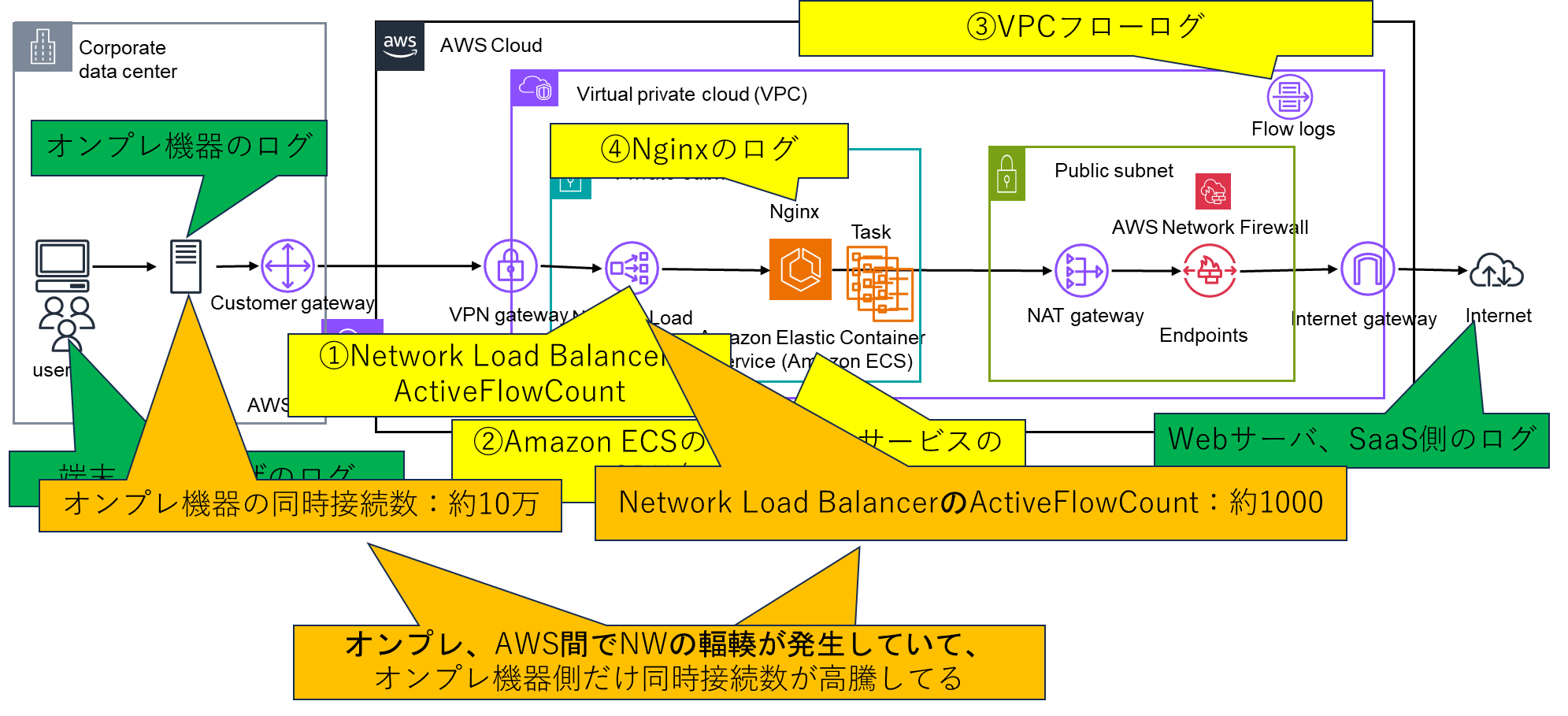
下記の構成でオンプレの機器からインターネット接続するためのAWS内のプロキシサーバにて、問題が発生した際に実施した確認した各種ログと問題があった場合の解決策を整理してまとめました。

①Network Load BalancerのActiveFlowCount(CloudWathchメトリクス)
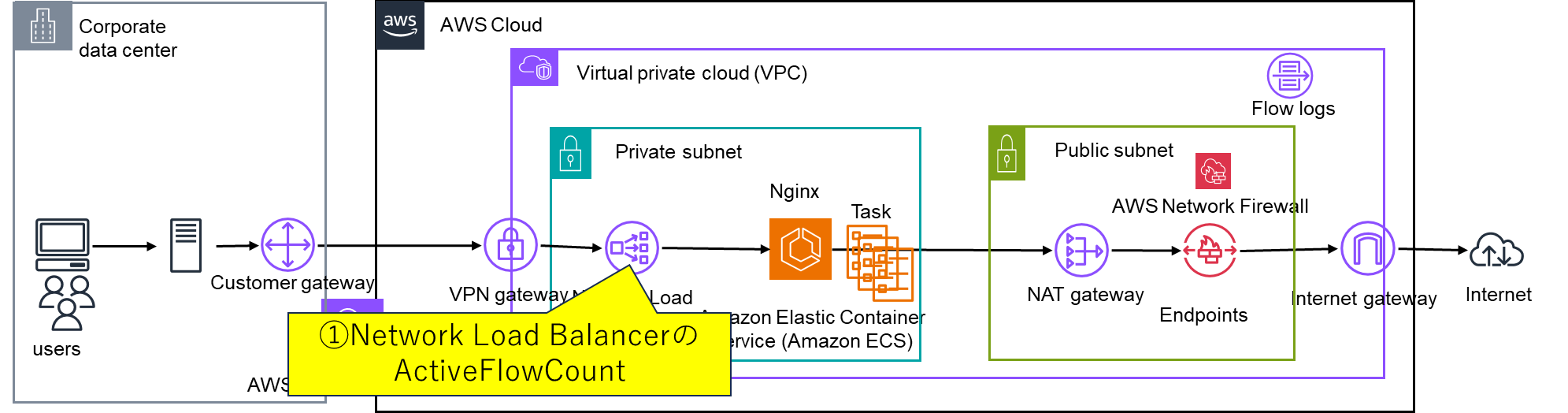
CloudWatchメトリクスで、対象のNetwork Load BalancerのActiveFlowCountの項目を確認します。
確認観点:ActiveFlowCountの値がシステムの許容範囲かを確認するActiveFlowCountの上昇がある一定値で止まってる場合、
何かしらの制約で処理できる同時接続数が上限に達してる場合があります。
異常があった場合の対策:問題がある場合は、システムのサイジング見直しを検討してみる。各種AWSリソースの数やAmazon ECSのTask数を増やしてみて、事象が解決するかを確認してみる。
②Amazon ECSのクラスターサービスのCPU/メモリ使用率(CloudWathchメトリクス)
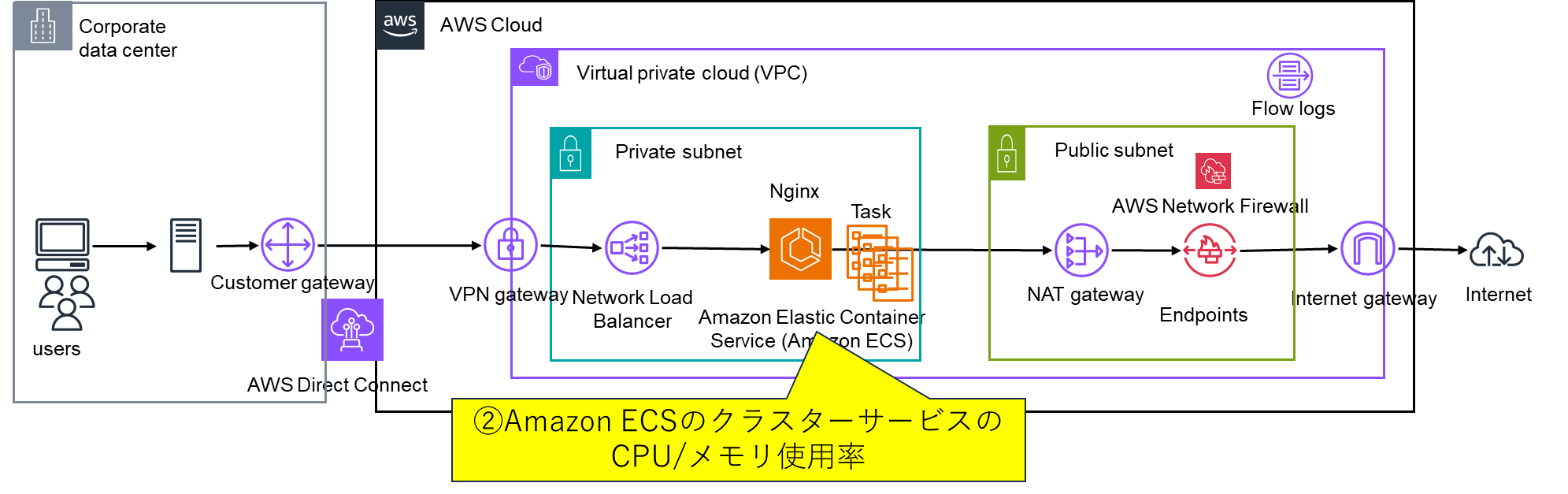
CloudWatchメトリクスで、対象のAmazon ECSのクラスターサービスのCpuUtilized、MemoryUtilizedの値から確認できます。
確認観点:puUtilized、MemoryUtilizedの値が100%近くになっていないかを確認する。
ECSタスクに割り当ててるCPU/メモリが足りずに、正常に処理しきれない可能性があります。
異常があった場合の対策:ECSタスクのスケールアップ/スケールアウトを検討する。スケールアップ/スケールアウトをして事象が解決するかを確認してみる
③VPCフローログ

VPCフローログを確認することで、VPC内通信のTCPレイヤでの異常有無を判断することができます。
確認観点:通信異常(REJECTの出力)が発生していないこと、ポート枯渇が発生していないことを確認
ポート枯渇の見分け方ですが、srcaddr,dstaddrでソートしたときに、srcaddr,dstaddrの値で判断します。
特定のポートしか利用されてない場合や、ポート番号1-65535を使い切ってるかを確認することで判断できます。
下記はsrcportが32768-60998で枯渇したときの出力イメージです。32768-60998以外のポート番号がログに出力されてませんでした。
| interface-id | srcaddr | dstaddr | srcport | dstport |
|---|---|---|---|---|
| eni-XXX | Amazon ECSTaskのIPアドレス | NAT gatewayのIPアドレス | 32768 | 443 |
| eni-XXX | Amazon ECSTaskのIPアドレス | NAT gatewayのIPアドレス | 32768 | 443 |
| ~ | ~ | ~ | ~ | ~ |
| eni-XXX | Amazon ECSTaskのIPアドレス | NAT gatewayのIPアドレス | 60998 | 443 |
異常があった場合の対策:通信異常(REJECTの出力)が発生している場合、該当の通信に関するセキュリティグループ、ネットワークACL、ルートテーブルの設定を見直してみるて、事象が解消するかを確認してみる。
ポート枯渇が発生した場合、ECSのTask数やNAT gatewayを増やして、送信元、先で使用するIPアドレスの数を増やして、事象が解消するかを確認してみる。
※ポート枯渇については以前こちらのブログでも解説してます。
https://qiita.com/tkazuaki0820/items/2afa7ad253d4d65b4af1
④Nginxのログ
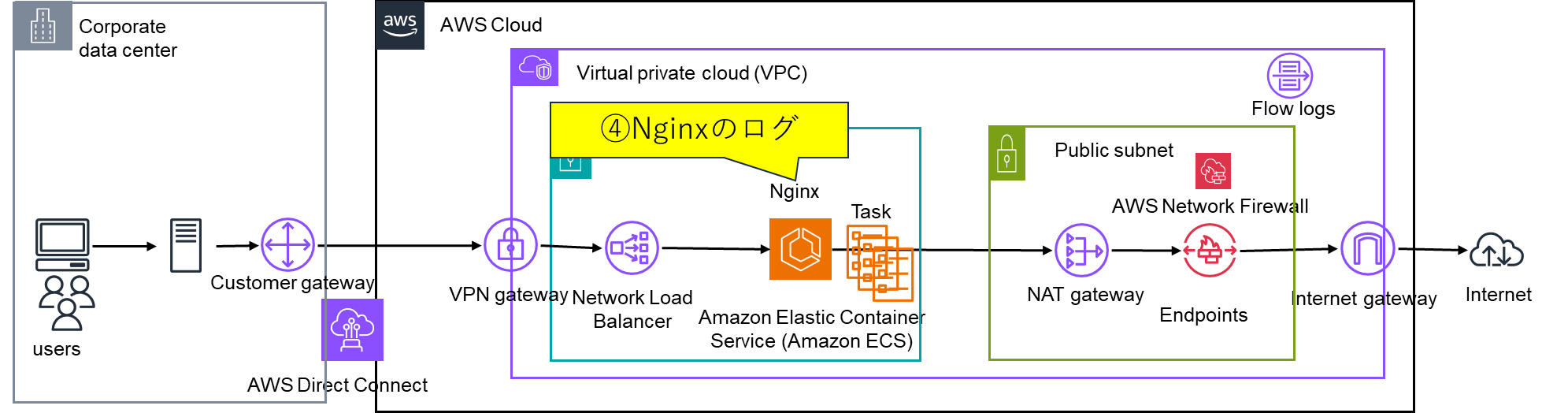
Nginxのログは予めログのフォーマットを設定する必要があります。
nginx.confのlog_formatに下記のように設定しています
http {
log_format main '$remote_addr - $remote_user [$time_local]"$request" '
'$status $request_completion $body_bytes_sent $https $request_time "$http_referer" '
'"$http_user_agent"';
#ログ
access_log /dev/stdout main;
#エラーログ
error_log /dev/stderr notice;
}
| パラメータ名 | 出力される内容 | 設定した理由 |
|---|---|---|
| $remote_addr | クライアントのIPアドレス | アクセス元を判断するため |
| $remote_user | クライアントのユーザ名 | アクセス元を判断するため |
| $time_local | アクセス日時 | アクセス時間を判断するため |
| $request | httpの要求URI | 要求URIを確認できるようにするため |
| $status | httpのステータス | ステータスの成功、失敗を確認するため |
| $body_bytes_sent | 送信バイト数 | 送信バイト数を確認できるようにするため |
| $http_referer | リファラーURL(遷移元URL) | 遷移元のURLを確認できるようにするため |
| $http_user_agent | ユーザエージェント情報(ブラウザ名・バージョン等) | ユーザの情報を確認できるようにするため |
| $request_time | ミリ秒単位のリクエストの処理時間 | リクエストの処理時間を確認できるようにするため |
| $https | 接続操作がSSL時にon | 接続がSSL通信であるかを確認できるようにするため |
| $request_completion | リクエストが完了した場合OK | リクエストが完了したかを確認できるようにするため |
確認観点:特に注視してる項目を解説します。
httpステータス($status)に200 OK以外でエラーが出てないかを確認し、通信不可のドメインの有無を確認する。
処理時間(request_time)を確認し、処理に時間がかかっていて遅延が発生していないことを確認、
異常があった場合の対策
Network Firewallのルールグループの通信許可してるドメイン一覧を確認する。通信許可ドメイン一覧を更新して事象が解消するかを確認してみる。
処理に時間がかかっていて遅延が発生してる場合、ECS側で割り当ててるリソースが足りない可能性もあります。ECSタスクのスケールアップ/スケールアウトを検討する。
また、処理が終わる前にNginxのタイムアウトになってる可能性もあります。Nginxのタイムアウト値の変更を検討する。
Nginxのタイムアウト値変更はnginx.confの下記のパラメータを変更することで設定できます。
http {
proxy_connect_timeout XXs; #セッションタイムアウト値
proxy_read_timeout XXs; #応答の読み込みのタイムアウト値
proxy_send_timeout XXs; #リクエストの転送のタイムアウト値
}
実際の解析
Network Load Balancer、ECS,Nginxのシステムの構成でのトラブルシューティングで普段確認してるログを一通り解説しました。纏めると下記になります。

実際には一つのログだけ見て原因を特定できないことも多く、AWS内だけでなくユーザが使用してる端末/ブラウザのログ、オンプレDCのログ、接続先のWebサーバ/Saaサービス等、
登場してくる機器/サービスのログを並行で確認して事実整理をしていくことが重要だと思います。
特定の処理を抽出してシステム構成図とマッピングして、各機器で確認できたことを整理すると真の原因が見えて来ることもああります。
※注意点として、ログの時刻がJSTとUTCで混在してますUTCは+9時間してJSTに変換して、時刻を統一してから整理をしましょう。

実際の例で解説します。ユーザ目線では端末,ブラウザにてWebサーバからの応答が遅いという同じ事象に見えても、
各機器のログを確認していたところ、下記のように全く原因が違うということがありました。
①HTTPリクエストが処理された時刻を確認したところ端末からHTTPリクエストは数msでレスポンスが帰ってきていた。
→NW経路には問題なく、ユーザが利用してる端末のスペック(CPU/メモリ)が不足しており、Web画面の描写に時間がかかっていた。
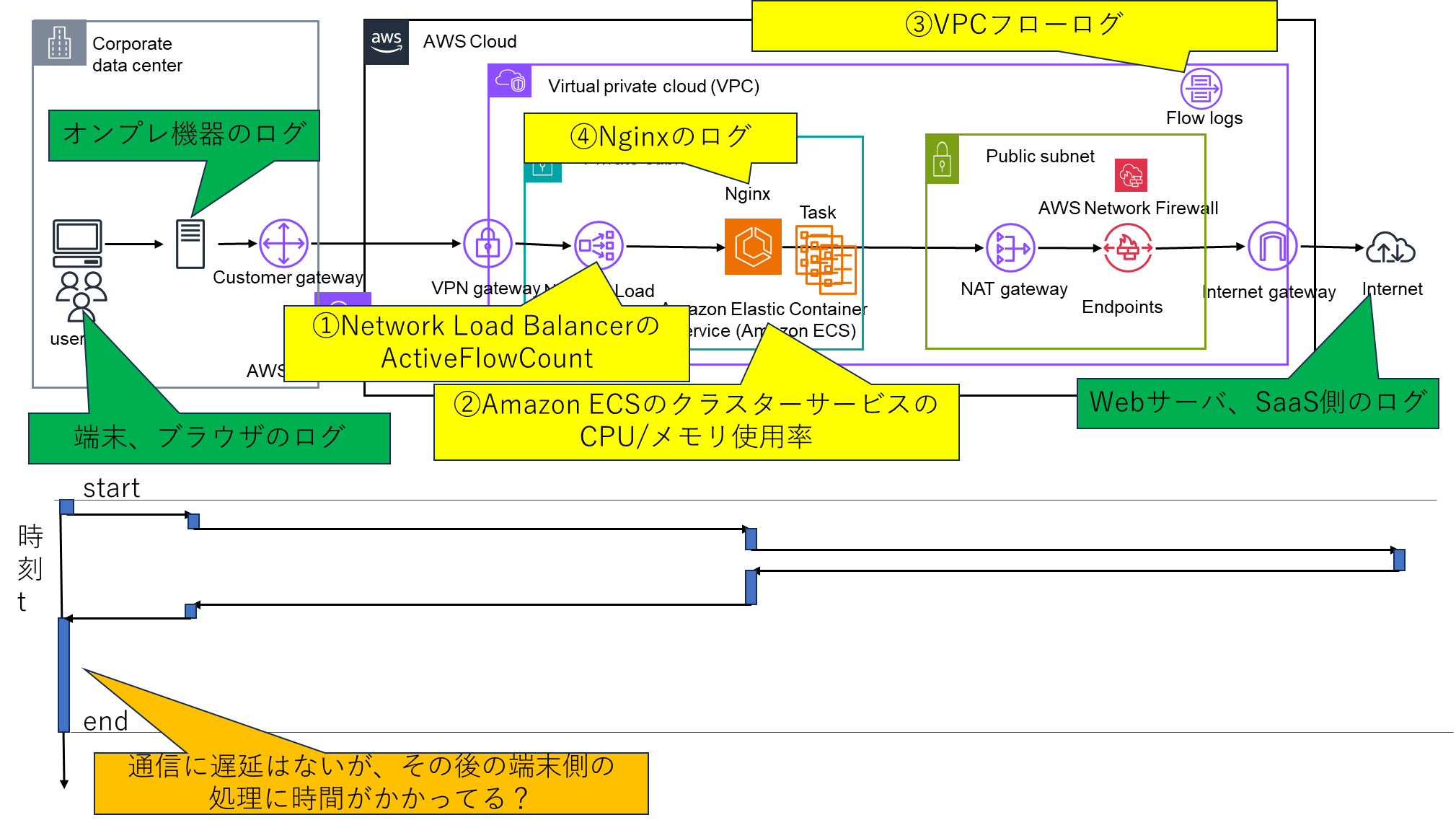
②各機器の同時接続数(ActiveFlowCount)の値を確認したところ、AWSのNetwork Load Balancer側の値と比較して、オンプレDC側の値が100倍近い値になってる。
→詳細を確認したところ、オンプレDC側の設定の問題でNW輻輳が発生していることが起因で通信が遅延していた。
最後に
最後にですが、現状のNetwork Load Balancerを利用する構成だと
HTTPレイヤでのログ確認がNginxのログ頼みにになっています。
Network Load Balancerではなく、Application Load Balancerを利用するともう少しログ解析が楽になるかなとは思ってます。
※補足するとクライアント側からの送信先IPを固定化したいという要件を実現するために、Network Load Balancerを採用してます。