夏休みなので,ディープニューラルネットワークで音源分離の学習と実行をおこなうプログラムの実装を行いました.
できるだけ誰でも利用できるように,Google Colaboratory上でDNNの学習が行えるようにしてあります.
End-to-End音源分離
話者Aの音声と話者Bの音声が混合された信号A+Bから,元のAとBを分離するような技術を音源分離といいます.音声は長らく波形をフーリエ変換して得られるスペクトログラムを特徴量として分析されてきていました.しかし,近年,混合信号の波形から分離信号の波形を直接推定するような手法が考案されており,特にEnd-to-End(E2E)音源分離などと呼ばれます.
Dual-path RNN TasNet
End-to-End音源分離のディープラーニングを使った手法の一つとしてDual-path RNN TasNetと呼ばれるものがあります.
Dual-path RNN TasNetはEncoder, Separator, Decoderの3つの部分からなります.
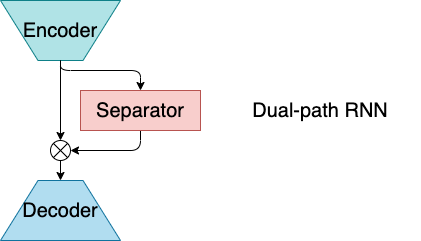
Encoderは波形から潜在空間へのマッピングを,Decoderは潜在空間から波形へのマッピングをおこないます.Separatorはマッピングされた潜在空間内の特徴量を音源ごとにマスキングして分離する処理をします.Encoder-Separator-Decoderの構成によるDNNによるE2E音源分離はこれまでにも発表されていたのですが,特にDual-path RNN TasNetではSeparator部分にDual-path RNNというモジュールを使用しています.Dual-path RNNはRNNを大域的な時間軸と局所的な時間軸のそれぞれの方向に走らせるネットワークです.これにより少ないパラメータ数でDNNの受容野を拡大することができ,高品質な音源分離を実現しています.
必要なもの
- Googleアカウント(Google Colaboratoryを利用するため)
- 時間(DNNの学習に時間がかかるため)
- 友人(混合音声を作るため)
- MacのPC
実行方法
Githubのリンクはこちらです.
DNNの学習はGoogle Colaboratory上のnotebookで,実際の分離はPC上で実行していきます.
1.DNNの学習
1.1. 前準備
コードを一式持ってきて,必要なライブラリをダウンロードします.
!git clone https://github.com/tky1117/DNN-based_source_separation.git
!pip install soundfile
Google driveにDNNのモデルのデータを残したい場合は,マウントしましょう.
from google.colab import drive
drive.mount("/content/drive")
今回はLibriSpeechという音声のデータセットを使います.
以下を実行することで,2話者の混合音声のデータセットを作成します.
%cd "/content/DNN-based_source_separation/egs/librispeech/common"
!. ./prepare.sh "../../../dataset" 2 # 2 is number of speakers
1.2. DNNの学習
では,作業ディレクトリに移動して,音源分離の学習を行います.
とはいえ,train.shを走らせるだけです.深層学習ライブラリはPyTorchを使用しています.
Dual-path RNN TasNetにはいくつかのハイパーパラメータが存在しますが,Google Colaboratoryの時間制約のために,デフォルトの設定では元の論文よりもモデルのサイズが小さくなっています.
%cd "/content/DNN-based_source_separation/egs/librispeech/dprnn_tasnet"
!. ./train.sh <OUT_DIR>
<OUT_DIR>下にモデルなどが保存されます.ディレクトリ名はハイパーパラメータを元に決定しているため,かなり長くなっているかと思います.デフォルトの設定のままでは,
<OUT_DIR>/2mix/trainable-trainable/sisdr/N64_L16_H256_K100_P50_B3/enc-relu_dilated1_separable1_causal0_norm1_mask-sigmoid/b4_e100_adam-lr1e-3-decay0_clip5/seed111/model/
というディレクトリにbest.pthとlast.pthとしてモデルが保存されています.best.pthは検証データのロスが最大であったエポックのモデルで,last.pthは学習の最後のエポックのモデルです.
12時間の時間制限がきてしまった場合,再び,
%cd "/content/DNN-based_source_separation/egs/librispeech/dprnn_tasnet"
!. ./train.sh <OUT_DIR> <MODEL_PATH>
とすることで,学習を続きから再開させることができます.
<MODEL_PATH>についても,デフォルトの設定では
<OUT_DIR>/2mix/trainable-trainable/sisdr/N64_L16_H256_K100_P50_B3/enc-relu_dilated1_separable1_causal0_norm1_mask-sigmoid/b4_e100_adam-lr1e-3-decay0_clip5/seed111/model/last.pth
になります.
ただし,ロスが5エポック連続して減少しなかった場合,DNNの学習を早期終了するようになっています.そのため,それ以上学習は進行しません.
2. PC上で音源分離の実行
Google Colaboratory上での学習が終わってから,実機上で音源分離を行なってみます.MacのPCを想定しています.
ここからは,ターミナル上での入力を示していきます.なお,Google Colaboratory上ではsoundfile追加するだけで動きますが(2020/9/4現在),ローカルに関しては別途必要なライブラリをインストールする必要があります.特に,pytorchのバージョンなどはGoogle Colaboratoryの環境に依存しています.
2.1. 前準備
まず,コードを一式ダウンロードして,作業ディレクトリまで移動します.
git clone https://github.com/tky1117/DNN-based_source_separation.git
cd "<WORK_DIR>/DNN-based_source_separation/egs/librispeech/dprnn_tasnet"
作業ディレクトリ下に学習済みのモデルを配置します.ここまで全てデフォルトの設定でおこなっていれば,
<WORK_DIR>/DNN-based_source_separation/egs/librispeech/dprnn_tasnet/exp/2mix/trainable-trainable/sisdr/N64_L16_H256_K100_P50_B3/enc-relu_dilated1_separable1_causal0_norm1_mask-sigmoid/b4_e100_adam-lr1e-3-decay0_clip5/seed111/model/
の下に,best.pthを配置することになります.
実際に音声を録音して分離するために,1.2.で指定した話者数分の人を用意しましょう.
2.2. 音声の分離と実行
前準備が終了したら,あとは実行するだけです.
. ./demo.sh
で5秒間の録音が開始します.適切に動作していれば,"Now recording..."の文字とともに,プログレスバーが表示されます.
録音が終了すると,DNNによる分離が開始されます.録音結果と分離結果は
<WORK_DIR>/DNN-based_source_separation/egs/librispeech/dprnn_tasnet/results
下にwavファイルとして保存されています.
まとめ
End-to-Endシングルチャネル音源分離の一つである,Dual-path RNN TasNetの学習と分離をおこなうプログラムを作成しました.おそらく学習には,12時間×4ぐらいは必要になると思います.雑音の少ない環境であれば,実機上でもそこそこ動くかと思います.Dual-path RNN TasNet以外のネットワークも実装してあるので,よかったらどうぞ.
更新履歴
- 2020/09/17 Githubのリンク先に学習済みのモデルを追加しました.
- 2021/1/28 DPRNN-TasNetの構造を修正しました.