はじめに
こんにちは。Tsukasaです!
前回のAWS完全初心者がAmazon Pollyで遊んでみた話 Part1に引き続きPart2について記事にしていきたいと思います。
Part1をまだ見ていない方がいらっしゃいましたら、こちらを是非ご覧ください!
Part1ではPollyのページで文章を入力し、音声化するという物凄くシンプルなことを行いましたが、今回はもう少しAWSの他のサービスを組み合わせた上で実装をしてみました。
早速見ていきたいと思います!
今回やること
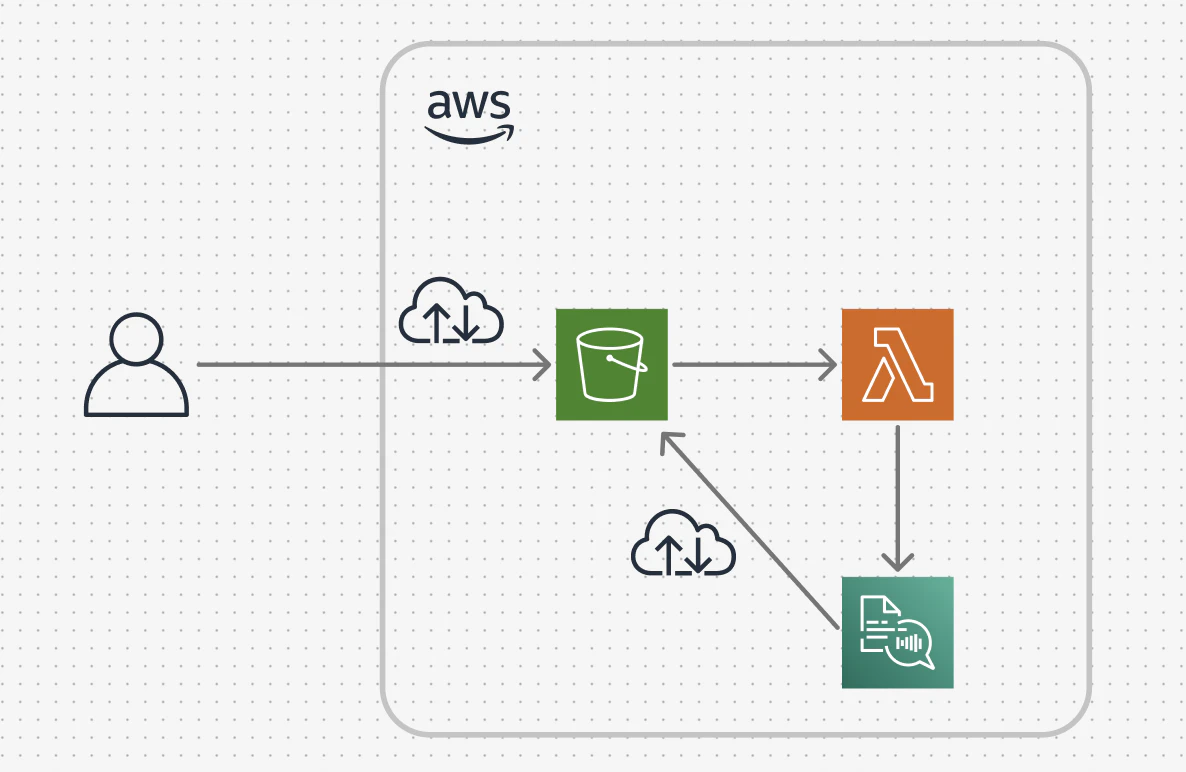
こちらが今回やりたい事の構成図となります。
こちらの構成も非常にシンプルになります。
S3に文章ファイルをアップロードし、Lambda関数がそれをトリガーとし、自動でPollyが文章ファイルを音声化して、最後にS3に音声ファイルを保存させるという流れになります。
それではそれぞれの役割について見ていきたいと思います。
S3
S3では主にファイルの保存先として使用します。
まずは今回音声化したい、ファイルを保存するためのバケットと
音声化した後に音声ファイルを保存するためのバケットの2つが必要になります。
Lambda
Lambdaは今回のハンズオンの核となる部分です。
S3バケットに文章ファイルがアップロードされたらそれをトリガーにPollyが発動され、文章ファイルを音声ファイルと作成します。
Polly
Pollyは文章ファイルを音声ファイルに変換する役割を担っています。
ただ、今回のハンズオンではLambda関数でそこまでカバーしているので、実際にコンソールからPollyのページに飛んで何かをしたりということはありません。
事前準備
まず実装に入る前に、今回のハンズオンで使用する文章ファイルを用意する必要があります。
ご自身で用意していただいても結構ですが、下記から使用していただいても大丈夫です。
ファイルを用意していただいた上で開始したいと思います!
S3バケットの作成
まずはS3バケットを作成する必要があります。
コンソールからS3を検索してS3のページを開きます。
右上のバケットを作成ボタンを押してバケットの作成を行います。

ここでは、文章ドキュメントをアップロードするためのバケットと音声ファイルに変換したファイルをアップロードするためのバケットの2つが必要になります。
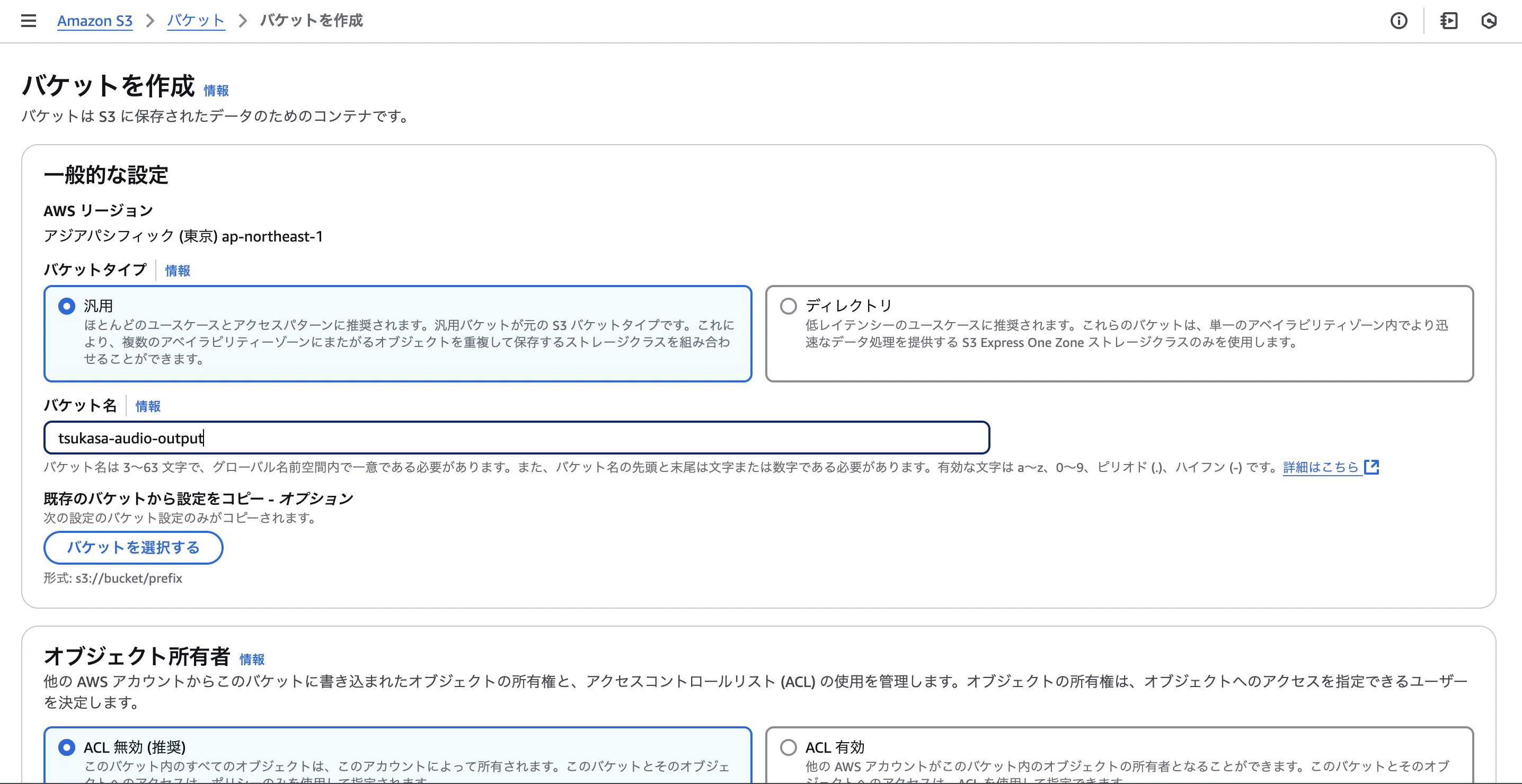
私は文章ドキュメントをアップロードするためのバケットを
tsukasa-sentence-update
音声ファイルに変換したファイルをアップロードするためのバケットを
tsukasa-audio-output
と名づけました。
バケット名ははっきりとしたわかりやすいものがオススメです。
Lambdaの作成
S3の作成が完了したら次はLambdaの作成を行います。
同じようにコンソール画面からLambdaを検索して開きます。
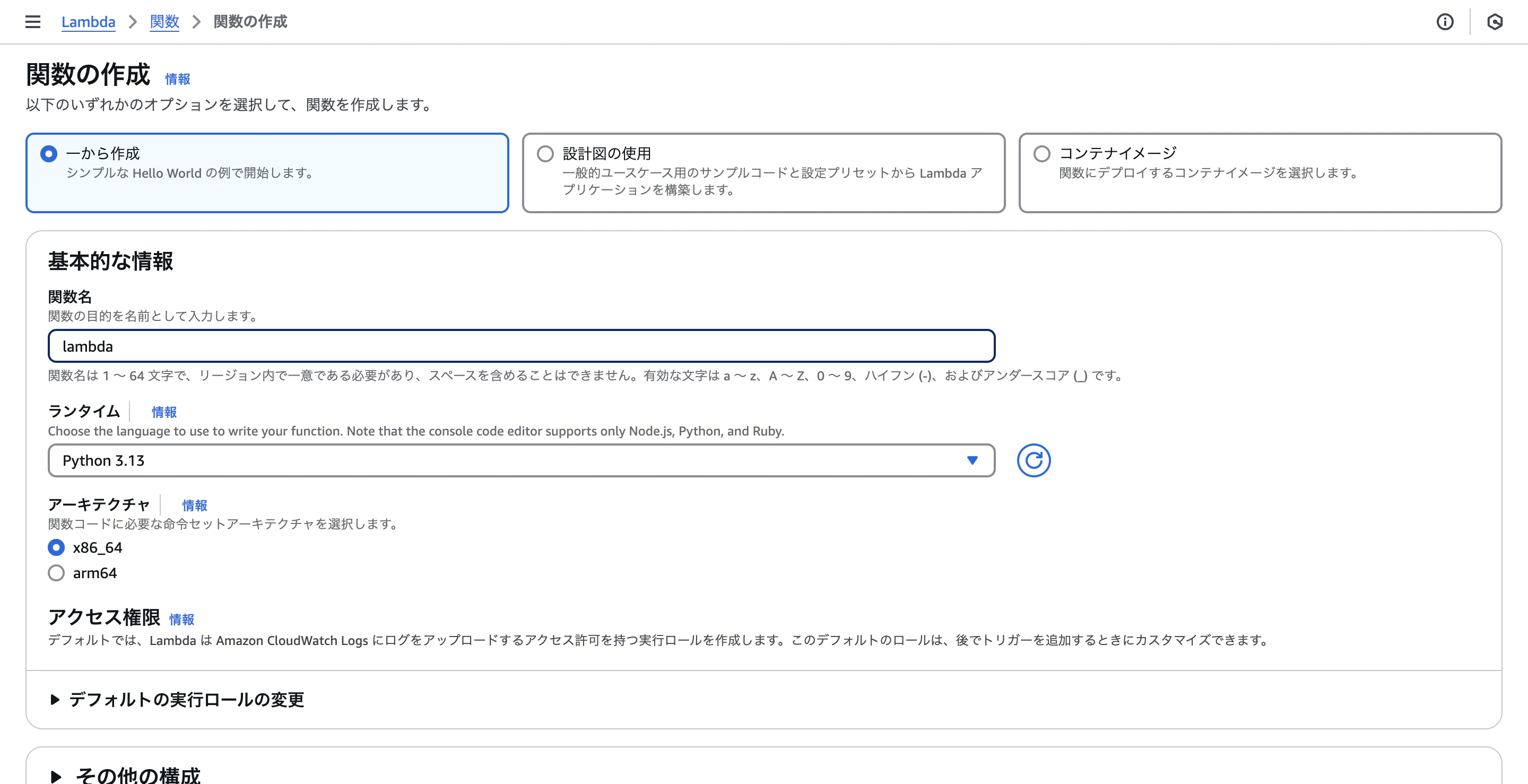
右上の関数の作成ボタンを押してLambdaを作成します。

今回は関数を一から作成したいと思います。
用途に合わせて設計図の使用やコンテナイメージも使えるので、用途に合わせて選択するようにしてください。
ランタイムはPython3.13を選択します。
後はデフォルトで大丈夫です。
その後一番下までスクロールして、関数の作成ボタンをクリックします。
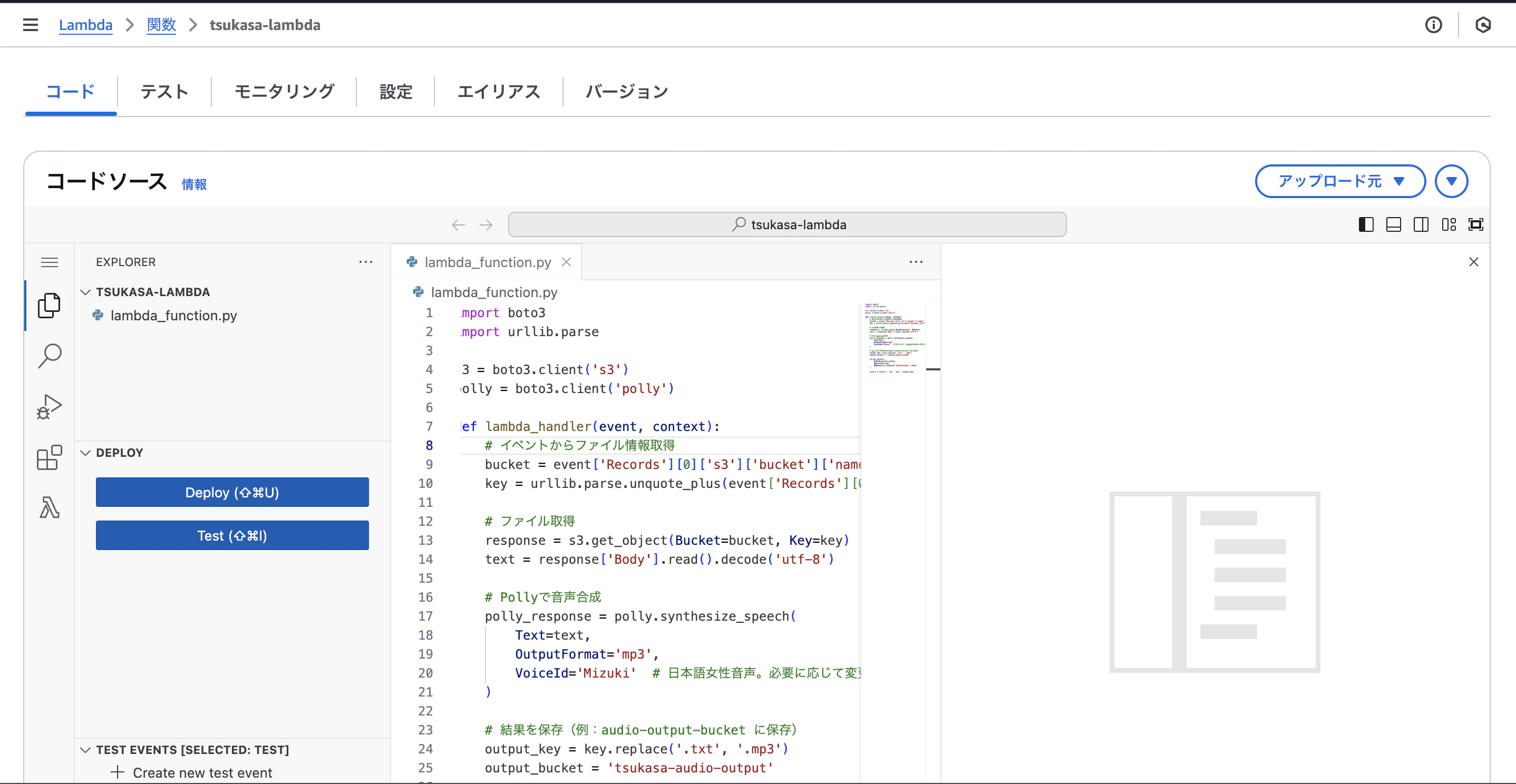
その後次のページでソースコードを記載する必要があります。
こちらが今回の核になります。
ソースコードは下記の物を使っていただいても結構です。
ただ1つ注意事項としましては、ソースコードの真ん中辺りにある出力先のファイル名はご自身で作成されたS3バケットの音声ファイルに変換したファイルをアップロードするためのバケット名に変えていただく必要があります。
import boto3
import urllib.parse
s3 = boto3.client('s3')
polly = boto3.client('polly')
def lambda_handler(event, context):
# アップロードされたファイルの情報を取得
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
try:
# S3からファイル内容を取得
response = s3.get_object(Bucket=bucket, Key=key)
text = response['Body'].read().decode('utf-8')
# Pollyで音声合成(日本語女性音声: Mizuki)
polly_response = polly.synthesize_speech(
Text=text,
OutputFormat='mp3',
VoiceId='Mizuki'
)
# 出力バケットとファイル名
output_bucket = 'audio-output-bucket' # 作成済のバケット名
output_key = key.replace('.txt', '.mp3')
# 音声ファイルをS3に保存
s3.put_object(
Bucket=output_bucket,
Key=output_key,
Body=polly_response['AudioStream'].read()
)
return {
'statusCode': 200,
'body': f'Audio saved to {output_bucket}/{output_key}'
}
except Exception as e:
print(e)
raise e
ソースコードが書けたら、次はトリガーを追加する必要があります。
今回のトリガーはS3にファイルがアップロードされたらでしたよね。そのため、トリガーにS3を追加します。

トリガーが追加できたら最後に、Lambdaに必要なIAM権限を追加します。
ソースコードの作成や、トリガーの追加はしましたが、権限を追加しないと仕様通りの動きとはなりませんので、忘れないようにする必要があります。
コンソールでIAMを検索します。
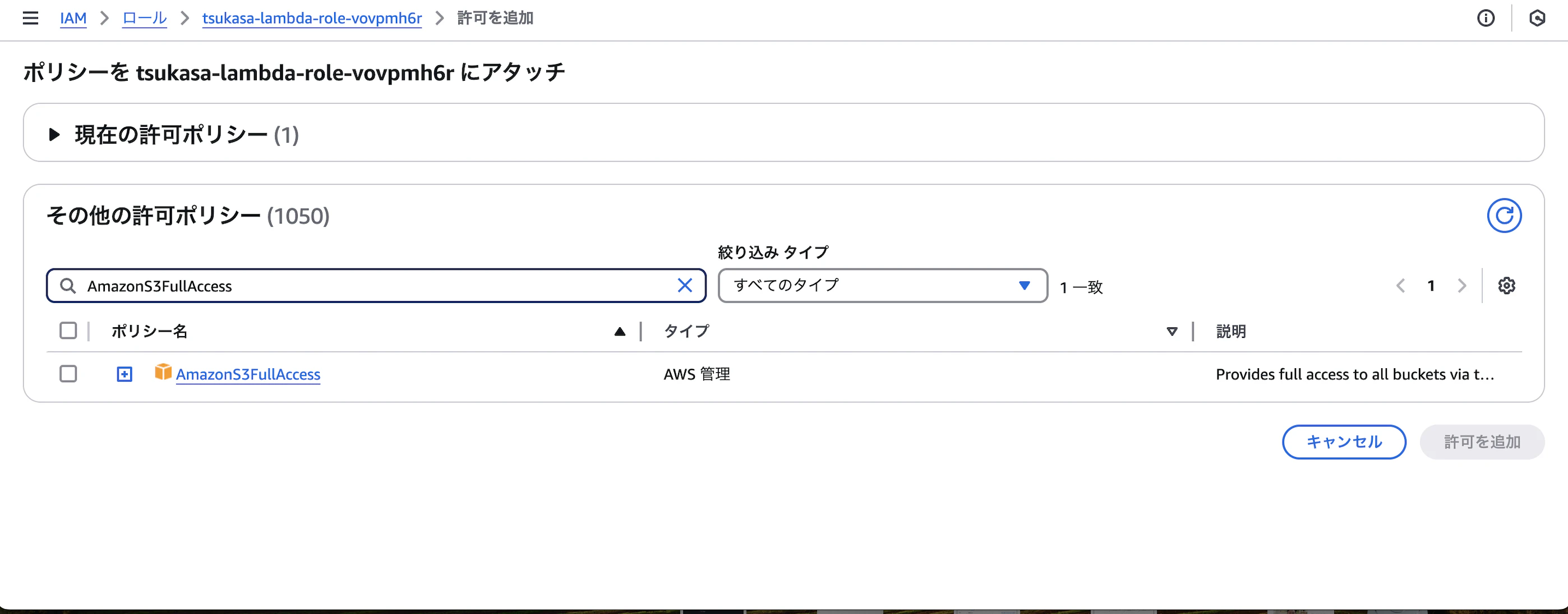
ロールから該当のIAMロールを選択し、許可ポリシーの項目で許可を追加をクリックします。
許可を追加をクリックすると、ポリシーをアタッチという項目が出てくるのでこちらを選択します。
※下記キャプチャは既に権限追加後のものとなります。

今回はLambdaに対してS3とPollyがアクセスできるようにしないといけません。
下記の2つのポリシーを検索して追加をします。
AmazonS3FullAccess
AmazonPollyFullAccess
ここまでできたら作業は終了となります。
後は、S3バケットに文章ファイルをアップロードしたら、自動で音声ファイルに変換して、S3バケットにファイルがアップロードされているかを確認します。
文章ファイルをアップロードしたら無事、音声ファイルとして返ってきました!!
成功です!!
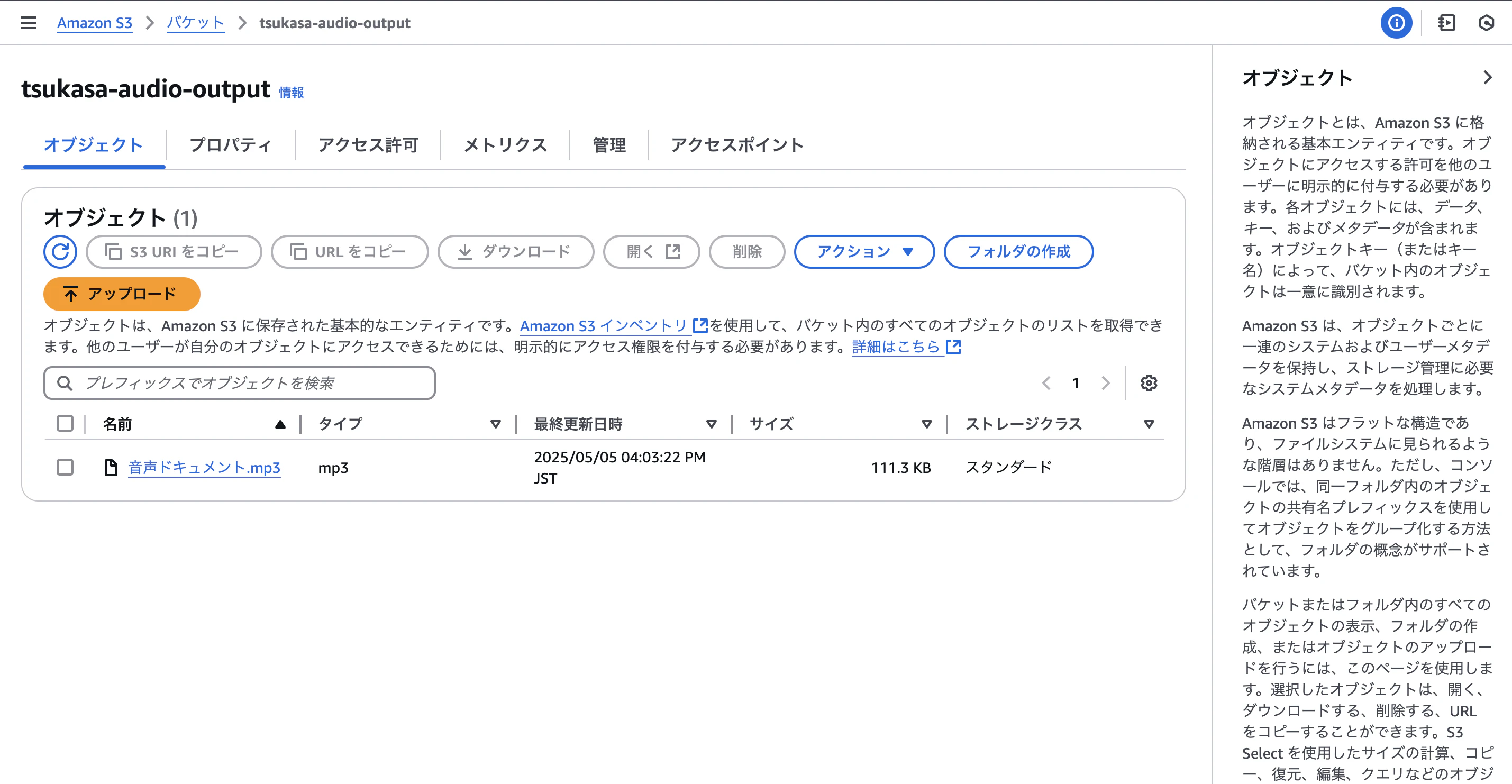

こちらに音声ファイルを載せておきますので、聞ける方は是非聞いてみてください!
終わりに
いかがでしたでしょうか?
Pollyというよりかはどちらかと言うとLambdaの使い方みたいになったかもしれませんね。笑
初心者でもこのように複数のAWSサービスを用いて、成果物をアウトプットすることができました。
時間としても1時間くらいでできましたので、初心者でまだ実際にAWSを触ったことがないという方も是非挑戦してみてください!