なぜ作ろうと思ったか
コロナ禍でチケットが争奪戦になると知り、
「うわ、めんどくせぇ、、、」って思いました(小並感)。
そこで、selenium使ってアクセスとあわよくばブラウザ操作を自動化できないかなって考えて、
表題通りのことをしようと思いました。
ちなみに過去にTinderのスワイプを半自動化(このアプリケーション作るためだけに登録した)
したこともあって、
ある程度ブラウザ操作に関しての知識はありました。
お世話になった教材:Pythonで面倒な「ブラウザ操作」や「データ収集」の作業を自動化しよう|Webスクレイピングの基本的な内容をわかりやすく解説|PythonでWebスクレイピング第01回
なぜpython
日頃からJavaScriptをメインで使っていますが、- コードが簡潔
- seleniumに関する情報が多い
実行環境はwindows10+vscode+chromeです。楽チン。
なおpythonは完全感覚でやっているので、説明が浅くなると思われます。ご留意を。
URLに飛ぼう
※HPの仕様が変わったら機能しなくなるかもしれません。#事前にchromedriver.exeをインストール
#pip install selenium
from logging import log
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
パッケージのインポートです。
Time:sleep()で動作に間隔をつける
options:「ブラウザが読み込んだら、以下処理を実装」みたいな処理のときに使う
options = Options() #optionsの呼び出し
options.page_load_strategy = 'normal' #ページ全体がロードするまで待機
browser = webdriver.Chrome('chromedriverが入っているパス', options=options)
url = 'https://reserve.tokyodisneyresort.jp/ticket/search/'
browser.get(url) #ブラウザオープン
browser.maximize_window() #ウィンドウの最大化
アクセスの処理です。
ページがロードするまでブラウザの処理を待って、その後処理を加えるというものです。
ページ読み込み戦略
カレンダーめくる処理
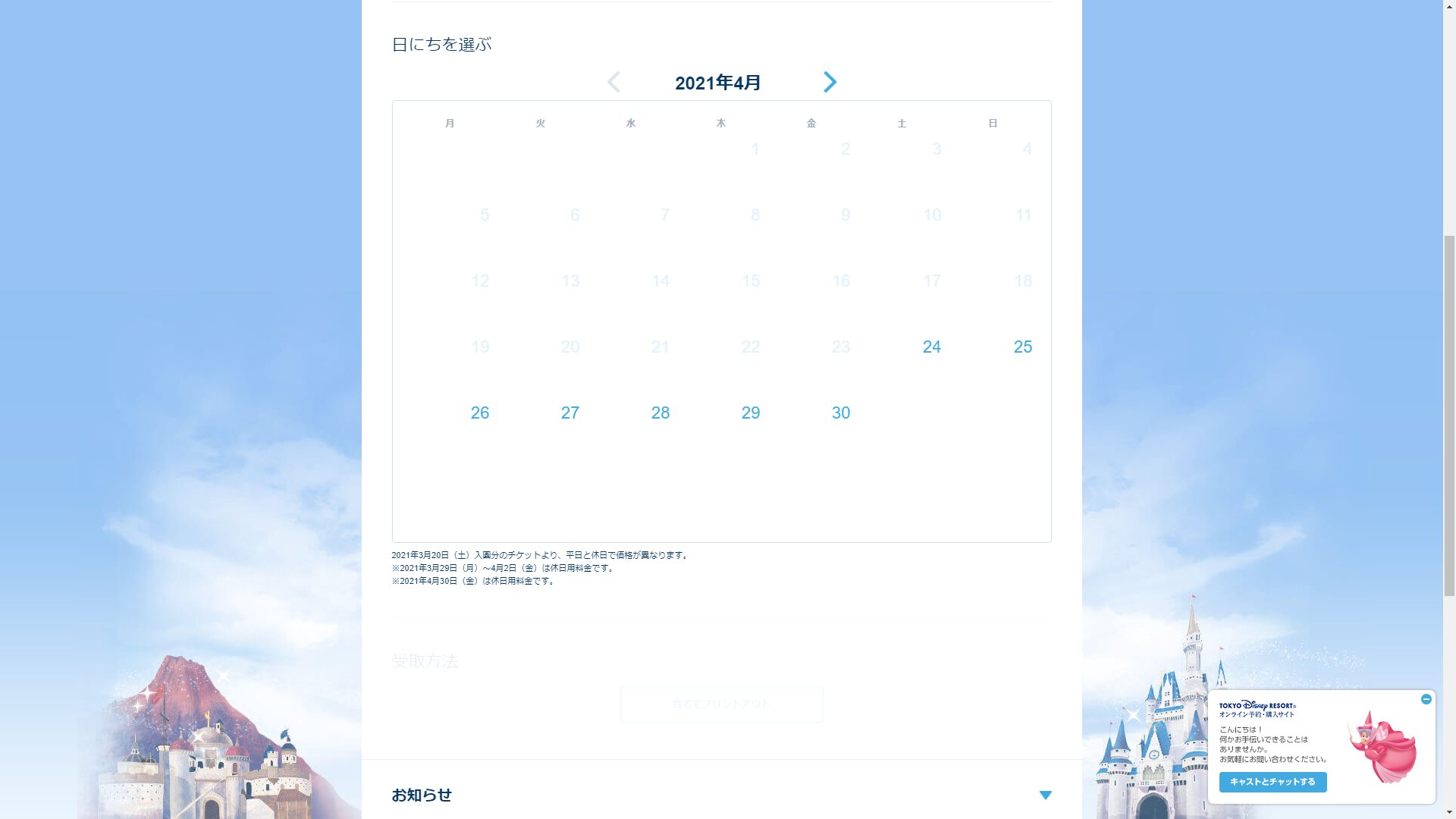
この画面が出てくるので、行きたい月までクリックしてもらいます。
next = browser.find_element_by_class_name('slick-next')
sleep(1)
next.click()
sleep(1)
next.click()
クラスの名前はchromeの開発者ツールで取って来れます。
日付選択と受け取り方法選択
 # 日付選択
sleep(1)
elems = browser.find_elements_by_tag_name("a")
for elem in elems:
attr = elem.get_attribute("data-daynumbercount")
if attr == "開発者ツールで行きたい日のdata-daynumber-countの値を入れる":
print('ok1')
elem.click()
# 受け取り方法
sleep(1)
print_btn = browser.find_element_by_id("searchEticket")
print_btn.click()
以下記事をガン見しました。控えめに言って神(感謝です)。
例の神記事:Seleniumを使用してhtmlのカスタムデータ属性を要素として取得したい
ここから先の処理
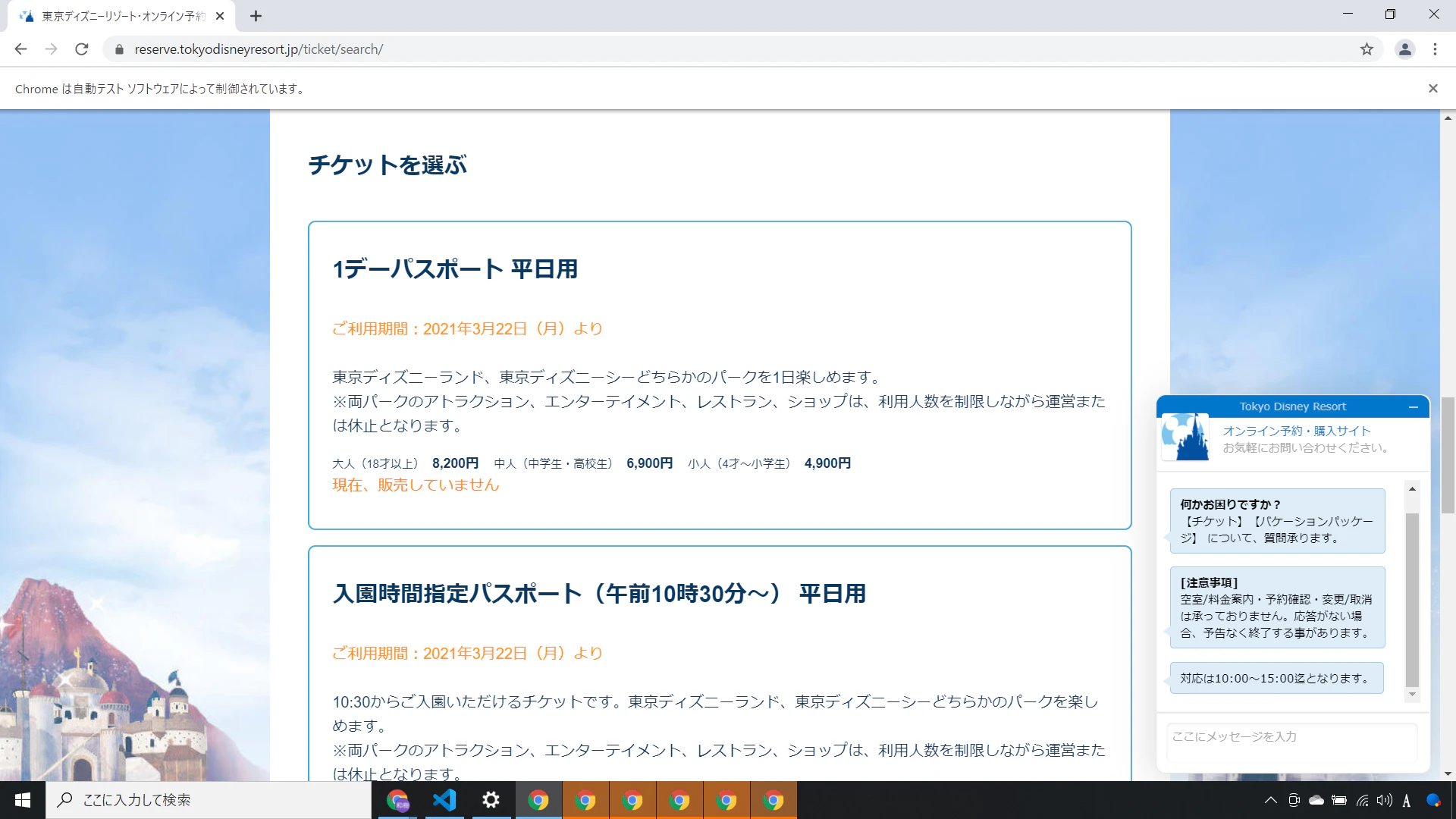
カードを選ぶ処理ですが、選択しても遷移されない状態になっているため、ここからは出たところ勝負になってしまう。
あくまでもチケットを取るために多くのアクセスをしたいだけなので処理の記述は終わり(怖いからスマホでもアクセスするけどね)。
そして、while文を付けてカウントさせれば、、、
一定間隔で複数アクセスができるはず。たぶん。
必要かもしれない処理
-
ディズニーのチケットサイトに接続できたら音を鳴らす
音を鳴らす処理よりも、個人的には例外処理でエラーページが出たらリロードするのは必要かも -
ディズニーチケット予約攻略法 – 実際に予約できたポイントを詳しく解説
ユーザージャーニーとして参考にしました。
実行テストができないためコメントアウトしているが、パークや枚数の選択はできるはず(「一覧から探す」からクラスが取れた)
あとは自動スクロールとかクレカ入力とかもできればいいが、チケット販売開始しないとクラスも取れないし、そもそもそんな余裕ないのでひとまずこれまで。
(2021/04/29 追記)
ログイン処理を書くのを忘れていたので記述。
また、ログイン→購入の流れにしたいので、urlを変更した
url = 'https://reserve.tokyodisneyresort.jp/top/' # ディズニートップページ
browser.get(url)
browser.maximize_window()
#ログイン処理
login_btn = browser.find_element_by_class_name('nav02')
sleep(1)
login_btn.click()
userId = browser.find_element_by_id('_userId')
userId.send_keys("メールアドレス")
sleep(1)
password = browser.find_element_by_id('_password')
password.send_keys("パスワード")
sleep(1)
login_form = browser.find_element_by_class_name("loginform")
login_form.click()
sleep(5)
browser.get('https://reserve.tokyodisneyresort.jp/ticket/search/') #チケットページ
まとめ
自動操作っていいなと感じる開発でした(語彙力) 乱数使ったりしてbot対策したり、 もっと間隔空けたほうが弾かれずにすみますね!!何かあればご教授ください🙇♂️