前回までの記事
はじめに
今回は「2.5」と題して前回記事で予告してた内容ではなく、ちょっとしたポイントをコラム的な形で書いていこうと思っています。
内容を端的にいうと「sourceに対してdescriptionが記載できない」ことへの対処法としてステージング層を採用している話です。
dbtのdescriptionとは?
dbtではymlファイルにテーブルに対するdescriptionやカラムに関するdescriptionを記述することができます。description以外にもテストの設定やタグ付けなども行うことができます。
記載したdescription等はdbtが提供している機能のdocumentationから確認できます。
documentationの詳細に関しては下記をご覧ください。
具体的にはdbt docs generateを行うとweb用のファイルが生成され、dbt docs serveを行うとlocalhostでwebが立ち上がってそこからdocumentationが確認できます。
※tdでdbt docs generateを実行すると下記エラーが発生しますが、関連ファイルのgenerateはできているようです。(このエラーが後述のsourceにdescriptionできない原因な気がしております。
21:04:30 Encountered an error while generating catalog: Database Error
TrinoUserError(type=USER_ERROR, name=PERMISSION_DENIED, message="Access Denied: Cannot select from table metadata.table_comments", query_id=20240725_210429_32750_9mcd8)
21:04:30 Encountered an error while generating catalog: Database Error
TrinoUserError(type=USER_ERROR, name=PERMISSION_DENIED, message="Access Denied: Cannot select from table metadata.table_comments", query_id=20240725_210429_32751_9mcd8)
21:04:30 dbt encountered 2 failures while writing the catalog
このdocumentationを見ていただくと、ちゃんとdescriptionを書いて整備すればテーブルの定義も確認できるしリネージュも確認できるしでデータカタログとして非常に優秀なことがわかるかと思います。
このdocumentationをローカルだけで見れる状態からwebページとして社内に公開する方法は先ほどのページの最後に記載されています。
我々の運用では上記に記載のS3の静的ホスティングを採用しています(簡単なユーザー認証としてcloudfrontも使っていますが本筋と外れるので割愛)。
documentationはプルリクがマージされたタイミングが更新タイミングなので、そのタイミングでdbt docs generateを実施して生成されたファイルをS3に保存するgithub actions workflowを実行することで最新化される運用を採用しています。
tdではsourceにdescriptionを記載できない
ここまでdescriptionについて説明してきましたが、下記によるとmodelだけでなくsourceについても同様にdescriptionの記述ができることになっています。
ここでsourceについて説明を入れておこうと思います。端的にいうと「ELTのEされたテーブルを参照するときに使う」になるかと思います。もう少し噛み砕いて説明すると、dbt_project内でsqlを記載しているテーブルはrefを使って参照するわけですが、一番上流まで戻ると、dbt内で生成していないtdに流し込まれたテーブルに辿り着き、それらはsourceを使って参照することになっています(dbt初めての人に説明する最初のハードルがsourceだと思っている程度にいまだに説明の仕方の正解がわかっていない)。
私は最初の頃ref参照はdbtの実行順番を管理する上で必要なのはわかるが、sourceに関しては直書きでいいのでは?と思っていましたが、sourceを使う利点として先ほどのページでは、
- リネージュとしてみれるよ
- testかけるよ
- freshness計算できるよ
と書かれており、一つ目のリネージュで確認できる件に関しては実行が失敗した時の原因究明で特に重宝します(突然発生する dbt buildの失敗に関しては基本的にEの問題だから)。
ということでdbtの様式に従ってsourceを使っていくわけですが、せっかくsourceを使うならdescriptionを記載して、td上のすべてのテーブルに関して網羅的にdocumentationで定義を確認できるようにしたくなると思います。
ということで公式の書き方に従ってsourceにdescriptionを記載するわけですが、tdの場合documentationに反映されません(おそらく前述のエラーが関係)。
ということでsourceに記載することは諦めて別の方策を考えていきます。
解決策:ステージングテーブルにdescriptionを記載する
シンプルではあるのですが、解決策としてsourceに記載できないならrefを経由すればいいということで、ステージングテーブルを導入してそこに記載することにしました。
ステージングテーブルとは下記のようにdbt公式のベストプラクティスにも書かれている概念で、端的にいうとETLではTでやるべきだった前処理をやるためのテーブルになります。
ステージングテーブルがないと、例えばとあるsourceを参照しているテーブルが複数あったときにすべてで同じ前処理が記載されてしまいます。最悪なケースだと参照しているそれぞれのテーブルで独自で考えたオレオレ前処理が発生します。
これらを防いでかつ前処理以外の本質的なクエリ部分に集中することができるため、ステージングテーブルを導入するメリットは大きいかと思います。
tdの場合このメリットにdescriptionをかけるというメリットが加わわるためより一層やる意義が出てきます。
ステージングテーブルはjoinやgroup byを使わないという原則があるため、基本的にsourceの情報は保持しており、sourceにdescriptionを記載する効果を兼ねています。
具体実装例
ここから具体的なステージングテーブルの実装例について解説していきます。
記載しているファイル以外は前回のファイルと同様なので割愛しております。
まず関連ファイルを列挙していきます。
_dbt/models/source.yml
version: 2
sources:
- name: test_dataset_z
database: td-presto
tables:
- name: seed_sample
こちらはsorceを定義しているymlファイルになります。
(新しくテーブル考えるの面倒だったので)前回seedから作成したテーブルを参照する形にしています。
ここからステージングテーブルを作るわけですが、dbt_power_userを使っていると下記のような形で「Generate model」というボタンが出てきます。
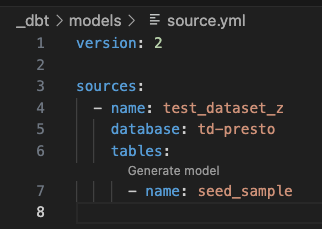
ボタンを押すと、下記のようなステージングテーブルの雛形のファイルが自動生成されます(とても便利)。
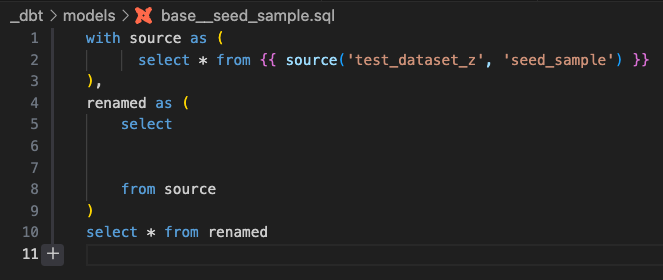
あとは6行目のところに前処理後のカラムを追加してパスを移動させれば完成です。
ちなみに生成されるファイルの名前は下記のvscodeの設定から変更することが可能です。
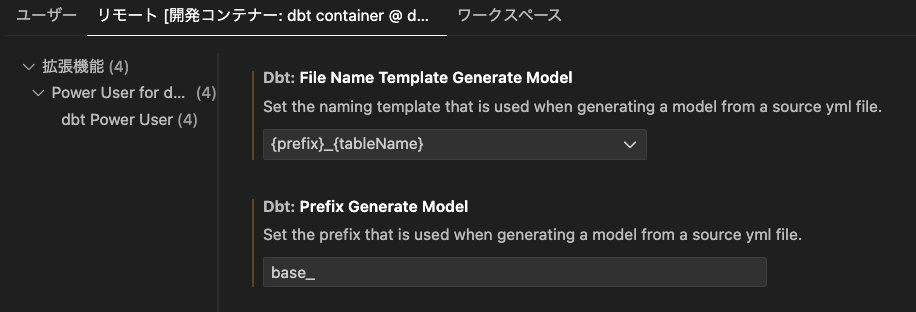
※devcontainer.jsonのsettingsに下記の設定を記載することでコンテナ生成時に設定を反映することもできます。
"dbt.fileNameTemplateGenerateModel": "{prefix}_{tableName}",
"dbt.prefixGenerateModel": "base_",
なぜベストプラクティスのstgというprefixを使っていないかというと、社内レビューでステージングという言い方は開発のステージング環境と混同するからという理由で、旧来の呼び方のbaseをprefixとして採用したという裏話があります。
また、ベストプラクティスではデータセット名__テーブル名のような形でデータセット名を入れることを推奨されていますが、データセット名入れると毎度記載するのが大変になるので、他データセットと被りが発生しない限りはデータセット名はつけない運用にしています(被りがあったらbase_データセット名__テーブル名のようにしている)。
最終的なステージングテーブルは例えば以下のようになります。
_dbt/base/test_dataset_z/base__seed_sample.sql
with source as (
select * from {{ source('test_dataset_z', 'seed_sample') }}
),
renamed as (
select
*,
substr(datetime, 1, 10) as date
from source
)
select * from renamed
ステージングテーブルに関してはbaseというフォルダを用意してその配下にデータセットのフォルダを作ってその配下に格納しています。
クエリを見ていただくと分かるとおり、前処理としてdatetimeからdateカラムを生成しています。
これでステージングテーブルはできているのですが、大きなテーブルになってくると流石にこのテーブルをテーブルとして実体化するのは運用上コスパが悪いというのは想像に難くないと思います。
ベストプラクティスとしてはviewを使うのですが、tdではviewを作れないので代わりにephemeralというマテリアライズ方法を使用することにします。
(ephemeralってなんぞやは一旦置いておいて)ephemeralにする方法は簡単で、dbt_project.ymlでbaseフォルダ配下に関してephemeralにするという設定を入れるだけです。
_dbt/dbt_project.yml
name: "_dbt"
version: "1.0.0"
config-version: 2
profile: "_dbt"
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target"
clean-targets:
- "target"
- "dbt_packages"
# 数字始まりの DB やテーブル名をクォートする
quoting:
identifier: true
schema: true
models:
_dbt:
database: '"td-presto"'
materialized: table
dataset_a:
+schema: "{{ 'test_dataset_a' if target.name != 'prod' else 'dataset_a' }}"
delete_and_create:
pre-hook:
- DROP TABLE IF EXISTS "{{ this.schema }}"."{{ this.table }}__dbt_tmp"
- DROP TABLE IF EXISTS "{{ this.schema }}"."{{ this.table }}"
append_diff:
pre-hook:
- '{{pre_hook_append_diff()}}'
post-hook:
- 'INSERT INTO {{ this }} SELECT * FROM "{{ this.schema }}".tmp__{{ this.table }}'
- 'DROP TABLE IF EXISTS "{{ this.schema }}".tmp__{{ this.table }}'
dataset_b:
+schema: "{{ 'test_dataset_b' if target.name != 'prod' else 'dataset_b' }}"
delete_and_create:
pre-hook:
- DROP TABLE IF EXISTS "{{ this.schema }}"."{{ this.table }}__dbt_tmp"
- DROP TABLE IF EXISTS "{{ this.schema }}"."{{ this.table }}"
append_diff:
pre-hook:
- '{{pre_hook_append_diff()}}'
post-hook:
- 'INSERT INTO {{ this }} SELECT * FROM "{{ this.schema }}".tmp__{{ this.table }}'
- 'DROP TABLE IF EXISTS "{{ this.schema }}".tmp__{{ this.table }}'
base:
materialized: ephemeral
ephemeralに関しては具体動作を確認していただければ、イメージつきやすいと思うので、下記のようにステージングテーブルを参照させてみます。
_dbt/models/dataset_a/delete_and_create/delete_and_create_sample_2.sql
select user_id, min(datetime) as min_datetime
from {{ ref('base__seed_sample') }}
group by 1
上記をコンパイルすると下記のようになります。
with __dbt__cte__base__seed_sample as (
with source as (
select * from td-presto.test_dataset_z.seed_sample
),
renamed as (
select
*,
substr(datetime, 1, 10) as date
from source
)
select * from renamed
)select user_id, min(datetime) as min_datetime
from __dbt__cte__base__seed_sample
group by 1
ご覧いただくと一目瞭然かと思いますが、ephemeralは参照先のクエリの中でwith句として呼び出されます。
これによって過剰なテーブル化をせずにステージングの良さを活かすことができます。
また、with句経由で呼び出した際も直接呼び出した時と同様にtime partitionが適応されるので、その点も問題ありません。
最後に本題であるdescriptionを記載する作業をしていきたいと思います。
ここでもdbt-power-userがいい仕事をしてくれます。
delete_and_create_sample_2.sqlをdbt buildしてテーブルを生成した後で、
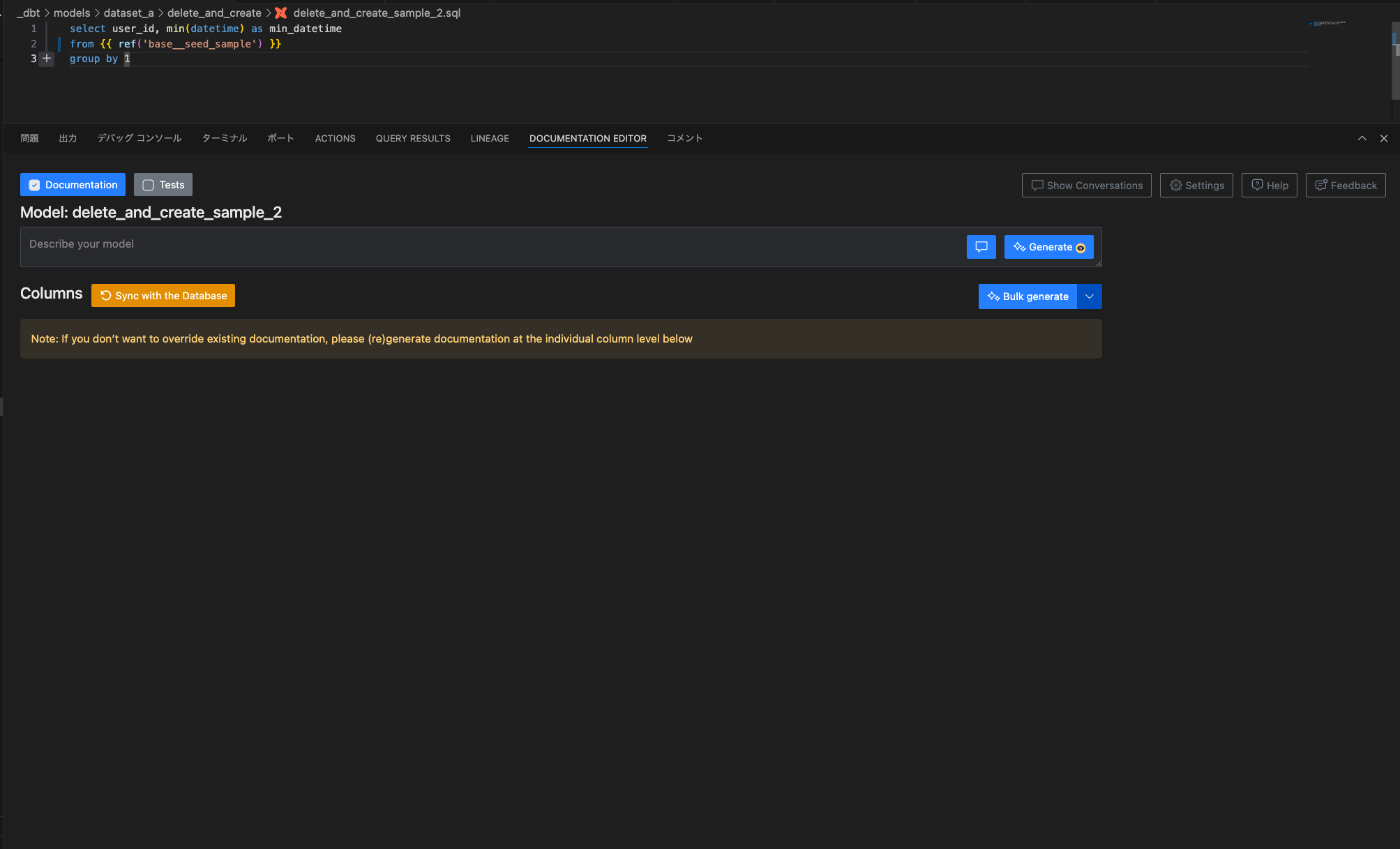
上記の「DOCUMENTATION EDITOR」タブの「Sync with the Database」を押下すると、
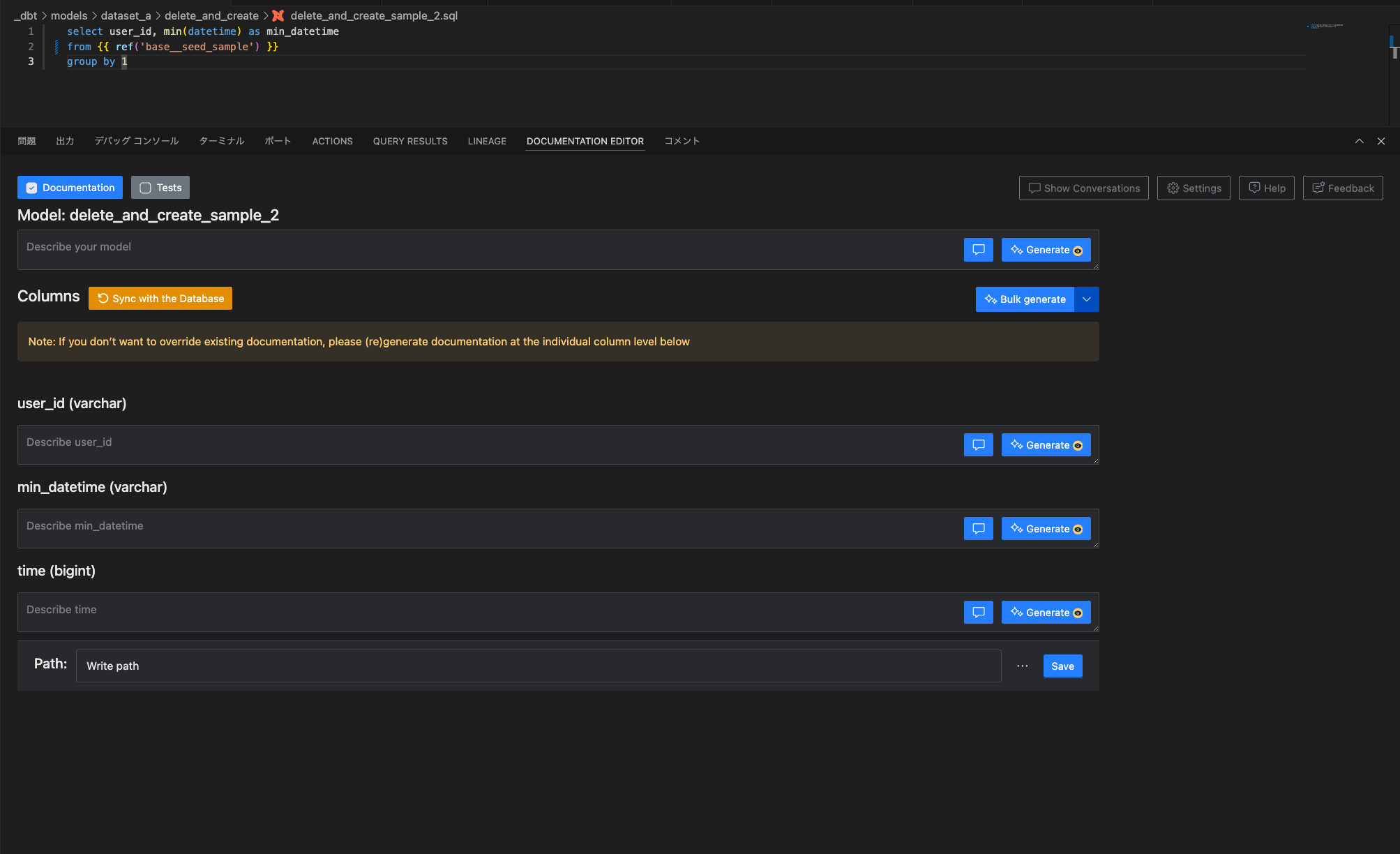
テーブルのカラムが自動で連携されます。テーブルとカラムそれぞれにdescriptionを入力して「Save」を押してymlファイルのパス(既存ファイルへの書き込みも新規ファイルの作成も可能)を入力すれば、下記のようなフォーマットに沿ったymlファイルが生成できます。
※新規作成の場合は1行目にversionを補完しないとerrorになるので注意
_dbt/models/dataset_a/_dataset_a__models.yml
version: 2
models:
- name: delete_and_create_sample_2
description: delete_and_create_sample_2のdescriptionです。
columns:
- name: user_id
description: ユーザーID
data_type: varchar
- name: min_datetime
description: 最初の購入時刻
data_type: varchar
- name: time
description: レコードの生成時刻
data_type: bigint
カラムの多いテーブルが2,3個あるとカラム名をいちいち入力するのが大変なのでdescriptionだけ書けばいいのはとても便利です。
ここまででお気づきになった方もいるかもしれませんが、ステージングテーブルをephemeralにするとテーブルが生成されないため、上記のようなdbt-power-userのdescriptionの入力サポートが受けられません(どうしてもやりたければ一度テーブル化してからephemeralにする方法がないことはない)。
ということでおとなしくymlに入力します。
_dbt/models/base/_base__models.yml
version: 2
models:
- name: base__seed_sample
description: staging_tableのdescription
columns:
- name: time
description: datetimeのunixtime
data_type: bigint
- name: user_id
description: ユーザーID
data_type: varchar
- name: payment
description: 支払い金額
data_type: bigint
- name: datetime
description: 日時
data_type: varchar
- name: date
description: 日
data_type: varchar
description用のymlファイルの分け方に関してはテーブルの個数次第で実運用の際にテーブルが探しやすい単位が良いと思っています。
もともとは公式の例にあるような一つのschema.ymlで全てのテーブルのdescriptionを管理していたのですが、テーブルが増えてきたので現在はデータセットごとのyml+ステージングはまとめて一つのymlで管理しています(そろそろステージングも分割するかも)。
実際にdbt docs generate&dbt docs serveしてみたいと思います。
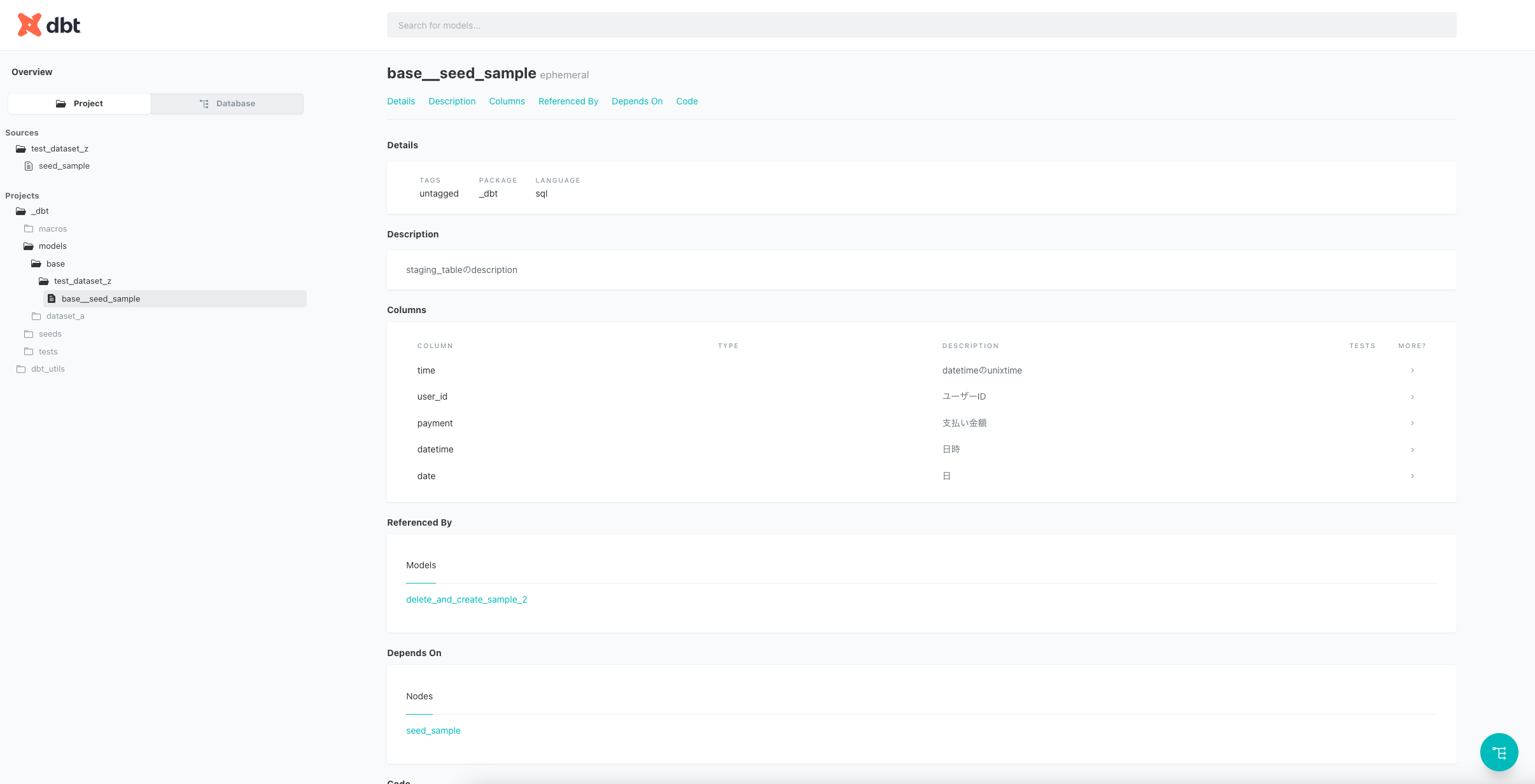
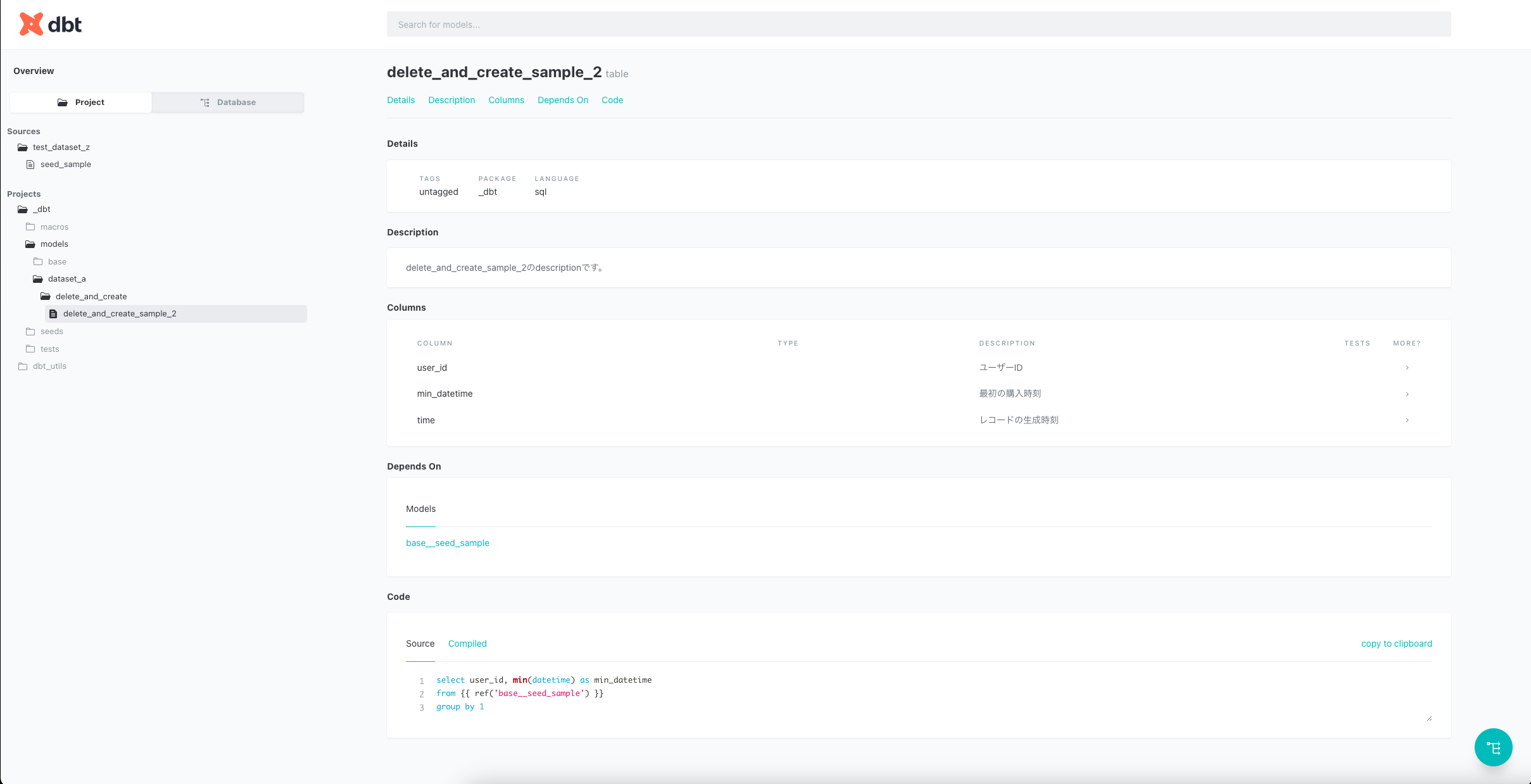
ちゃんとdescriptionが記載されていることが確認できます。
終わりに
今回はdescriptionを記載するために、ベストプラクティスのステージングテーブルを活用することとそれらをdbt-power-userを使って可能な限り楽して実装する方法を紹介させていただきました。
次回は前回の予告通りの内容の記事を書こうと思います。