Azure Machine LearningのAutoMLで時系列予測を試してみた~②モデル評価編~
本稿は「Azure Machine LearningのAutoMLで時系列予測を試してみた」の①モデル作成編に続く、②モデル評価編です。
前回の記事を見られてない方は是非ご一読いただければと思います。
Azure Machine LearningのAutoMLで時系列予測を試してみた~①モデル作成編~
前回はAutoMLで時系列モデルの学習ジョブをデプロイするところまで解説しました。
今回は時系列予測における重要な評価指標を、Azureポータルの画面上のどこを見ればいいのか、解説していきます。
学習モデルの選定
アセットの「ジョブ」からデプロイされた「bike-forcasting」の概要が確認できますので、クリックしてみましょう。
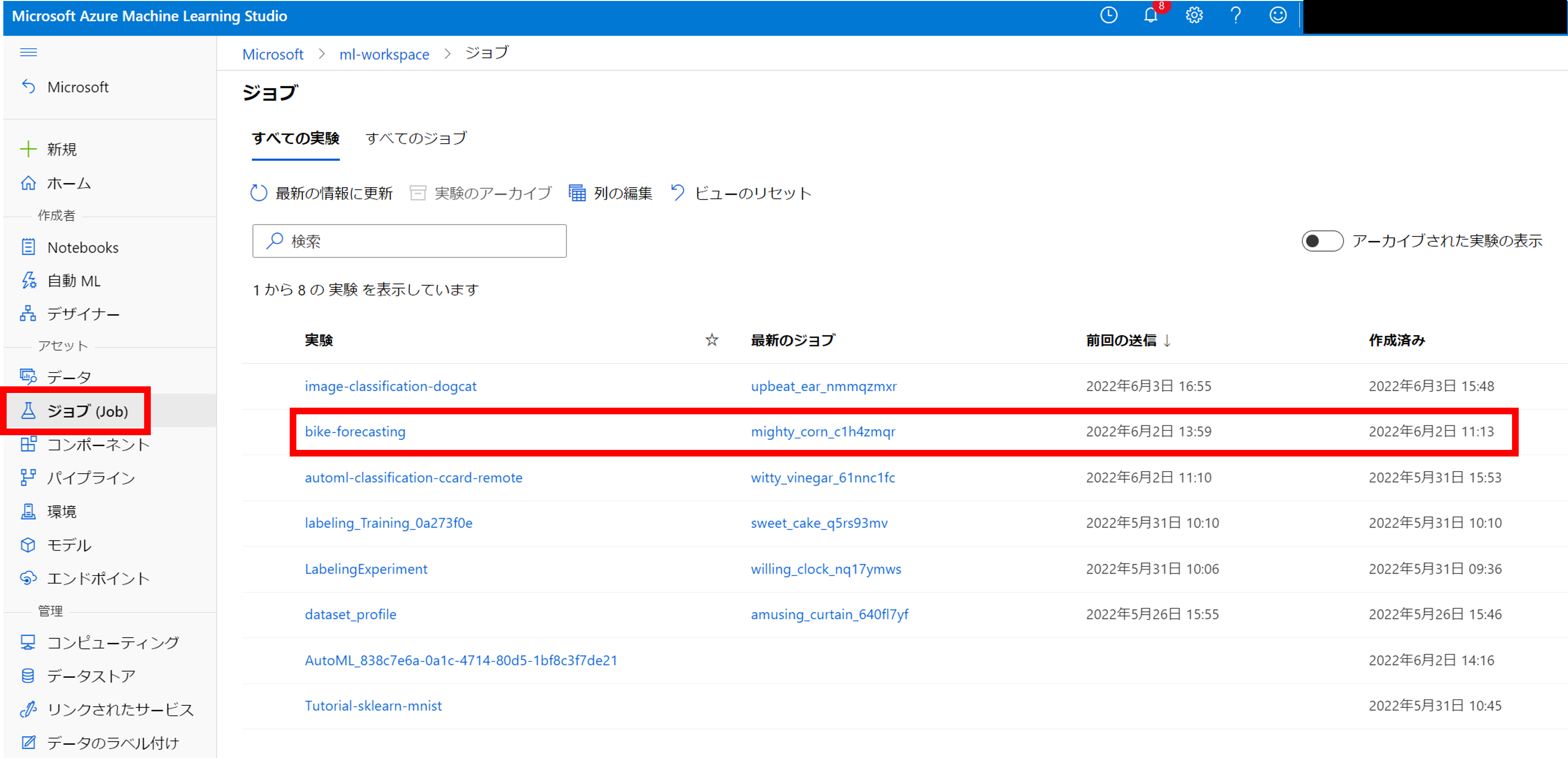
こちらのダッシュボードには、各親ジョブの実験結果が一覧で表示されます。
一番上のジョブが、前回のブログでデプロイした学習ジョブです。クリックしてみましょう。
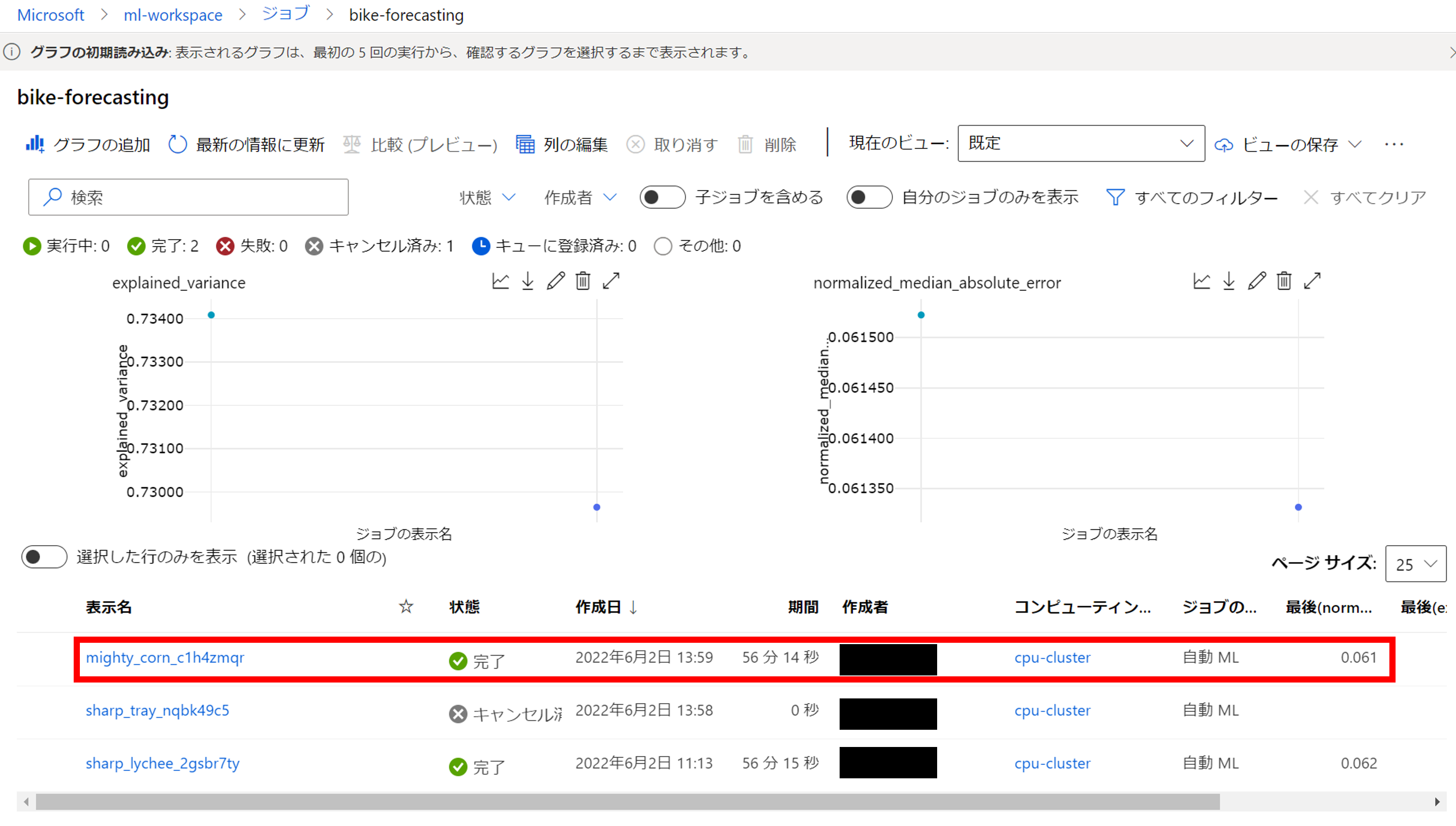
親ジョブ-> 概要
こちらの画面では下記を確認することができます。
- プロパティ:学習の実行時間やコンピュータリソース
- 入力:学習のデータセット
- 最適なモデルの概要:最も精度の良かったモデルのアルゴリズム・パラメータ・精度
- 実行の概要:学習条件
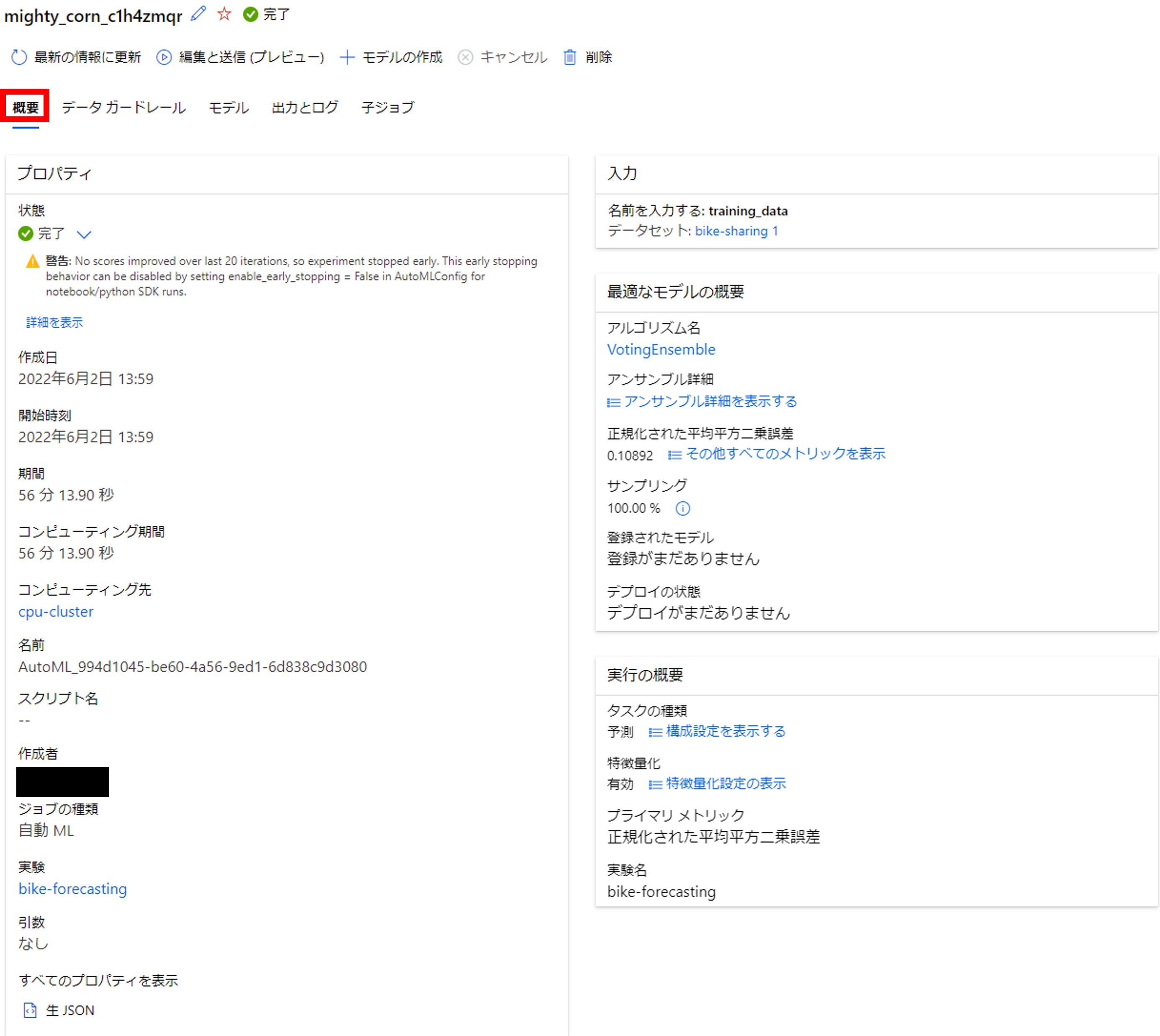
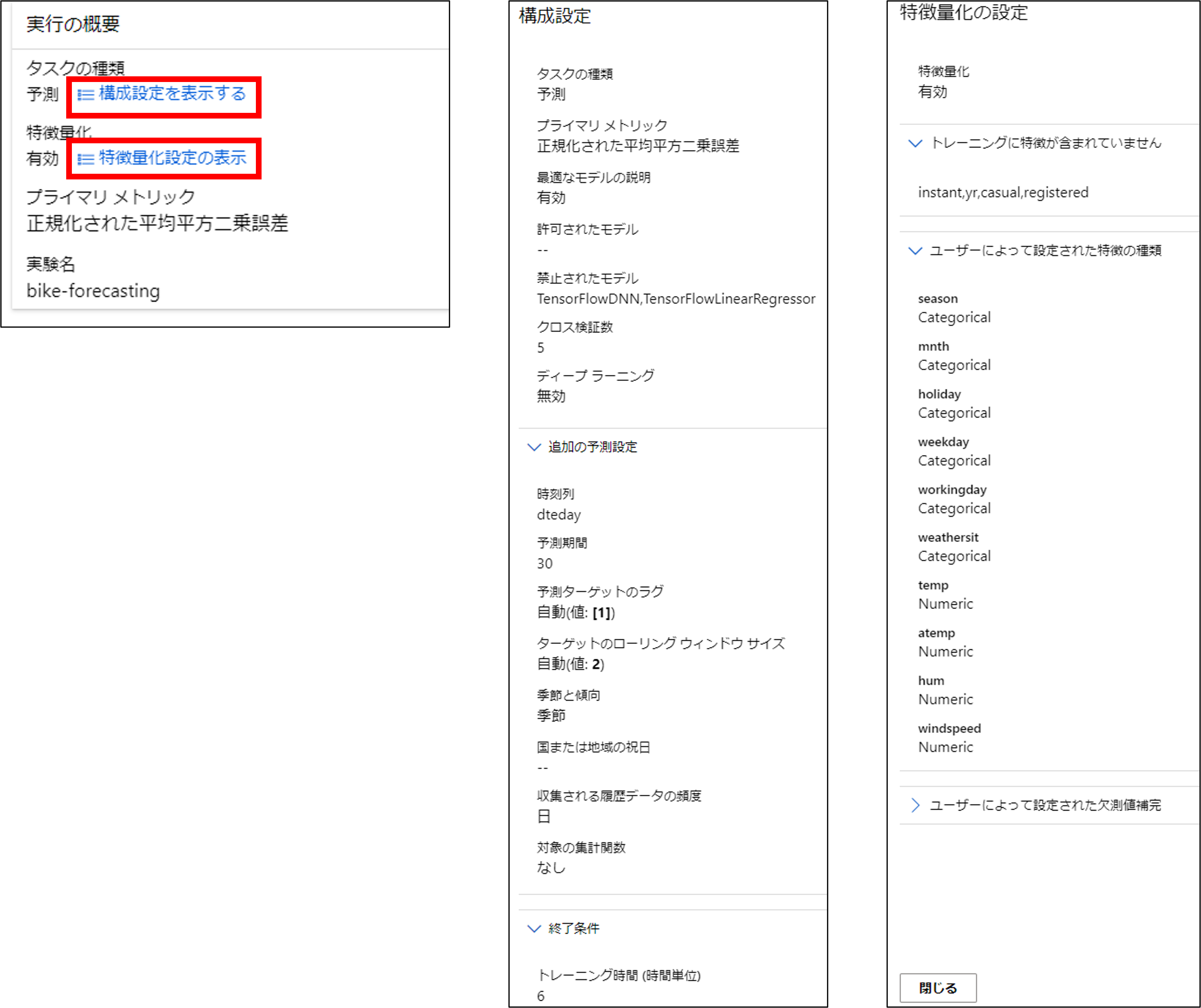
「実行の概要」では、学習ジョブを設定した際のパラメータが確認できます。
例えば、交差検証のクロス数、予測期間、どの特徴量を使ったか、等が確認できます。
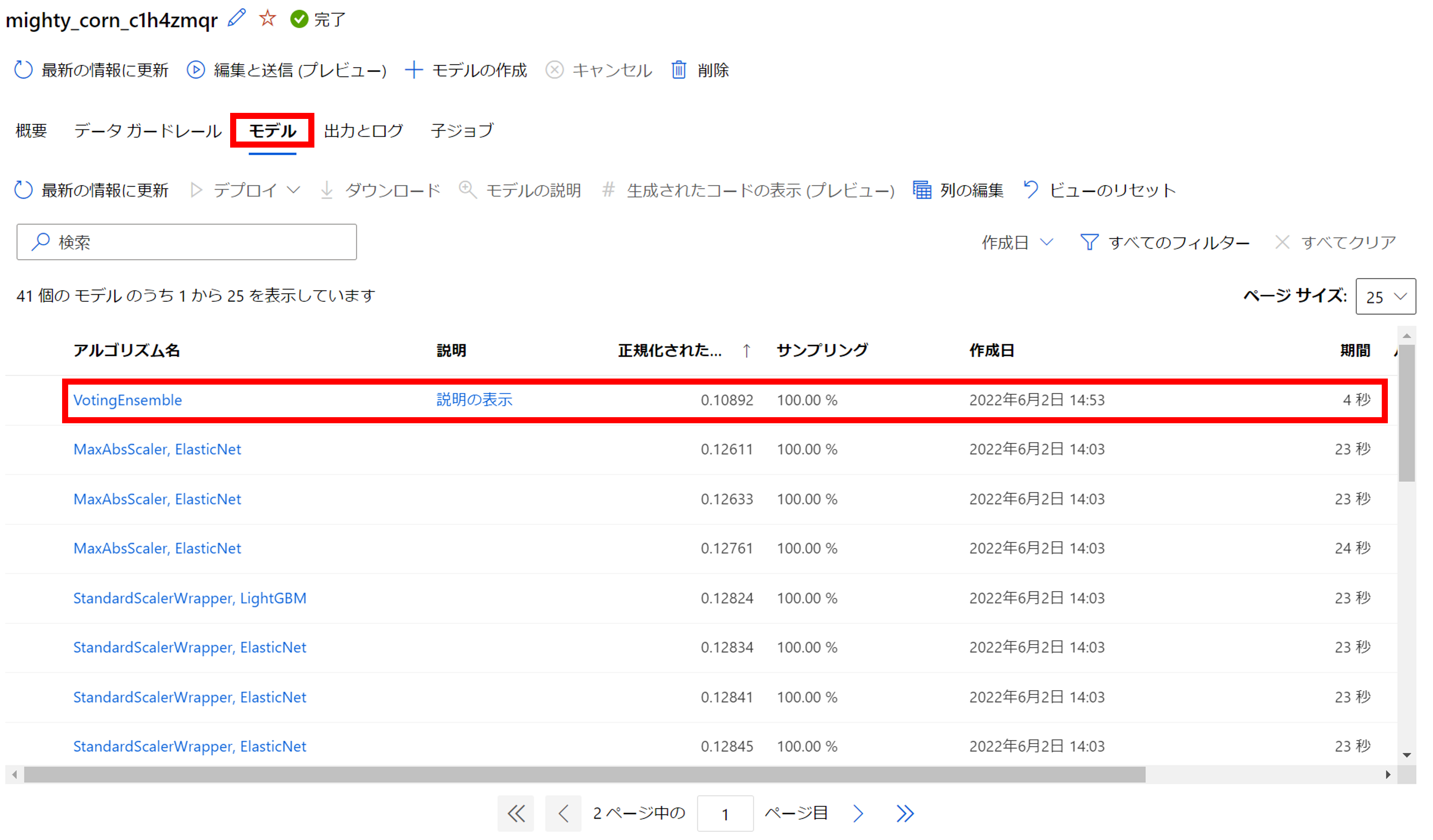
親ジョブ->モデル
次に「モデル」をクリックしましょう。
こちらの画面では、AutoMLで子ジョブとして実行された各アルゴリズムの実験結果が一覧で確認できます。
1番目に精度の良かったモデルは「VotingEnsemble」でした。こちらは複数アルゴリズムのアンサンブルモデルですね。
2番目は「MaxAbsScaler, ElasticNet」でした。前半の「MaxAbsScaler」は正規化手法、後半の「ElasticNet」はアルゴリズム名です。
2番目から4番目は同じモデルが並んでいますが、こちらはモデルのパラメータがそれぞれ違うことを意味します。
AutoMLのメリットは、このように複数のアルゴリズムでパラメータを振って各モデルの精度を比較し、精度を一覧で管理できるところです。
特にアンサンブルモデルはコーディングが慣れている人でも作るのが大変なので、ありがたいですね。
今回は1番精度の良かった「VotingEnsemble」をクリックしましょう。
学習モデルの評価
こちらの章ではジョブの中身と学習モデルの評価結果を見ていきます。
- ジョブの中身
- モデルのハイパーパラメータ
- 入力データの特徴量
- モデルの評価
- 予測誤差・決定係数・実績値vs予測値
- 予測結果の時系列プロット
- 特徴量の重要度(影響度)
モデルのハイパーパラメータ
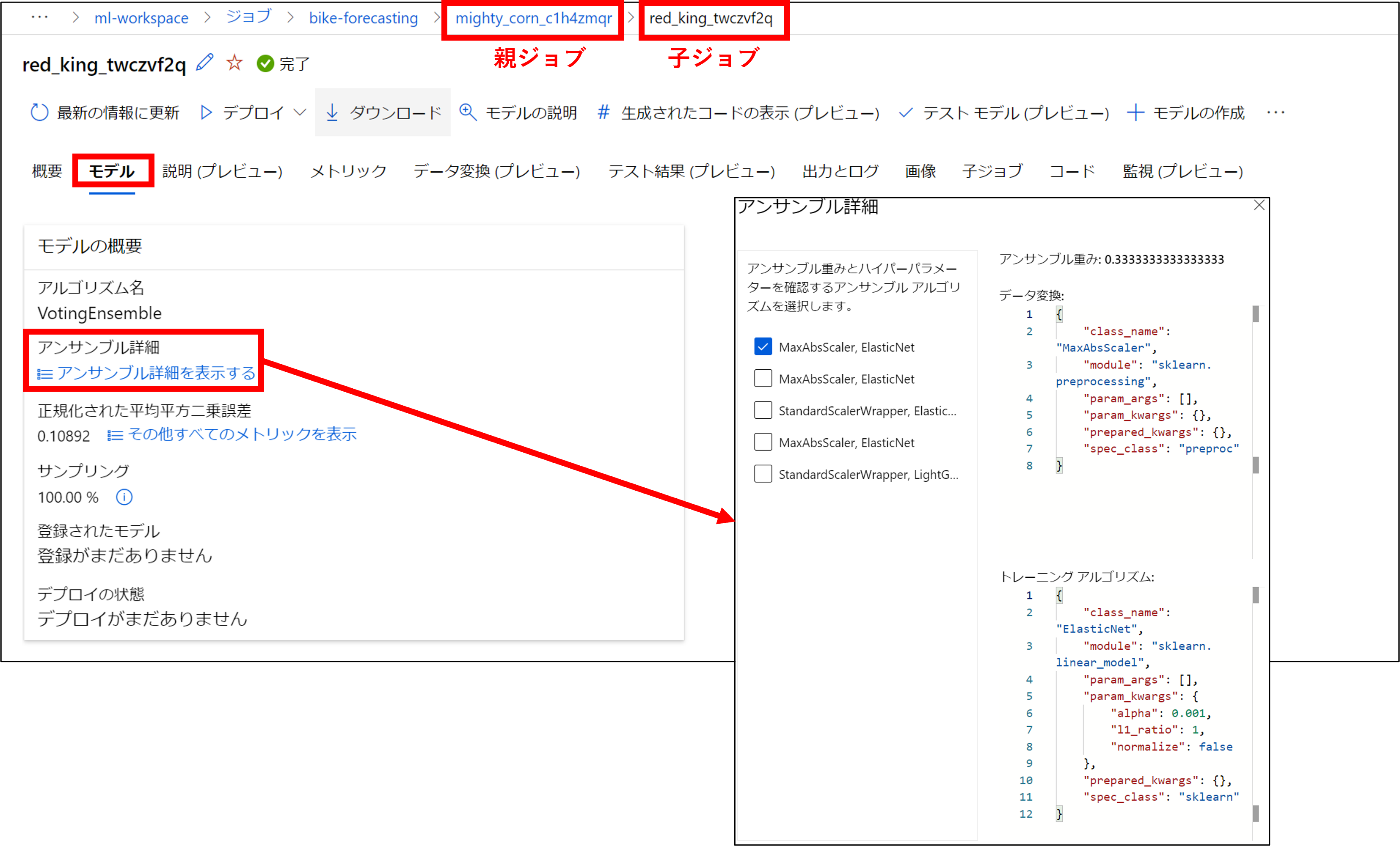
先ほどVotingEnsembleをクリックした画面で「モデル」をクリックしましょう。
こちらの画面ではモデルの概要を見ることができます。
「アンサンブル詳細を表示する」をクリックすると、アンサンブルの元アルゴリズムのパラメータやアルゴリズムの重みを確認することができます。
※アンサンブルモデルではない場合、同じ位置に表示される「ハイパーパラメータを表示する」からハイパーパラメータを確認できます。
入力データの特徴量
今回は自動化特徴量機能を使っていることもあり、どのような特徴量が生成されたか気になると思います。
こちらは少し分かりづらいのですが、「出力とログ」から「output -> engineered_feature_names.json」から確認することができます。
「automl_target_col***」から始まる特徴量は「目的変数」に関する特徴量であることを意味します。
- _automl_target_col_season:利用者数(cnt)の季節性
- _automl_target_col_col_lag1D:1日前の利用者数
- _automl_target_col_col_mean2D:1日前と2日前の利用者数の移動平均

予測誤差・決定係数・実績値vs予測値
学習の中身について把握できたので、モデルの評価を見ていきましょう。
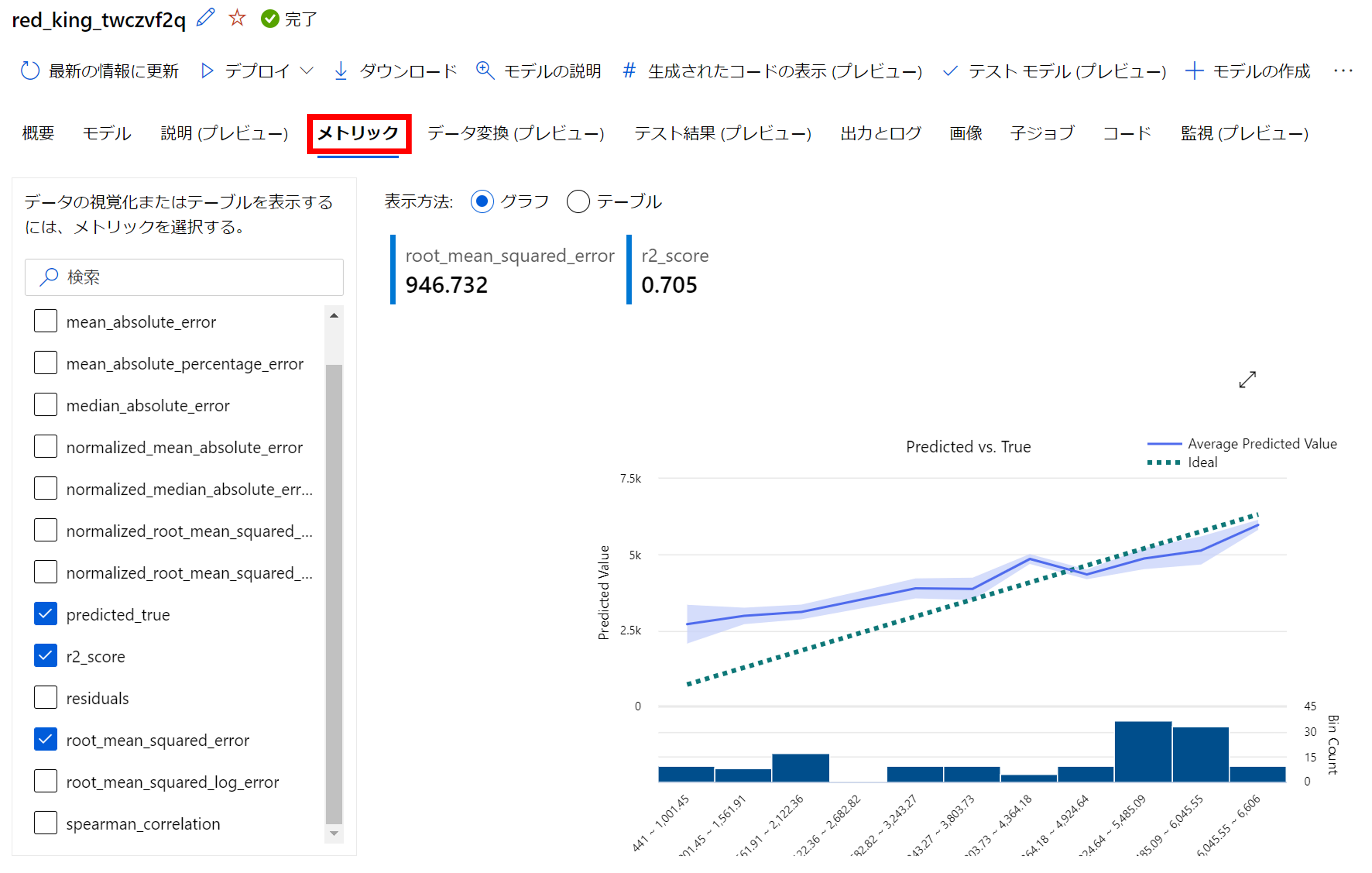
「メトリック」から学習モデルの様々な評価指標を見ることができます。
こちらの評価指標は、交差検証の各ホールドの平均値として算出されています。
「root_mean_squared_error(RMSE)」を見ると、誤差の標準偏差がおよそ「946」であることが分かります。もともとの利用者数が「平均±標準偏差=4504±1937」の正規分布に近い分布であったことを考えると、そこそこの精度で予測できているのではないでしょうか。決定係数は「0.705」ということで、説明変数で目的変数を十分説明できていることが分かります。
右下の画像は「実績値vs予測値」のグラフです。x軸が実績値、y軸が予測値です。点線が「実績値=予測値」のラインです。
このグラフを見る限り、利用者が多い日の予測精度は高いですが、利用者の少ない日の予測精度は若干悪いことが分かります。
予測結果の時系列プロット
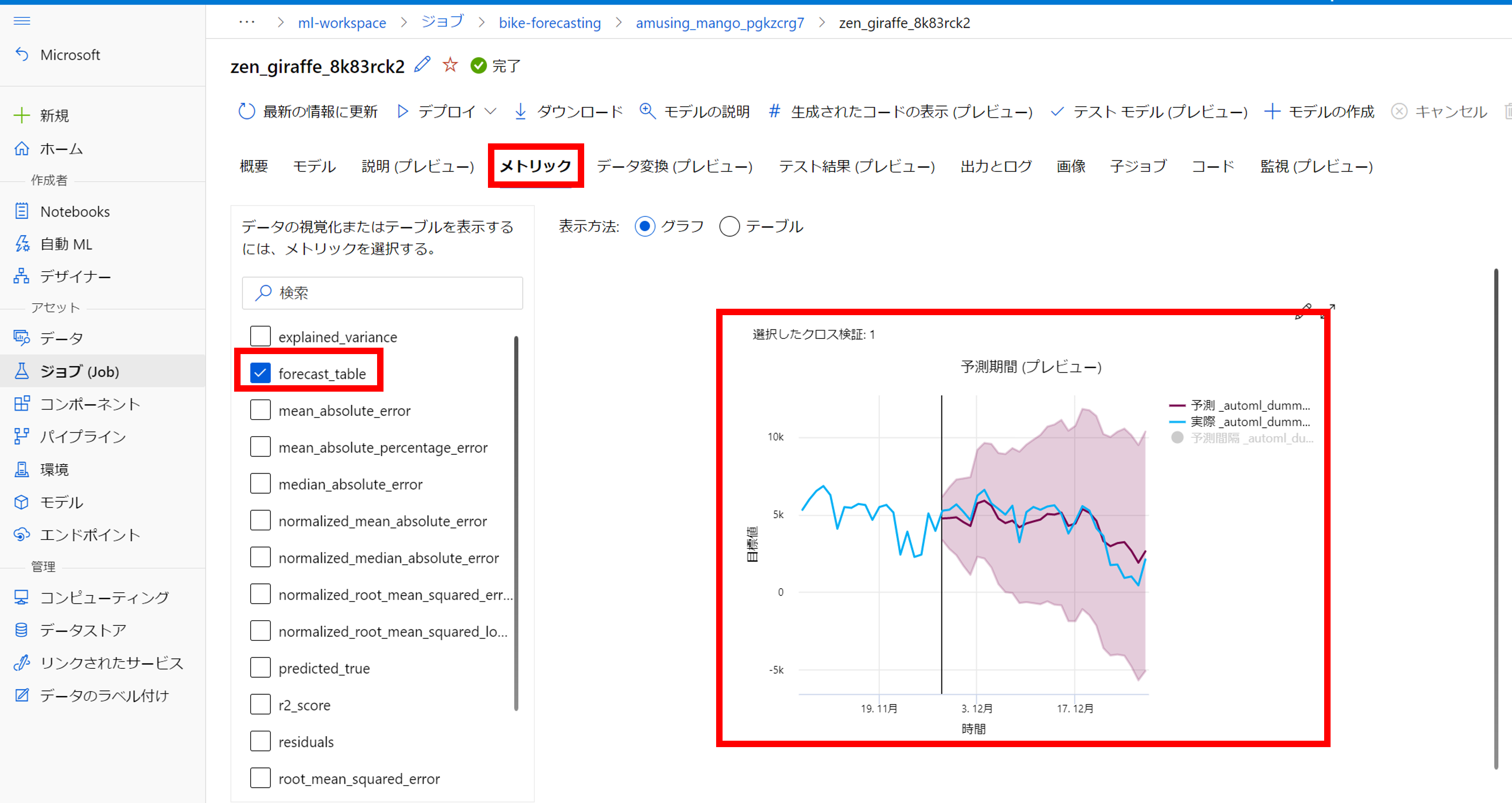
時系列予測の場合、予測結果の時系列プロットを見ていきましょう
「メトリック」->「foracast_table」をクリックすると、検証データの実績値・予測値を時系列で確認することができます。
12月末の利用者が少ないところの精度はいまいちですが、おおむねトレンドは予測できていることが確認できます。
(12月末はクリスマスやら年末イベントで利用者が少ない??)
※こちらの予測結果の時系列プロットは22年6月にプレビューされた機能です(この機能はありがたい...!!)
特徴量の重要度
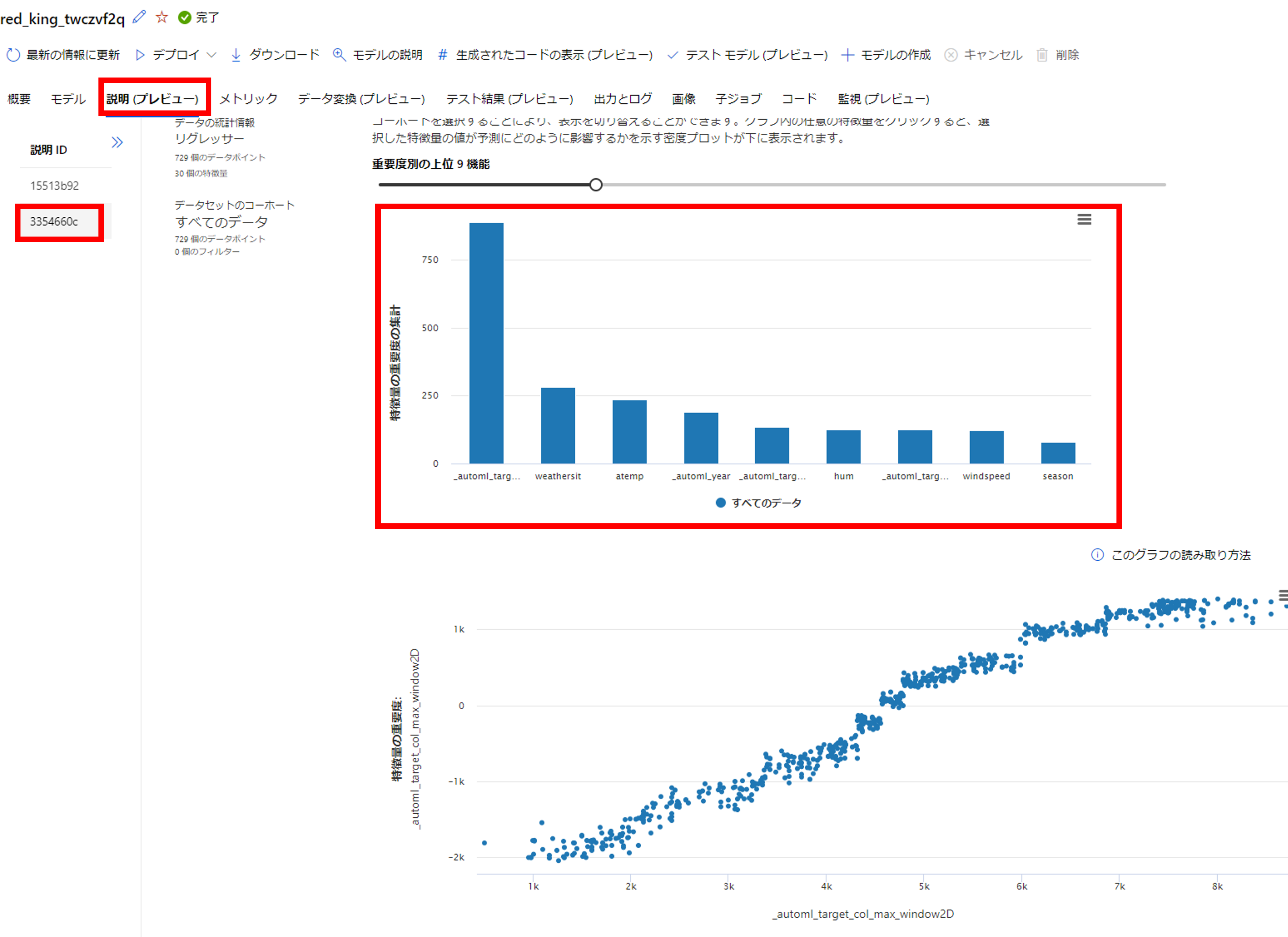
次に説明変数の重要度を見ていきましょう。「説明(プレビュー)」をクリックします。
左側の「説明ID」ですが基本的には二つのIDが生成されます。
1番目のIDはデータ加工前の説明変数を用いたモデル解釈で、2番目のIDはデータ加工後の説明変数を用いたモデル解釈となります。
今回はデータ加工後の説明変数を見たいので、2番目のID「3354660c」をクリックしましょう。
特徴量の重要度は「特徴量の収容度の集計」のタブから確認できます。
こちらを確認すると「_automl_target_col_max_window2D(利用者数の移動最大)」「weatersit(天気 晴れ/曇り/雨)」「atemp(気温)」の順番で重要であることが分かります。
※説明変数が長すぎて見えない場合は、グラフのバーをクリックすると下にプロットが出てきて、そちらで変数名を確認できます。
Azure Machine Learningではいくつかのモデル解釈手法があります(詳しくは公式ドキュメント)。
AutoMLを実行すると基本的には「mimic.lightgbm」という手法が使われてます。
こちらの手法はサロゲートモデル(代理モデル)を使ってモデルの中身を解釈する手法で、
例えばアンサンブルモデル等の複雑なモデルの中身を何とか解釈しよう、というモチベーションがある時に使われます。
大まかな流れは下記の通りです。
- 学習したモデルに対して、再び学習データXを投入し予測結果yを取得する
- Xとyの組み合わせに対して、解釈可能なモデル(今回はlightgbm)を学習させる
- lightbgmのモデルの中身を解釈する
サロゲートモデルの詳しい説明はこちらを参照(https://hacarus.github.io/interpretable-ml-book-ja/global.html)
元々の学習モデルの精度が悪い場合、モデルの説明自体、意味がないのでご注意ください。
まとめ
いかがでしたでしょうか?Azure Machine Learningの時系列予測のAutoMLを①モデル作成編②モデル評価編に分けて解説しました。
ノーコードでこれだけのことができるのは素晴らしいですね。今回は解説対象外でしたが、作成したモデルはワンクリックでAPIとしてデプロイすることもできます。こちらの機能もとても便利なので、合わせて是非お試しいただければと思います。