TensorFlow等の機械学習ライブラリの使い方を勉強していくと「何か動くものを作ってみたい!」と考えると思います。
今回はTensorFlowLiteとLINE Messaging API、Herokuを組み合わせて画像分類BOTを作ってみたいと思います。
Herokuを使う理由
作成したアプリのデプロイ先にはAWSやGCPなど様々な選択しがあります。
Herokuは無料枠が用意されており比較的簡単に使い始めることができます。
無料枠には起動できる仮装環境の数や一月あたりの使用時間制限など制約がありますが、
サンプルのAPPをデプロイする環境としてはおすすめです。
TensorFlowLiteを使う理由
本記事ではデプロイ先にHerokuの無料枠を使用しています。
無料枠では保存容量が300MB程度に制限されています。
そのため、モデルの容量を小さくできるTensorFlowLiteを使用しています。
LINE Messaging APIを使う理由
機械学習を組み込むアプリにはAndroidやiOSのスマホアプリやWEBアプリなどいろいろあると思います。
TensorFlowには、AndroidやiOSのそれぞれの環境に対応したライブラリがありますが、
それらを使用するためにはもちろんアプリ開発の知識が必要となります。
また、TensorFlow.jsを使えばブラウザまたはNode.jsでアプリを作成することもできます。
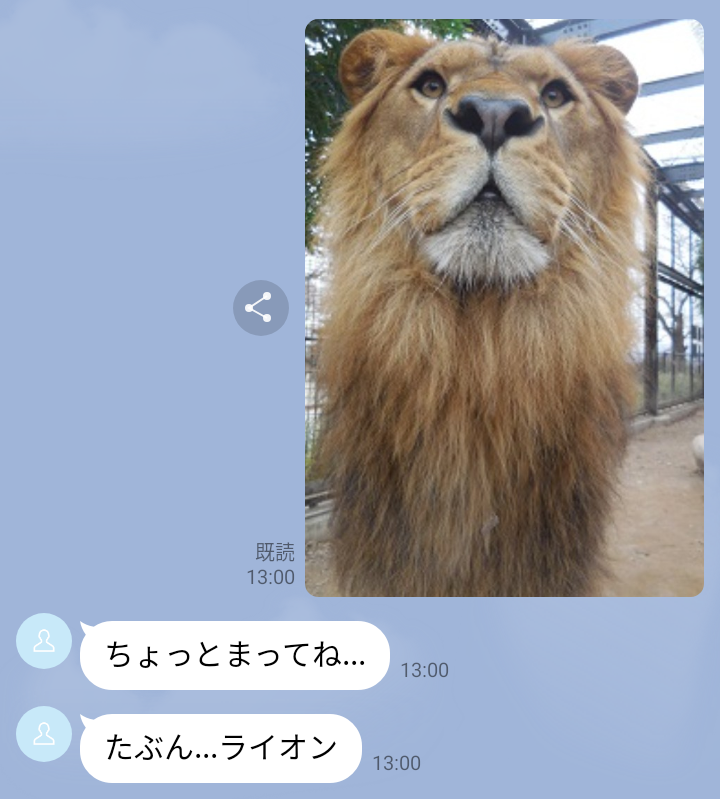
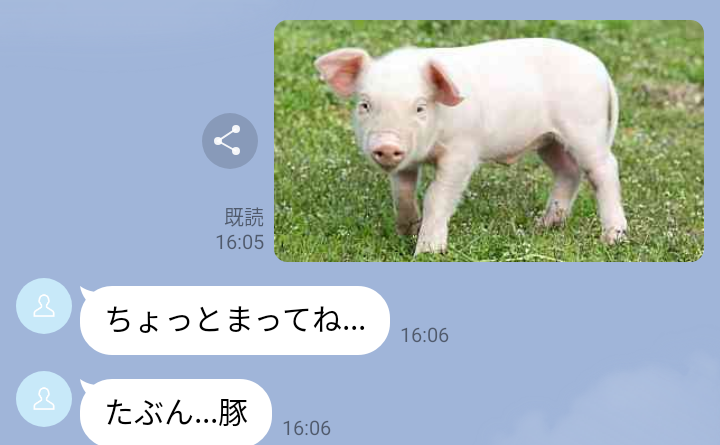
今回作成するアプリは「ユーザーから送られてきた画像に写っているものを分類する」ものです。
スマホアプリとして作成する場合には、スマホアプリとバックエンドの両方を開発する必要があります。
ブラウザで動作させるアプリではないのではないこと、最小限のコードでアプリ開発を行いたいとの理由からLINE Messaging APIを使うことにしました。
オウム返しBOTを作成してみる
BOTの動作を確認するために簡単なオウム返しBOTを作ってみたいと思います。
LINE Messaging APIの動作の流れを簡単に説明したいと思います。
- ユーザーがLINEプラットフォームへメッセージを送信する。
- LINEプラットフォームからBOTサーバに対してイベントオブジェクトを含むHTTP POSTリクエストが送られる。
- リクエストがLINEプラットフォームから送られたことを確認するために、BOTサーバで検証が行われる。
- 検証にクリアしたらユーザーから送られてきたコンテンツ(テキストメッセージや画像メッセージなど)が取得できるようになる。
- ユーザーリクエストに対して必要な処理を行いメッセージを送信する。
この流れだけをみると実装するのは大変だと思うかもしれませんが、LINE Messaging API SDKを使えば比較的簡単に実装することができます。
実際に廃発が必要なのは「ユーザーから送られてきたメッセージの処理」の部分です。
LINE Messaging API SDKとオウム返しBOTのサンプルコードは公式ドキュメントをご確認ください。
今回はPythonを使っていますがそれ以外にもJAVA、PHP、GO、Node.jsなどいろいろな言語のSDKが用意されています。
LINE Messaging API SDK
https://github.com/line/line-bot-sdk-python
作成したオウム返しBOTはHerokuへデプロイすればLINEから使用することができます。
Herokuへのデプロイ方法は別の長くなるので別の記事にしたいと思います。
画像分類BOTの実装
今回作成する画像分類BOTはオウム返しBOTを応用することで実装することができます。
実際に実装する部分としては、
- ユーザーから送られてきた画像を取得する。
- 画像分類モデルで画像に写っているものラベリングする。
- ラベルをテキストメッセージとしてユーザーへ送信する。
実装したコードは以下です。
# モデルのロード
model = Interpreter(model_path='モデルパス')
model.allocate_tensors()
# モデルのインプット、アウトプットの形状を取得
input_details = model.get_input_details()[0]
output_details = model.get_output_details()[0]
@handler.add(MessageEvent, message=ImageMessage)
def handle_image(event):
# ユーザーから送られてきたコンテンツを取得する
image_url = f'https://api.line.me/v2/bot/message/{event.message.id}/content/'
header = {
"Content-Type": "application/json",
"Authorization": "Bearer " + YOUR_CHANNEL_ACCESS_TOKEN
}
res = requests.get(image_url, headers=header)
# 画像の前処理
image = Image.open(BytesIO(res.content))
input_data = process_image(input_details['shape'], image)
# 画像に写っているもののラベルを予測
model.set_tensor(input_details["index"], input_data)
model.invoke()
label = model.tensor(output_details["index"])().argmax()
# 画像のラベルをテキストメッセージでユーザーに送信する。
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=f'たぶん...{label}'))
オウム返しBOTの下記の箇所を置き換えることで画像分類BOTとして動作させることができます。
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=event.message.text))
サンプル: