Optunaでは値の範囲を変えて追加で学習させることができる。
同様に、初期値を指定して学習を開始することも可能。
事前の手動の実験で良さそうなパラメータがわかっていてその周囲から探索してほしいとき、を想定している。
TL, DR
trial.trial_idで条件分岐させて初期値を指定する。
最適化する分布と同じ分布型(suggest_uniformとか)で指定する必要がある
ただし、カテゴリカル変数(suggest_categorical)は範囲の変更に対応していないので、カテゴリカル変数を含めて初期条件を指定したいときはリセマラしないといけないかも。
範囲を変化させる
Optunaのtutorialに載っている例から。
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
study.trials_dataframe()[('params', 'x')].plot()
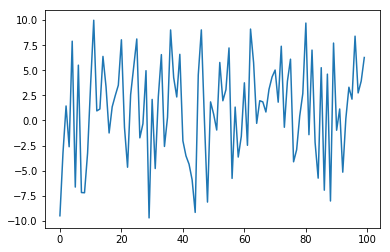
これは普通の最適化。
まずはtutorial通り、追加で学習する。
study.optimize(objective, n_trials=100)
study.trials_dataframe()[('params', 'x')].plot()
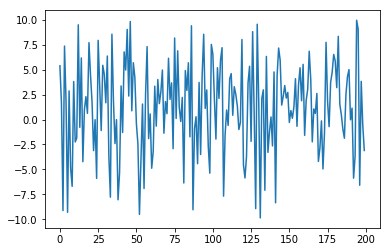
値の範囲を変えてみる。objectiveを再定義する。
def objective2(trial):
x = trial.suggest_uniform('x', -40, 40)
return (x - 2) ** 2
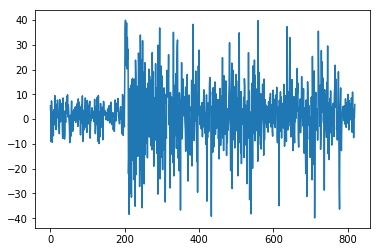
study.optimize(objective2, n_trials=500)
study.trials_dataframe()[('params', 'x')].plot()
初期値の設定
import optuna
def objective(trial):
if trial.trial_id ==0:
x = trial.suggest_uniform('x', 2, 2)
else:
x = trial.suggest_uniform('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
study.trials_dataframe()[('params', 'x')].plot()
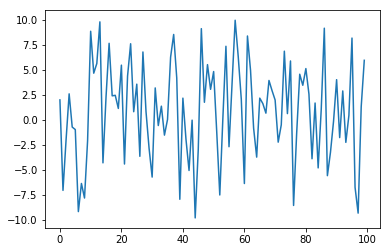
study.trials_dataframe().head(5)
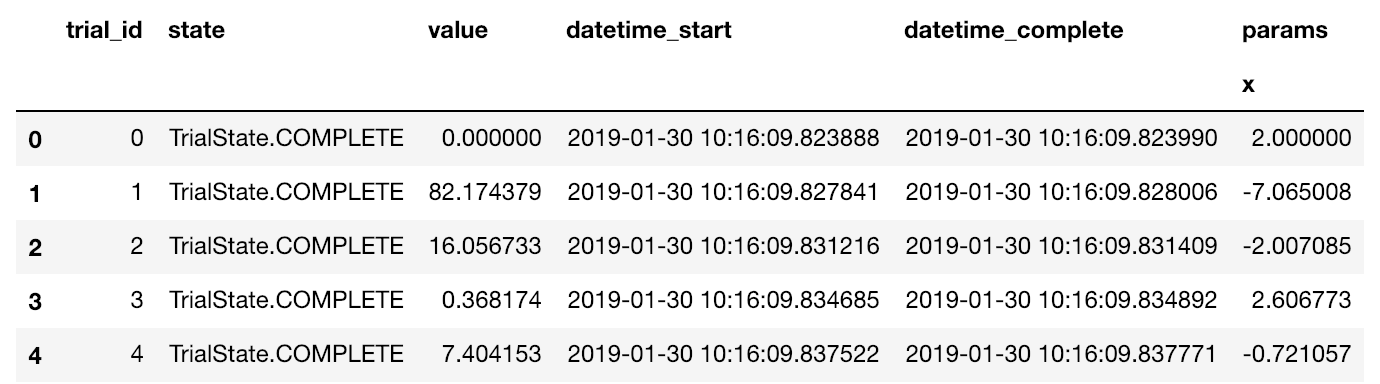
x=2から始めることができました。ざっとソースを眺めた限りでは、サンプリング(trial.suggest)する段階でそれ以前に試行した値とその結果を元にサンプリングしてきているようなので大きな副作用はないんじゃないかと思います。
※ ただし、suggest_categoricalで1つの値のみ指定しようとするとカテゴリ変数はdynamic range changeに対応していないといったエラーが返ってくる。