!注意:新しい記事をご覧ください
2024年4月29日に GPU 用の新しい VM イメージ (NVIDIA GPU-Optimized VMI) が提供されました。それに伴って、この投稿で扱っている NVIDIA GPU Cloud Machine Image は選択できなくなっています。
新しい VM イメージを使った記事を新たに投稿していますので、そちらをご覧下さい。
この投稿は NVIDIA GPU Cloud Machine Image を使った場合の解説として残しておきます。
はじめに
Hugging Face には日本語に対応した LLM が色々と存在するので、Oracle Cloud Infrastructure (OCI) にある GPU インスタンスを使って サクッと Inferencing(推論)を試す環境を作ってみます。
使うもの
- OCI の A10 GPU VM インスタンス上に推論環境を構築
- 推論には Text Generation Inference (TGI) を使用 (Docker コンテナとして動かす)
Text Generation Inference は、Hugging Face にある Large Language Model (LLM) をデプロイして推論を実行するためのツールキットです。
-
Streamlit を使って推論を実行する UI を準備する
Streamlit は、Chat アプリケーションを秒速で作成することができる Python のフレームワークです。
A10 インスタンスを立ち上げる
OCI に不慣れで仮想ネットワークの作成やコンピュート・インスタンスの立ち上げ方が分からない方は、OCIチュートリアルのコンテンツを参照してください。
今回は A10 GPU が搭載された VM を立ち上げますが、ポイントだけ簡単に解説します。
まず、正しいシェイプと VM イメージを選択してください。
イメージは、"NVIDIA GPU Cloud Machine Image" を選択してください。ちょっと見つけにくいとこにありますが、「Marketplace」にある「パートナー・イメージ」のリストの中にあります。

シェイプについて、今回は NVIDIA A10 GPU が使える最小の VM シェイプ (VM.GPU.A10.1) を選択します。

上のイメージのようにイメージとシェイプが選択されていることを確認して下さい。
更に、ブートボリュームのサイズに関してデフォルトは 50GB になっていますが、モデルを色々とダウンロードするとかなりの容量を消費してしまうので、余裕を持った大きめのサイズに変更して下さい。

動作確認
インスタンスが立ち上がったら、ssh でログインして動作確認しましょう。
ユーザは "ubuntu" です(通常 OCIのイメージは "oci" なので ssh の config を何も考えずに編集していると案外ここでひっかかったりします)。
まず、シンプルに nvidia-smi で GPU の状況確認
$ nvidia-smi
Fri Apr 19 02:18:25 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A10 On | 00000000:00:04.0 Off | 0 |
| 0% 33C P8 20W / 150W| 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
今回、アプリケーションは docker コンテナで動作するので、コンテナでも GPU が問題なく使えるか確認します。
$ docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Fri Apr 19 02:18:43 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A10 On | 00000000:00:04.0 Off | 0 |
| 0% 33C P8 15W / 150W| 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
GPU インスタンスの準備完了!
Text Generation Inference を起動する
TGI の Docker イメージを使います。
起動スクリプト(run.sh)
#!/bin/bash
model=tokyotech-llm/Swallow-MS-7b-instruct-v0.1
docker run --rm --gpus all --shm-size 1g -p 8080:80 \
--name text-generation-launcher \
-v $PWD/data:/data ghcr.io/huggingface/text-generation-inference:2.0 \
--model-id $model
model に Hugging Face のモデルIDを指定して、色々な LLM を試すことができますが、まずは 70憶 (7B) パラメータの Swallow-MS-7b-instruct-v0.1 を使ってみます。
シェルを実行すると、色々と出力が続きますが...
$ ./run.sh
2024-04-19T02:26:01.803283Z INFO text_generation_launcher: Args { model_id: "tokyotech-llm/Swallow-MS-7b-v0.1", ...
2024-04-19T02:26:01.803350Z INFO hf_hub: Token file not found "/root/.cache/huggingface/token"
2024-04-19T02:26:02.104602Z INFO text_generation_launcher: Default `max_input_tokens` to 4095
2024-04-19T02:26:02.104615Z INFO text_generation_launcher: Default `max_total_tokens` to 4096
2024-04-19T02:26:02.104617Z INFO text_generation_launcher: Default `max_batch_prefill_tokens` to 4145
2024-04-19T02:26:02.104619Z INFO text_generation_launcher: Using default cuda graphs [1, 2, 4, 8, 16, 32]
2024-04-19T02:26:02.104688Z INFO download: text_generation_launcher: Starting download process.
2024-04-19T02:26:07.235815Z INFO text_generation_launcher: Download file: model-00001-of-00003.safetensors
2024-04-19T02:26:11.381817Z INFO text_generation_launcher: Downloaded /data/models--tokyotech-llm--Swallow-MS-7b-v0.1/snapshots/0818a5240056fd26208305da3d26b386c7835c8a/model-00001-of-00003.safetensors in 0:00:04.
<< 途中省略 >>
2024-04-19T02:26:34.924366Z INFO text_generation_router: router/src/main.rs:349: Connected
2024-04-19T02:26:34.924369Z WARN text_generation_router: router/src/main.rs:363: Invalid hostname, defaulting to 0.0.0.0
Invalid hostname, defaulting to 0.0.0.0 が出力されたところで、APIのエンドポイントが準備完了になっています。
API の仕様はこちらを参照してください。
では、curl を使ってエンドポイントのテストを行ってみます。
(レスポンスは実行毎に異なる可能性があります)
$ curl 127.0.0.1:8080/generate \
> -X POST \
> -d '{"inputs":"日本の首都は?"}' \
> -H 'Content-Type: application/json'
{"generated_text":"日本の首都は東京です。"}
Streamlit で作る UI から TGI を呼び出す際のエンドポイントは /generate でもいいのですが、今回は /generate_stream を使います。このエンドポイントでは、推論で生成されるテキストを部分毎に都度返してくるので、推論の完了までUI の処理を待機する必要がありません。
$ curl 127.0.0.1:8080/generate_stream \
> -X POST \
> -d '{"inputs":"日本の首都は?"}' \
> -H 'Content-Type: application/json'
data:{"index":1,"token":{"id":13,"text":"\n","logprob":-0.4050293,"special":false},"generated_text":null,"details":null}
data:{"index":2,"token":{"id":32068,"text":"日本","logprob":-1.6171875,"special":false},"generated_text":null,"details":null}
data:{"index":3,"token":{"id":28993,"text":"の","logprob":-0.043518066,"special":false},"generated_text":null,"details":null}
data:{"index":4,"token":{"id":37377,"text":"首都","logprob":-0.09429932,"special":false},"generated_text":null,"details":null}
data:{"index":5,"token":{"id":29277,"text":"は","logprob":-0.015113831,"special":false},"generated_text":null,"details":null}
data:{"index":6,"token":{"id":32220,"text":"東京","logprob":-0.07556152,"special":false},"generated_text":null,"details":null}
data:{"index":7,"token":{"id":32001,"text":"です","logprob":-0.116760254,"special":false},"generated_text":null,"details":null}
data:{"index":8,"token":{"id":28944,"text":"。","logprob":-0.00091314316,"special":false},"generated_text":null,"details":null}
data:{"index":9,"token":{"id":2,"text":"</s>","logprob":-0.40795898,"special":true},"generated_text":"\n日本の首都は東京です。","details":null}
TGI も準備完了!
Streamlit で UI を作る
最後にこのエンドポイントを呼び出す Chat UI を作ります。
まずは Streamlit のインストールですが、この GPU インスタンスは既に conda の仮想環境になっているので、Streamlit のインストールも conda で行います。
$ conda install streamlit
Chat UI の Python スクリプト(chat.py)を準備します。
import streamlit as st
import json, requests, re
endpoint = "http://localhost:8080/generate_stream"
def generate_text(
inputs,
max_new_tokens, presence_penalty, repetition_penalty, temperature):
body = {
"inputs" : inputs,
"parameters": {
"max_new_tokens" : max_new_tokens,
"presence_penalty" : presence_penalty,
"repetition_penalty" : repetition_penalty,
"temperature" : temperature
}
}
response = requests.post(endpoint, json=body, stream=True) # type: requests.models.Response
if not response.ok: raise Exception(response.text)
for chunk in response.iter_content(chunk_size=None):
chunk_str = re.sub(r"^data: ?", "", chunk.decode()) # field = 1*name-char [ colon [ space ] *any-char ] end-of-line
data = json.loads(chunk_str)
if not data["generated_text"]:
yield data["token"]["text"]
st.title("Text Generation Chat Bot")
with st.sidebar:
st.header(f"options")
max_new_tokens = st.number_input("max new tokens", min_value=0, max_value=65535, value=1024)
frequency_penalty = st.slider("frequency penalty", min_value=0.0, max_value=1.0, value=0.1, step=0.01)
repetition_penalty = st.slider("repetition penalty", min_value=0.0, max_value=2.0, value=1.1, step=0.01)
temperature = st.slider("temparature", min_value=0.0, max_value=5.0, value=0.5, step=0.01)
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if input := st.chat_input("メッセージを入力してください"):
print(f"input: {input}")
st.chat_message("user").write(input)
st.session_state.messages.append({"role": "user", "content": input})
prompt = f"""
あなたは優秀な日本人のアシスタントです。ユーザの質問に対して全力で真摯な回答を試みます。
質問に対して簡潔に答えてください。
{input}
"""
response = generate_text(
prompt,
max_new_tokens, frequency_penalty, repetition_penalty, temperature
)
with st.chat_message("assistant"):
msg = ""
area = st.empty()
for text in response:
msg += text
area.write(msg)
print(f"msg: {msg}")
st.session_state.messages.append({"role": "assistant", "content": msg})
このスクリプトを使って、Streamlit を起動します。
$ streamlit run chat.py
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
Network URL: http://xxx.xxx.xxx.xxx:8501
External URL: http://xxx.xxx.xxx.xxx:8501
GPU インスタンスの 8501 番ポートを開けてグローバルアドレスでアクセスするか、ssh のポートフォーワーディング経由でアクセスするか、いずれかの方法でUI 画面にアクセスして下さい。
こんな UI になっているハズです。
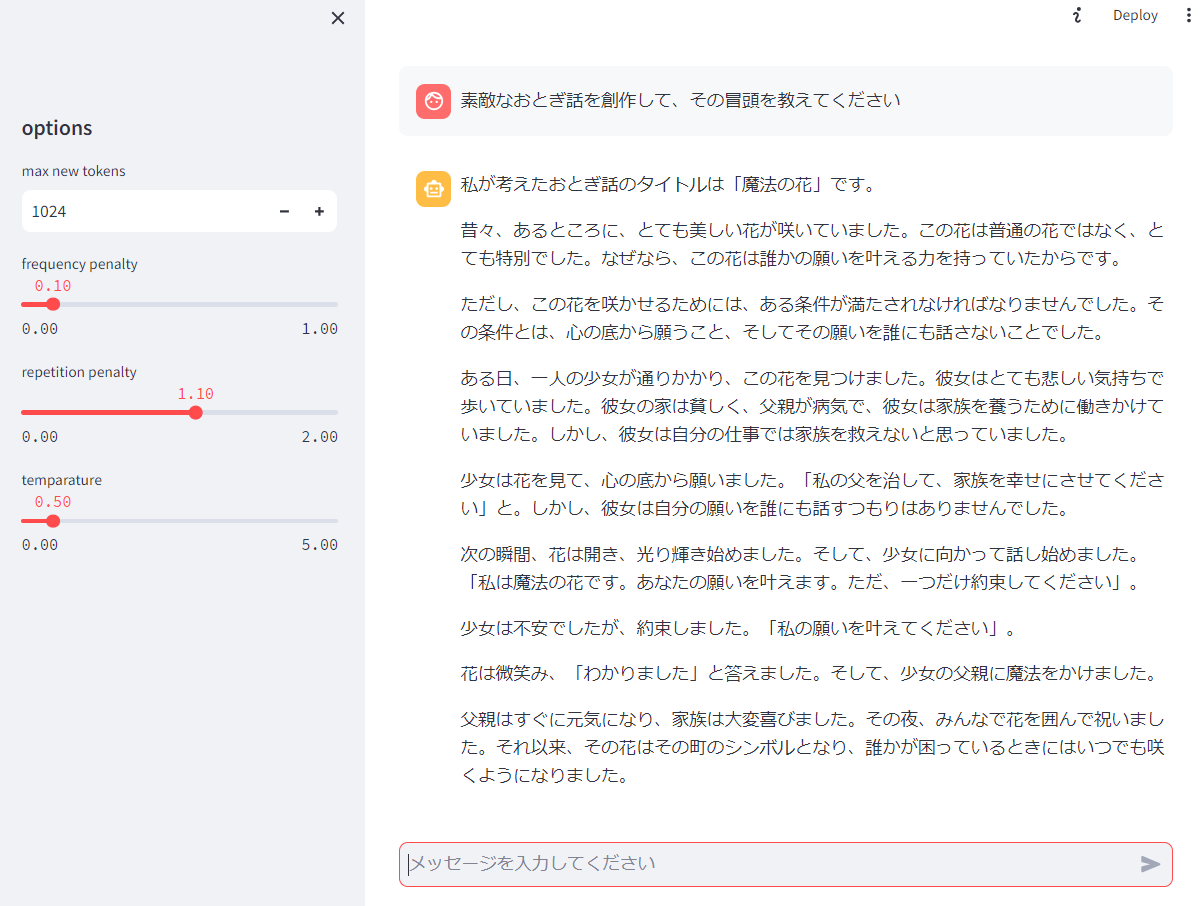
これで完成!
別のモデルを試したいときは、TGI のモデル指定を変えてコンテナを再起動すれば OK です。
大きいサイズの LLM を動かす(クオンタイズ:量子化)
現状のセッティングで、 130億 (13B) パラメータを動かそうと思ったらメモリー不足で無理でした。幸い TGI にはクオンタイズ(重みなどのパラーメータをより小さいビットで表現する)のオプションがあるので、これを使えば VM.GPU.A10.1 シェイプでもなんとか 13B LLM も動かせました。
#!/bin/bash
model=tokyotech-llm/Swallow-13b-instruct-v0.1
docker run --rm --gpus all --shm-size 1g -p 8080:80 \
--name text-generation-launcher \
-v $PWD/data:/data ghcr.io/huggingface/text-generation-inference:2.0 \
--model-id $model \
--quantize eetq
--quantize に指定可能な値は、TGI の --help で確認できます。
--quantize <QUANTIZE>
Whether you want the model to be quantized
[env: QUANTIZE=]
Possible values:
- awq: 4 bit quantization. Requires a specific AWQ quantized model: https://hf.co/models?search=awq. Should replace GPTQ models wherever possible because of the better latency
- eetq: 8 bit quantization, doesn't require specific model. Should be a drop-in replacement to bitsandbytes with much better performance. Kernels are from https://github.com/NetEase-FuXi/EETQ.git
- gptq: 4 bit quantization. Requires a specific GTPQ quantized model: https://hf.co/models?search=gptq. text-generation-inference will use exllama (faster) kernels wherever possible, and use triton kernel (wider support) when it's not. AWQ has faster kernels
- bitsandbytes: Bitsandbytes 8bit. Can be applied on any model, will cut the memory requirement in half, but it is known that the model will be much slower to run than the native f16
- bitsandbytes-nf4: Bitsandbytes 4bit. Can be applied on any model, will cut the memory requirement by 4x, but it is known that the model will be much slower to run than the native f16
- bitsandbytes-fp4: Bitsandbytes 4bit. nf4 should be preferred in most cases but maybe this one has better perplexity performance for you model
13B のモデルをクオンタイズして推論を実行しているコンテナの中から GPU の状況を確認
$ docker exec -it text-generation-launcher nvidia-smi
Wed May 1 04:58:15 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A10 On | 00000000:00:04.0 Off | 0 |
| 0% 46C P0 60W / 150W | 21160MiB / 23028MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
+-----------------------------------------------------------------------------------------+
トラブルシューティング
アプリケーションを実行していると、以下のようなエラーが出ることがあります。
(base) ubuntu@tgi:~/work/cuda$ nvidia-smi
Failed to initialize NVML: Driver/library version mismatch
NVML library version: 535.171
解決のために色々と試みましたが、元に戻すことができませんでした。が、潔くGPU 用のドライバを更新すれば、エラーの発生が全くなくなりました。
以下のサイトからダウンロードしてインストールを行って下さい。
A10 インスタンスを立ち上げた後にまずこの作業を行った方が合理的かもです。
まとめ
OCI で NVIDIA A10 GPU を搭載した一番小さな VM シェイプを使って LLM の推論を Chat UI で試す環境を作ってみました。全く未知のところから始めると色々とつまずくところがあると思いますので、皆さんが試す際の参考にしていただければと...。