この記事は Nutanix Advent Calendar 2023 の16日目として作成しました。
※ 発言は個人の発言であり、帰属する組織とは何ら関係がありません
※ 発言は個人の発言であり、帰属する組織とは何ら関係がありません
はじめてのアドベントカレンダーなので何をどういうテンションで書いて良いかわかっておりません。
いつでもどこの会社でも雑食系ソリューションアーキテクトの鈴木です。
takanorisuzukiのほうです
GPT-in-a-BOX 突如現る
これを見ているようなコアな方々はすでにご存知だと思いますが、2023年8月15日に突然 とち狂ったかのように GPT-in-a-Box というものをNutanixが発表しました。

GPTは入ってないけどGPT-in-a-BOX
Nutanixはハードウェアを売ってないけどGPT-in-a-BOX
この発表を見た瞬間にカーネルパニックが起きたのか、BSODが起きたのかわからない感じになったことを鮮明に覚えています。
そして個人的にはGPT-in-a-BOXという言葉を極力使わないようにしています。
(それでも日々の業務はGPT-in-a-BOXに追いかけ回されています)
GPT-in-a-BOXとは 「誰かNutanixの上でGPTを動かしてほしい」 という気持ちを最前面に押し出した結果生まれたワードだと理解しています。
Japan SA TeamではGPT-in-a-BOXの代わりにAI on Nutanixという名称に変えてお話しています。
個人的にはAIと呼ぶのも苦手で、MLの方がしっくり来ます。
私の中のMLとはMachine Learningではなく Muscle Learningです。
大量の電気と水を消費しながらGPUをぶん回して巨大なデータをひたすら休みなく動かして学習させる「脳みそまで筋肉」という考え方です。
筋肉は裏切らない
--- 閑話休題 ---
ChatGPTによるAIの民主化
GPTやLLMという流行り言葉を聞いたらついついみんなでお祭り騒ぎして踊り出したい気持ちをグッと堪えて整理してみます。
AI/MLクラスタでは2017年からTransformerフィーバーが始まっていたのを横目でチラチラみていたのですがChatGPTの登場でITにも詳しくない人にまで革命を起こしたChatGPTの勢いが止まりません。
1998年のGoogle登場以来の大変革が起きているのは多くの方が感じていると思います。
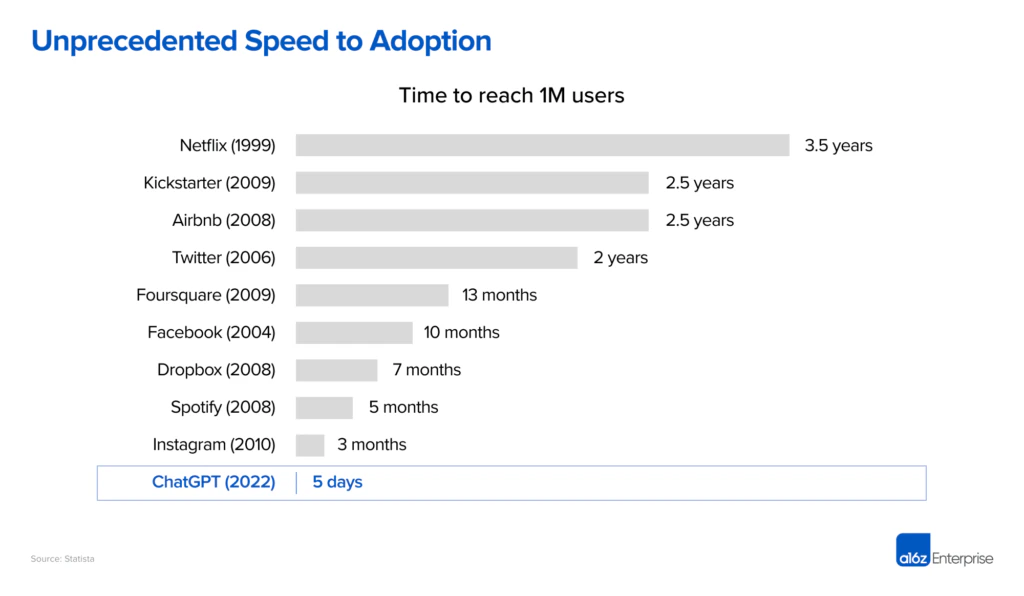
Source: The Economic Case for Generative AI and Foundation Models
私の娘は中学校の宿題で随筆を書かなくてはいけなかったのですが、私は随筆の書き方なんて習った記憶がないのか、加齢により忘れてしまったのかさえ定かではないのでChatGPT先生を与えたら驚きの成果物を提出していました。
ChatGPTの回答をそのまま使うのではなく、テーマ選定やストーリー作成のヒント、文章校正などに使っていて、AI-Native世代が来る日も遠くはないと感じています。
AIとは
ググってくだs GPTってください。
なんて読めばいいんだろう、「じーぴーてぃー」ってください?
フォニックス的には、「ぐぷとぅ」ってください?
動詞化されるのも過去最速になると思うので正式な呼称についてはもうしばらくお待ち下さい。


なんでNutanixがAIなのか
生成AIってGPU大量に使ってるとか、そのための電力と水を入手するために新しい発電所やデータセンターを水のある場所に作るとか、何とかB(ビリオン)の学習したモデルとか話題になりますが、データがあってこそのAIです。
何とかBは学習データの話でしょ?と思ったアナタ、そういうことじゃないです。
インターネットの半分は優しさで出来ています。残りの半分は嘘や欲望で出来ています。(個人の感想です)
どんなに公開情報を大量に学習したとしても、突拍子もないことを言うやつとか、嘘つくやつは使い所が難しいです。
企業にとって価値のあるデータとは何かということを忘れてChatGPTに勤しむ方はここでお別れです。
異世界に住んでいるHappy Peopleの例(閲覧注意)
- プロンプトテンプレート作り続けてテンプレ公開
- プロンプト公開前には承認のためのハンコリレー
- スプレッドシートでプロンプトテンプレート管理
- プロンプトエンジニアリングで最適な回答が出せるようにひたすら壁打ち
生成AIを使って、全く同じアウトプットを10回連続で出せたら神の領域です。
新しいモデルが出るたびにゼロリセットされることは先にお伝えしておきます。
多くのエンタープライズ企業において本当に価値があるデータって、現場で働く人達のパソコンやファイルサーバの中に眠ってる情報だったり、紙の書類だったり、ノウハウとして人の頭の中にあったりします。
Microsoftさん、Office系のデータをバイナリではなくテキストで読ませてください、お願いします。バイナリではなくテキストがほしいんです。お願いします。
デジタル化されていない、もしくはデジタル化されていても成形されていない有象無象のデータが企業の至る所に散りばめられていて、それをすべて一箇所に入れて正規化したデータにするというのも気の遠くなる作業です。
しかしデータを持たないAI/MLに価値はありません。
AI/MLは所詮コンピュートであり、データをINPUTしたらデータをOUTPUTするものです。
テキストや音声、画像、動画などのマルチモーダルLLMは、ユーザーインタフェースに似ています。
いずれにしてもデータがすべてです。
Nutanixはデータ管理に強みを持つプラットフォームです。
ここで一旦CMに入ります。
お早めにトイレや飲み物の準備を済ませてお戻りください。
休憩後のウォーミングアップとして、以下の文章を早口で息継ぎなしで読み切ってください。
Nutanixはシステムの置き場所に関わらず、データと計算リソースを提供できて、壊れたら勝手にソフトウェアでオートヒールするクラウドみたいなシステムだった。とくにエッジはIT管理者も不在で保守員も駆けつけにくい、AIアプリで使いたくなるオブジェクトストレージもあるし、ファイルサーバもある、DBaaSも持ってた! OSS組み合わせて自前で作っても運用が大変だしアップグレード地獄になるくらいならオンラインで1クリックアップグレードできるNutanixが便利!
Nutanixを初期からご存知の皆様はVDIに向いているという印象をお持ちの方も少なくないと思いますが、VDIよりももっと相性がいいのがエッジの推論サーバです。
特にAI/MLアプリではオブジェクトストレージ使いたい!
スモールスタートできて性能は出るやつ、スケールアウトしたい、管理は楽したいとかなってくると選択肢が狭くなります。
AI/MLアプリのライフサイクル
AI/MLワークフローのステップ
AI/MLアプリのサービス提供や運用を考えるとクラウド事業者でも採用しているKubeflowが広範なエコシステムを持っていて選択肢としては有力ですね。
Kubeflowについての詳細は公式サイトをご覧ください。
公式サイトでも触れられていますがAI/MLアプリのワークフローではいくつかのステップが必要になります。
- データの準備
- モデルトレーニング
- 予測サービス
- サービス管理
1. データの準備
この話題だけでアドベントカレンダーが埋まってしまうトピックなので、データ整理するポイントを記載します。
- どんなデータを持っているのか
- そのデータはどこにあるか
- そのデータ量は一定か、それとも増えるか
- そのデータはどうやって入手したのか
- なぜそのデータを持つのか
- そのデータの所有者は誰か
- 誰のデータを持っているのか 、誰のものか確認する方法はあるか
- そのデータを利用するのは誰か
- そのデータを外部の誰かと共有しているか
- データは国境を越えているか
- 内部的には誰がそのデータにアクセスできるのか
- そのデータに外部からアクセスできるのは誰か
Source: takanorisuzuki
データは紙からスキャンしただけだとやはり取り扱いにくいし、異常値や欠損なども考えるとデータを整形する前処理サーバも必要ですね。
全データをパブリッククラウドに上げて、全部読み出ししやすい形で収集できる新規システムは問題ないですが、既存のデータを活用するとなると色々大変な作業が待ち受けています。
2. モデルトレーニング
多くのエンタープライズ企業においては、高価なGPUを数万枚持っているパブリッククラウド事業者やOpenAI, Metaの方々たちと同じ土俵でベースモデルを作るのは現実的ではありません。彼らの作ったベースモデル上で新たに日本語学習をさせている日本語対応モデルや、国内でも一からベースモデルを作ってくれている企業もありますので、そういった先人達の知恵を有効利用させてもらいましょう。
HuggingFaceにも様々なモデルが転がっているので眺めているだけでも楽しいです。
野良モデルがカオスなのでセキュリティ意識高い系でお願いします
3. 予測サービス
実際にユーザーにAI/MLサービスを提供するフェーズです。
すべてパブリッククラウドで実行することもできますが、ユーザーの近くで推論したいケースやネットワークが切断したときでも動いてほしいという要望も出てきます。
そのためにはサービス提供する場所の近くのエッジに推論サーバとストレージを設置することになります。
4. サービス管理
AI/MLアプリは作って終わりではありません。
現場で利用されているログや現場で新たに取得した最新データを収集して、AI/MLアプリの改善をする必要があります。エッジで推論している場合は、AI/MLアプリだけでなくエッジのインフラ環境の更新も必要になります。
AI on NutanixのChatBot活用例
社内専用ChatGPTのイメージについては以下のYoutubeにありますのでご覧ください。
この動画では企業のエッジとデータセンター間でAI/MLアプリを展開する例が紹介されています。
現場の方は常日頃のビジネスに有用なデータを特定の場所に保管しておくだけで継続的に賢くなってくれるようなイメージです。
- チャットBOTに質問しますが好ましくない回答をされます
- エッジ側で正しい回答を返すために必要なドキュメントをオブジェクトストレージにアップロードします
- アップロードされたコンテンツが自動的にデータセンター側のオブジェクトストレージに同期されます
- コンテンツが更新されたことを検知すると自動でモデルをファインチューニングします
- ファインチューニングされたモデルをエッジに自動展開します、複数エッジ拠点でも大丈夫です
- もう一度同じ質問をすると、初回よりも好ましい回答を返します
前提
- 最新データはエッジ拠点やビジネスの現場で生まれる
- そのデータはインターネット上に流出させたくない、または大きさや速度、拠点数などの制約でクラウドに上げられない
- モデル自体に機密情報を学習させると、モデルの流出も情報漏洩のリスク
この動画の例ではファインチューニングしていますが、モデルに機密情報を学習させたくなければRAG(Retrieval-Augmented Generation)を使うだけでもある程度の回答が出せますし、多くのユースケースではこれでも十分です。
RAGを使う場合もやはり推論サーバの近くにストレージが必要となります。
RAGについて興味のある方向けにNVIDIAさんのブログ記事を載せておきます。
Retrieval-Augmented Generation (RAG) とは?
そろそろ疲れてきたので本題
GPT-in-a-BOXって何それおいしいの?
というテーマで書いてきましたが、GPT-in-a-BOXは実体を持たない希望的観測ということは冒頭にお伝えした通りです。概念であり、象徴であり、シンボルです。
AI/ML用のインフラ整えるのって設計や導入も大変だし、とくにインフラ運用なんて考えたくないですよね。だからパブリッククラウドでいいじゃん!ってなるんですが、データを全部クラウド上げるの面倒だしネットワーク切れたら困るし。。。
万が一クラウド事業者を変えたいってなったら、すべてのデータを転送すると通信量で大変なことになるので、重要なデータはお守りとして手元に持っておきたいという企業も少なくないです。このGPT-in-a-BOXという概念の本質は、Nutanixを使うとエッジAIユースケースでほしい機能が一通り揃っていることです。
- スモールスタートできるオブジェクトストレージもファイルサービスもついています
- もしハードウェアが壊れてもソフトウェアで勝手にデータ冗長化を保ちます
- KubernetesとかKubeflowとか面倒なやつは1クリックで展開されます
- コンテナで面倒なパーシステントボリュームもよしなに管理してくれます
- 箱を追加すると勝手にシステムがスケールアウトします
- 物理ファームウェアやNutanix、K8Sなどのアップグレードもオンラインで1クリックです
- インターネット接続やネットワークが切れたときでも単独で稼働できます
- リモートに箱を準備すると多拠点でDRが組めます
- パブリッククラウドのオブジェクトストレージとのレプリケーションもできます
- Azure Arc, Google Anthos, Amazon EKS Anywhereのエッジとしても動きます
つまりエッジ推論サーバとして相性がいい
はじめの一歩 - ChatBot
AI/MLの進化により今まで出来なかったことができるようになってきました。
一番簡単に始められるユースケースの代表が社内Chatbotです。
ChatBotは検索の上位互換であり、キーワードではなく自然言語で欲しい情報を見つけてくれます。
どの企業でもキーになるベテランは社内外のことをよく知っていますが、その人に24時間問い合わせることは出来ないですよね。
相手の時間を使ってしまうので下手な質問も出来ません。
ChatBotなら24時間、嫌な顔せずに聞くことができます。
ここまでは普通の考え方。
価値のあるデータはその先にあります
いつでも誰でも下手な質問かどうかを気にせずに質問できるようになります。
つまりこの質問の中には、その人が本当に知りたかったことが隠されています。
顧客が本当に必要だった物

Source: ニコニコ大百科
1998年にGoogle検索が登場してからここまで成長できたのは、この顧客が本当に必要だった物を検索エンジンを通して知ることが出来たことが大きな要因になっています。
今、多くの企業がAI/MLを活用することで、自社でその情報を入手することができます。
さて、ChatBotを利用するのは誰ですか?
- お客様
- 株主
- 従業員
- 関連会社・パートナー企業
企業にとってステークホルダーになる方々が本当に知りたいことを理解することは大切です。
ChatBotも取り扱うデータによって段階があります。
まずインターネットなどの漏洩しても困らないデータから取り扱い始めて、自社に関する公開情報、そして自社の機密情報、最終的にはユーザーの個人情報を用いてパーソナライズドサービスが展開できるようになります。
利用者とアクセスできるデータの種類を整理しながら進化していくのが理想
日本は近い将来人口半減、地球温暖化、世界食糧危機、様々な社会的課題がありますが、AIは人がやりたくないこと、やらなくてもいいことを代わりにひたすらやってくれて、最終的に大きな課題を解決する手助けをしてくれます。
私達、ホモ・サピエンス(自称)は、お客様が本当にほしかったものを正しく理解してそれを提供するためにすべてのリソースを投入しましょう。
このAIによる変革期を一緒に勉強しながら成長してくれるエンジニア仲間を募集しています。
We are Hiring!
そういえばwasmedgeってタグつけてたの忘れてた
ソリューションアーキテクトはエンジニアの類いなのでちょっとだけ興味のある技術を紹介しておきます。
実は最近、コンテナが重くて遅いしちょっと飽きてきたのでもういいかなと思ってWasmedgeに手を出し始めました。
どんな技術でもいいのですが、データとネットワークはいつも制約だらけという課題は未だに解決できていません。
Wasmedgeって何だろうと思った方はUbuntu Server 22.04あたりを使って触ってみてください。
まずはWasmedgeのインストールと日本語モデル(Calm2-7B-Chat-GGUF)、Chatbotアプリ(llama-chat.wasm)をダウンロードします。
(CyberAgent様ありがとうございます。)
sudo apt update && sudo apt install -y libopenblas-dev git curl
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install.sh | bash -s -- --plugin wasi_nn-ggml
source $HOME/.bashrc
curl -LO https://huggingface.co/second-state/Calm2-7B-Chat-GGUF/resolve/main/calm2-7b-chat.Q4_K_M.gguf
curl -LO https://github.com/second-state/llama-utils/raw/main/chat/llama-chat.wasm
そしてCLIベースのChatBotを実行
wasmedge --dir .:. --nn-preload default:GGML:AUTO:calm2-7b-chat.Q4_K_M.gguf llama-chat.wasm -p vicuna-1.1-chat --stream-stdout
チャットに聞いてみる
[You]:
Nutanixってどんな会社?
Nutanixは、ハイパーコンバージドインフラストラクチャ(HCI)市場におけるリーダー的存在です。同社は、仮想化ソフトウェアとストレージアプライアンスを組み合わせて、シンプルな管理と高いパフォーマンスを実現しています。Nutanixは、データセンターの仮想化、自動化、および簡素化に重点を置いており、企業向けにクラウドのようなエクスペリエンスを提供しています。Nutanixは、VMware、Microsoft、およびOpenStackなどの主要な仮想化プラットフォームと統合しています。また、Nutanixは、HPE、Dell EMC、Lenovo、およびHitachiなどの主要なハードウェアベンダーと提携しています。
ちょっと情報が古いですが世間一般の認識と大きくズレている感じではないですね。
私はIntel Macを使っているのですが手元のMacbook環境でも快適に動作しています。
今まであまり口に出したことなかったのですが、Calm が大好きです。
$ ls -l
total 4172936
-rw-rw-r-- 1 nutanix nutanix 4270416736 Dec 14 07:31 calm2-7b-chat.Q4_K_M.gguf
-rw-rw-r-- 1 nutanix nutanix 2660562 Dec 14 06:58 llama-chat.wasm
ファイルサイズを見てみるとCalm2が4.2GBちょっとで、wasmアプリにおいては2.6MBです。
これにオブジェクトストレージやファイルサーバに入れているデータをRAGで引っ張ってくるだけでも色々幸せになれそうですね。
tsuzumiのような国産LLMも出てきているので、新しいAI時代の幕開けをみんなで楽しみましょう。
私は本日から年末休暇に入ります。
それではまた来年、皆様良いお年を。
A Happy New AI Year!!