はじめに
SurrealDBというグラフデータベースを活用し、仮想製造ラインのトレーサビリティ管理システムを実装してグラフデータベースの実用性を確認しました。
このシステムでは、製造ライン上で生成される様々なデータを収集し、それらをグラフデータベースに蓄積することで製造工程や製品の履歴を可視化することが可能となります。
具体的な目標としては、以下の課題の解決を目指しました:
-
製造工程や製品の履歴の可視化:
製造ライン上で発生するデータを収集し、グラフデータベースに蓄積することで、製造工程や製品の履歴を視覚的に把握することができます。 -
問題特定と解決の迅速化:
可視化された製造工程や製品の履歴を活用し、もし不具合が発生した場合には、その原因を特定し、問題解決を迅速に行うことが可能となります。 -
品質向上と製造プロセスの改善:
蓄積されたデータを分析し、製品の品質向上や製造プロセスの改善に役立てることができます。
製造ラインのトレーサビリティ情報管理にはグラフデータベースが有効だと確認できました。
製造現場では、品質問題や作業遅延などに対して迅速な対応が求められます。
問題の原因分析は蓄積された製造情報を活用して行うことが必要ですが、データベースの非専門家(管理者や作業者)がグラフデータベースを自在に活用することは容易ではありません。
その解決策として、非専門家でも容易にSurrealDBに蓄積された製造情報を検索できるようにするために、以下の機能を持ったチャットボットを実装しました。
-
大規模言語モデルを使用して日本語の質問文からグラフデータベースのクエリ(SurrealQL)を自動生成します。
-
生成されたクエリをSurrealDBで実行し結果を大規模言語モデルを使用して日本語回答文を生成します。
この記事では、日本語の質問文からグラフデータベースのクエリを生成する手順を中心に記述しています。
このチャットボットは不完全であり実用化には程遠いですが、非専門家がグラフデータベースを活用するためのヒントを与えてくれました。
なお、システム全体の詳しい説明と成果物は以下のgithub リポジトリを参照してください。
SurrealDBとは
この記事ではSurrealDBについては説明していません.
詳細な情報は、以下のサイトや記事を参考にしてください.
- SurrealDB is the ultimate cloud database for tomorrow's applications
- SurrealDB wants to be the future of SQL
- SurrealDB Internal design — Part 1 — Welcome to Wonderland
- SurrealDB Internal design — Part 2 — Architecture
- SurrealDB Internal design — Part 3— Into the Rabbit Hole with SurrealQL
- SurrealDB’s Sophisticated Storage Solution — SurrealDB Internals Part 4
仮想製造ライン
下図の非常に単純な仮想製造ラインを想定し、工場の要素である製造ライン、貯蔵庫をシミュレートするSimpyを使用したシミュレータを準備します。
シミュレータを実行し各製造ラインからの製造から発生する製造事象データをSurrealDBへグラフデータとして格納します。
- 仮想工場

設計したグラフデータモデル
「ノード」は物理的に存在する「物」と製造ラインで実行される「作業」を定義しました。
- ノード定義
ノード 説明 テーブル名 備考 工場 製品生産場所 FACTORY 製品仕様 製品仕様情報 SPECIFICATION 製造ライン 作業工程毎の生産ライン PRODUCTION_LINE 機器 生産ラインで使用する機器・センサー等 MACHINE 貯蔵庫 製品を保管する場所 STORAGE 製品 製造した物 PRODUCT 製品仕様 製品の仕様情報 SPECIFICATION 作業 製造ライン実施された作業情報 WORK 原材料 仕掛品を製造する原材料 RAW_MATERIAL 検査結果 検査作業の結果情報 INSPECTION_RESULT 欠陥情報 検出された欠陥情報 DEFECT_INFORMATION 作業班 製造ライン毎に割当てられる作業班 OPERATING_CREW 機器情報 機器・センサーからのログ MEASUREMENTS
「関係」はノード間の関係を洗い出し定義しました。
-
関係定義
関係 意味 補足 A->CONSISTS_OF->B AはBを構成要素として持つ A->EXECUTES->B A(製造ライン)はB(作業)を実行する A->STATRED_BY->B A(製品)へB(作業)を開始する A->ENDED_BY->B A(製品)へのB(作業)を終了する A->RECORDS->B AはBを記録する A->USED_TO_PRODUCE->B A(原材料)からB(製品)が生成される A->COMPRISED_OF->B A(製品)はB(部品)を持つ A->HAS_DEFECT->B A(製品)はB(欠陥情報)を持つ A->DEFECT_DETECTED_BY->B A(製品)はB(作業)で欠陥が検知された A<-TEST_RESULT_OF<-B A(検査情報)はB(製品)の検査結果である A->MOVE_FROM->B B(作業)がA(場所)から仕掛品を移動する A->MOVE_TO->B A(作業)がB(場所)へ仕掛品を移動する A->MOVED_BY->B A(仕掛品)がB(作業)によって移動される A->HAS_WORKERS->B A(製造ライン)はB(作業班)を持つ -
グラフデータモデル図

-
実際のグラフデータ

グラフデータベース利用の利点
グラフデータモデルが設計できたら、製造ラインで発生するさまざまなデータをSurrealDBに保存することは非常に簡単です.
ノードと関係の登録は軽量な処理であり、工場の現場で発生するデータをリアルタイムで登録することも可能です.
グラフデータモデルには固定のスキーマが存在しないため、製造ラインの更新や新しい製品の製造などが発生しても、既存の情報に影響を与えることなく新しい情報を追加できます.
また、後からノード間の関係を追加することも可能なため、製造ライン情報の管理は非常に柔軟に行えます.
製造工程や作業履歴などの可視化のためのデータ検索は、RDBを使用する場合と同様に適切なクエリを作成することで実現できます.
設計情報、受注情報、発注情報、在庫情報、製品出荷情報、顧客情報などをグラフデータとして登録し、関連付けすることで、製造ライン情報を幅広く活用することができます.
グラフデータベース利用の課題
品質問題や製造ラインの遅延などの原因分析には、グラフデータの検索機能を利用することができ、直感では分からない隠れた要因を発見する可能性があります.
原因分析には、探索的なグラフデータの検索が必要であり、複数のクエリ(SurrealQL)を作成する必要があります.
探索的な検索とは、事前に検索方法が決められない検索方法のことです。例えば、以下のような検索が探索的な検索の例です。
- ある仕掛品の欠陥発生率は、原材料製造会社の特定工場に依存する。
- ある仕掛品の欠陥発生率は、貯蔵庫へ移送した搬送車に依存する。
- ある仕掛品の欠陥発生率は、製造ラインの室温と外気温との差に依存する。
通常、RDBで探索的な検索を行う場合には、事前に検索対象となるデータを決め、スキーマを定義する必要があります。
しかし、現実的には原因分析において、事前にすべての可能性を予測することは難しいです。
一方、グラフデータベースでは、仕掛品を関係で結び付けるデータをすべて検索することができます。
これにより、様々な要素間の関係性を柔軟に探索することができます。
しかし、グラフデータベースのクエリを非専門家(管理者、作業者)が作成することは容易ではありません。
クエリの作成にはデータモデルの理解やクエリ言語の知識が必要となります。
解決策
大規模言語モデル(Large Language Models/LLM)とチャットボットを組み合わせることで、自然言語の問い合わせ文からクエリ(SurrealQL)を自動生成し、データベースからの検索結果を自然言語で回答する仕組みを実現しました。この仕組みによって、非専門家でも容易にグラフデータベースの検索を利用し、問題の原因分析を行うことができます。
以下のような手順で自然言語からクエリを生成する仕組みを実現する必要があります。
-
グラフデータベースにおける検索対象となるデータの特性や関係性を理解し、それに基づいて局所データを準備します。
例えば、製造ラインの情報や製品の作業履歴などのデータを準備します。 -
自然言語の問い合わせ文とそれに対するSurrealQLクエリの対応関係をプロンプトとして準備しておきます。
これにより、大規模言語モデル(LLM)は問い合わせ文から適切なSurrealQLクエリを生成する能力を獲得します。 -
ユーザーが自然言語で問い合わせ文を入力すると、チャットボットを介して大規模言語モデルによる自動生成が行われます。
モデルは問い合わせ文を解釈し、関連するデータや検索条件を特定し、それに基づいてSurrealQLクエリを生成します。 -
生成されたSurrealQLクエリはグラフデータベースへ送信され、検索が実行されます。
-
検索結果は再度自然言語に変換され、利用者に対して回答として提示されます。
実装
今回は解決策2~5を実装しました。
-
チャットボット画面
streamlit + streamlit-chat で実装されています。

-
処理フロー
チャットボットの日本語質問文を以下の処理フローで日本語回答を作成し、チャットボットへ表示してます。
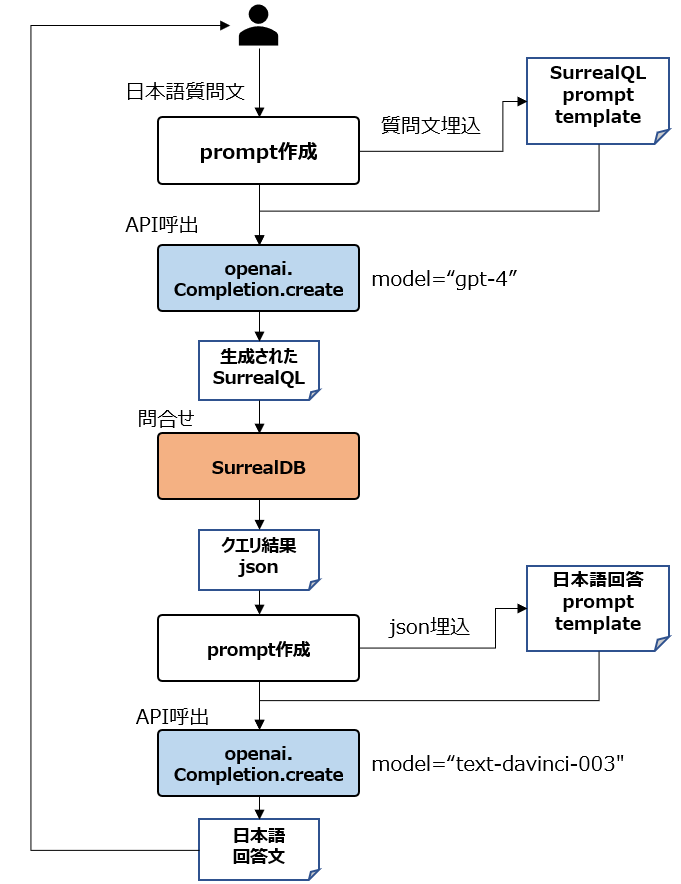
-
OpenAI API呼出
OpenAIのAPI呼出は非常に簡単です。
※コードの異常処理は適当にコーディングされています。
質問文はpayloadに格納されています。import openai def query4( payload: Any, prompt_lang='日本語' ) -> Any: """ OpenAI API GPT-4 による 日本語からSurrealQL生成 :param payload: 入力データ :param prompt_lang: プロンプトの言語指定 :return: GPTからの結果 """ messages = CONVERT_NL_TO_SURREALQL_MESSAGES_jp.copy() messages.append({ "role": "user", "content": payload.get("inputs", {}).get("text", "?") }) try: completions = openai.ChatCompletion.create( model="gpt-4", messages=messages, timeout=API_TIMEOUT, ) sql = completions.choices[0].message.content except (APIConnectionError, AuthenticationError) as e: print(f'{e}') sql = '' return { 'generated_text': sql, } -
SurrealQL用prompt
promptは、日本語質問文と対応するSurrealQLを約20ケース記述しています。
入力された質問文はpromptの最後の質問としてGPT-4へ渡されます。
以下はpromptの抜粋情報です。全てのコードはgithubリポジトリを参照してください。
※全体プロンプト参照role content system グラフデータベースへの問合せ言語を生成するアシスタントです. user 製品 product_id の作業が実行された製造ラインを取得する assistant SELECT ->STARTED_BY->WORK<-EXECUTES<-PRODUCTION_LINE AS production_line FROM PRODUCT WHERE id = "product_id" ; user 製品 product_id の作業が実行された製造ラインを取得する assistant SELECT ->ENDED_BY->WORK<-EXECUTES<-PRODUCTION_LINE AS production_line FROM PRODUCT WHERE id = "product_id"; user 製品の作業を取得する assistant SELECT ->STARTED_BY->WORK AS work as product FROM PRODUCT FETCH work ; user 製造ライン production_line_id で実行された製品 product_id の作業の開始時間,作業を取得する assistant SELECT id AS work_id, <-STARTED_BY.data.timestamp AS started_at FROM WORK WHERE <-STARTED_BY<-(PRODUCT WHERE id = "product_id" ) AND <-EXECUTES<-(PRODUCTION_LINE WHERE id = "production_line_id" ) FETCH started_at ; -
日本語回答prompt
{question} : 日本語質問文が埋め込まれます。
{result} : SurrealDBのクエリ結果jsonが埋め込まれます。ANALYZE_RESPONSE_PROMPT_jp = ( '私は高度に知的な質問・応答ボットである.' '質問とその質問の回答をJSONデータで与える.' 'JSONデータの回答を人間が理解できるテキストへ変換して回答しろ.\n' 'JSONデータが空の場合は、"該当する情報はありません"と回答しろ.\n' 'JSONデータの日付は日本時間へ変換しろ.\n' '{additional}\n' '質問:{question}\n' '回答:{result}\n' )
質問例
-
問合せ
欠陥情報を持つ製品IDを取得しろ -
生成されたSurrealQL
SELECT <-HAS_DEFECT<-PRODUCT.id AS product_id FROM DEFECT_INFORMATION SPLIT product_id ; -
回答
欠陥情報を持つ製品IDは、PRODUCT:S10010、PRODUCT:S10025、PRODUCT:S10004、 ... PRODUCT:P40001、PRODUCT:P40003です。 -
問合せ
製品ID=PRODUCT:S10004の欠陥を検出した作業IDと、作業開始時間、作業終了時間を取得しろ -
生成されたSurrealQL
SELECT id AS work_id, <-STARTED_BY.data.timestamp AS started_at, <-ENDED_BY.data.timestamp AS ended_at FROM WORK WHERE <-STARTED_BY<-(PRODUCT WHERE id = 'PRODUCT:S10004') AND ->RECORDS->DEFECT_INFORMATION<-HAS_DEFECT<-PRODUCT SPLIT work_id FETCH started_at, ended_at ; -
回答
作業ID:WORK:wpl00200039、作業開始時間:2023年1月1日 1時15分、作業終了時間:2023年1月1日 1時31分 -
問合せ
作業ID = "WORK:wpl00200039"が実行された製造ラインIDを取得しろ -
生成されたSurrealQL
SELECT id AS production_line_id FROM PRODUCTION_LINE WHERE ->EXECUTES->(WORK WHERE id = 'WORK:wpl00200039') ; -
回答
作業ID「WORK:wpl00200039」は製造ラインID「PRODUCTION_LINE:pl002」で実行されたものです。
問合せがうまくいかない例
以下の例は質問文が不完全だったり、GPT-4が正しいSurrealQL構文を知らないために発生しているダメな例です。
これらの対策としては、チャットボットが質問者の目的を理解して不足する情報を問合せ、利用者が情報を追加できる仕組みが必要でしょう。
-
質問文
2023年1月1日 00:00から 05:00までに検出された欠陥情報IDを取得しろ -
ダメなSurrealQL
DEFECT_INFORMATIONはtimestamp情報を持っていないので以下のクエリは何も検索しません。
欠陥を検知した時間は「作業」に紐づくので質問文には「作業」を含ませる必要があります。SELECT id AS defect_id FROM DEFECT_INFORMATION WHERE data.timestamp >= '2023-01-01T00:00:00' AND data.timestamp <= '2023-01-01T05:00:00' FETCH defect_id ; -
質問文を変えてみる
作業が実行された2023年1月1日 00:00から 05:00の間に検知された欠陥情報IDを取得しろ。 -
ダメなsurrealQL
SurrealQL には BETWEENがないのに...SELECT id AS defect_id FROM DEFECT_INFORMATION WHERE ->RECORDS->WORK.data.timestamp BETWEEN "2023-01-01T00:00:00" AND "2023-01-01T05:00:00" FETCH defect_id ; -
質問文を変えてみる
作業が実行された2023年1月1日 00:00から 05:00の間に検知された欠陥情報IDを取得しろ。 BETWEEN は使用しないこと。 -
ダメなSurrealDB
作業開始時間の条件記述間違っています。
正しくは、以下のように記述する必要があります。
(->RECORDS<-WORK<-(STARTED_BY WHERE data.timestamp > '2023-01-01T00:00:00Z'))SELECT id AS defect_id FROM DEFECT_INFORMATION WHERE (->RECORDS<-WORK<-STARTED_BY.data.timestamp > '2023-01-01T00:00:00Z') AND (->RECORDS<-WORK<-STARTED_BY.data.timestamp < '2023-01-01T05:00:00Z') FETCH defect_id ; -
質問文へ時間条件の記述方法を教える
作業が実行された2023年1月1日 00:00から 05:00の間に検知された欠陥情報IDを取得しろ。 BETWEEN は使用しないこと。 開始時間の検索は(<-RECORDS<-WORK<-(STARTED_BY WHERE data.timestamp 'operator' 'time')) を使用する -
正解のSurrealDB
SELECT id AS defect_id FROM DEFECT_INFORMATION WHERE <-RECORDS<-WORK<-(STARTED_BY WHERE data.timestamp > '2023-01-01T00:00:00Z') AND <-RECORDS<-WORK<-(STARTED_BY WHERE data.timestamp < '2023-01-01T05:00:00Z'); -
回答文
2023年1月1日 00:00から05:00の間に検知された欠陥情報IDは、 DEFECT_INFORMATION:dfm00000069、DEFECT_INFORMATION:dfm00000110、 DEFECT_INFORMATION:dfm00000228、DEFECT_INFORMATION:dfm00000393です。
まとめ
今回の大規模言語モデルを使用して自然言語からクエリを生成する仕組みは、シンプルなプロンプトを用いています。そのため、生成されるクエリの精度は問い合わせ文の品質に大きく依存します。このようなシンプルなプロンプトでも、一定の精度でクエリを生成することができることがわかりました。
ただし、今回の方法ではOpenAI APIの使用token数が2K tokens/API呼出を超えるため、OpenAI APIの利用コストが非常に高額(約6円/API)になるので実用的とは言えないです。
クエリ生成の精度を向上させるためには、グラフデータモデル情報を局所データとして蓄積し、LangChainなどのフロー制御を使用してそのデータを活用することが考えられます。これにより、モデルの生成能力やクエリの精度を向上させることができると期待されます。
正確なクエリを生成するためには、利用者が明確かつ具体的な問いを行うことが重要です。そのため、利用者に適切な問いかけを行い、情報の具体化や追加情報の提供を促すことが重要です。
例えば、特定の製品や製造ライン、日時範囲などの具体的な条件を問い合わせ文に含めることで、より的確なクエリが生成されます。
さらに、グラフデータベースのクエリ生成や検索結果の可視化、洞察の抽出を支援するツールやダッシュボードを実装することも効果的です。これにより、利用者は直感的にデータを探索し、原因分析に役立つ情報を容易に得ることができると考えます。
今後の取り組み
-
チャットボットの高度化
利用者との会話による質問文の精度を向上させる仕組み。
検索結果の可視化(グラフ、表等)。 -
製造ライン情報のナレッジグラフ化と活用
製造ラインに関連する設計情報、作業履歴、センサーデータ、品質データ等をナレッジグラフとしてSurrealDBで管理する。
ナレッジグラフはクエリ生成時の局所データとして活用する。 -
グラフデータモデルの自動生成
製造ライン情報と製造ラインデータを形式的言語(RDF1やOWL2)で定義し、大規模言語モデルを使用してグラフデータモデルを自動生成する。