今回はGithubでAAMのライブラリを発見したためFittingまでを行ってみました.
内容
- AAMとは
- AAMのライブラリについて
- 学習画像の選定
- AAMの作成とFitting
- 考察と問題点
1.AAMとは
Active Appearance Models は顔画像のモデル化に用いられる合成モデルである.オブジェクトに付与された形状情報とそれによって形成されるメッシュ内の輝度情報を学習データとしてモデル化を行う.モデル化により得たパラメータ(Appearanceパラメータ)が元の形状,輝度情報を表現できていることから,その顔画像の特徴量として用いられる.また,ある顔画像の輝度情報とAAMをもちいて合成された輝度情報の差を最少にするように勾配法などを用いて最適化を行うことで,その顔画像を表現するアピアランスパラメータを得ることができ,その顔画像を表す特徴量となる.この動作をFittingと呼ぶ.また,その際に合成される形状情報は,その顔画像の特徴点となる.今回はAAMのライブラリを用いてFittingを行う.
2.AAMのライブラリについて
AAMLibrary
今回Githubで発見した.ライブラリは名前もそのままでAAMLibrary といいます.以下リンクを張っておきます.
https://github.com/greatyao/aamlibrary
AAMではモデルの作成とFittingが主な処理になっているのですが,このライブラリはサンプルとしてこの二つの処理の単純な実装を行っています.後はsampleフォルダを参照してください.
ここでは,以下sampleの実行を行っていきたいと思います.まず初めに行うことはモデルの作成です.そこで,sampleフォルダのrun-build.batを実行します.しかし,ここで問題が発生します.学習画像ファイルがありません.ということで学習画像の選定をまず行わなければいけません.
3.学習画像の選定
AAMを作成する際には学習データとして,顔画像と特徴点情報が必要になります.この特徴点情報を学習することで未知画像の特徴点を得ることができるのです.そこで学習データとしてもこの二つが必要になります.インターネットで学習データを探すとBioID Face Databaseというデータベースが見つかりましたので今回はこれを使うことにしました.
このデータベースでは,顔画像,目の位置情報,特徴点情報の三つのデータを得ることができます.
学習画像は右側のBioID-FaceDatabase-V1.2.zip (124 MB)をクリックすることで得ることができます.このファイルには顔画像と目の位置を収録したファイルが1521個ずつ収録されています.また,特徴点の情報はFGnet Markup Scheme (500 KB)をクリックすることで得ることができます.これらはファイル名に通し番号が付与されていてその番号毎に顔画像が分かれているようです.ここで得た学習画像と特徴点情報を実際の学習データとして使います.
4.AAMの作成とFitting
モデル(AAM)の生成
AAMLibraryのsampleであるrun-build.batは以下のように記述されていました.
build -t 0 -p 2 ../image jpg pts haarcascade_frontalface_alt2.xml my.amf
pause
これはimageファイル内の学習データを用いるという意味です.また画像ファイルはjpg,そして特徴点ファイルはpts形式でなくてはいけません.BioID Face Databaseは奇跡的に特徴点情報がptsファイルで提供されているのでそのまま用いることができます.しかし,画像はpgmファイルなのでjpgへの変換しなくてはいけませんでした.変換は何でもよいのですがIrfanViewが楽でしたのでお勧めします.これで画像データができたので実行してみましょう.実行後はAAMデータとしてmy.amfファイルが出力されます.
*「image」フォルダは「example」フォルダと同じ階層に作製してください
- BioIDから取得したptsファイルには「bioid_1140a.pts」というファイルが存在してます.これがあると誤動作をするので消去しておくことをお勧めします.
Fitting
Fittingでは実際の顔画像にAAMのモデルを適応させ,顔画像の特徴量の取得を行います.AAMLibraryのサンプルではFittingにより得た特徴量を用いて合成された顔画像を張り付けた画像を出力していました.では,run-fit.batの中身を見てみましょう.
fit my.amf haarcascade_frontalface_alt2.xml test.jpg
pause
これは,my.amfに記述されているモデル情報用いてtest.jpgの顔画像のFittingを行うという意味です.ここでtest.jpgは学習データ同様白黒にしてあります.結果は以下のようになりました.
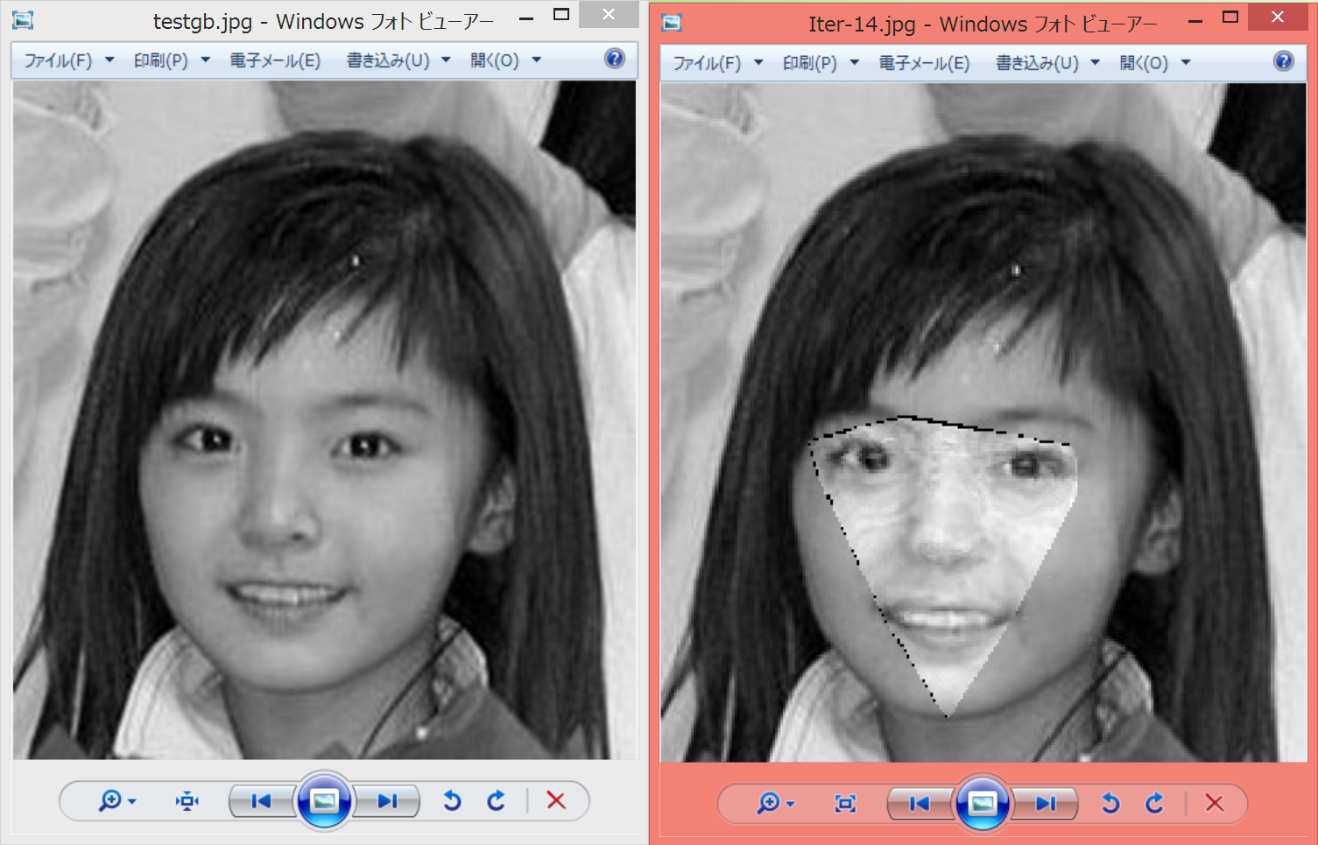
左が元の画像で右がFitting後の画像です.見るに堪えない感じになっていますがこれが現実です.AAMでは輝度モデルの合成が弱点となっています.ですが,鼻や目,口の位置などがぼんやりととれていることが分かります.これは形状情報は正確にとれているということです.つまりは画像の輝度情報のみから顔画像の形状情報が取れているということです.
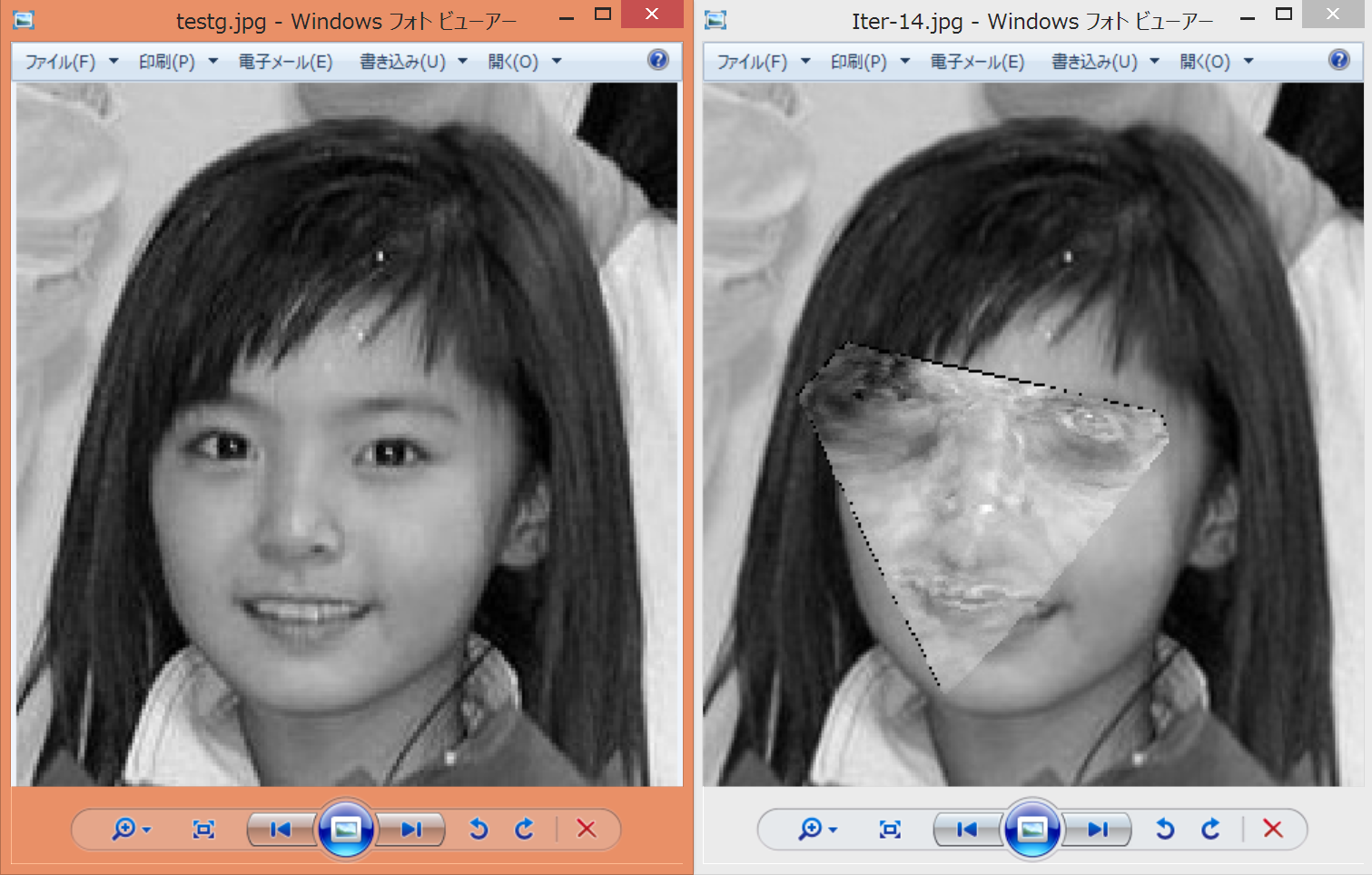
ちなみに解像度を低くすること以下のようにFittingが失敗してしまいました.画像の解像度は学習画像とテスト画像で合わせた方が良いようですね.
5.考察と問題点
今回の実験ではAAMのライブラリが実際に使えることが示された.実際に外部のライブラリを触ってみると学習が速く,Fittingも思ったより高速にできるということを再確認させられた.今後の自分のAAMの実装に生かそうと感じた.今回用いたライブラリは2Dの初めて提案された手法とRevisitedと呼ばれるLucas-Kanade法を用いた高速化手法の二つが実装されておりどちらも実行することができる.Revisitedは実装が比較的複雑であるため敬遠されがちであるのでぜひこの機に使ってみてほしい.問題点としては先ほども記述した通り輝度モデルの表現力である.輝度モデルは学習画像の輝度情報を用いているため高次元のデータとなるそのため学習データ数が少量の場合は今回のように表現力不足が生じる.よって学習データが大量に必要となるが手動で特徴付けされる学習データは大量に作り出す場合相当な労力となる.また,今回は2DAAMであったため,顔画像の傾きやオクルージョンにロバストではない.よって,3DAAMへの拡張が必要になる.まあ,これが自分の研究なんだけどね,以上