はじめに
LLMで長文のテキストを生成する場合、完全な回答を得るまでに結構長い時間待つ必要があります。このため、多くのLLMテキスト生成サービスは Stream モードをサポートしていて、回答の断片を少しずつクライアントに送り返すことができます。
この機能を使うと、全ての回答の生成を待たずに回答が順次画面に表示されるような Chat UI を作成することができます。
そして Oracle Cloud Infrastructure Generative AI Service も Stream モードをサポートしていますので、ここではまず仕様を確認しつつ、最後は簡単な Chat UI を作るところまでやってみたいと思います。なお、使用するプログラミング言語は Python です。
API の仕様を確認する / REST Call する
POST /20231130/actions/generateText
の API で Cohere モデルを使ってテキスト生成を行うには CohereLlmInferenceRequest Json オブジェクトを渡しますが、このオブジェクトには isStream というパラメータがあります。
-
isStream => Required: no / Type: boolean / Default: false
Whether to stream back partial progress. If set, tokens are sent as data-only server-sent events as they become available.
isStream を true にすると "Server-Sent Event" 形式でトークンだけが送られくると書いてありますので、実際に確認してみましょう。
まずは、テキスト生成を実行する関数を requests パッケージを使って作ります。
import os, requests, logging, http, oci
# HTTP の送受信をデバッグする設定
requests_log = logging.getLogger("urllib3")
requests_log.setLevel(logging.DEBUG)
http.client.HTTPConnection.debuglevel=1
endpoint = "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com"
def get_config_signer(file_location=None, profile_name=None) -> oci.signer.Signer:
""" ユーザー秘密鍵ベースの Signer を取得
環境変数 OCI_CONFIG_FILE_LOC, OCI_CONFIG_PROFILE で読み込み先を変更可
"""
default_file_loc = os.environ.get('OCI_CONFIG_FILE_LOC') if 'OCI_CONFIG_FILE_LOC' in os.environ else '~/.oci/config'
default_profile_name = os.environ.get('OCI_CONFIG_PROFILE') if 'OCI_CONFIG_PROFILE' in os.environ else 'DEFAULT'
file_loc = file_location if file_location else default_file_loc
profile = profile_name if profile_name else default_profile_name
config = oci.config.from_file(os.path.expanduser(file_loc), profile)
signer = oci.signer.Signer(
tenancy=config['tenancy'],
user=config['user'],
fingerprint=config['fingerprint'],
private_key_file_location=config['key_file'],
pass_phrase=config['pass_phrase']
)
return signer
def generate_text(
prompt:str,
compartment_id:str=None,
signer:oci.signer.Signer=None,
maxTokens:int=None, # Default: 20
temperature:float=None, # Default: 1, 0-5
frequencyPenalty:float=None, # Default: 0, 0-1
presencePenalty:float=None, # Default: 0, 0-1
numGenerations:int=None, # Default: 1, 1-5
topP:float=None, # Default: 0.75, 0-1
topK:int=None, # Default: 0, 0-500
truncate:str=None, # NONE (default), START, END
returnLikelihoods:str=None, # NONE (default), ALL, GENERATION
stopSequences:list=None,
isStream:bool=False,
isEcho:bool=None,
servingMode:dict=None, # Default: ON_DEMAND
modelId:str=None # "cohere.command" (default), "cohere.command-light"
):
""" テキストの生成 """
path = "/20231130/actions/generateText"
body = {
"compartmentId" : compartment_id if compartment_id else os.environ["COMPARTMENT_ID"],
"servingMode" : servingMode if servingMode else {
"modelId": modelId if modelId else "cohere.command",
"servingType" : "ON_DEMAND"
},
"inferenceRequest" : {
"runtimeType": "COHERE"
}
}
inference_request = body["inferenceRequest"]
inference_request["prompt"] = prompt
if maxTokens: inference_request["maxTokens"] = maxTokens
if temperature: inference_request["temperature"] = temperature
if frequencyPenalty: inference_request["frequencyPenalty"] = frequencyPenalty
if presencePenalty: inference_request["presencePenalty"] = presencePenalty
if numGenerations: inference_request["numGenerations"] = numGenerations
if topP: inference_request["topP"] = topP
if topK: inference_request["topK"] = topK
if truncate: inference_request["truncate"] = truncate
if returnLikelihoods: inference_request["returnLikelihoods"] = returnLikelihoods
if stopSequences: inference_request["stopSequences"] = stopSequences
if isStream: inference_request["isStream"] = isStream
if isEcho: inference_request["isEcho"] = isEcho
response = requests.post(
endpoint + path,
json=body,
auth=signer if signer else get_config_signer(),
timeout=(3.0, 15.0),
stream=isStream
)
if not response.ok: raise Exception(response.text)
return response
isStream の値によって response がどう変わるか確認しましょう。
まずは isStream = False
response = generate_text("Hello World!", isStream=False)
実行結果(HTTPの送信部分は割愛)
reply: 'HTTP/1.1 200 OK\r\n'
header: content-type: application/json
header: opc-request-id: /3496488D78C5CD0CDF26EE9BB2FB0AA6/D74C2D4052D6388F6F978687AE5D862C
header: content-encoding: gzip
header: content-length: 415
次に isStream = True の場合
response = generate_text("Hello World!", isStream=True)
実行結果(HTTPの送信部分は割愛)
reply: 'HTTP/1.1 200 OK\r\n'
header: content-type: text/event-stream
header: cache-control: no-cache
header: opc-request-id: /D3D62A8A778AA469C9422323D7499201/38B2082BD282C31DB8A76041CA9CF016
header: content-encoding: gzip
header: transfer-encoding: chunked
isStream = False のケースでは、レスポンスヘッダは content-type: application/json となりますが、isStream = True のケースでは、レスポンスヘッダは content-type: text/event-stream になり、さらに transfer-encoding: chunked も付加されています。
つまりこれは isStream の設定値によって response の処理の方法を変える必要があるということです。
まず、isStream = False の場合 content-type: application/json なので response は json として扱えます。
print(json.dumps(response.json(), indent=2))
""" 実行結果
{
"modelId": "cohere.command",
"modelVersion": "15.6",
"inferenceResponse": {
"runtimeType": "COHERE",
"generatedTexts": [
{
"id": "29189012-754a-46ef-b88f-64027687147d",
"text": " Hi there! How are you? I'm glad to talk to you. Feeling a bit conversational myself"
}
],
"timeCreated": "2024-04-16T01:40:25.011Z"
}
}
"""
isStream = True の場合は content-type: text/event-stream なので response を chunk 毎に処理します。生成されるテキスト部分のみが順次送られてきます。
for chunk in response.iter_content(chunk_size=None):
print(chunk)
""" 実行結果
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" Hi"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" there"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":"!"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" How"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" are"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" you"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" today"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":"?"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" \\""}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":"Hello"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" World"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":"!\\""}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" is"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" a"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" classic"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" and"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" simple"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" program"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" that"}\n\n'
b'data: {"id":"c725b000-f84f-4c95-90ba-bc79b3fea5a3","text":" prints"}\n\n'
"""
Stream で受け取る利点は、長く時間のかかるテキスト生成処理を最後まで待たずに処理ができることです。では実際どのくらい経過時間に差が出るか計測してみます。
import json, time
# 「Ellie という少女のおとぎ話を作って!」 ← かなり長い回答になることを期待
prompt = "Make up a fairy tale about a girl called Ellie."
# isStream = False の計測
start = time.time()
response = generate_text(prompt, maxTokens=2048, isStream=False)
print(f"elapsed time (isStream = False): {time.time() - start:.2f} sec")
# おとぎ話を取り出す
story = response.json()["inferenceResponse"]["generatedTexts"][0]["text"]
# isStream = True の計測
is_first_chunk = True
for chunk in response.iter_content(chunk_size=None):
if is_first_chunk:
print(f"elapsed time (isStream = True [first chunk]): {time.time() - start:.2f} sec")
is_first_chunk = False
print(f"elapsed time (isStream = True [complete]): {time.time() - start:.2f} sec")
# 最後におとぎ話を確認
print("--- story ---")
print(story)
実行結果
elapsed time (isStream = False): 15.37 sec
elapsed time (isStream = True [first chunk]): 0.41 sec
elapsed time (isStream = True [complete]): 19.81 sec
--- story ---
Once upon a time, in a quaint little village nestled among the rolling hills and towering trees, there lived a kind and spirited young girl named Ellie. Ellie had deep affection for the enchanted forest that surrounded her village, often spending her days wandering through its mystical paths, marveling at the dancing rays of sunlight that filtered through the branches.
One particularly sunny afternoon, as Ellie wandered deeper into the forest than she had ever been before, she stumbled upon a mesmerizing clearing. The air was fragrant with wildflowers, and the grass was soft and lush like a plush carpet. In the center of this enchanting space stood a magnificent tree, its branches stretching high into the sky, adorned with glittering gemstones that caught the light in a mesmerizing display.
Ellie was in awe of this magical tree and approached it with a sense of curiosity and wonder. As she reached out to touch one of the sparkling gems, she suddenly found herself transported to a strange and unfamiliar place. The ground beneath her feet was no longer grass but instead a soft, sandy expanse dotted with peculiar looking boulders.
Confused and a bit frightened by this unexpected turn of events, Ellie began to explore her new surroundings. She climbed atop one of the boulders and looked out over a vast desert expanse, the horizon kissed by the gentle glow of the setting sun. The beauty of this foreign land took her breath away, and a sense of adventure stirred within her heart.
As the last rays of sunlight faded away, Ellie realized she needed to find her way back home, but how could she return from this strange place? Just as she began to feel a sense of despair, a luminous glow caught her eye. It came from a solitary flower that grew amidst the boulders, its delicate petals shimmering with an otherworldly light.
Without hesitation, Ellie picked the flower and made her way back to the magnificent tree in the clearing. As she placed the glowing flower atop one of the branches, she found herself instantly transported back to the familiar forest clearing. Overwhelmed with gratitude, she hurried home, her heart filled with tales of her extraordinary adventure.
From that day forward, Ellie was known as the girl with the extraordinary tales. Whenever villagers or travelers passed through the enchanted forest, they would seek her wisdom and listen in awe as she shared her experiences of the mystical realm she had discovered. And so, the tale of Ellie, the girl who found the glowing flower, became a legend within the enchanting forest, passed down through generations, forever a source of inspiration and wonder.
The end.
isStream = False だと、このおとぎ話を読むのに 15.37 秒待たないといけません。
一方 isStream = True の場合、最初の chunk を受信するのが 0.41秒後なので、リクエストしてすぐにおとぎ話の最初の部分を読み始めることができます。
ところで、生成されたおとぎ話がすごくよくできていて感心しました!
(注: 2回の計測で同じストーリーが生成された訳ではもちろん無いです)
Python SDK で Stream する
Python SDK でも同様に Stream モードによる処理が可能です。
CohereLlmInferenceRequest の is_stream = True にすると、通常 レスポンスは GenerateTextResult になるところが oci._vendor.sseclient.SSEClient になります。
events() で個々の event データ(= 生成されたテキストの断片)を for ループで取り出せます。
import os, oci
from oci.generative_ai_inference import GenerativeAiInferenceClient
from oci.generative_ai_inference.models import \
GenerateTextDetails, OnDemandServingMode, CohereLlmInferenceRequest
compartment_id = os.environ["COMPARTMENT_ID"]
config = oci.config.from_file()
config["region"] = "us-chicago-1"
client = GenerativeAiInferenceClient(config=config)
prompt = "Hello World!"
# is_stream = True でテキスト生成
response = client.generate_text(
GenerateTextDetails(
compartment_id = compartment_id,
inference_request = CohereLlmInferenceRequest(
is_stream=True,
prompt=prompt
),
serving_mode = OnDemandServingMode(model_id="cohere.command")
)
).data # type: oci._vendor.sseclient.SSEClient
# 順次受け取るイベントの内容を表示
for event in response.events():
print(event.data)
実行結果
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" Hi"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" there"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":"!"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" How"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" are"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" you"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" today"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":"?"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" Feel"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" free"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" to"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" tell"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" me"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" about"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" yourself"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":","}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" or"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" ask"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" me"}
{"id":"fe28c12d-755d-46a3-9438-c988f5a450fd","text":" any"}
Streamlit で Chat UIを作る
では、Streamlit で実際に動く Chat UI を作ってみましょう。
Streamlit のインストールは pip で可能です。
pip install streamlit
Chat UI の作り方については このドキュメント (Build a basic LLM chat app) が参考になります。
import streamlit as st
import os, oci, json
from oci.generative_ai_inference import GenerativeAiInferenceClient
from oci.generative_ai_inference.models import \
GenerateTextDetails, OnDemandServingMode, CohereLlmInferenceRequest
compartment_id = os.environ["COMPARTMENT_ID"]
config = oci.config.from_file()
config["region"] = "us-chicago-1"
client = GenerativeAiInferenceClient(config=config)
def generate_text(
prompt,
max_tokens, frequency_penalty, presence_penalty, temperature, top_k, top_p
):
response = client.generate_text(
GenerateTextDetails(
compartment_id = compartment_id,
inference_request = CohereLlmInferenceRequest(
is_stream=True,
prompt=prompt,
max_tokens=max_tokens,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty,
temperature=temperature,
top_k=top_k,
top_p=top_p
),
serving_mode = OnDemandServingMode(model_id="cohere.command")
)
).data # type: oci._vendor.sseclient.SSEClient
for event in response.events():
yield json.loads(event.data)["text"]
st.title("Generate Text Chat Bot")
with st.sidebar:
st.header(f"options")
max_tokens = st.number_input("max tokens", min_value=0, max_value=65535, value=20)
frequency_penalty = st.slider("frequency penalty", min_value=0, max_value=1, value=0)
presence_penalty = st.slider("presence penalty", min_value=0, max_value=1, value=0)
temperature = st.slider("temparature", min_value=0.0, max_value=5.0, value=1.0, step=0.01)
top_k = st.slider("top k", min_value=0.0, max_value=500.0, value=0.0, step=0.01)
top_p = st.slider("top k", min_value=0.0, max_value=1.0, value=0.75, step=0.01)
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("メッセージを入力してください"):
st.chat_message("user").markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
response = generate_text(
prompt,
max_tokens, frequency_penalty, presence_penalty, temperature, top_k, top_p
) # type: generator
with st.chat_message("assistant"):
msg = ""
area = st.empty()
for text in response:
msg += text
area.markdown(msg)
st.session_state.messages.append({"role": "assistant", "content": msg})
generate_text(...) 関数は 最後に return ではなく yield を使っているので yield の度に呼び出した側へ値を返すジェネレータ関数として動作します。response = generate_text(...) の response はジェネレータ・オブジェクトですので、for 文でループして yield された値を処理します。
では、Python スクリプトとして保存して Streamlit で実行します。
$ streamlit run generate_text_chat.py
You can now view your Streamlit app in your browser.
Network URL: http://xxx.xxx.xxx.xxx:8501
External URL: http://xxx.xxx.xxx.xxx:8501
ローカルで実行していない場合は、ssh で 8501 番ポートをフォーワードして、ブラウザから http://localhost:8501 にアクセスして下さい。
では、最後にもう一度 Chat UI からおとぎ話を作ってもらいましょう。
(↓ 静止画像になっている場合はクリックするとアニメーションになります)
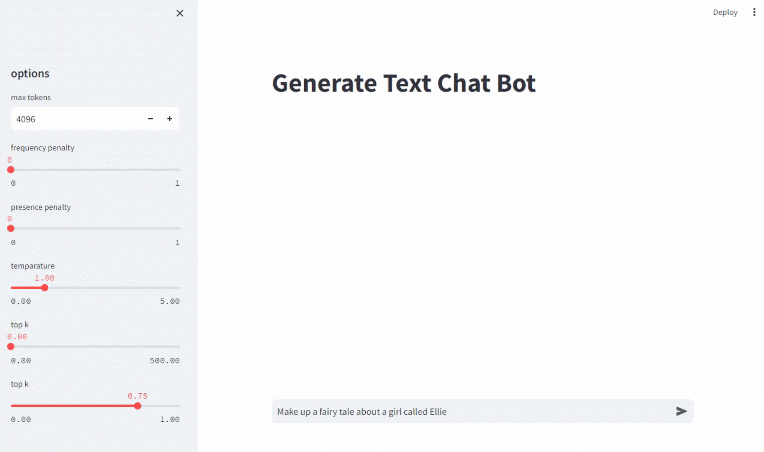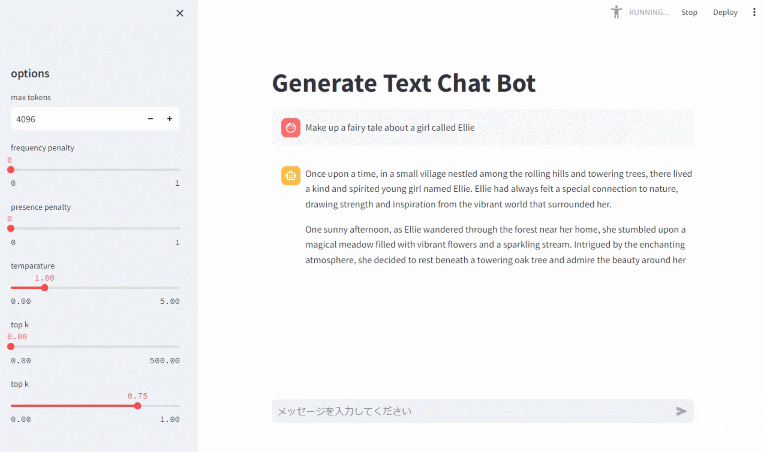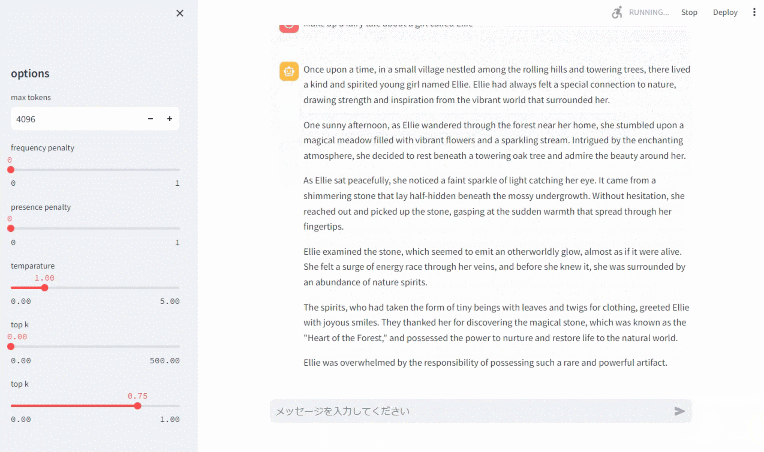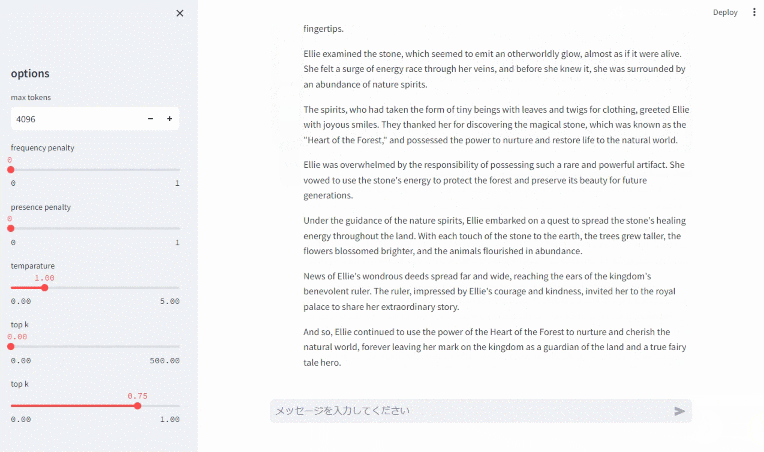
パラパラと流れる Chat UI ができました!