はじめに
何をしたのか
NormalizeNumexpと呼ばれる数量表現や時間表現の抽出・正規化を行うOSSの実装をすべてPythonで実装しました。
Python3.7~3.10で動きます。
GitHub:https://github.com/tkscode/pyNormalizeNumExp
PyPI:https://pypi.org/project/pynormalizenumexp/
何が嬉しいのか
Pythonで使う際にpipコマンドで一発でインストールできるようになりました。
本家はC++で実装されており、Pythonで利用する場合は
といった手順を踏みますが
- コードが古いため1.~2.でエラーが頻発し、インストールに時間が非常にかかる
- 前提としているPythonのバージョンがEOLを迎えている2.X系である
- 3.Xでも動くことは動くが将来的にエラーや予期せぬ挙動などのトラブルに繋がる可能性がある
- 依存ライブラリのバージョンを間違えるとPython版が動かない
ということで、利用するまでの道のりが長いのでPythonで全部実装することにしました。
(本家の方にプルリク出せば良いというのはあるのですが、長年メンテされてない&個人的にがっつりコードを書きたい気分だったのでゼロからPythonで実装しました)
NormalizeNumexpとは
- 以下の例のようなイメージでテキスト中にある数量・時間表現を単位情報とともに抽出し、その表記や値を統一するツールです。
- これらの表現は書き手によって揺れるため、抽出するには頑張って正規表現などを用意する必要がありますが、NormalizeNumexpではそれらの揺らぎもある程度考慮して抽出することができます。
- 「ある程度」と書いたのは、NormalizeNumexpも裏で持っている表現のパターン辞書や正規表現をもとに抽出するので、あらゆる表現に対応しているとは限らないためです。
入力:「2021年11月19日時点でのドル円は114.34円なので、100ドルは¥11344になる。2021/11/20のドル円は分からない。」
出力:
- 時間表現:2021年11月19日 単位:(なし) 正規化表現:2021-11-19
- 数量表現:114.34円 単位:円 正規化表現:114.34
- 数量表現:100ドル 単位:ドル 正規化表現:100
- 数量表現:¥11344 単位:円 正規化表現:11344
- 時間表現:2021/11/20 単位:(なし) 正規化表現:2021-11-20
なお、内部では形態素解析や構文解析、固有表現抽出などの機械学習的なアプローチは全く使っていません。
パターン辞書や正規表現などを使ったルールベースごりごりの処理で実現しています。
実行例
>>> from pynormalizenumexp.normalize_numexp import NormalizeNumexp
>>> normalizer = NormalizeNumexp("ja")
>>> results = normalizer.normalize("太郎は3年前の2021年12月4日に生まれた", as_dict=True)
>>> for r in results:
... print(r)
...
{'type': 'reltime', 'original_expr': '3年前', 'position_start': 3, 'position_end': 6, 'counter': 'none', 'value_lower_bound': None, 'value_upper_bound': None, 'value_lower_bound_abs': {'year': inf, 'month': inf, 'day': inf, 'hour': inf, 'minute': inf, 'second': inf}, 'value_upper_bound_abs': {'year': -inf, 'month': -inf, 'day': -inf, 'hour': -inf, 'minute': -inf, 'second': -inf}, 'value_lower_bound_rel': {'year': -3, 'month': inf, 'day': inf, 'hour': inf, 'minute': inf, 'second': inf}, 'value_upper_bound_rel': {'year': -3, 'month': -inf, 'day': -inf, 'hour': -inf, 'minute': -inf, 'second': -inf}, 'options': []}
{'type': 'abstime', 'original_expr': '2021年12月4日', 'position_start': 7, 'position_end': 17, 'counter': 'none', 'value_lower_bound': {'year': 2021, 'month': 12, 'day': 4, 'hour': inf, 'minute': inf, 'second': inf}, 'value_upper_bound': {'year': 2021, 'month': 12, 'day': 4, 'hour': -inf, 'minute': -inf, 'second': -inf}, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
年月日だけでなく、「X年前」といった表現も抽出が可能です。
value_lower_boundと付くものはその表現が示す下限値、value_upper_boundと付くものはその表現が示す上限値を表します。
このvalue_lower_boundやvalue_upper_boundが正規化された値に相当します。
(なお、日時の情報で該当する値がない場合は実装の都合上infまたは-infになっています)
>>> results = normalizer.normalize("2021/11/19時点でのドル円は114.34円なので、100ドルは¥11344になる。令和3年11月20日のドル円は分からない。", as_dict=True)
>>> for r in results:
... print(r)
...
{'type': 'abstime', 'original_expr': '2021/11/19', 'position_start': 0, 'position_end': 10, 'counter': 'none', 'value_lower_bound': {'year': 2021, 'month': 11, 'day': 19, 'hour': inf, 'minute': inf, 'second': inf}, 'value_upper_bound': {'year': 2021, 'month': 11, 'day': 19, 'hour': -inf, 'minute': -inf, 'second': -inf}, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
{'type': 'numerical', 'original_expr': '114.34円', 'position_start': 18, 'position_end': 25, 'counter': '円', 'value_lower_bound': 114.34, 'value_upper_bound': 114.34, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
{'type': 'numerical', 'original_expr': '100ドル', 'position_start': 29, 'position_end': 34, 'counter': 'ドル', 'value_lower_bound': 100, 'value_upper_bound': 100, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
{'type': 'numerical', 'original_expr': '¥11344', 'position_start': 35, 'position_end': 41, 'counter': '円', 'value_lower_bound': 11344, 'value_upper_bound': 11344, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
{'type': 'abstime', 'original_expr': '令和3年11月20日', 'position_start': 45, 'position_end': 55, 'counter': 'none', 'value_lower_bound': {'year': 2021, 'month': 11, 'day': 20, 'hour': inf, 'minute': inf, 'second': inf}, 'value_upper_bound': {'year': 2021, 'month': 11, 'day': 20, 'hour': -inf, 'minute': -inf, 'second': -inf}, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
年月日の形式はスラッシュ区切りや和暦表現でも抽出が可能で、和暦の場合は西暦にした値も取得ができます。(上記の例の場合、令和3年→2021)
金額など、単位が数字の前に付く場合や後に付く場合も抽出できます。
>>> results = normalizer.normalize("捜索は10/1~10/15の2週間に渡って行われた", as_dict=True)
>>> for r in results:
... print(r)
...
{'type': 'abstime', 'original_expr': '10/1~10/15', 'position_start': 3, 'position_end': 13, 'counter': 'none', 'value_lower_bound': {'year': inf, 'month': 10, 'day': 1, 'hour': inf, 'minute': inf, 'second': inf}, 'value_upper_bound': {'year': -inf, 'month': 10, 'day': 15, 'hour': -inf, 'minute': -inf, 'second': -inf}, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
{'type': 'duration', 'original_expr': '2週間', 'position_start': 14, 'position_end': 17, 'counter': 'none', 'value_lower_bound': {'year': inf, 'month': inf, 'day': 14, 'hour': inf, 'minute': inf, 'second': inf}, 'value_upper_bound': {'year': -inf, 'month': -inf, 'day': 14, 'hour': -inf, 'minute': -inf, 'second': -inf}, 'value_lower_bound_abs': None, 'value_upper_bound_abs': None, 'value_lower_bound_rel': None, 'value_upper_bound_rel': None, 'options': []}
「~」などで繋げた場合は、下限値と上限値をそれぞれ抽出することができます。
NormalizeNumexpの中身はどうなっているのか
NormalizeNumexpでは以下の4種類の表現を抽出・正規化するようになっており、大まかには入力となるテキストからそれぞれの表現を抽出したあとに不適当な表現(例:URLに含まれる数量表現)を削除するという流れになっています。
- 数量表現
- 「1個」や「3kg」など量を表す表現
- 絶対時間表現
- 「1月1日」や「19時半」などの絶対的な時間を表す表現
- 相対時間表現
- 「3日前」や「6時間後」などの相対的な時間を表す表現
- 期間表現
- 「1ヶ月間」や「2時間」などの期間を表す表現
- 少しややこしいですが、「1月~2月」「3日から4日」のように「~」や「から」などを含む場合は時間表現として抽出されます
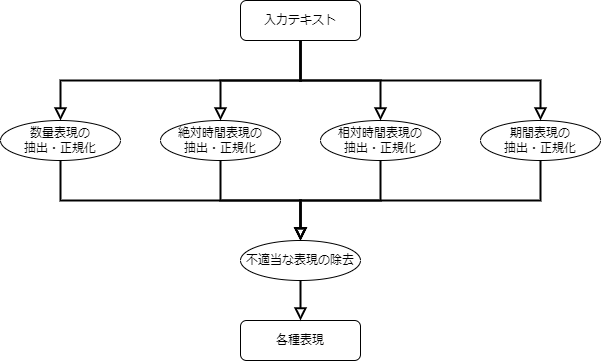
各表現の抽出ロジックの概要は以降に記載します。
各表現の抽出ロジック
数量表現や絶対時間表現など種類ごとに細かい差はありますが、大まかには以下のようなロジックで表現を抽出・正規化しています。
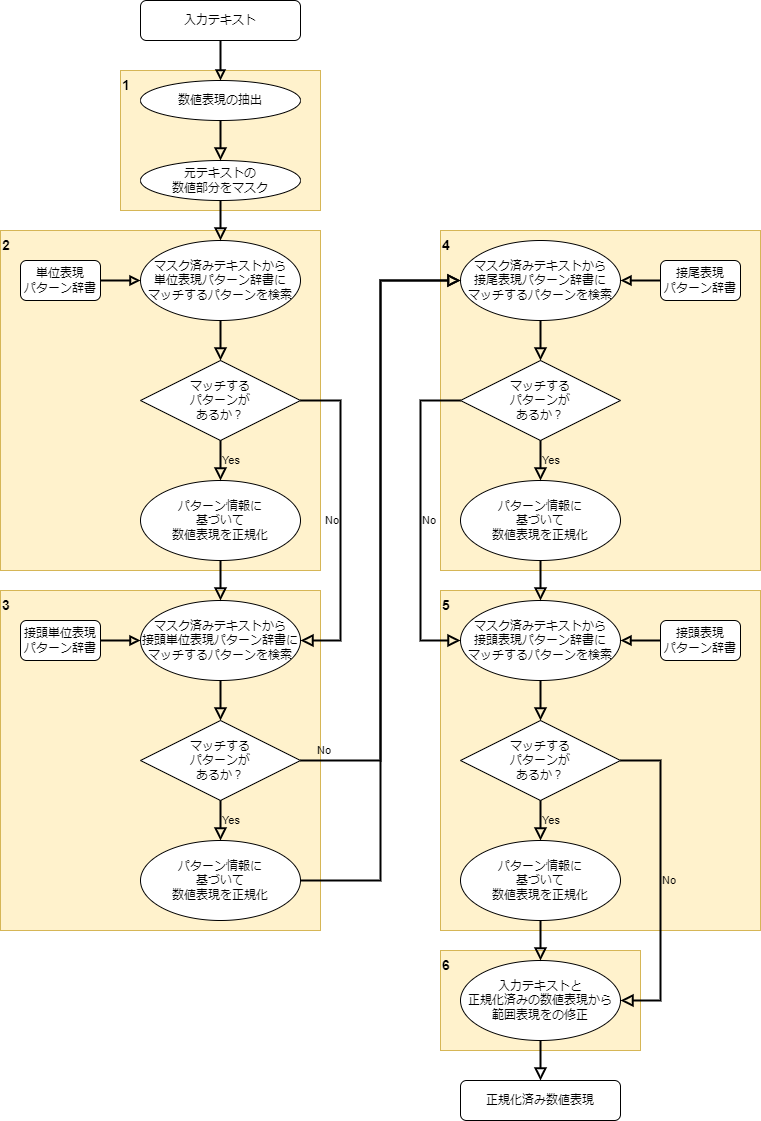
黄色いボックスで示したように大きく6つの処理に分けることができるので、その説明を以下に記載します。
(実際のロジックはかなり複雑なのでかなりラフに説明します)
1. 数値表現の抽出
ここでは入力されたテキストから**数値に関する部分だけ(=数値表現)**を見つけ出します。単位や時間などの情報は見ません。
例えば、以下のようなテキストが入力された場合は、2021、11、19、114、34、百、11、344といった数値を見つけます。(数字の全角半角だけでなく漢数字も見つけます)
2021年11月19日時点でのドル円は114.34円なので、百ドルは¥11,344になる。
そして小数点やカンマを挟んで連続するような数値は1つの数値とみなすようにします。
例:114と34は.を挟むので、114.34という1つの数値としてみなします。11,344も同様です。
この抽出と同時に、抽出した数値表現(文字列)の数値を計算します。(例:百→100)
この計算は「100円」と「百円」が同じ値であると分かるようにする(=正規化する)ために実施しています。
その後、入力テキストの数値表現の部分を予め決められたプレースホルダー(ǂ)に置換=マスクします。
上記の入力テキスト例の場合、以下のようにマスクされます。
ǂ年ǂ月ǂ日時点でのドル円はǂ円なので、ǂドルは¥ǂになる。
2. 単位表現の抽出
ここでは、1.で作成したマスク済みテキストと単位表現パターンを定義した辞書を照らし合わせて、単位表現=単位情報を含む数値表現を抽出します。
例えば、辞書に年月日を表すパターン「年ǂ月ǂ日」が定義されている場合、パターンが出現する直前の数値(プレースホルダー)も含めた「ǂ年ǂ月ǂ日」が単位表現(この場合は絶対時間表現)として抽出されます。
このパターン辞書は数量表現、絶対時間表現、相対時間表現、期間表現ごとに用意されているため、どの辞書にマッチしたかでどの表現かが自動的に決まります。
なお、上記の例で言うと、パターン辞書には「年」や「月ǂ日」なども含まれますが、最長一致するパターンが採用されます。
ǂ年ǂ月ǂ日時点でのドル円はǂ円なので、ǂドルは¥ǂになる。
というマスク済みテキストからは以下の単位表現が抽出されます。
- 絶対時間表現:
ǂ年ǂ月ǂ日(元テキストでは2021年11月19日) - 数量表現:
ǂ円(元テキストでは114.34円) - 数量表現:
ǂドル(元テキストでは百ドル)
3. 接頭単位表現の抽出
接頭単位は「¥」、「$」、「時速」や「北緯」といった数値の直前に出てくる単位のことを指します。
なので、2.と同様に接頭単位表現を定義したパターン辞書とのマッチングにより抽出してきます。
(4.~6.では割愛しますが、以降の流れでもパターン辞書とのマッチングにより抽出してきます)
ǂ年ǂ月ǂ日時点でのドル円はǂ円なので、ǂドルは¥ǂになる。
というマスク済みテキストからは、¥ǂが数量表現(元テキストでは¥11,344)として抽出されます。
4. 接尾表現の抽出
接尾表現は「XX以下」「XX頃」など数値の直後に出てくる数値の範囲などを補足するのに使う表現を指します。
元テキスト:3時頃に目がさめた
マスク済みテキスト:ǂ時頃に目がさめた
というテキストからは、ǂ時頃(3時頃)が絶対時間表現として抽出されます。
(厳密には、先に2.の単位表現の抽出で3時が絶対時間表現として抽出され、その表現に続く接尾表現を取ってくるようになっています)
なお、NormalizeNumexpでは数値表現の下限値と上限値を計算するようになっているので、「3時頃」のようなアバウトな表現は下限値が「2時」、上限値が「4時」のように計算されます。
5. 接頭表現の抽出
接頭表現は「だいたいXX個」「午後XX時」など数値の直後に出てくる数値の範囲などを補足するのに使う表現を指します。
元テキスト:だいたい8時に寝て、午後1時に目がさめた
マスク済みテキスト:だいたいǂ時に寝て、午後ǂ時に目がさめた
というテキストからは、だいたいǂ時(だいたい8時)と午後ǂ時が抽出されます。
4.の接尾表現の抽出と同様に、接頭表現でも「だいたい8時」のようなアバウトな表現は下限値が「7時」、上限値が「9時」として計算されます。
また、「午後1時」は「13時」のように計算(正規化)されます。
6. 範囲表現の修正
範囲表現は名前の通り「3時~4時」「5個から6個」など、「~」「から」を使った範囲を示す表現を指します。
上記のフロー2.~5.ではこのような範囲表現は気にせずに各種表現を抽出しているので、最後に元のテキストと抽出した表現を見て範囲表現がないかチェックをしています。
例えば、以下のようなテキストの場合
3時~4時の間に起きた
-
3時と4時が絶対時間表現として抽出される -
3時と4時の間に範囲を表す~があるので、3時~4時を1つの絶対時間表現として抽出する(下限値を3時、上限値を4時として計算する)
という感じになります。
また、「2021/12/1~12/10」のように範囲表現で部分的に省略されているような場合は、省略された部分を補う(「12/10」を「2021/12/10」にする)ようになっています。
(具体的なロジックはやや複雑なので省略します)
(非常にラフな説明ですが、、)4種類の各表現抽出の中で、以上のようなロジックを経ることで冒頭にサンプルで示したように数量表現や時間表現などを抽出・正規化することができます。
まとめ
- NormalizeNumexpをPythonでゼロから実装しました
- Pythonで使う際のインストールが非常に楽になりました
- トラシュー含め何時間もかかっていたのが数秒で使えるようになりました
- (ついでに、実装し直すにあたって読み解いたロジックをまとめました)
その他学んだこと
- Pythonのimportlibの使い方
- パターン辞書はJSONファイルで定義しているのですが、それを読み込む際のファイルパスの指定をキレイにできないかと思案していたところ、importlibでパッケージ名やモジュール名をパスに含めることで簡単に読み込むことができました。
- 例:https://github.com/tkscode/pyNormalizeNumExp/blob/ac7df9b49153d9b792f5c8087b17c0d8c4a615b2/pynormalizenumexp/utility/dict_loader.py#L43
- GitHub Actionsを使った単体テストとPyPIへの公開
- PyPIに公開するならCI/CD的なこともやろうと思い、GitHub Actionsを使って単体テストの実行&Codecovへのカバレッジのアップロード、PyPIへのライブラリ公開を行うようにしました。
- 今回はパッケージ管理にPoetryを使ったのですが、単体テストの実行もPyPIへの公開も簡単にできました。
- 単体テスト例:https://github.com/tkscode/pyNormalizeNumExp/blob/ac7df9b49153d9b792f5c8087b17c0d8c4a615b2/.github/workflows/pytest.yml
- PyPI公開例:https://github.com/tkscode/pyNormalizeNumExp/blob/ac7df9b49153d9b792f5c8087b17c0d8c4a615b2/.github/workflows/upload_python_package.yml
- 定期的なコードのメンテは大事
参考リンク
- NormalizeNumexp本家様:nullnull/normalizeNumexp