はじめに ー 週末研究ノートとは?
個人的に研究的な活動をやるにあたり、オープンにしてみたら面白いかもと思い、自分が興味を持っている ざっくりテーマについて、これから、ゆるい週末研究を公開していこうと思います。(有識者の方のアドバイスも、ちょっとというかかなり期待してます!笑)
どこかの権威的な学会やジャーナルなどで発表する予定はないため、万が一、私の記事を利用する際には自己責任でお願いします。そんな人はいないと思いますが、念のため。
今回のサマリ (TL; DR)
数年ぐらい前に、共著本を書く時に作ったモジュールを VSCode でもメンテできるように構成を整理しました。その流れでトークナイザの違いによる正答率、実行時間の違いを評価したのでシェアします。
環境
- Docker Desktop: 4.0.1(68347)
- コンテナのメモリ: 12G
- 自分の環境では、コンテナのメモリを 12GiB まで拡張しておかないと落ちました笑
- Docker: version 20.10.8
- docker-compose: version 1.29.2
- Python: 3.8.10
- GitHub リポジトリ
今回の週末研究ノート
概要
青空文庫、livedoor ニュースコーパスをデータセットとして、MeCab, Janome, Sudachi, Sentence Piece の4つの形態素解析器を用いて、精度(正答率)を評価しました。
コード上では、Nagisa でも評価できるようにコメントアウトしていますが、あまりに実行時間がかかるので、今回の評価対象から除外しました。
パイプライン
作ったパイプラインは、JpTokenizer クラスを継承した、JpTokenizerMeCab, JpTokenizerJanome, JpTokenizerSudachi, JpTokenizerSentencePiece クラス(のインスタンス)でトークナイズした後、tf-idf でベクトル化、その後、PCA で次元削減したベクトルと結合して、LGBM でクラス分類するものです。図に示すと以下の通りになります。
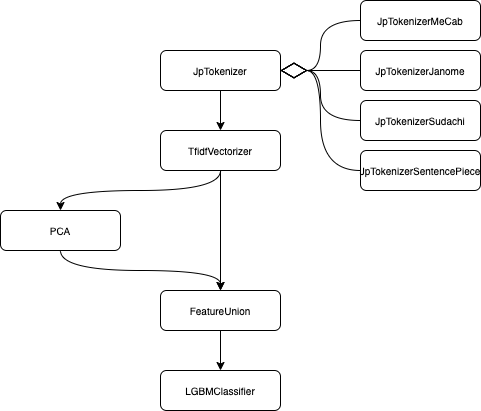
データをシャッフルしてデータ分割した後、同じデータセットでトークナイザを入れ替えて正答率を評価しました。
実行環境の準備
リポジトリのクローン
~/p/1 ❯❯❯ git clone https://github.com/tkosht/experiment.git
Cloning into 'experiment'...
remote: Enumerating objects: 275, done.
remote: Counting objects: 100% (275/275), done.
remote: Compressing objects: 100% (202/202), done.
remote: Total 275 (delta 85), reused 194 (delta 46), pack-reused 0
Receiving objects: 100% (275/275), 299.37 KiB | 499.00 KiB/s, done.
Resolving deltas: 100% (85/85), done.
~/p/1 ❯❯❯ ls
experiment/
ブランチ切り替え
~/p/1 ❯❯❯ cd experiment
~/p/1/experiment ❯❯❯ git switch text-classification
Branch 'text-classification' set up to track remote branch 'text-classification' from 'origin'.
Switched to a new branch 'text-classification'
~/p/1/experiment ❯❯❯ git branch
main
* text-classification
~/p/1/experiment ❯❯❯
コンテナのビルド&起動
~/p/experiment ❯❯❯ make
docker-compose build
Building app
[+] Building 6.3s (5/29)
=> [internal] load build definition from Dockerfile.cpu 0.1s
:
コンテナの起動確認
~/p/experiment ❯❯❯ make ps
docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------------------------------------------------------
experiment bash Up 0.0.0.0:5000->5000/tcp,:::5000->5000/tcp, 0.0.0.0:6006->6006/tcp,:::6006->6006/tcp,
0.0.0.0:8000->8000/tcp,:::8000->8000/tcp, 0.0.0.0:8080->8080/tcp,:::8080->8080/tcp,
0.0.0.0:9229->9229/tcp,:::9229->9229/tcp
~/p/experiment ❯❯❯
辞書のインストール
MeCab, Sudachi の辞書をインストールするには、コンテナ内で bash を起動し、backend ディレクトリ直下で make install を実行します。
~/p/experiment ❯❯❯ make bash
docker-compose up -d app
experiment is up-to-date
docker-compose exec app bash
dsuser@c6f99ce288f0:~/workspace$ cd backend/
dsuser@c6f99ce288f0:~/workspace/backend$ make install
sh bin/morph/install_mecabdic.sh
Cloning into 'mecab-ipadic-neologd'...
remote: Enumerating objects: 9210, done.
Receiving objects: 63% (5891/9210), 35.52 MiB | 246.00 KiB/s
:
実行
livedoor ニュースコーパス(ldcc)
~/p/experiment ❯❯❯ cd backend
~/p/e/backend ❯❯❯ make run-ldcc
青空文庫(aozora)
~/p/experiment ❯❯❯ cd backend
~/p/e/backend ❯❯❯ make run-aozora
実行結果
上記環境の準備ができたら、早速実行結果を見ていきます。
livedoor ニュースコーパス (ldcc)
~/p/e/backend ❯❯❯ cat log/run.log.ldcc | egrep '(datetime|Jp.*,)'
datetime, tokenizer, train_acc, valid_acc, elapsed_time, cpu_time
2021/10/18 22:53:16 , JpTokenizerMeCab, 1.0, 0.9561284486657621, 295.2752750000218, 451.85172472799997
2021/10/18 23:12:33 , JpTokenizerJanome, 1.0, 0.9547715965626413, 1155.6335971000372, 1299.311036286
2021/10/18 23:27:25 , JpTokenizerSudachi, 1.0, 0.9579375848032564, 892.0077779999701, 1033.869282912
2021/10/18 23:30:46 , JpTokenizerSentencePiece, 1.0, 0.9588421528720036, 200.03009699995164, 475.91284866800015
2021/10/18 23:34:40 , JpTokenizerMeCab, 1.0, 0.947535052012664, 231.71136680000927, 362.2309905950001
2021/10/18 23:54:15 , JpTokenizerJanome, 1.0, 0.9507010402532791, 1174.1650601000292, 1329.868560463
2021/10/19 00:12:01 , JpTokenizerSudachi, 1.0, 0.9538670284938942, 1065.5431799000362, 1220.2210928059994
2021/10/19 00:16:09 , JpTokenizerSentencePiece, 1.0, 0.9556761646313885, 245.5751178000355, 576.70874533
2021/10/19 00:19:28 , JpTokenizerMeCab, 1.0, 0.9611035730438715, 197.11452950001694, 347.50039318700055
2021/10/19 00:39:45 , JpTokenizerJanome, 1.0, 0.9574853007688828, 1216.471751700039, 1357.8573210659997
2021/10/19 00:54:54 , JpTokenizerSudachi, 1.0, 0.9611035730438715, 908.6285593999783, 1045.788085096001
2021/10/19 00:58:16 , JpTokenizerSentencePiece, 1.0, 0.9611035730438715, 200.6965769000817, 481.8085457010002
上のファイルをcsv に変換して、簡易分析してみましょう。
結果整形
以下のようにスクリプトを実行すると data/result/ 配下に csv ファイルとして結果ログを整形した結果を出力します。
~/p/e/backend ❯❯❯ ls data/result
ls: data/result: No such file or directory
~/p/e/backend ❯❯❯ sh bin/morph/to_csv.sh
~/p/e/backend ❯❯❯ ls data/result
aozora.csv ldcc.csv
~/p/e/backend ❯❯❯
正答率
検証セットの正答率をみてみます。
>>> import pandas
>>> df = pandas.read_csv("data/result/ldcc.csv", skipinitialspace=True)
>>> df.groupby("tokenizer").describe()["valid_acc"]
count mean std min 25% 50% 75% max
tokenizer
JpTokenizerJanome 3.0 0.954319 0.003415 0.950701 0.952736 0.954772 0.956128 0.957485
JpTokenizerMeCab 3.0 0.954922 0.006864 0.947535 0.951832 0.956128 0.958616 0.961104
JpTokenizerSentencePiece 3.0 0.958541 0.002726 0.955676 0.957259 0.958842 0.959973 0.961104
JpTokenizerSudachi 3.0 0.957636 0.003628 0.953867 0.955902 0.957938 0.959521 0.961104
livedoor ニュースコーパスを使ったクラス分類では、ほぼ、どのトークナイザを使っても 平均約95%の正答率で大きな差がないように見えます。標準偏差は、MeCab を除いて約0.3%程度で、SentencePiece の標準偏差が一番小さいようです。ただ、標準偏差が一番大きい MeCab でも 約0.7%と低いので大きく正答率はぶれないと推定できます。
また、若干、SentencePiece の正答率が高いように見えます。
実行時間
次は、実行時間をみてみましょう。
>>> df = pandas.read_csv("data/result/ldcc.csv", skipinitialspace=True)
>>> df.groupby("tokenizer").describe()["elapsed_time"]
count mean std min 25% 50% 75% max
tokenizer
JpTokenizerJanome 3.0 1182.090136 31.183736 1155.633597 1164.899329 1174.165060 1195.318406 1216.471752
JpTokenizerMeCab 3.0 241.367057 49.787622 197.114530 214.412948 231.711367 263.493321 295.275275
JpTokenizerSentencePiece 3.0 215.433931 26.105161 200.030097 200.363337 200.696577 223.135847 245.575118
JpTokenizerSudachi 3.0 955.393172 95.754011 892.007778 900.318169 908.628559 987.085870 1065.543180
>>> df.groupby("tokenizer").describe()["cpu_time"]
count mean std min 25% 50% 75% max
tokenizer
JpTokenizerJanome 3.0 1329.012306 29.282533 1299.311036 1314.589798 1329.868560 1343.862941 1357.857321
JpTokenizerMeCab 3.0 387.194370 56.477233 347.500393 354.865692 362.230991 407.041358 451.851725
JpTokenizerSentencePiece 3.0 511.476713 56.569456 475.912849 478.860697 481.808546 529.258646 576.708745
JpTokenizerSudachi 3.0 1099.959487 104.319964 1033.869283 1039.828684 1045.788085 1133.004589 1220.221093
>>>
経過時間(elapsed_time)、CPU時間(cpu_time) の平均を比べてみると、MeCab が一番小さく、最も高速であるとわかります。
正答率が良かった SentencePiece は、経過時間(学習時間を含む)もMeCab の次に小さく、それなりに高速であることがわかります。
青空文庫(aozora)
青空文庫に対しても、比較してみます。
正答率
>>> df = pandas.read_csv("data/result/aozora.csv", skipinitialspace=True)
>>> df.groupby("tokenizer").describe()["valid_acc"]
count mean std min 25% 50% 75% max
tokenizer
JpTokenizerJanome 3.0 0.792593 0.018900 0.771111 0.785556 0.800000 0.803333 0.806667
JpTokenizerMeCab 3.0 0.795556 0.021886 0.771111 0.786667 0.802222 0.807778 0.813333
JpTokenizerSentencePiece 3.0 0.829630 0.017824 0.811111 0.821111 0.831111 0.838889 0.846667
JpTokenizerSudachi 3.0 0.808889 0.032049 0.773333 0.795556 0.817778 0.826667 0.835556
>>>
青空文庫を使ったデータについては、SentencePiece 以外は、約 80% の正答率とほぼ同等ですが、SentencePiece は 約 83% と他のトークナイザよりもよい結果になりました。また、標準偏差についても1.8% と正答率のばらつきも一番小さく、より安定する正答率が期待できる結果になりました。
実行時間
>>> df = pandas.read_csv("data/result/aozora.csv", skipinitialspace=True)
>>> df.groupby("tokenizer").describe()["elapsed_time"]
count mean std min 25% 50% 75% max
tokenizer
JpTokenizerJanome 3.0 2413.819408 49.390590 2363.523425 2389.603184 2415.682944 2438.967400 2462.251857
JpTokenizerMeCab 3.0 88.271292 8.092714 83.573667 83.598984 83.624301 90.620104 97.615907
JpTokenizerSentencePiece 3.0 340.076074 6.913173 333.385537 336.518002 339.650467 343.421342 347.192218
JpTokenizerSudachi 3.0 1620.522197 114.059864 1545.804074 1554.878440 1563.952807 1657.881259 1751.809711
>>> df.groupby("tokenizer").describe()["cpu_time"]
count mean std min 25% 50% 75% max
tokenizer
JpTokenizerJanome 3.0 2474.472940 52.376899 2421.456101 2448.616641 2475.777180 2500.981360 2526.185539
JpTokenizerMeCab 3.0 153.270915 5.526774 148.152682 150.340750 152.528819 155.830031 159.131243
JpTokenizerSentencePiece 3.0 724.512431 9.514062 713.611898 721.195443 728.778988 729.962697 731.146407
JpTokenizerSudachi 3.0 1683.941731 119.669483 1605.085597 1615.092507 1625.099417 1723.369797 1821.640178
>>>
livedoor ニュースコーパスと同じく、経過時間(elapsed_time)、CPU時間(cpu_time) の平均を比べてみると、MeCab が一番小さく、次に SentencePiece という結果になりました。
以前比較評価したときは、Sudachi が結構時間がかかる印象でしたが、Janome の処理速度にかなり近づき実用上でも十分な速度になったのは、驚きでした。
データセットとモデルの保存
評価に使ったデータは、data/dataset 配下に保存され、モデル・パイプラインは、data/model 配下に保存されます。正答率や実行時間以外の指標値で評価したい場合は、これらの保存された結果を用いて分析することができます。
~/p/e/backend ❯❯❯ ls data/dataset
aozoraset.gz aozoraset_iter01.gz ldccset.gz ldccset_iter01.gz
aozoraset_iter00.gz aozoraset_iter02.gz ldccset_iter00.gz ldccset_iter02.gz
~/p/e/backend ❯❯❯ ls data/model
pipe-jptokenizerjanome.gz pipe-jptokenizersentencepiece.gz
pipe-jptokenizermecab.gz pipe-jptokenizersudachi.gz
~/p/e/backend ❯❯❯
まとめ
- VSCode を使ってメンテできるように、リポジトリを整備
- 整備ついでに、トークナイザの違いによる正答率、実行時間を評価
- 正答率で比較すると、SentencePiece がほんの少しですが平均が高く、標準偏差が小さく安定した正答率が望める結果になった
- 実行時間で比較すると、経過時間、CPU時間、ともに MeCab が最も小さく、高速である結果になった
- Sudachi がかなり高速化された様子で、今後の更なる高速化に期待感が湧き上がった
- 比較評価するために使ったデータ、モデル(パイプライン)はファイルとして保存されるように作っている
- 正答率、実行時間以外で評価したいときは、これらを用いて評価することができる
次回は、保存した結果を用いて、可視化などの分析をやってみたいと思います
参考文献
- 今回は、過去に作成したものを掘り起こして再評価したものなので、参考文献はなし