
[使用]をクリックすると、エンドポイントの認証キーや使い方が確認できます。
今回はPythonでAPIで叩きたいので、コードをコピーします。
モデルの推論
最後に作成した推論エンドポイントに画像を送って、結果を確かめましょう。
import urllib.request
import json
import os
import ssl
sample_image = './cat.3.jpg'
with open(sample_image, 'rb') as f:
body = f.read()
url = 'https://dogcat-classification-endpoint.japaneast.inference.ml.azure.com/score'
api_key = 'XXXXXXXXXXXXXXXXXXXXXXXXXXX' # Replace this with the API key for the web service
headers = {'Content-Type':'application/octet-stream', 'Authorization':('Bearer '+ api_key), 'azureml-model-deployment': 'default' }
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
print(result)
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
print(error.info())
print(error.read().decode("utf8", 'ignore'))
cat.3.jpgの画像はこんな感じです。

b'{"filename": "/tmp/tmp_l6jwbuy/tmpe1_t5zb0", "probs": [0.7836150527000427, 0.2163849025964737], "labels": ["cat", "dog"]}\n'
各ラベルの確率が返ってきてきました!ちゃんと猫と認識されていますね。
まとめ
今回はAzrreのAutoMLの画像分類を解説しましたが、いかがでしたでしょうか?
まずは、基本的なモデルで手軽に画像分類を試してみたい、という方にはピッタリのサービスだと思います。
慣れてきたらモデルやパラメータチューニングを変えてみて、性能がどのように変わるか試してみると良いかもしれませんね!