背景
GCPやAWS上のK8sではtype LoadBalancerとか書けばいい感じに外部からアクセスできるIPがアサインされるが、これはcloud-controllerという仕組みで(K8s内部ではなく)そのクラウドサービス上のLBaaSと連携して実現されている。
そのため、自分でオンプレなどにK8sを構築しようとすると普通LBaaSがないので、外部からK8sのアクセスをどうしようという悩みがよく起きる。
MetalLBとは
Googleが作ったベアメタルK8s環境でもつかえるExternal Load Balancer実装。
クラウド上のK8sと同じ間隔でオンプレでもtype LoadBalancerを使うことができる。
インストール方法
すでにK8s環境があれば一行で入る。
kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.5.0/manifests/metallb.yaml
コンフィグ
MetalLBにはBGPモードとL2モードがある。
BGPモード
BGPモードではK8sクラスタの上流にBGPが喋れるルータが必要になる。
そのルータのピア情報と払い出すExternal IPのプールの設定を入れる。
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
peers:
- my-asn: 64501
peer-asn: 64500
peer-address: 172.30.8.35
address-pools:
- name: my-ip-space
protocol: bgp
avoid-buggy-ips: true
addresses:
- 198.51.100.0/24
kubectl apply -f bgp.yml
L2モード
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: my-ip-space
protocol: layer2
addresses:
- 192.168.1.240/28
kubectl apply -f l2.yml
使ってみる
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1
ports:
- name: http
containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
type: LoadBalancer
kubectl apply -f nginx.yml
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx LoadBalancer 10.99.4.87 198.51.100.1 80:31263/TCP 1h
EXTERNAL-IPがついてる、すごい。
アーキテクチャ
BGPモード
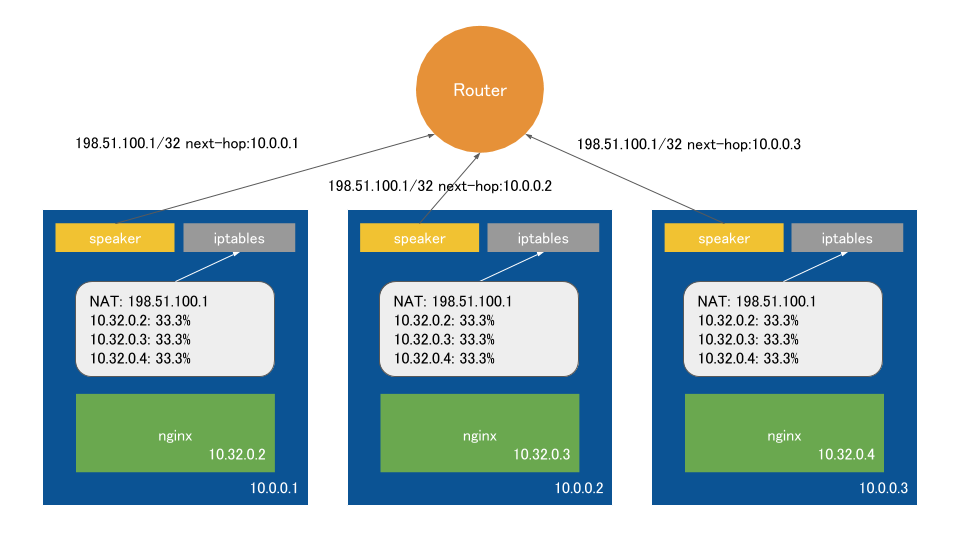
MetalLBをインストールするとDaemonSetを使用して、すべてのノードでspeakerというコンテナがホストネットワークモードで動き出す。
これはtype LoadBalancerなServiceがデプロイされた際にそのExternal IPをピアを張っているルータにnext-hopが自分であるように広告する。
同時にkube-proxyが各ノードのiptablesにreplicaに応じた確率でExternal IPからコンテナIPにNATされるように設定を書き込む。
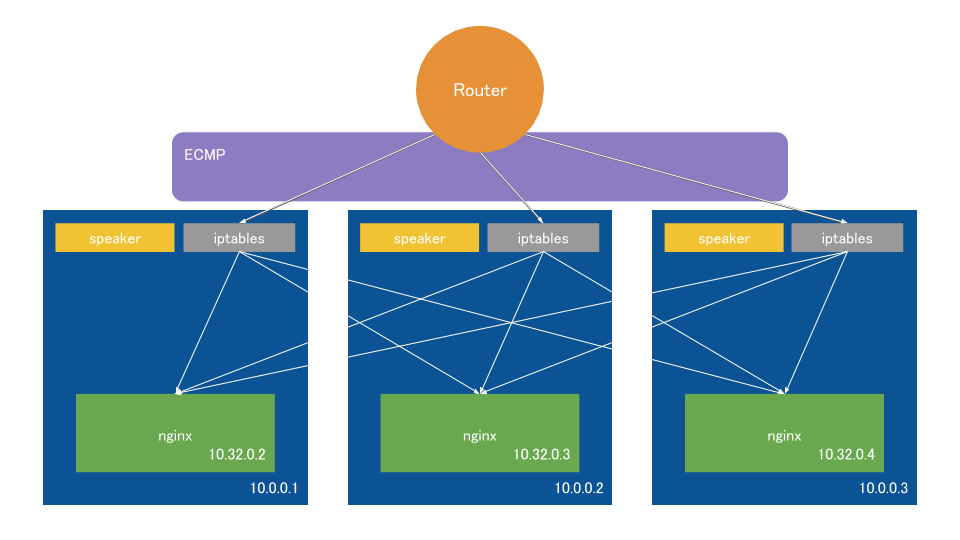
結果、ルーターはExternal IPへの経路をノードの数だけもち、ECMPでルータ→各ノード間はロードバランシングされる。
そしてExternal IPをもらった各ノードはiptablesでさらにロードバランスされる。
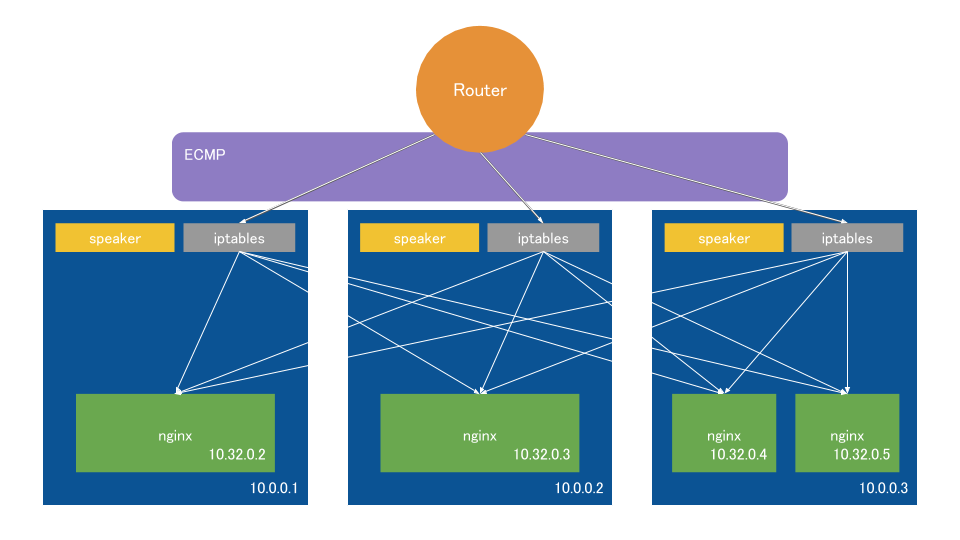
一見、2段のロードバランスは無駄に見えるが、これはノード:コンテナが必ずしも1:1でないため。
デフォルトでは、上図のように偏った状態でも各コンテナに均等にロードバランスするために2段構成になっている。
2段目のノード間をまたぐ通信をやめたい場合にはTrafficPolicyをLocalにすることでiptablesからのロードバランス先を自分のノード上にあるコンテナのみに制限することができるが、その場合均等にロードバランスされなくなる場合が出てくることになる。(上図だと左のコンテナから33.3%, 33.3%, 16.7%, 16.7%のようになる)
この構成のいいところはBGPの喋れるルータがあるだけで使え、フォワーディング性能の限界まで水平にスケールアウトできることである。
しかも全ノードをACTとして使え、ノード障害時には自動的にBGPのピアから外れてルーティングされなくなるため、DNSのレコードから消すような操作もいらない。
注意点
コンテナネットワークをオーバレイで作ってる場合は問題ないが、同じくBGPを使うCalicoで構築している場合はコンフリクトするため、いくつかワークアラウンドが紹介されている。
https://metallb.universe.tf/configuration/calico/
L2モード
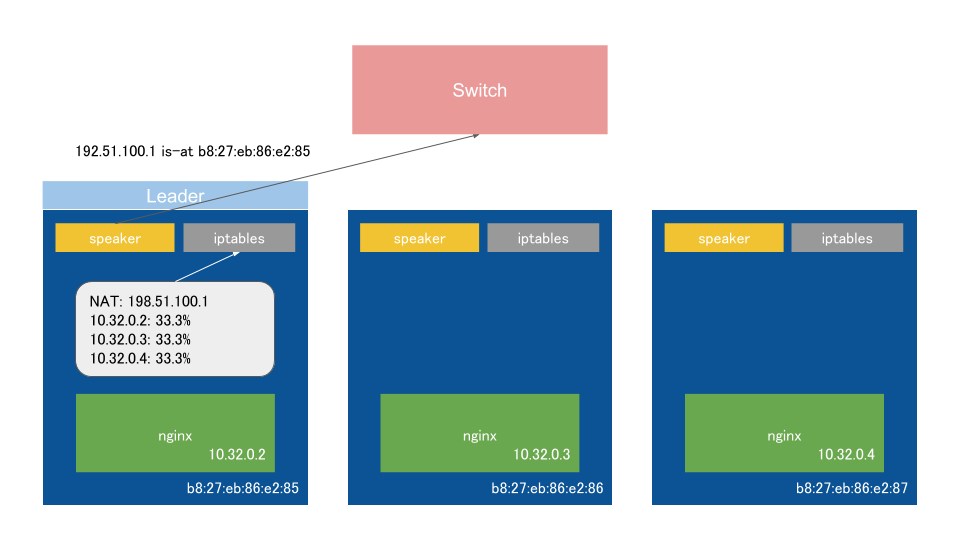
L2モードではLeaderに選定されたノードのspeakerがExternal IPのARP要求に対して、自分のノードのMACアドレスを応答する。
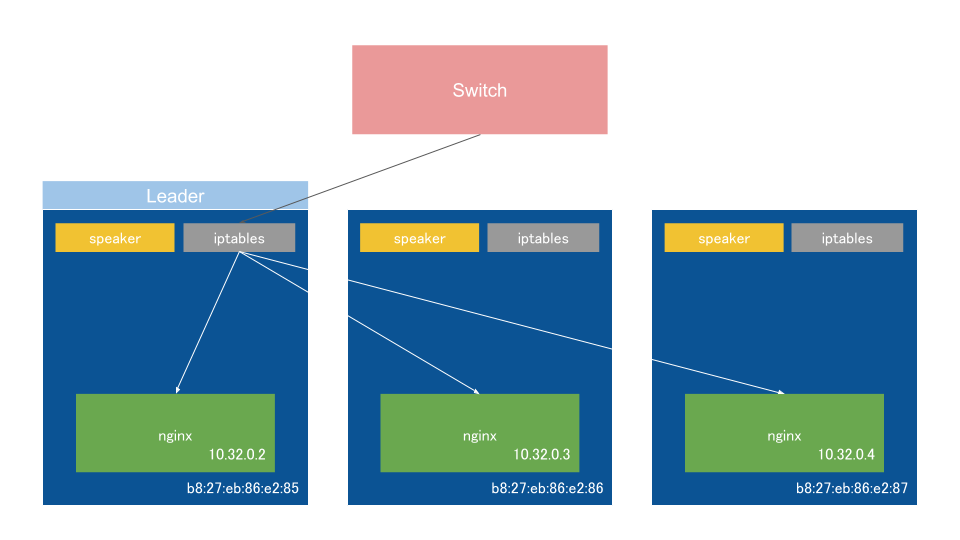
あとはBGPモードと同様。
見ての通りトラフィックがLeaderノードに集中してしまい、LB自体のスケールはできないが、手軽に構築できる。
障害時にはLeaderが再選出され、Gratuitous ARPでL2のARPテーブルを更新する。
Version 0.7.x以降
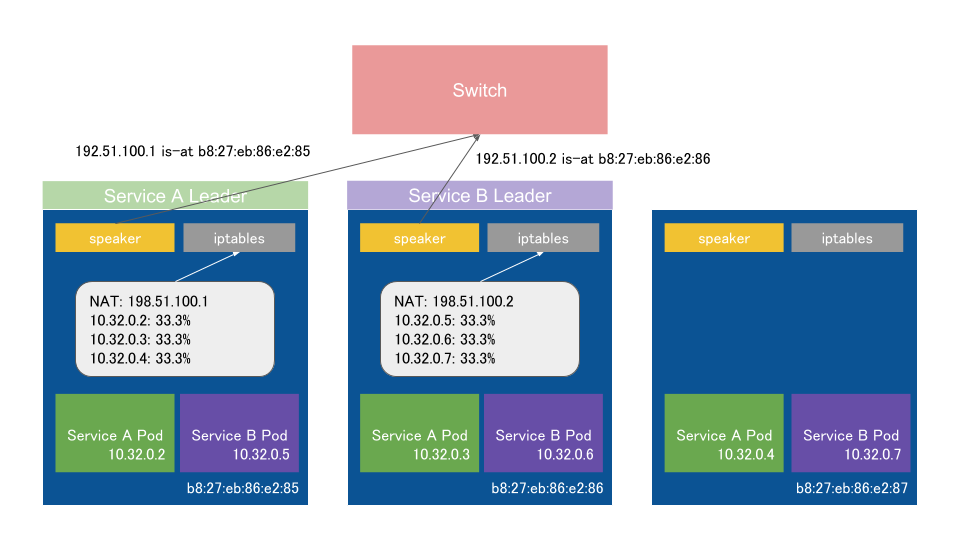
v0.7.x以降では基本的なアーキテクチャは同じだが、クラスタ全体でのLeaderの選出をやめ、ServiceごとにLeaderを選出するようになった。
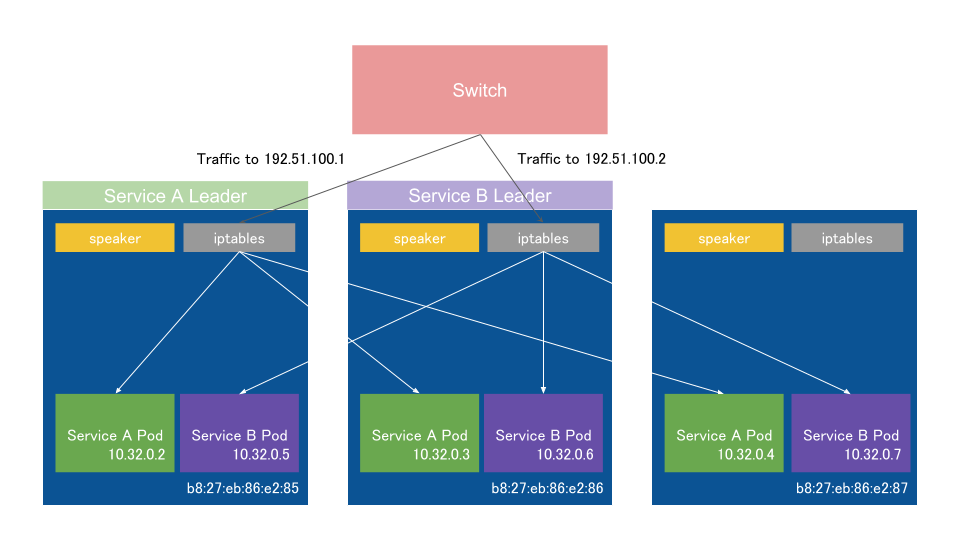
上記の変更により、複数Serviceを建てている場合に多少スケールするようになった。
また、L2 modeでもexternalTrafficPolicyをLocalにすることができるようになった。(Leaderは該当ServiceのPodが動いているノードから選出される)
参考
- ロードバランサのアーキテクチャいろいろ - yunazuno.log
http://yunazuno.hatenablog.com/entry/2016/02/29/090001 - GKE/Kubernetes でなぜ Pod と通信できるのか - Qiita
https://qiita.com/apstndb/items/9d13230c666db80e74d0 - Simple Stateful Load Balancer with iptables and NAT
https://www.webair.com/community/simple-stateful-load-balancer-with-iptables-and-nat/