はじめに
本記事では、Azure Machine Learning(以下AML)上で機械学習のプロジェクトを始めるにあたって「これだけは最初にやっておいた方が良いよ」という種々の設定を解説します。MLOpsのDevOps的側面(エンジニアリング的側面)が強く、VS Code/Gitの使い方、conda仮想環境/リンター・フォーマッターの設定方法等、コーディングの手間までの内容になっています。しかし、この下準備があるのとないのでは、今後のMLプロジェクトの進めやすさがかなり変わってくるので、是非ご一読いただければと思います。
ワークスペースの準備
まずは、AMLのワークスペースを作成しましょう。このワークスペースでは、機械学習プロジェクトで必要なリソース/データセット管理、学習結果の共有等を行います。
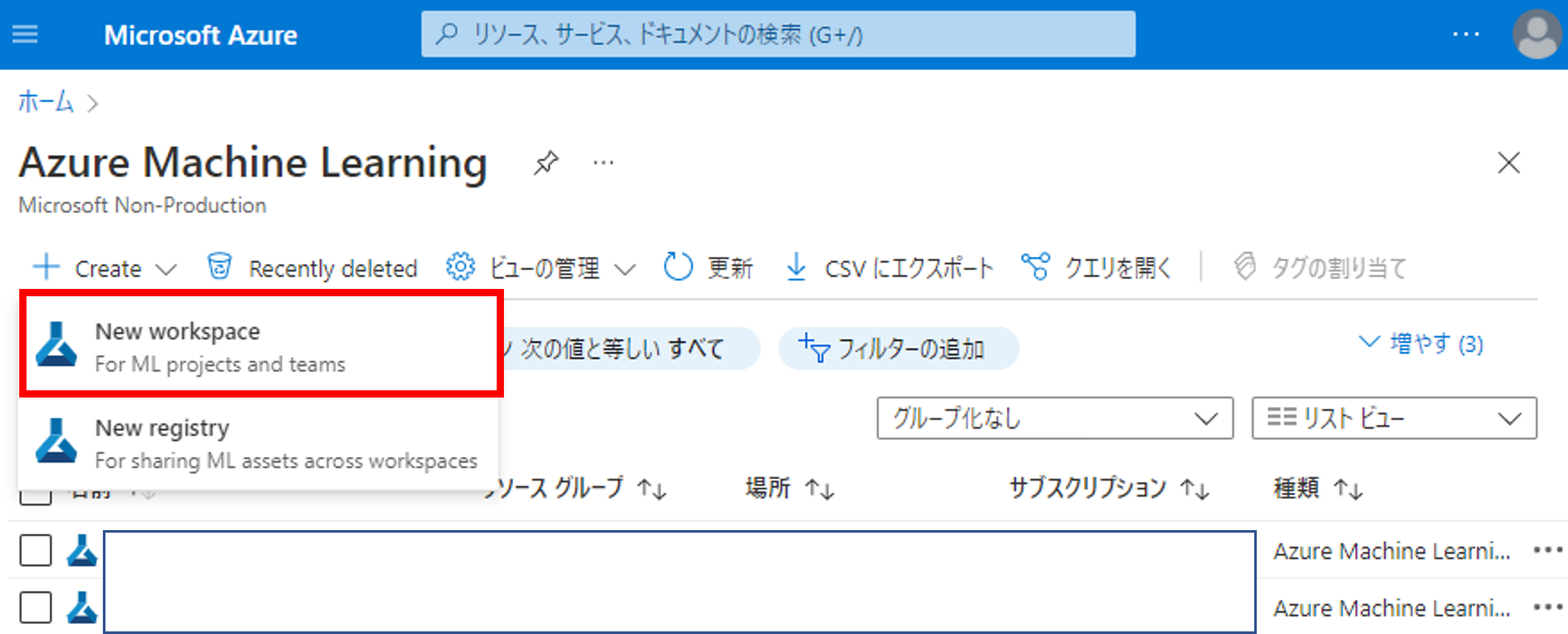
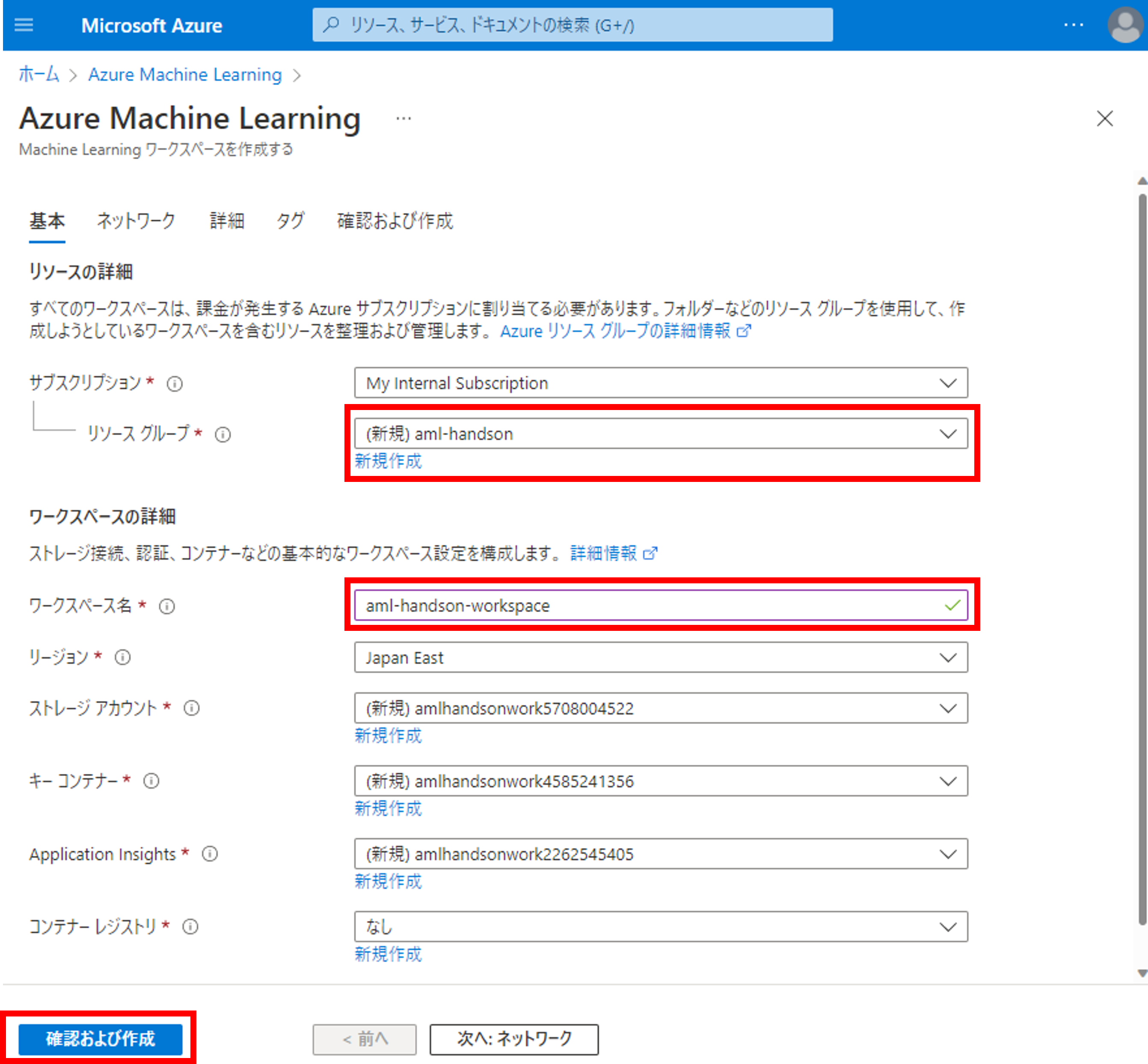
リソースグループとワークスペース名を入力します。
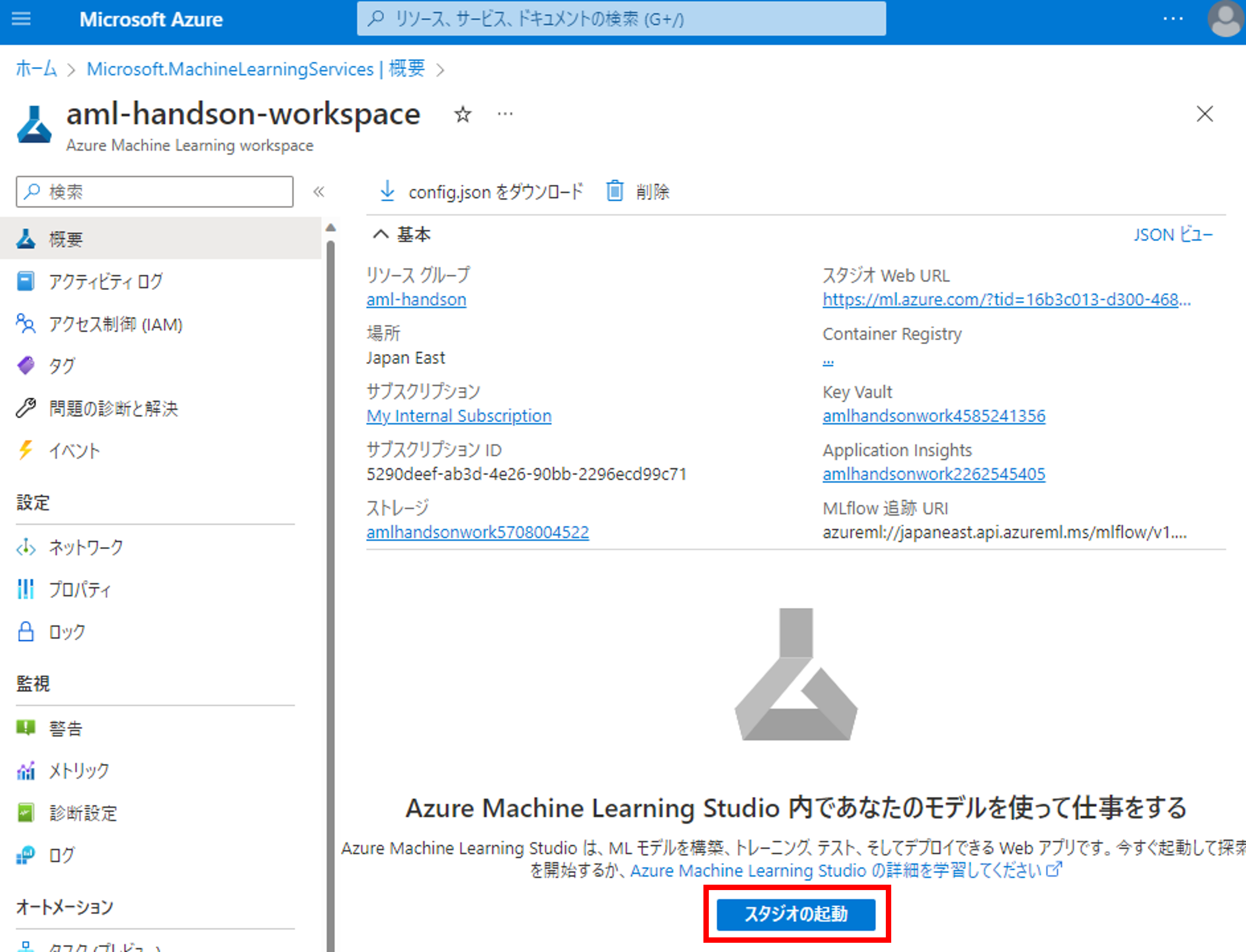
リソースが作成されたらスタジオを起動しましょう。
コンピューティングインスタンスの準備
個人の開発環境としてコンピューティングインスタンスを作成しましょう。AMLのマネージドインスタンスには機械学習に必要なPyhtonのライブラリが一通りインストールされています。
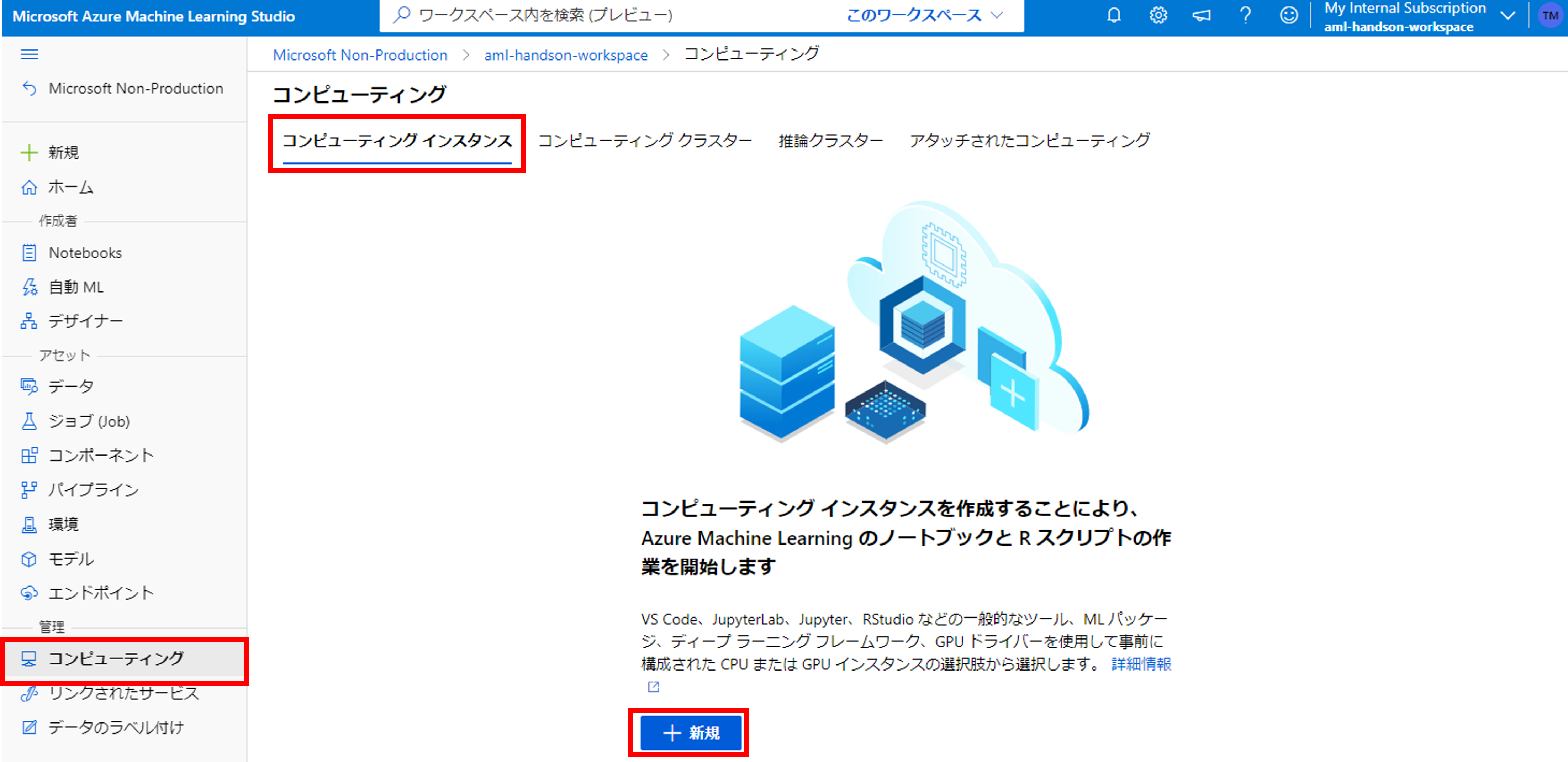
コンピューティング名を入力し、仮想マシンのサイズを選択します。
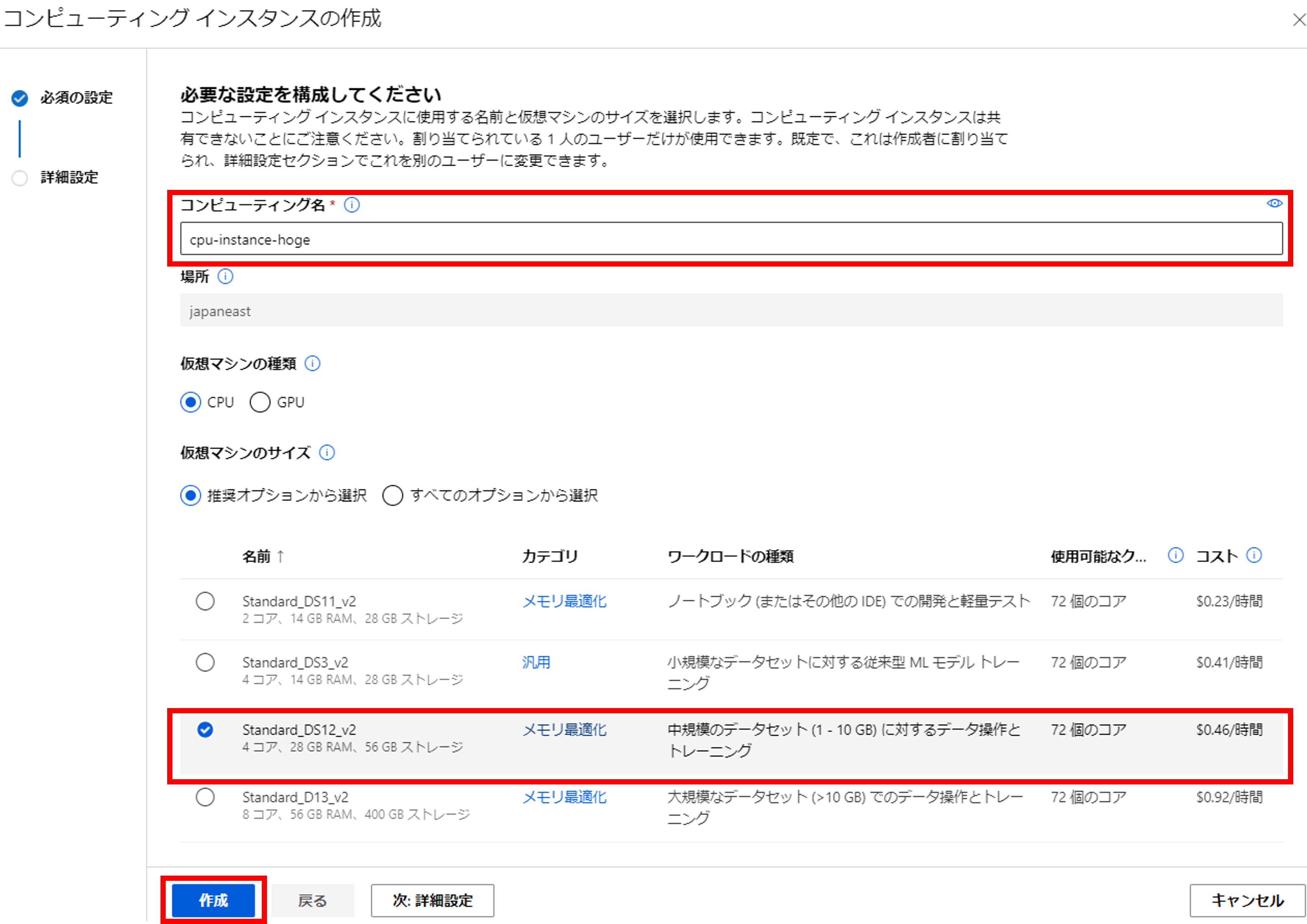
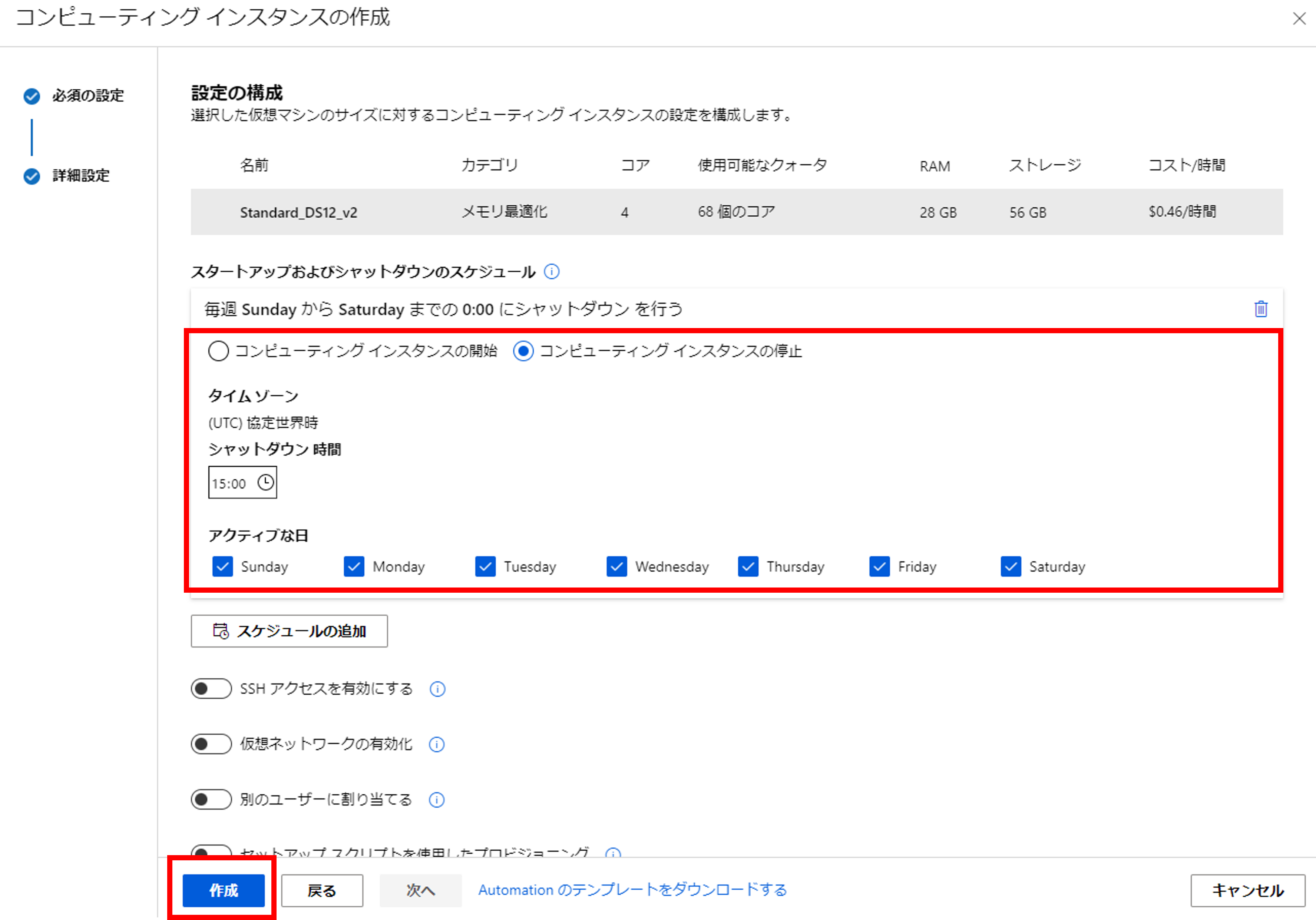
ここで作成をクリックしても問題ないのですが、おすすめの設定を紹介します。詳細設定をクリックすると、インスタンスのシャットダウンのスケジュールを設定することができます。これで「シャットダウン忘れてがっつり課金された~」という事故を防げます。MLOpsのポイントは何と言っても「自動化」です。すでにMLOpsは始まっているのです!
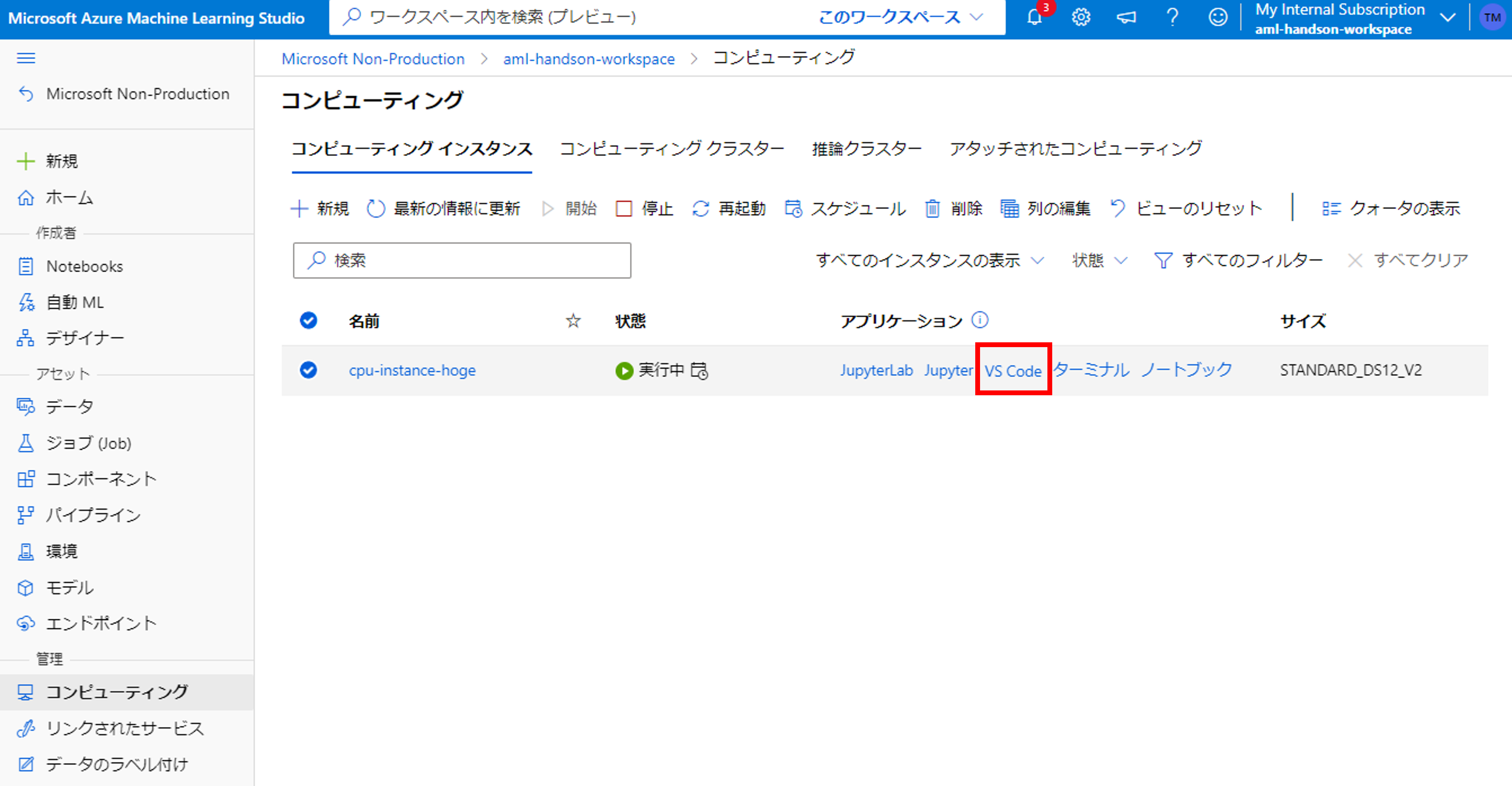
リソースが作成できたので、さっそくインスタンスにアクセスします。アプリケーションからVS Codeをクリックしましょう。
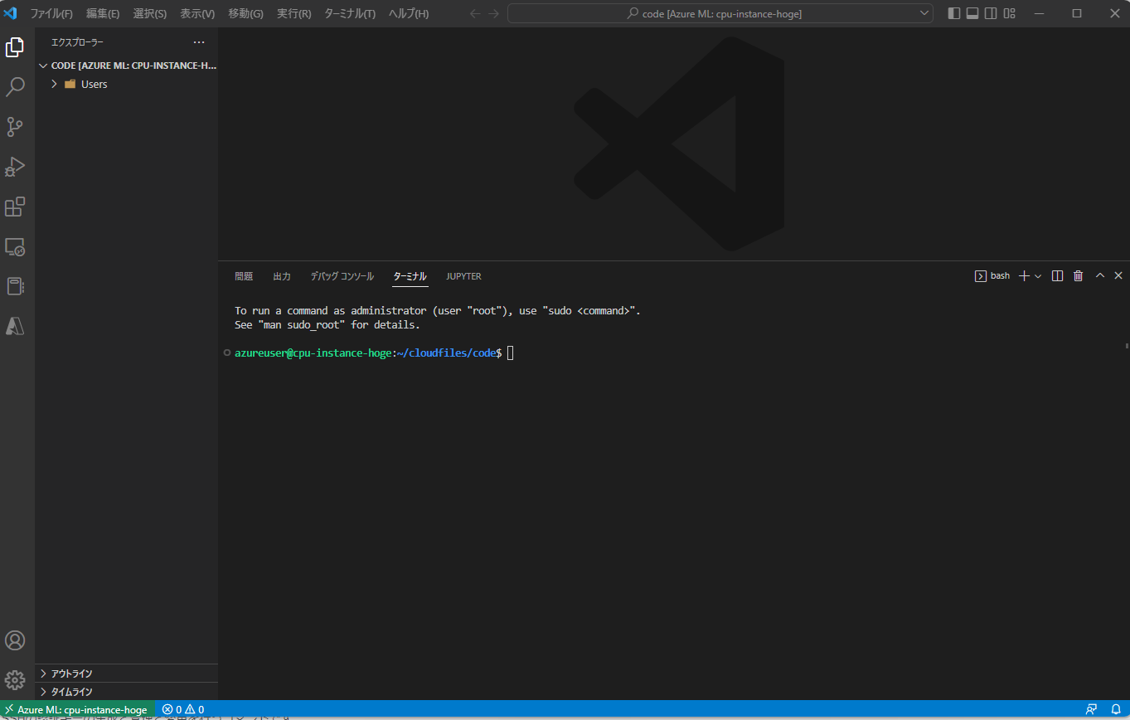
Jupyter NotebookやJupyter Labが好きな人にもVS Codeをお勧めします。MLOpsでは「コードの品質」が重要なポイントになってきます。VS Codeではコードの品質を保つための様々なツール(リンターやフォーマッター等)をGUIで使うことができます。また、PythonのデバッガーやGit拡張機能等も使い倒していくことになるのでこのあたりはVS Codeめっちゃ便利です。
Azure DevOpsの準備
開発に入る前に、コードを管理するための仕組みを作っておきます。コード管理はGitHubが有名ですが、今回はAzure DevOpsを使います。Azure DevOpsはチーム開発に必要な一連の機能を提供しており、MLOpsで良く使う機能は「Repos(コード管理)」「Pipeline」です。「Azure DevOps organizations」からDevOps Studioにログインしましょう。
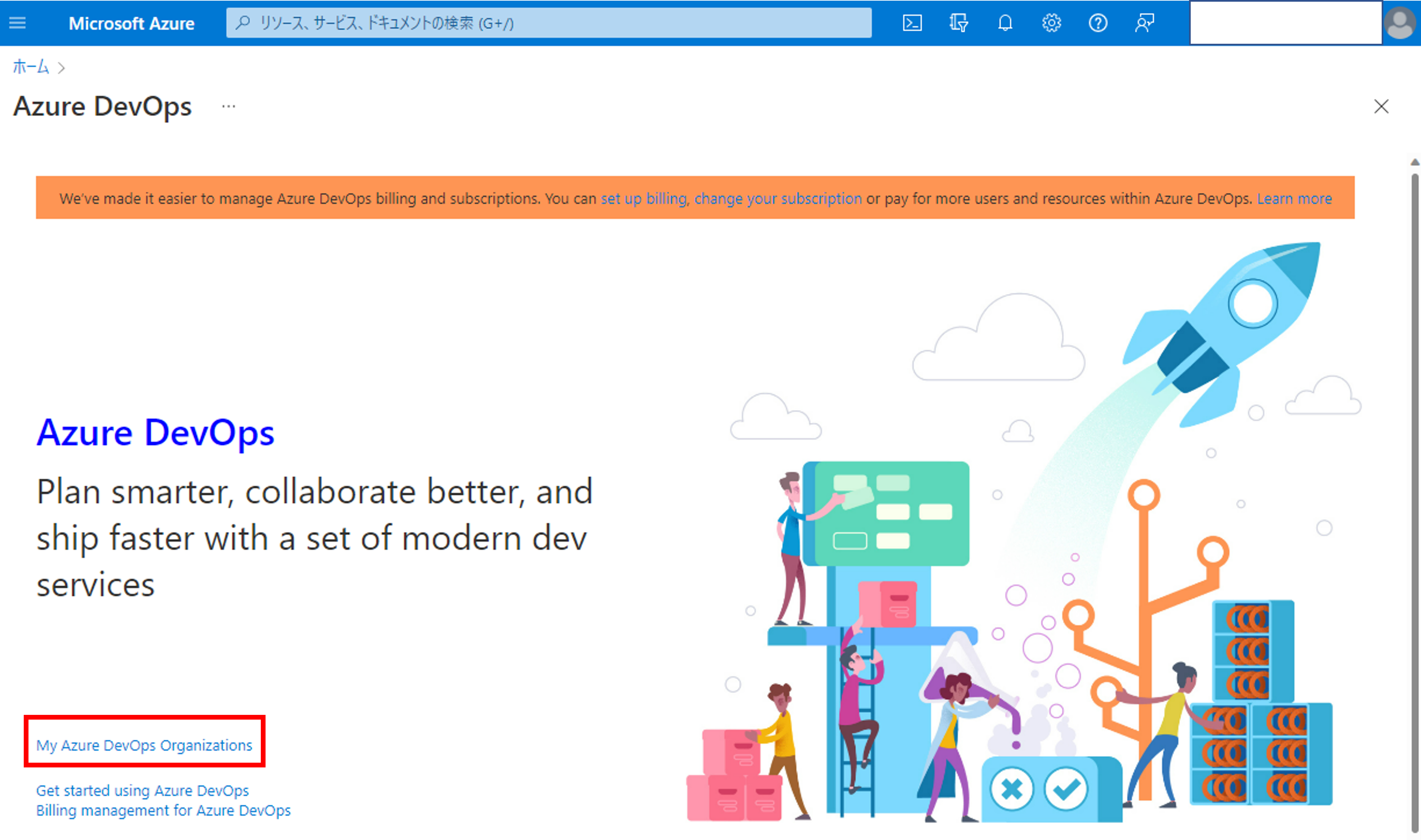
組織(Organization)が作成されていない場合は組織を作成します。 DevOpsでは組織-プロジェクト-レポジトリの階層構造で種々が管理されています。
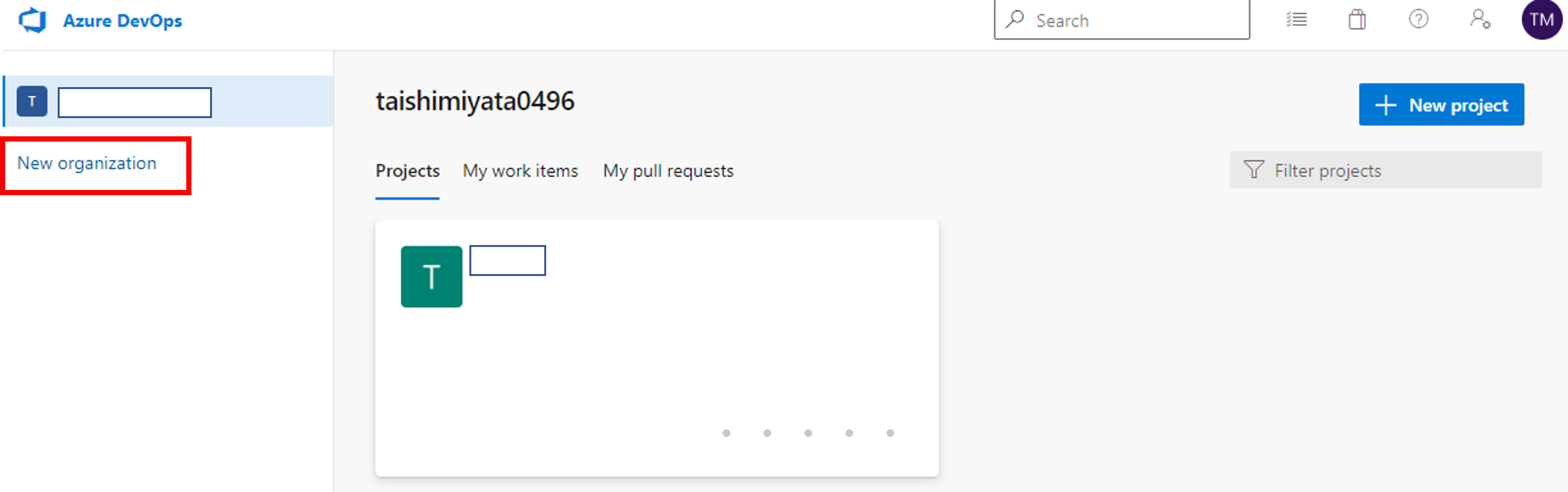
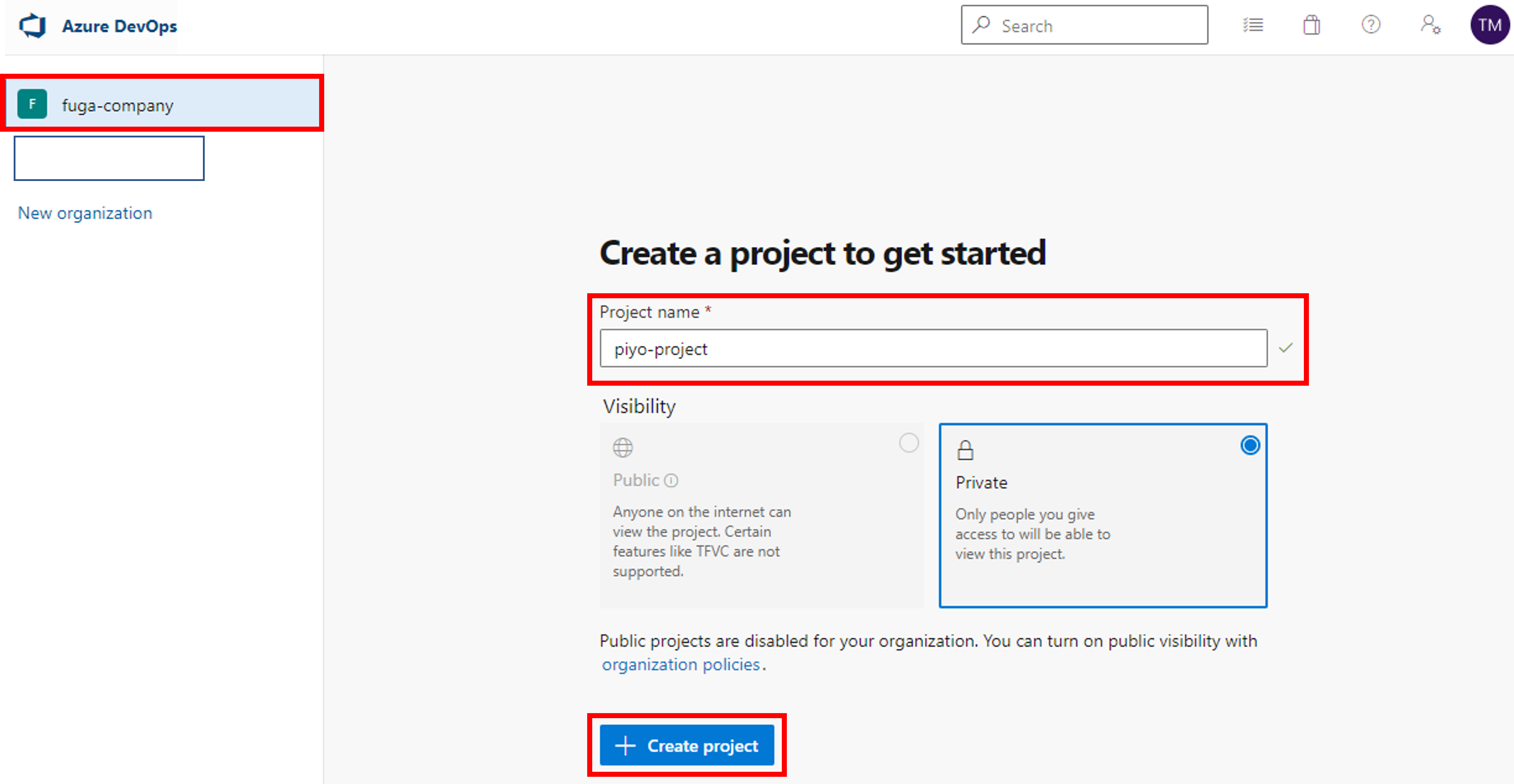
次にプロジェクトを作成します。
プロジェクトを作成するとReposに自動的にレポジトリが作成されます。
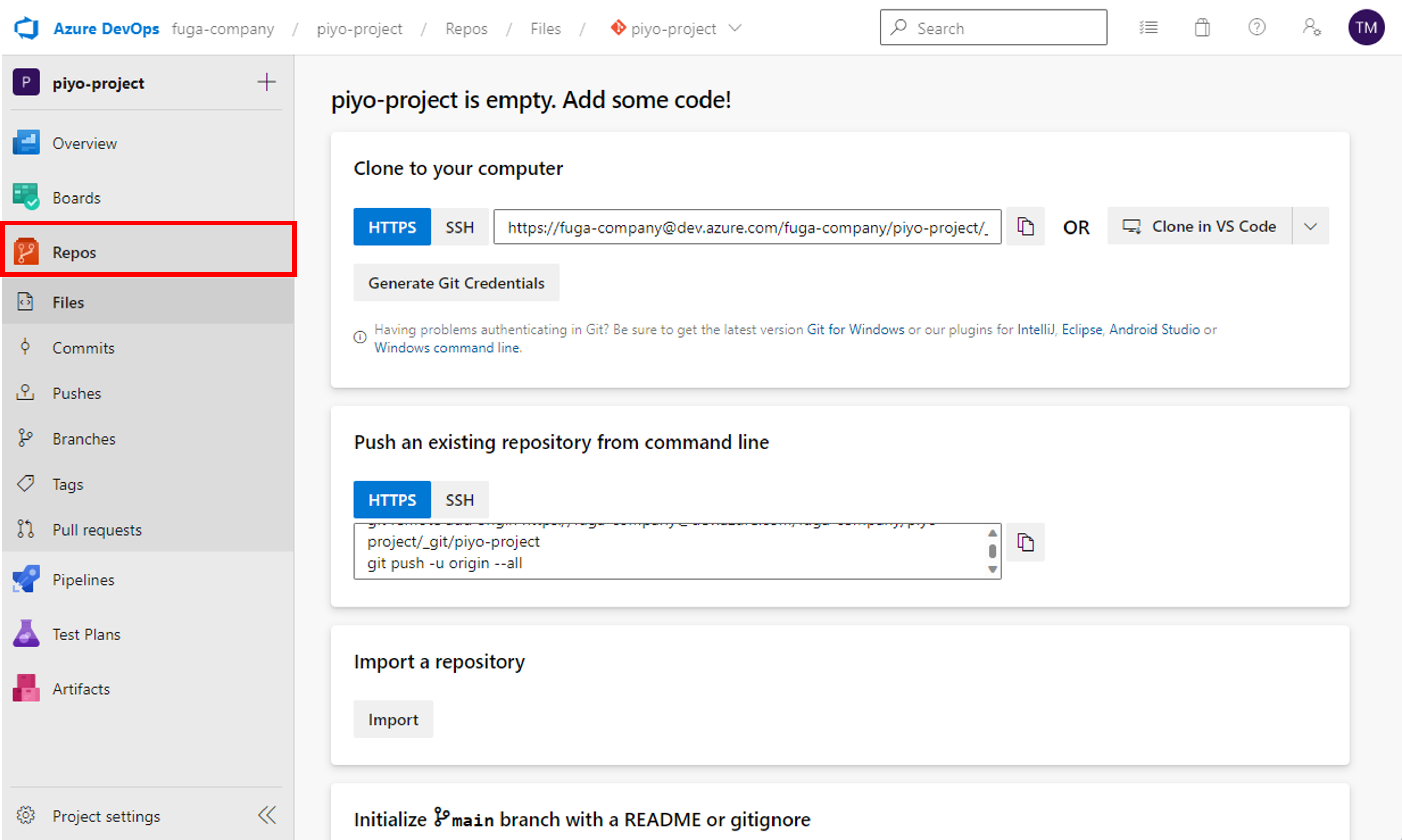
次に開発環境のマネージドインスタンスからGitへアクセスするための認証設定を行います。DevOpsでは大きく分けて「Personal Access Token(PAT)」と「SSH公開鍵」の認証方法がありますが、PATの場合プルやコミットする毎にPATを入力する必要がありめんどくさいので、SSH公開鍵を登録する方法がおすすめです。
VS Code(先ほど立ち上げたコンピューティングインスタンス)に戻って、新しいターミナルを開き、下記のコマンドを実行します。
$ cd ~/.ssh
$ ssh-keygen -t rsa
(3回Enter)
.sshの配下に公開鍵id_rsa.pubが生成されるので中身をコピーします。
次にDevOpsに戻り、右上のPersonal Settingのアイコンをクリックし、SSH public keysをクリックします。
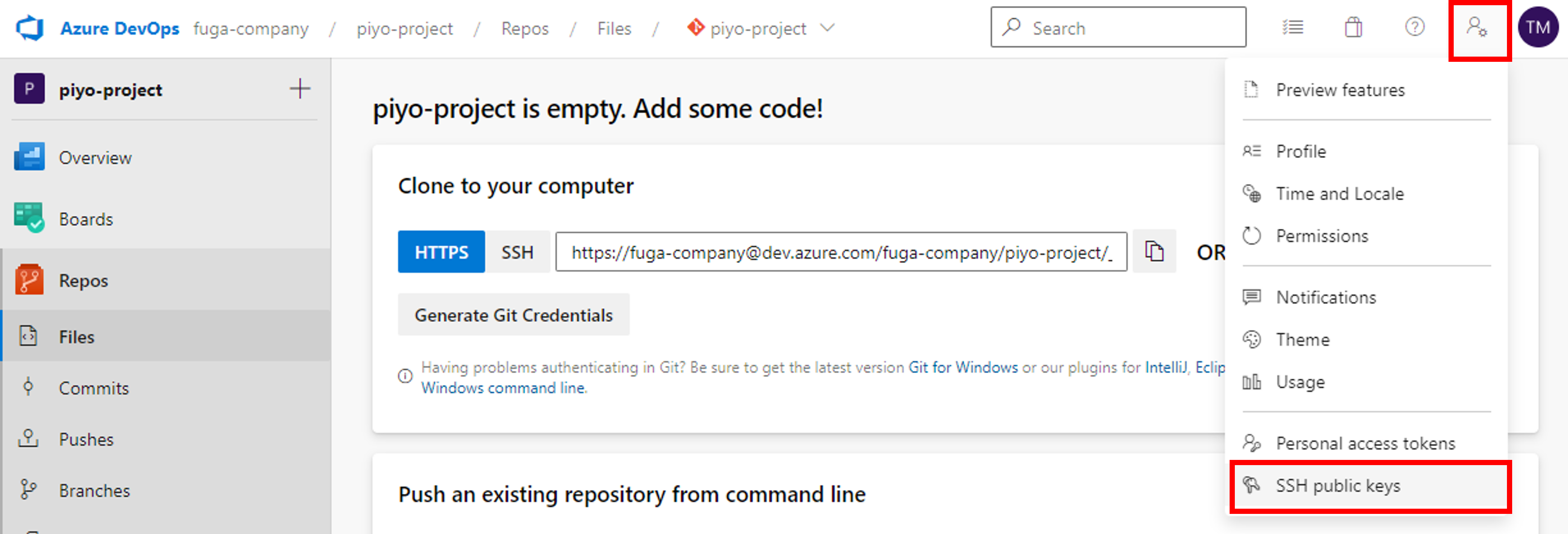
New Keyをクリックし、先ほど生成した公開鍵の内容を張り付けて登録完了です。
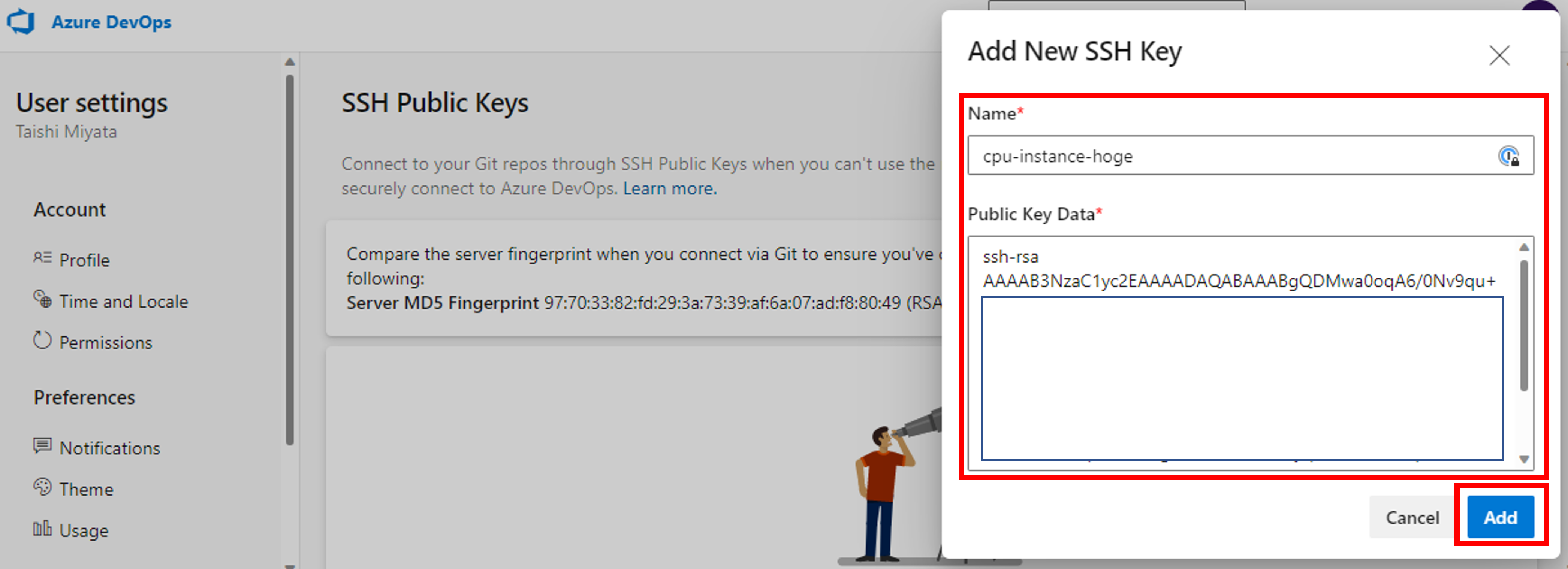
作成したプロジェクトがgit cloneできるか確認します。クローンする前にレポジトリを初期化しておきます。
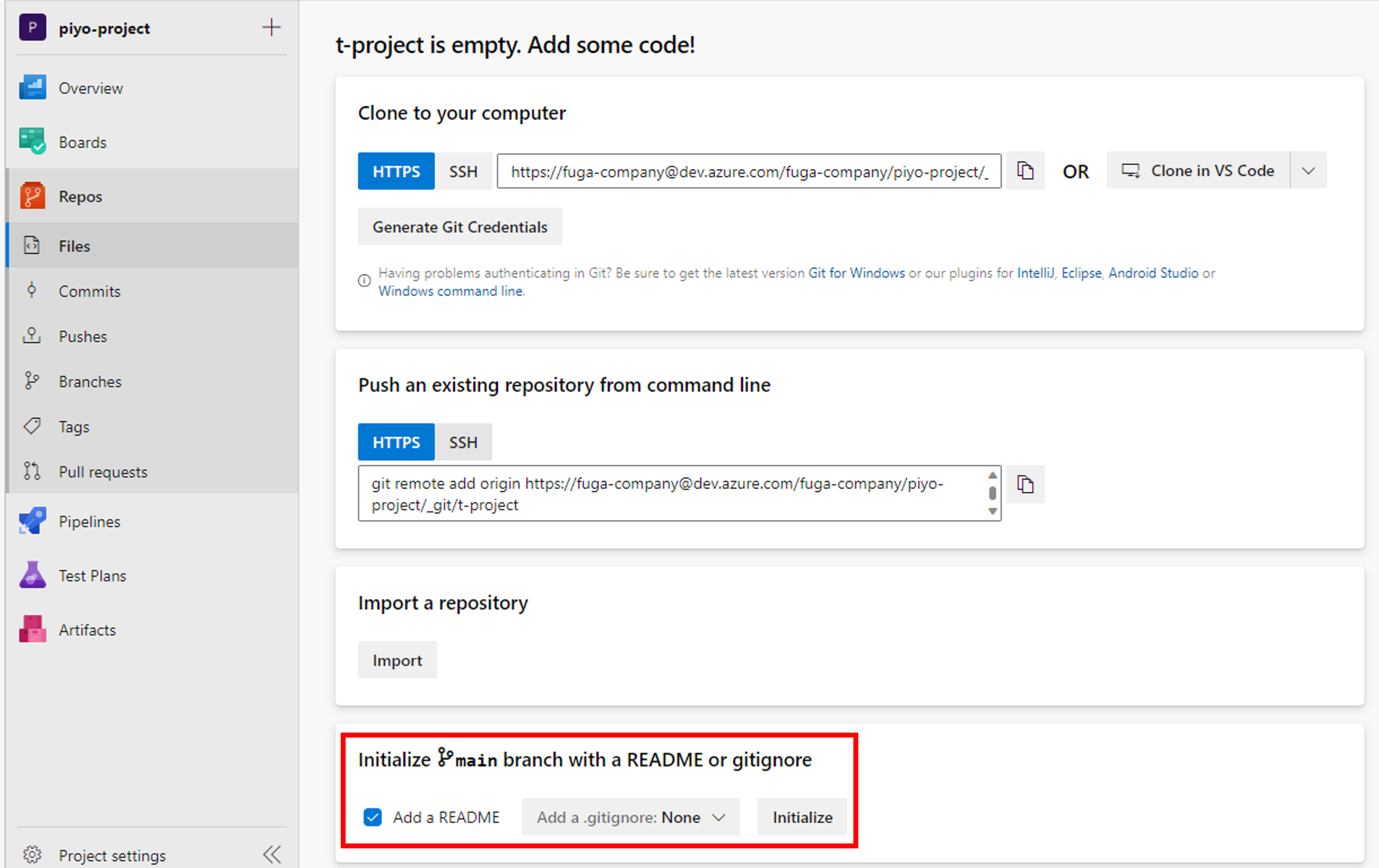
ReposからSSHのURLを取得します。
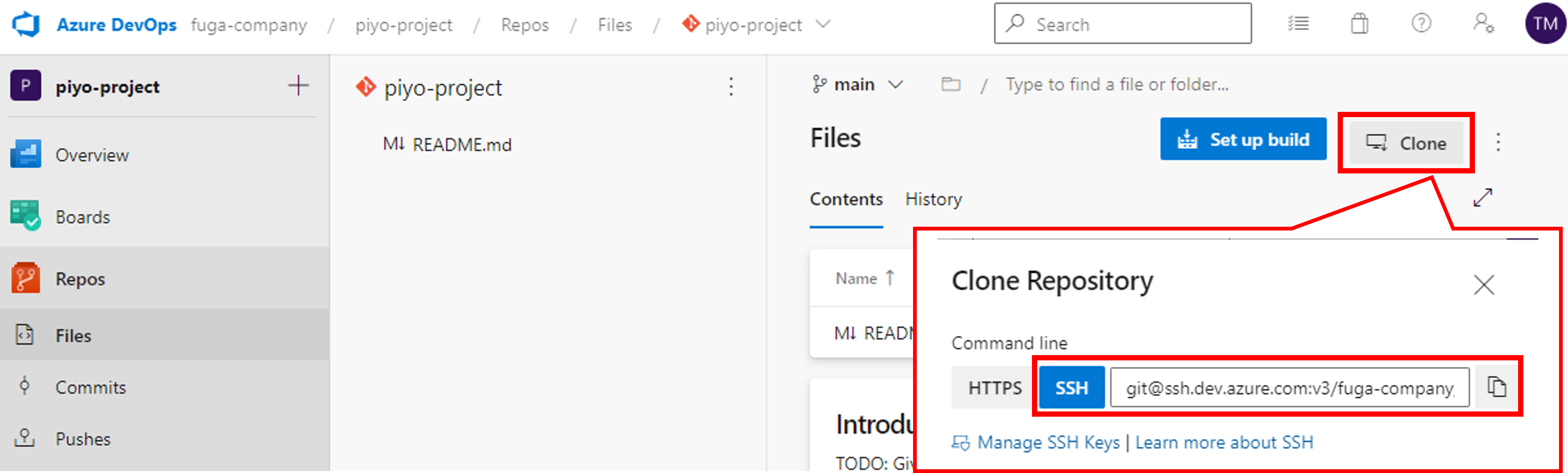
VS Codeに戻り、作業ディレクトリ以下に移動し、git cloneします。
$ cd /home/azureuser/cloudfiles/code/Users/taishimiyata
$ git clone git@ssh.dev.azure.com:v3/fuga-company/piyo-project/piyo-project
Cloning into 'piyo-project'...
remote: Azure Repos
remote: Found 3 objects to send. (37 ms)
Receiving objects: 100% (3/3), done.
ちゃんとクローン出来ていることが確認できました。VS Codeのワークスペースをpiyo-projectに変更しましょう。
$ code piyo-project/
この画面まで表示できればOKです。
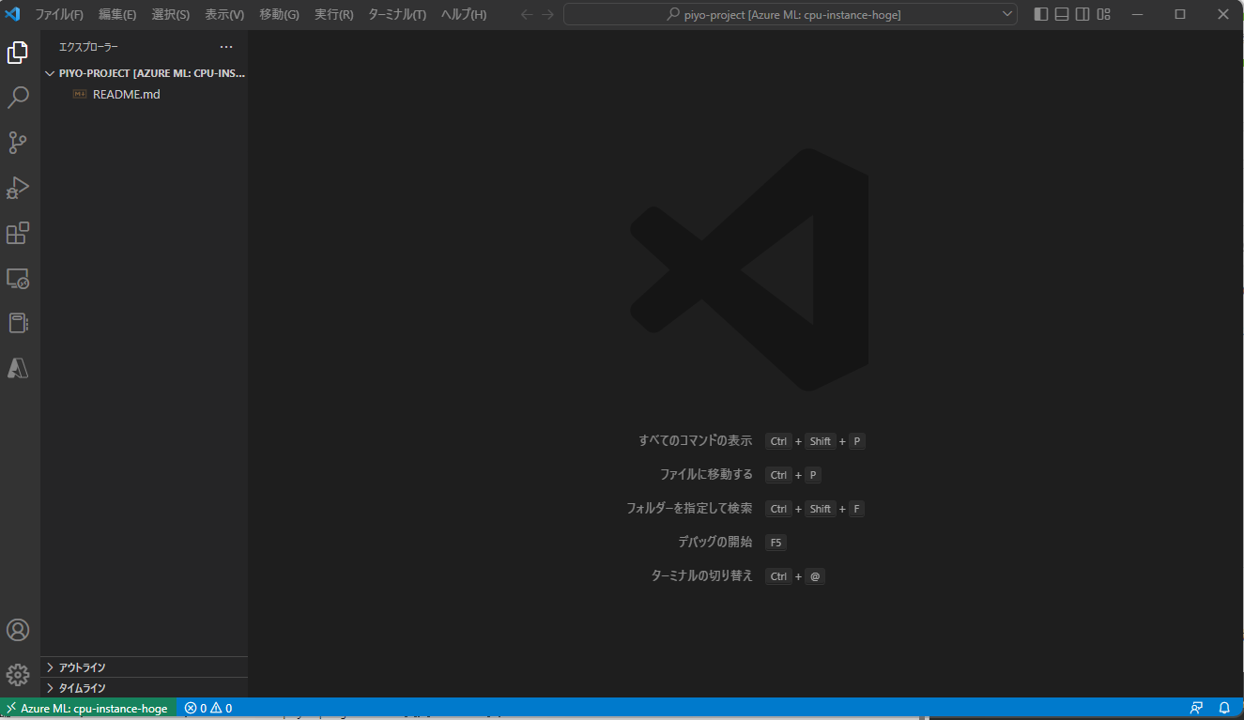
次にVS CodeのGit拡張機能を有効にしていきます。左側のGitのアイコンをクリックしましょう。
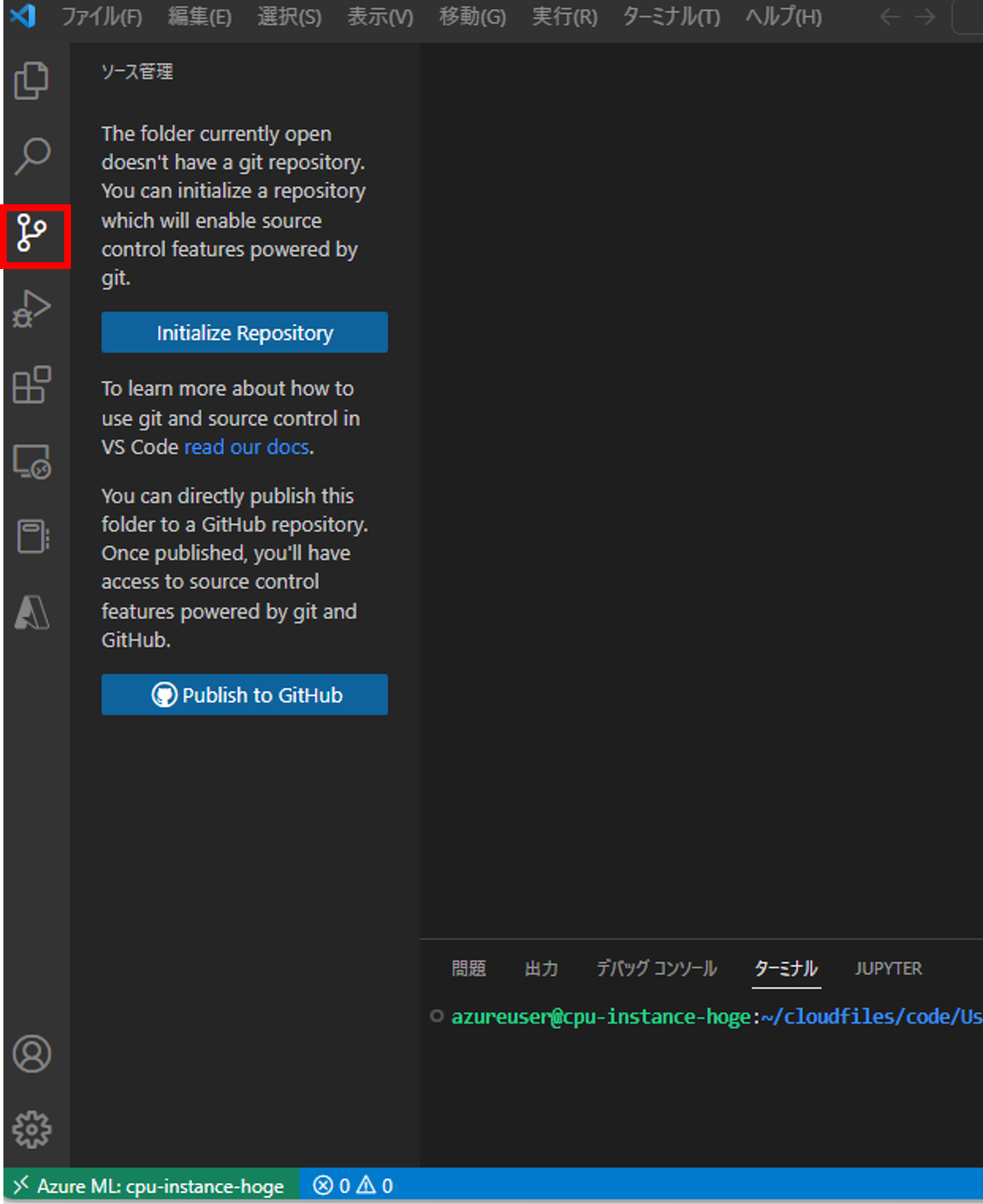
デフォルトではGit拡張機能が有効になっていないことが確認できます。この現象はマネージドインスタンス側でsafe.directoryの設定に起因するものなので、下記コマンドでsafe.directoryを*で許可します。
$ git config --global safe.directory "*"
設定を反映させるために、ウィンドウの再読み込みを行います。
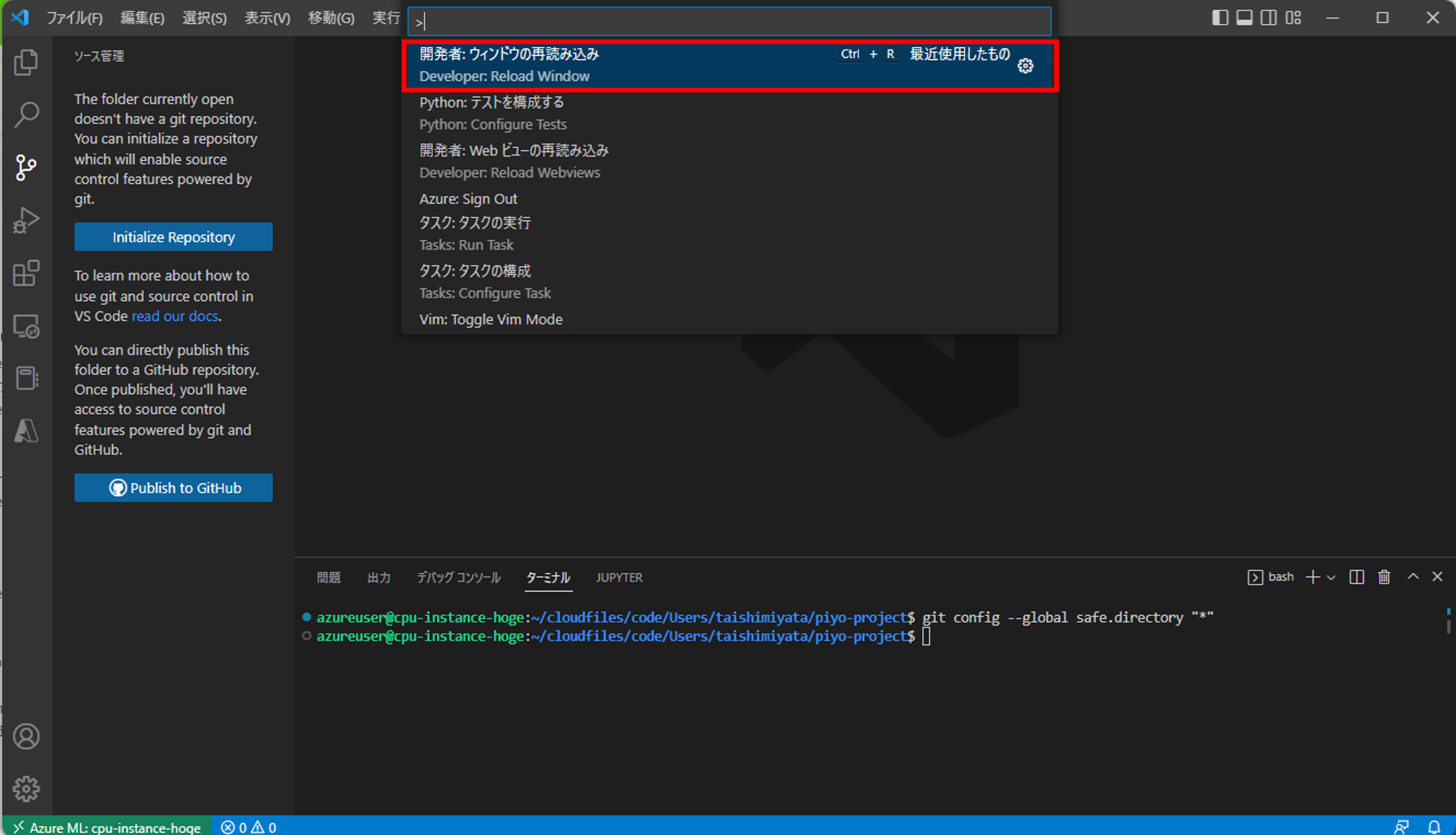
Git拡張機能が有効になりましたね。
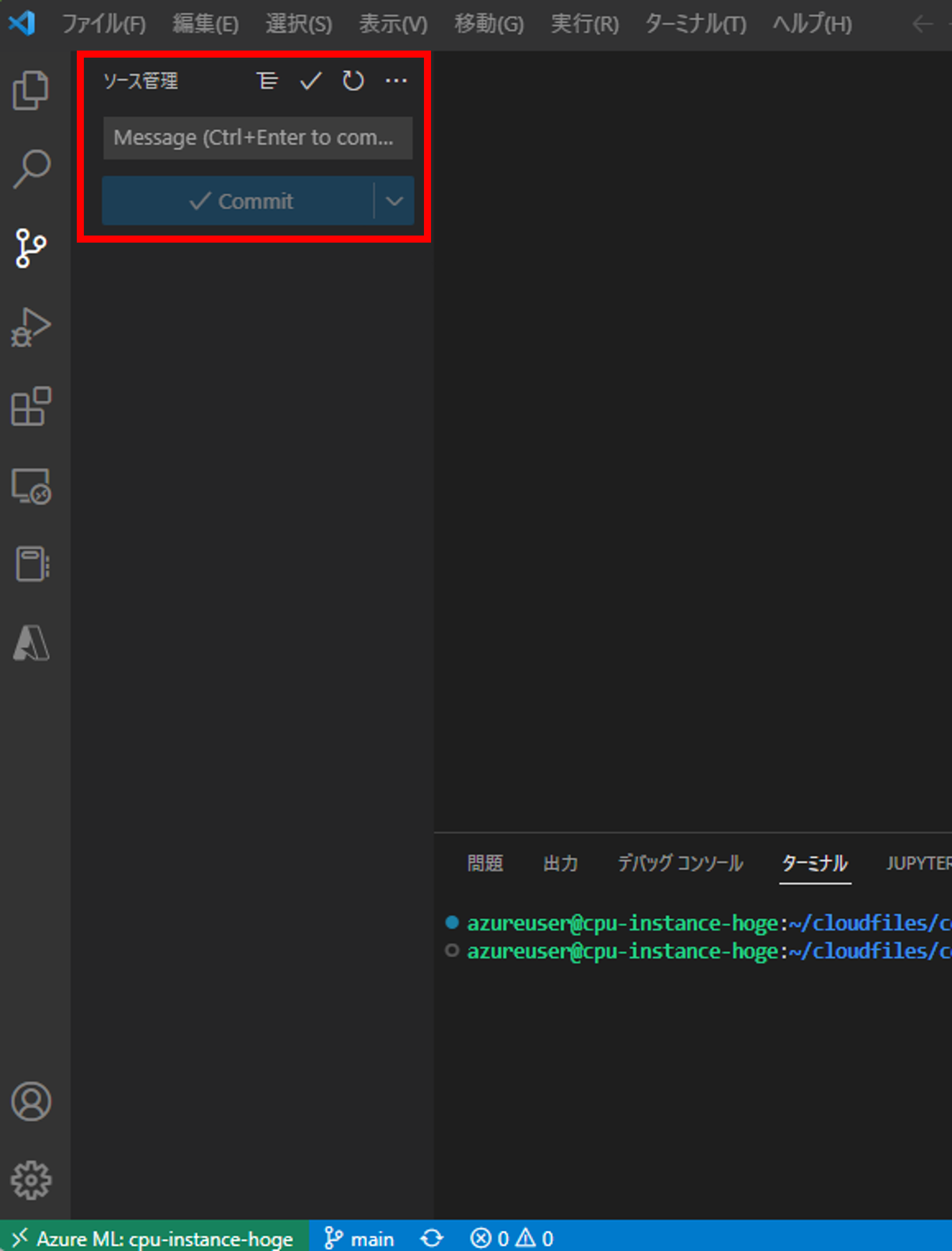
コミットやプッシュをする際に必要な設定も忘れないようにしましょう。
$ git config --global user.email "AAA@bbb.com"
$ git config --global user.name "Hoge Fuga"
これにてgit連携の部分は完了です。
conda仮想環境の作成
次にcondaの仮想環境を作成していきます。今回は下記のenvironment.ymlを作成しました。
name: sample-env
channels:
- conda-forge
- defaults
dependencies:
- python=3.10.4
- pip
- notebook
- ipykernel
- mlflow
- pip:
- azure-ai-ml==1.0.0
- azureml-mlflow==1.46.0
- flake8==4.0.1
- isort==5.10.1
- black==22.3.0
- catboost==1.0.6
- scikit-learn==1.1.1
- pandas==1.4.3
- numpy==1.23.1
- pytest==7.1.3
- mypy==0.971
- python-dotenv
このenvironment.ymlは、AML上でジョブを実行したい場合に環境情報として指定することになります。きっちり管理しておきましょう。それでは、condaの仮想環境を作成します。
$ conda init bash
$ conda env create -f environment.yml
condaの仮想環境の作成後、一度ターミナルを再起動する必要があります。exitコマンド等でターミナルを終了し、再度新しいターミナルを開きます。bashの行の先頭に(base)があればOKです。
次に、先ほど作成したcondaの仮想環境にログイン、Jpuyterのカーネルにも追加しておきます。
$ conda activate sample-env
$ ipython kernel install --user --name=sample-env
下記のように表示されればOKです。

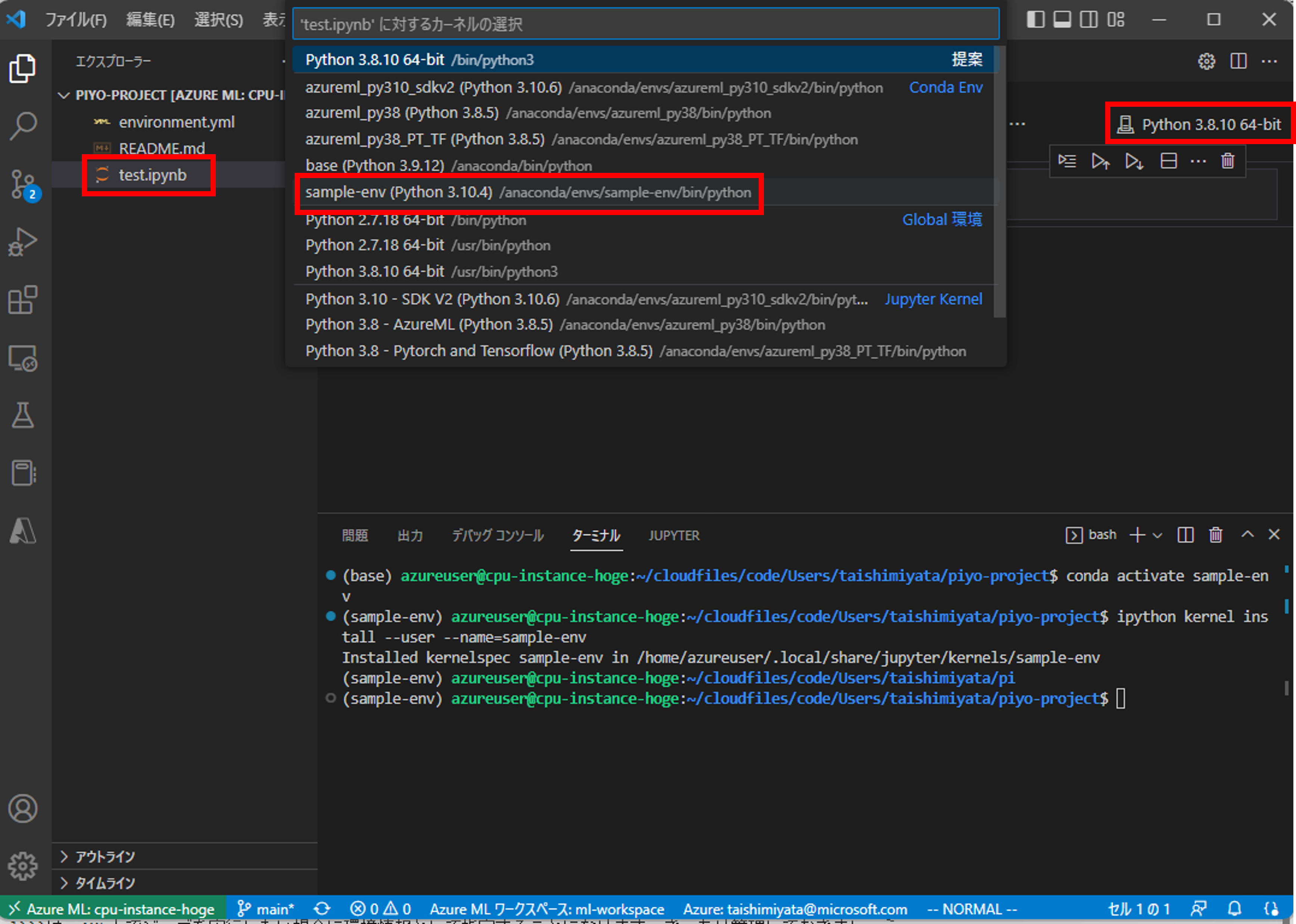
Jupyter Notebookでカーネルが使えるか確認します。適当な.ipynbファイルを新規で作成し、右上のカーネルをクリックします。先ほど作成したsample-envが出てくることを確認しましょう。
次に.pyファイルに関しても開発環境を確認しておきます。test.pyを新規で作成し、右下のインタープリターをクリックします。すると、先ほど作成したcondaの仮想環境が選択できると思います。
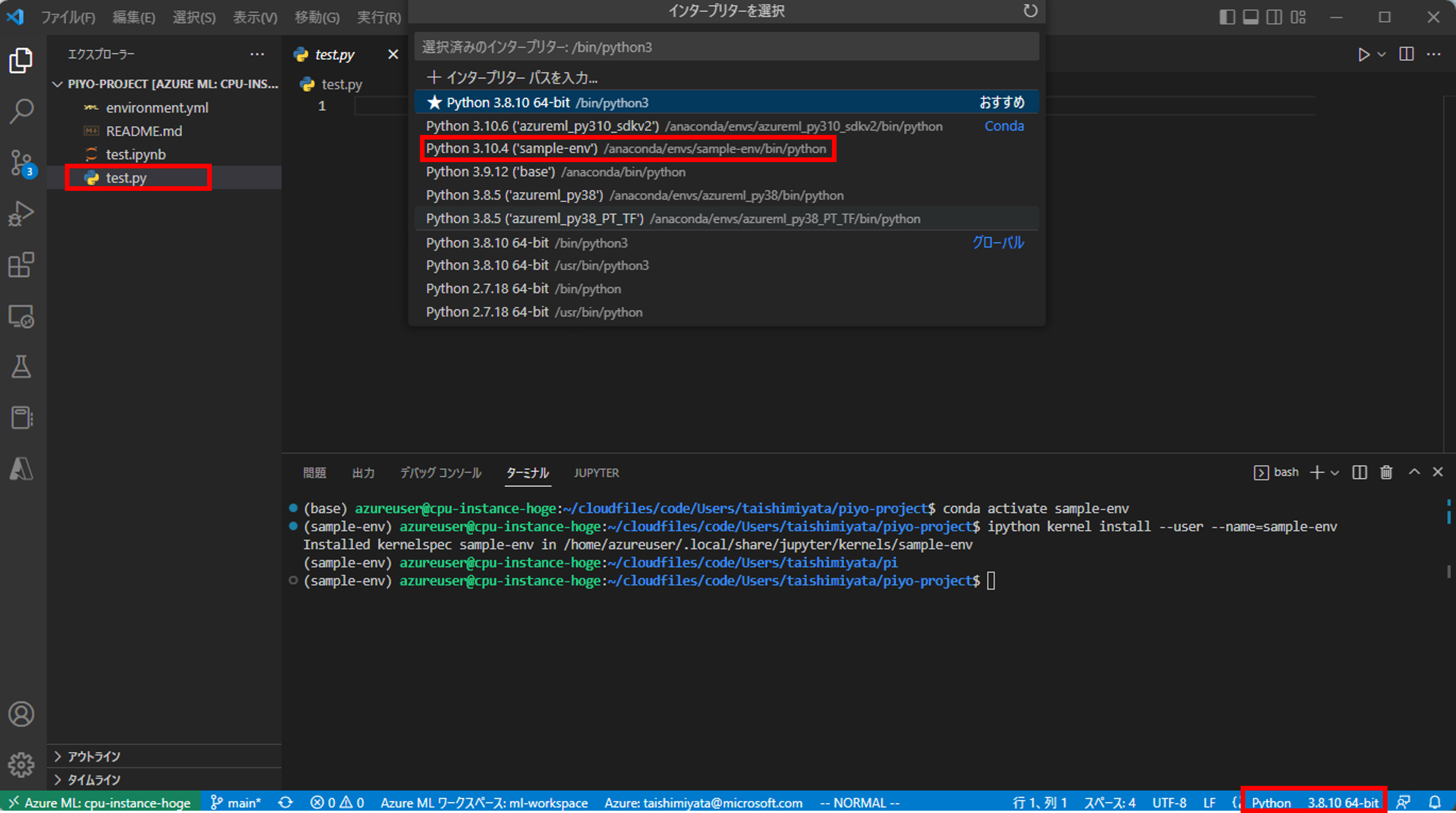
これで.ipynbと.pyがconda仮想環境のカーネルで開発できる状態になりました。
リンターとフォーマッターの導入
コードの品質を保つ上で、コードの静的解析ツールのリンターやコード整形のフォーマッターを導入することをおすすめします。導入のコストは低く、コード品質への効果は非常に大きいです。今回はリンターとしてflake8、フォーマッターとしてblackを使っていきます。これらライブラリはcondaの仮想環境のymlに加えておきましょう。
これらのライブラリをVS Codeに反映させるためには、ワークスペースに.vscodeのディレクトリを作成し、settings.jsonに設定を記述します。
{
"python.linting.enabled": true,
"python.linting.flake8Enabled": true,
"python.linting.lintOnSave": true,
"python.formatting.provider": "black",
"editor.formatOnSave": true,
"python.terminal.activateEnvironment": true
}
設定項目の概要は下記の通りとなります。必要最低限の設定ですのでお好みに応じてカスタマイズしてください!
| 設定項目 | 説明 | 値 |
|---|---|---|
| python.linting.enabled | Lintの機能を有効にするか | true |
| python.linting.flake8Enabled | Linterにflake8を使用するかどうか | true |
| python.linting.lintOnSave | ファイル保存時にLintを実行するか | true |
| python.formatting.provider | formatterに何を使用するか | black |
| editor.formatOnSave | ファイル保存時に自動整形するか | true |
| python.terminal.activateEnvironment | ターミナル起動時に仮想環境をactivateするか | true |
崩壊したコードを書いてファイルを保存してみると、良い感じフォーマッターが整形してくれています。VS Codeの下の問題を見るとflake8が機能していることも確認できますね。
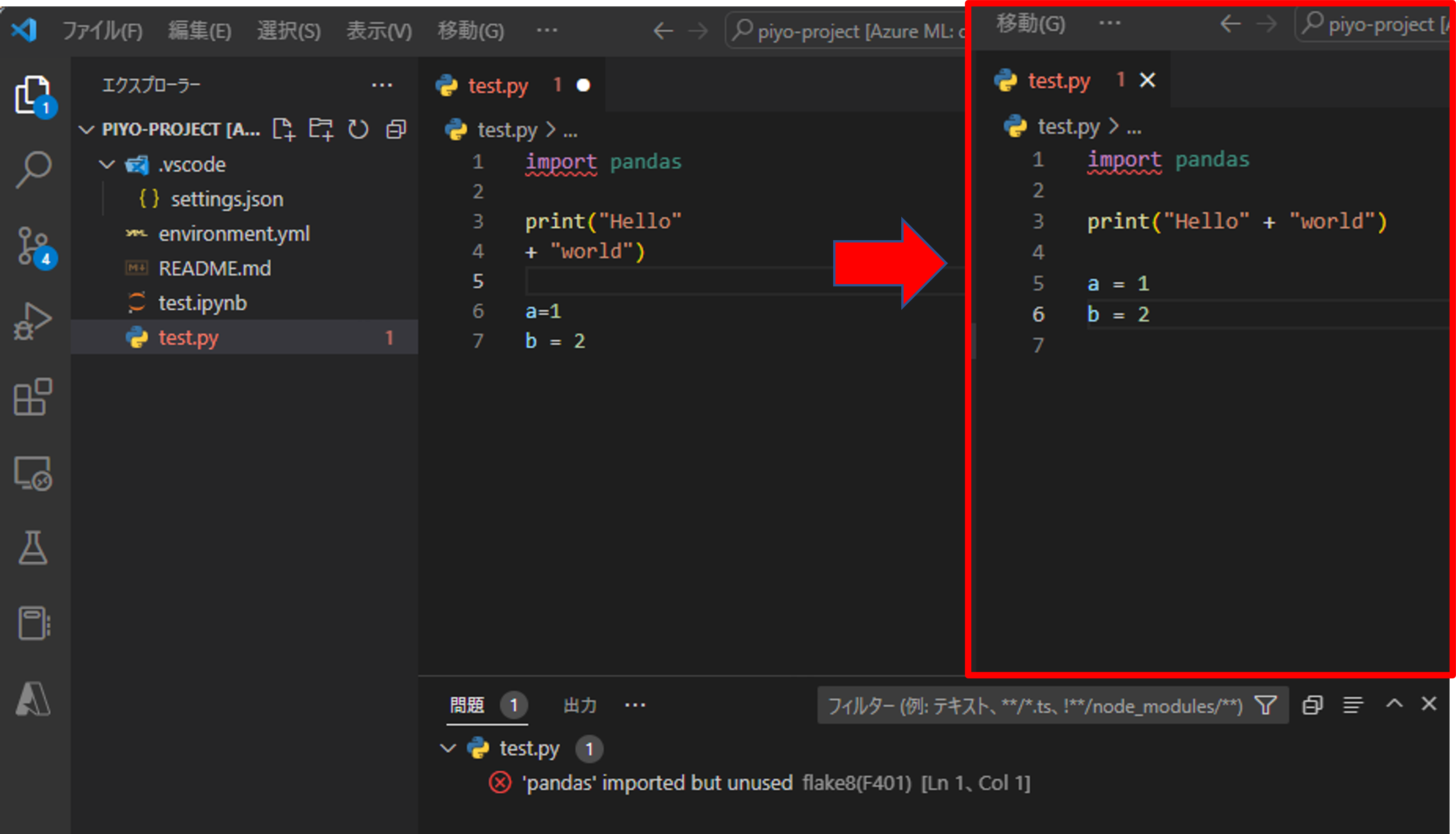
以上で下準備は終了となります。あとは楽しくコーディングして、リンターやフォーマッターで気持ち良くなりながら、精度の良い機械学習モデルを作ってください!(投げやり)
まとめ
今回はMLOpsにおけるAzure Machine Learningの始め方について解説しました。初動は大事ですし、ほぼパターン化されていると思うので、一部でもお役立ていただけると嬉しいです。