はじめに
IO500 というベンチマークをご存じでしょうか。IO500はファイルアクセス性能を測るベンチマークとしてSC'17から始まりました。
最新のリストでもエントリ数は51と、まだ規模が小さいものですが、スコア変動が大きかったり新規のシステムが次々と登場してきたりで、
その界隈に身を置くものとしては毎回の発表が楽しみなもののひとつです。
ほとんどの方にとってIO500って何しているかわからん状態だと思うので、本稿ではIO500について簡単に紹介します。
IO500のベンチマーク内容
IO500のベンチマークは、大きくbw(bandwidth)とmd(metadata)で構成されています。
ざっくりいうと、bwはファイルのread/write性能(GiB/s)、mdはファイルのcreation/stat/removal(kIOP/s)性能です。
それぞれにeasy/hard(mdでは+find)の測定項目があります。easyは測定オプションを自由に決められるもので、システムが一番得意としているアクセスの性能を表していると言えます。
一方、hardはオプションが(一部を除いて)固定、かつ、ファイルシステムがあまり得意としていないアクセスを行うもので、システムが不得意なアクセスをされた時の性能を表している、という理解で凡そ間違いはないでしょう。
具体的な内訳は以下のようになっています。
- bw: IORで測定。
- easy(IOEasy)
- 自由にIORのオプション(ファイルサイズや一度のIOサイズなど)を決めてOK
- ランク(プロセス)別ファイル、大きなIOサイズが指定されることが多い
- 各システムが一番得意なread/writeの性能
- hard(IOHard)
- ランク(プロセス)共有ファイル、47,008バイト単位のストライドアクセス
- 一般的にシステムが不得意なread/writeの性能
- 共有ファイル、中途半端なIOサイズは性能が悪くなりやすい
- easy(IOEasy)
- md: mdtestで測定
- easy(MDEasy)
- 自由にmdtestのオプションを決めてOK
- ランク(プロセス)別ディレクトリ指定が多い
- hard(MDHard)
- ランク(プロセス)共有ディレクトリ、作成ファイルに3901byte書き込み
- 一般的にシステムが不得意な作成/削除性能
- 共有ディレクトリの作成削除は性能が悪くなりやすい
- find
- ファイルの検索性能
- easy(MDEasy)
bw、mdはそれぞれの測定項目の相乗平均でスコアが算出され、さらにbw、mdの相乗平均がIO500スコアとして算出されます。
ランキング部門はシステムトータル性能、10 Node Challenge(10クライアントノード性能)に分かれています。サーバ台数に関するルールは無いです。
最新のリストに登場するシステムの紹介
最新のリスト を見ると、聞きなれない名前が多いと思うので、Top 10に名を連ねているシステムについて簡単に紹介します。
リストのfilesystem type列がファイルシステムの名前です。
MadFS
謎のファイルシステムです。中国で開発されているようですが、それ以外の情報が一切ありません。ググると同名の論文が出てきますが、おそらく関係ありません。
DAOS
ANLの次期スパコンAurora で採用されている、不揮発性メモリをベースとしたシステムです。DAOS自体はオブジェクトストレージで、ファイルシステムはオブジェクトストレージのAPIを使って実装されています。もう少し踏み込んだに概要ついては、昨年の記事を参照いただけると幸いです。
WekaIO Matrix
WekaIO社が開発しているファイルシステムです。内部アーキテクチャについてはあまり公開されていないですが、AWSのマーケットプレイスで提供しているので使ってみたい方は使ってみてください。国内での導入事例は私の知る限り無いです。
Lustre
スパコンやっている人ならおそらく知らない人はいない分散ファイルシステムです。他のシステムが比較的新しい中、Lustreは昨年20周年を迎えました。
改善に改善を重ねているため、内部実装は結構複雑な気がしますが、新システムに食らいついてよく頑張っているなぁというのが素直な感想、、、
IME
Data Direct Network(DDN)社製のBurst Bufferです。Oakforest-PACSをはじめ国内でも複数個所で導入されています。
BeeGFS
元はドイツのFraunhoferで研究されていたファイルシステムで今はThinkParQが主体となって開発しています(GitLabはpublicだけど開発は確かclosed)。
軽量、簡単を一つの売りにしているようで、国内では共有ファイルシステムとしてではなく、計算ノードに搭載されたSSDで一時的な分散ファイルシステムを作る(BeeOND)用途で導入されている例があるようです。(ABCI, 不老)
Top10圏外ではありますが、NextGENIOのGekkoFSも新規のファイルシステムとして高い性能を出しています。IBMのGPFSは影を潜めていますが、SC'18ではSummitのシステムとして1位を獲得しています。国産ファイルシステムとしては10 Node規模ですがGfarmもエントリしています。その他のシステムも興味があればぜひググって出自を調べてみてください。
スコアの内訳を少し見てみる
リスト のdata列にあるzipファイルをダウンロードすると、各エントリの測定内容の詳細を見ることが出来ます。
スコアが似ていても、内訳は大きく異なる場合があるため、システムの得手不得手は詳細を見ないとわかりません。
例えば、Tianhe-2(bwランキング11位)とWolf(bwランキング12位)のbwの内訳は以下のようになっています。
| システム | bw(GiB/s) | easy write(GiB/s) | easy read(GiB/s) | hard write(GiB/s) | hard read(GiB/s) |
|---|---|---|---|---|---|
| Tianhe-2(Lustre) | 209.43 | 608.64 | 665.58 | 31.87 | 161.64 |
| Wolf(DAOS) | 183.36 | 108.24 | 308.91 | 122.91 | 275.09 |
bwのスコア自体は大きく違いませんが、Tianhe-2(Lustre)はeasyとhardの差が激しいのに対し、Wolf(DAOS)ではeasyとhardでほぼ差がない(というかwriteはhardのほうが高い)、といったようにシステムによって性能特性は大きく異なります。
これだけ見ると、Wolf(DAOS)はeasyもhardも同じくらい出るので使い手からするとあまりチューニングしなくてもよいようなイメージを受けます。(実際は知りません)
一方のTianhe-2(Lustre)は、共有ファイルよりもプロセス別ファイルを使ったほうがread/write性能が高く、ファイルシステムの性能を活かすためには、そのようなファイルアクセスをするようにアプリケーションを書き換える必要があるように見て取れます。
スコアの変遷
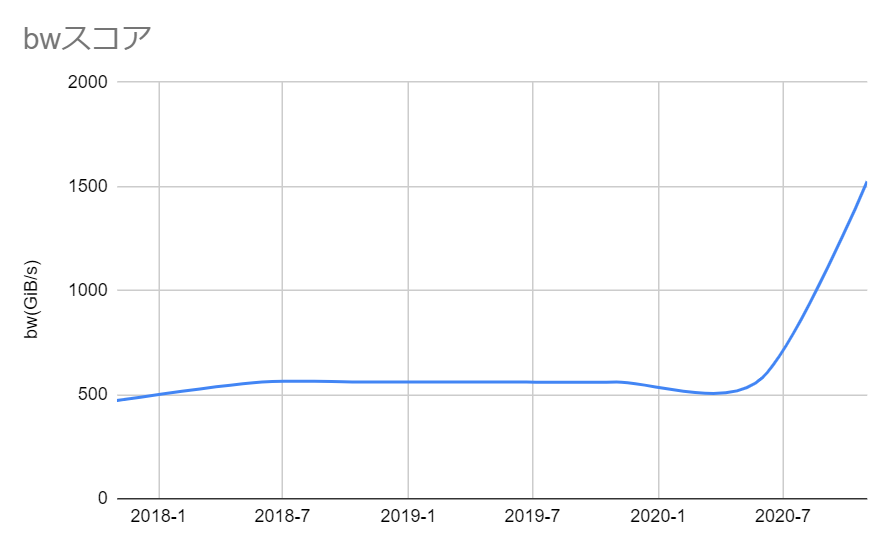
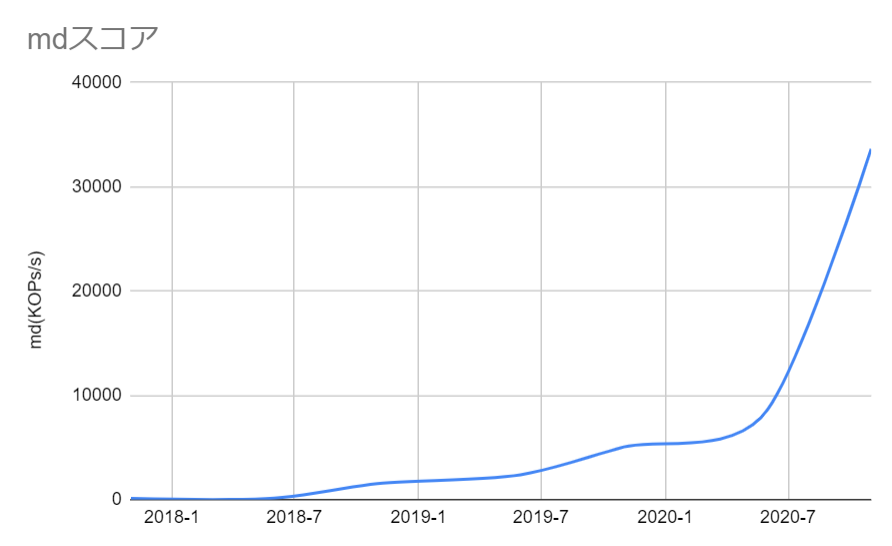
次にSC'17からSC'20のbw、mdのトップのスコア変遷をプロットしてみて、傾向を見てみます。
bw
SC'20でMadFSが登場したことで一気にスコアが3倍程度に跳ね上がっていますが、後述するmdの伸びに比べると比較的緩やかな伸びになっています。
MadFSについては公開情報が全くなく全様が謎なので、今後公開されたらもう少し見ていきたいと思います。
md
bwに比べるとmdのスコア向上はすさまじく、SC'17とSC'20で約320倍スコアが伸びています。個人で調べた限りですが、最近の研究(例. IndexFS)ではbwをどう上げるかよりも、大量のファイルをどうさばくかといったmd性能の向上にフォーカスを当てているものが多く、それがIO500のスコアの伸びにも表れているのだろうと思います。
DAOSやMadFSの登場によって、大分行くとこまで行った気もしますが、これら二つについてはまだ測定規模が小さいのもあり、Auroraでの全系測定などが今後行われたら、またどんでもない数値が出てくるのかなぁ、と期待しています。
おわりに
IO500についてのざっくりとした紹介をしました。かなり大雑把な説明になってしまった気がするので、質問やガチ勢からのコメントお待ちしています。