背景
ある時、息子クンが父さんである私に尋ねた。
息子クン:「父さん、英単語ってどうやって覚えるの?」
父さん :「そりゃあ、学校の授業でも音読するだろう?で、その次に暗唱っていう訓練をするんじゃないのかな?」
息子クン:「まぁ、やっている人はやっているけれど・・・」
父さん :「教科書をまず訳せるようになって、その次のステップで見ないで言えるようにする。そういう訓練が効果的だよ。」
息子クン:「その・・・。暗唱っていうのが、出来ないんだよ。」
父さん :「え?!何回も唱えれば、全部でなくても少しは覚えられるよね?」
息子クン:「少しはね。でも何回もやっているうちに疲れちゃうんだ、で、やる気もなくなって・・・」
父さん :「(マジか、これアカンやつや、勉強嫌いになってもうた、orz)」
要求分析
「英単語を覚える」という修行はネイティブさんや、帰国子女さんでない限り、誰もが通る険しい道のり。
息子クンは、早くも壁にブチあたってしまったようだ。
「単語を覚える」といっても色々とやり方はあるので、ちょっと整理してみよう。
基本的なアプローチは、英単語を読んで、日本語に訳せるかを訓練する。
その繰り返しの慣れによって、覚えてしまうまでに小慣れてくる状態にすることだ。
単語の覚え方としては、次のようなやり方が代表的だが、息子クンは苦手な方なので「1の英単語」の方向性が良いだろう。
- 英単語として覚える
- 例文の中で覚える
- 文章の中で覚える
脳、というより体に染み込ませる方法としては、以下がある。
- 書いて覚える
- 声に出して覚える
- CDなどの音源で聴いて覚える
色々と調べてみると、効率や実用面から「2の声」が良さそうだ。
しかし、息子クンは暗唱っていうのが、出来ないとも言っている。
となると、「2の声」も実行可能性が低そうだ。
「1の書く」は時間的に厳しいだろう。
残るのは「3の音源」の活用となり、隙間時間の聞き流しによって、少しでも定着を図るのが良いだろう。
しかし、音源はどう整理すればよいのか?
単語帳の付録のCDには英語音声のみのモノが多い。
英語と日本語のセットを繰り返す音源もあるが、息子クン曰く、リズムが気に入らないらしい。
「なになにを探す」といった発声の中で、「なになに」がしつこいなどとクレームまでつけてきた。
なんて、モンスターカスタマーなんだ!

ボキャブラリー強化大作戦
他社製品、もとい市販のモノで対応出来ないの出れば、自分で音源をくっつて編集するか。
いや、世界を股にかけるエンジニアの父さんにだって、そんな時間はないぞ。
そうだ、Google先生に聞いてみよう。
すると、百式英単語という方法が出てきました。
英語と日本語の音源をブツブツ繰り返す、これはイイ。
あ、でも、息子クン、高校生じゃないんだよな。
やはり音源を自分で作るしかないのか。
自ら覚える単語を指定して、音源のスピードなども調整でき、場合によっては英->日、日->英も切り替えられると良いだろう。
そんなこんなで、次ような方式を考えてみた。
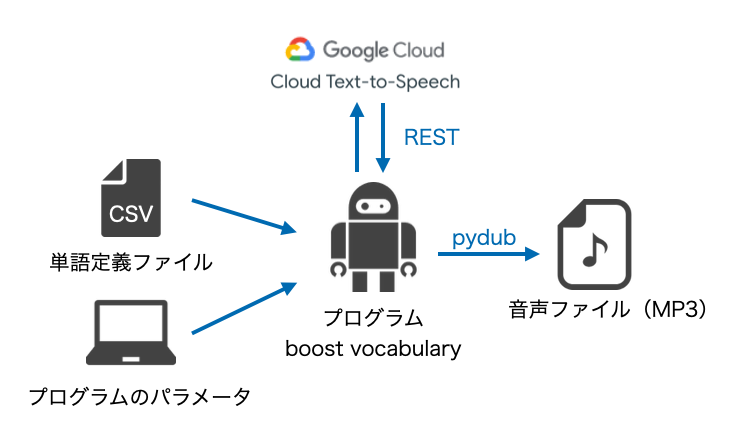
前準備
GoogleのText-to-Speech Client Librariesの記事にあるSetting up authenticationを実施し、サービス アカウント キーが含まれる JSON ファイルを取得してください。
このファイルをプログラムの引数に指定します。
このサービスは100万文字までは無料で使えるようです。
実装
単語定義ファイル
CSVファイルで次のようなフォーマットとした。
|フラグ|Id3tag_artist|Id3tag_album|Id3tag_title|english|japanese|output|loop_count|
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| y | 父さんの英語 |part1|0001|begin|始める|./mp3/kihon78/0001.mp3|2|
- フラグ
音声ファイルを生成するか否かのフラグを指定する。一度作成済みのファイルは「n」にするなど、管理する。 - id3tag
Iphone等のモバイル端末に入れて聴く想定のため、タグがないと整理がつかないので定義できるようにした。ココは運用におけるこだわりポイント。 - loop_count
単語だったら2回、解説を入れる場合は1回など、行ごとに調整が効くようにした。
音声ファイル生成イメージ

パラメータ
単語ごとに設定を変えたい値は単語定義ファイルへ、ファイル単位で良さそうなものはパラメータ(コマンドライン引数)とした。システム定義かアプリケーション定義かインスタンス定義かオン中に変更可能かなど、この辺は設定項目を効かせたい範囲に応じて設計する必要がありますね。想定している運用次第といったところ。
- speaking_rate
英語、日本語のそれぞれで発声のスピードを指定できるようにした。
母国語と外国語では慣れが異なるので、日本語を速くするのがオススメ。 - 間の時間
英語と日本語の間、繰り返しの間を調整できるようにした。
間を多くとれば、瞬間英作文の練習にもなるだろう。
音声ファイルの生成
- どの言語で扱うか、誰が発声するか、といったパラメータは、'en-US','en-US-Wavenet-D'といったプリセットにて指定する。
- AudioEncodingで各種拡張子に変更できる模様。
def create_audio(
output_path,
text,
params_language_code,
params_name,
params_speaking_rate):
client = texttospeech.TextToSpeechClient.from_service_account_json(
option.servicekey_of_file)
s_input = texttospeech.types.SynthesisInput(text=text)
voice_params = texttospeech.types.VoiceSelectionParams(
language_code=params_language_code, name=params_name)
audio_config = texttospeech.types.AudioConfig(
audio_encoding=texttospeech.enums.AudioEncoding.MP3,
speaking_rate=params_speaking_rate)
response = client.synthesize_speech(
s_input, voice_params, audio_config)
with open(output_path, 'wb') as out:
out.write(response.audio_content)
音声ファイルの結合
- pydupのAudioSegmentを使用することで、あたかも文字列を連結するかのごとく、音声ファイルをつなぎ合わせることができる。
def synthesize_audio(
input_en_path,
input_jp_path,
loop_count,
output_path,
option):
loop_max = int(loop_count.strip())
audio_en = AudioSegment.from_mp3(input_en_path)
audio_jp = AudioSegment.from_mp3(input_jp_path)
opening_margin = AudioSegment.silent(duration=100)
between_sentences = AudioSegment.silent(duration=option.between_sentences)
between_the_loop = AudioSegment.silent(duration=option.between_the_loop)
if option.japanese_top:
audio = opening_margin + audio_jp + between_sentences + audio_en
if loop_max > 1:
for li in range(loop_max - 1):
audio += between_the_loop + audio_jp + between_sentences + audio_en
else:
audio = opening_margin + audio_en + between_sentences + audio_jp
if loop_max > 1:
for li in range(loop_max - 1):
audio += between_the_loop + audio_en + between_sentences + audio_jp
audio.export(output_path, format='mp3')
os.remove(input_en_path)
os.remove(input_jp_path)
ソース一式
実装のフルセットはgithubにありますので、もし宜しければ参照してみてください。
Future Work
- Quizlet等の単語アプリからAPIで覚えていない単語リストを取得し、当該プログラムにより
苦手な音声ファイルを生成。そのファイルをLINEまたはDiscord等で対象者に配信する仕組みに発展させる。 - 苦手な単語をとことんパーソナライズして追い込む。
- 忘却曲線によって忘れたかもしれない単語をリストアップし、Google Homeで発声させ、定着化を図る。
- 息子クンに負けないように、父さんもソフトウェアの力で英語力をアップさせるぞ!