はじめに
LangGraphを学ぶ機会があったので復習がてらまとめた記事です。
なお、Langchainについてはここでは解説していません(なのでLangchainについて既に知っている人向けの記事です)
また、Langchain及びLangGraphの更新は結構頻繁なので細かい仕様は公式で確認推奨です。
公式はドキュメントも充実しているので読みやすいです(ありがたい!!!)
サンプルコードはPython3で実装しています。
LangGraphのバージョンは、v0.4.3を使用
参考記事
LangGraphとは
LangChainアーキテクチャの一部として開発された、状態を保持するLLMアプリケーションを構築するためのフレームワークです。
複雑な制御フローとステートマシンの概念を取り入れることで、高度な対話型AIシステムやマルチエージェントシステムの実装を可能にします。

LangGraphの基本構造
LangGraphは有向グラフのモデルを採用しており、以下の主要な要素から構成されています
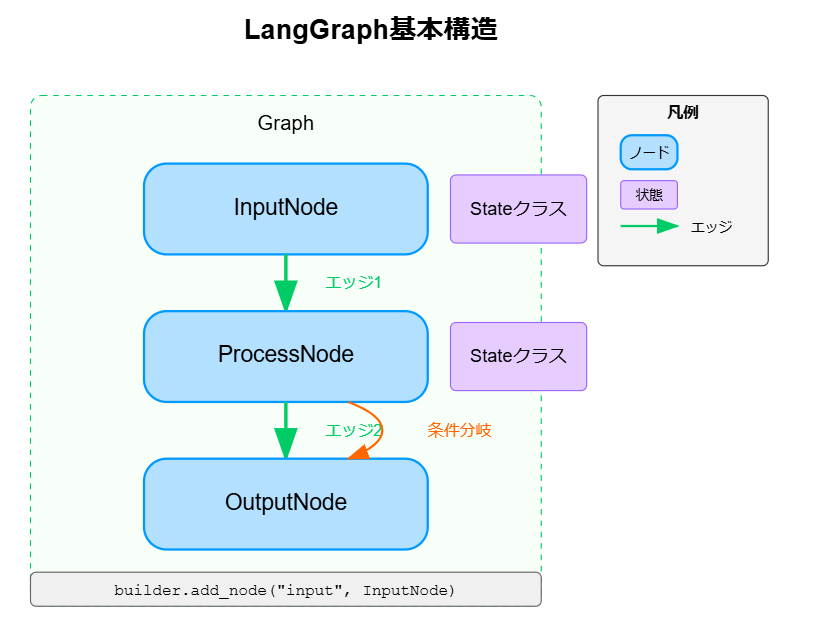
グラフ(Graph)
- ノードとエッジで構成される全体構造
- ワークフローやプロセスフローを表現
状態(State)
- ノード間でデータを共有する手段として機能
- 各ノードが参照及び更新する
- 通常は辞書型で実装され、TypedDictやBaseModelで型定義される
ノード(Node)
- 処理単位を表す要素
- 入力を受け取り、処理を実行し、出力を生成
- LangChainのチェーン、LLM、ツール、カスタム関数などを含む
エッジ(Edge)
- ノード間の接続と情報の流れを定義
- 条件付きエッジにより分岐ロジックを実装可能
LangChainとLangGraphの関係
LangChainとLangGraphは相互に補完し合う関係にあります
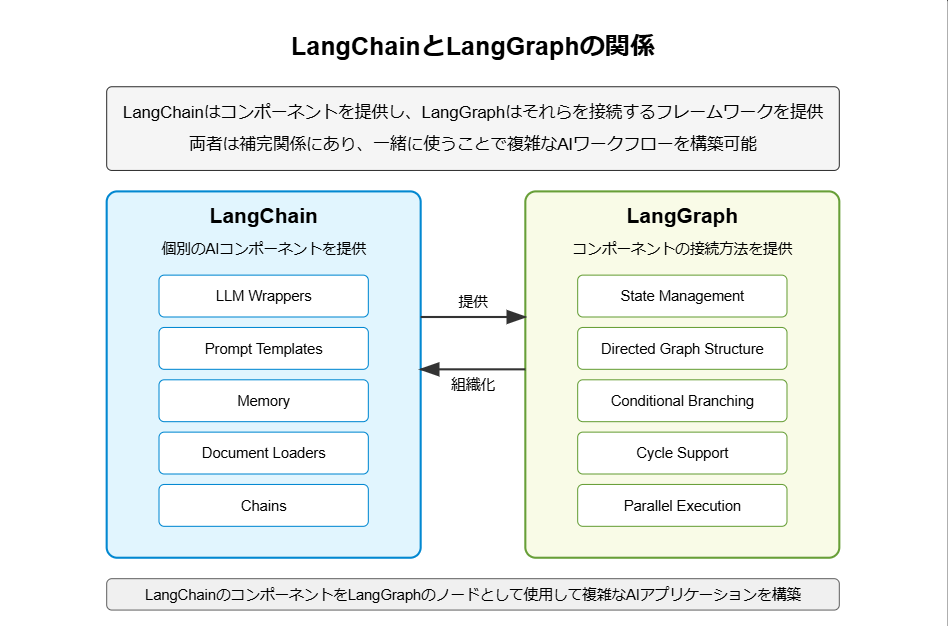
また、フローで比較するとLangchainが単純なフロー(チェーン構造)に対して、LangGraphは複雑なフローも表現できる。

LangGraphの詳細
状態の定義
「typingモジュールのTypeDict」または「PydanticのBaseModel」が使用できます。
from pydantic import BaseModel
# 状態の型定義
class ChatState(BaseModel):
messages: list # 会話履歴
current_question: str # 現在の質問
research_results: dict # 調査結果
final_answer: str # 最終回答
ノードの例
# 1. 関数ノード - 最も基本的なノード
def simple_node(state):
# 状態を処理して新しい状態を返す
new_value = state.value + 100
return {"value": new_value}
# 2. LLMノード - LangChainのLLMを利用するノード
def llm_node(state):
llm = ChatOpenAI(temperature=0)
prompt = ChatPromptTemplate.from_template("質問: {question}")
chain = prompt | llm
response = chain.invoke({"question": state["question"]})
return {"final_answer": response.content}
# 3. ツールノード - 外部ツールやAPIを利用するノード
def tool_node(state):
search_tool = GoogleSearchAPIWrapper()
search_results = search_tool.run(state["query"])
return {"search_results": search_results}
ノードの追加と接続(エッジ)
# グラフにノードを追加
graph = StateGraph(State)
graph.add_node("analyzer", analyze_question)
graph.add_node("researcher", research)
graph.add_node("answerer", generate_answer)
# 簡単な接続(シーケンシャル)
graph.add_edge("analyzer", "researcher")
graph.add_edge("researcher", "answerer")
# より複雑な条件付き接続
def route_based_on_analysis(state):
if state["complexity_score"] > 0.7:
return "deep_research"
else:
return "quick_research"
graph.add_conditional_edges(
"analyzer",
route_based_on_analysis,
{
"deep_research": "deep_researcher",
"quick_research": "quick_researcher"
}
)
LangGraphのメリット
自分としては以下かなと。
- 複雑なワークフローの実現: 条件分岐、ループ、並列処理などを自然に表現
- 状態管理の明示化: アプリケーションの状態を明示的に追跡・管理
- デバッグの容易さ: グラフ構造により処理の流れが視覚的に理解しやすい
- スケーラビリティ: ノードやエッジの追加・変更が簡単なので、小規模なコンポーネントから複雑なシステムへの拡張が容易
※シンプルな1方向だけのフローをLangGraphで実現するとLangChainだけで実現した方がコード量は少なかったりするので注意
LangGraphのユースケース
- 高度な対話システム: 複数のターンにわたる対話の文脈を管理
- 自動化されたワークフロー: 複数のステップと条件分岐を含むタスク
- マルチエージェントシステム: 異なる役割を持つエージェント間の協調動作
- 自己修正システム: 出力を評価し改善するフィードバックループ
- 複合的なAIサービス: 複数のAI機能を組み合わせたアプリケーション
まとめ
LangGraphは、LLMアプリケーション開発における「次のステップ」と言えるフレームワークです。
単純なシーケンシャルなチェーンから、複雑な状態管理と制御フローを持つアプリケーションへの移行を可能にします。
特に、以下のような場合にLangGraphの採用を検討すべきです:
- 複雑な条件分岐を含むLLMアプリケーション
- 状態を保持する必要がある対話システム
- 複数のLLMやツールを連携させる必要があるシステム
- 反復的な改善ループを実装するアプリケーション
LangGraphを活用することで、より洗練された、状態を意識したLLMアプリケーションの構築が可能になります。
実装例:シンプルなエージェントの構築
本例ではTavilyというAIエージェント専用に構築された検索エンジンを利用。毎月1000APIコールまでは無料
Tavilyの使い方についてはこちらの方の記事が参考になりました。
import boto3
import json
import traceback
from typing import Annotated, Any, Literal
from dotenv import load_dotenv
from langchain_aws import ChatBedrock
from langchain_core.messages import HumanMessage, ToolMessage
from langgraph.graph import END, START, StateGraph
from langgraph.graph.message import add_messages
from langchain_community.tools.tavily_search import TavilySearchResults
from pydantic import BaseModel
from IPython.display import Image, display
# 環境変数の読み込み(boto3/Tavily用)
# .envファイル等でAWS_PROFILEとTAVILY_API_KEYを設定しておく
load_dotenv()
# ツールのセットアップ
tool = TavilySearchResults(max_results=1)
tools = [tool]
bedrock_client = boto3.client(service_name="bedrock-runtime", region_name="us-east-1")
def create_bedrock_llm(
temperature: float = 0,
max_tokens: int = 1000,
model_id: str = "anthropic.claude-3-5-sonnet-20240620-v1:0"
) -> ChatBedrock:
"""プロバイダーはBedrockを利用
"""
model_params = {
"temperature": temperature,
"max_tokens": max_tokens
}
return ChatBedrock(
client=bedrock_client,
model_id=model_id,
model_kwargs=model_params
)
# モデルに検索エンジンツールをバインド
model = create_bedrock_llm()
model_with_tools = model.bind_tools(tools)
class State(BaseModel):
# 既存のlistを上書きではなく、追加していく
messages: Annotated[list, add_messages]
def call_model(state: State) -> dict[str, list[Any]]:
print("========== モデルの実行 ==========")
messages = state.messages
response = model_with_tools.invoke(messages)
print("response:\n", response)
return {"messages": [response]}
# Note:自前で実装せずともlanggraph.prebuilt.ToolNode利用するだけでも今は実現できるが練習がてら
def call_tool(state: State) -> dict[str, list[Any]]:
"""ツールの実行
"""
print("========== ツールの実行 ==========")
messages = state.messages
# 継続条件に基づき、最後のメッセージが関数呼び出しを含まれています
last_message = messages[-1]
outputs = []
for tool_call in last_message.tool_calls:
print("tool_call: ", tool_call)
for tl in tools:
if tl.name == tool_call["name"]:
tool_result = tl.invoke(tool_call["args"])
tool_result_str = json.dumps(tool_result)
print("tool_result_str:\n", tool_result_str)
outputs.append(ToolMessage(
content=tool_result_str,
name=tool_call["name"],
tool_call_id=tool_call["id"],
))
return {"messages": outputs}
# Note:自前で実装せずともlanggraph.prebuilt.tools_condition利用するだけでも今は実現できるが練習がてら
def should_continue(state: State) -> Literal["end", "continue"]:
"""
継続条件の判定
エージェントがアクションを取るよう指示した場合、処理続行
"""
print("========== 継続条件の判定 ==========")
messages = state.messages
ai_message = messages[-1]
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "continue"
return "end"
# StateGraphオブジェクトの作成
graph_builder = StateGraph(State)
# ノード関数の登録
graph_builder.add_node("agent", call_model)
graph_builder.add_node("action", call_tool)
# エッジを定義:グラフを実行した際に、どの順番でノードを処理するか(START~END)
graph_builder.add_edge(START, "agent")
graph_builder.add_edge("action", "agent")
# 条件付きエッジの追加
graph_builder.add_conditional_edges(
# 最初に、開始ノードを定義します。
"agent",
# 次に呼び出されるノードを決定する関数
should_continue,
# should_continueの出力とどのノードに行くかのマッピング
{
"continue": "action",
"end": END
}
)
graph = graph_builder.compile()
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
inputs = {"messages": [HumanMessage(content=user_input)]}
ai_response = graph.invoke(inputs)
print("AI: ", ai_response["messages"][-1].content)
except Exception as e:
print(e)
traceback.print_exc()
break
上記のフローをコードから可視化したのが以下

# get_graphメソッドからフローの可視化も可能
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
print("エラー")
ちなみに実行結果例は以下の通りです。
質問:現在の日本の総理大臣は誰?
========== モデルの実行 ==========
response:
content='この質問に正確に答えるために、最新の情報を検索する必要があります。日本の政治情勢は変化する可能性があるため、現在の情報を確認しましょう。~~~省略~~~
========== 継続条件の判定 ==========
========== ツールの実行 ==========
~~~省略~~~
========== モデルの実行 ==========
response:
content='検索結果に基づいて、現在の日本の総理大臣についてお答えします。~~~省略~~~
========== 継続条件の判定 ==========
AI: 検索結果に基づいて、現在の日本の総理大臣についてお答えします。
現在の日本の総理大臣(内閣総理大臣)は石破茂(いしば しげる)氏です。石破氏は第103代内閣総理大臣として、2024年(令和6年)11月11日に就任しました。
ただし、この情報には注意が必要です:
1. Wikipediaの情報は常に最新とは限らず、誰でも編集できるため、時に不正確な情報が含まれる可能性があります。
2. 政治的な変化は急速に起こる可能性があるため、この情報が検索時点で最新であっても、現在は異なる可能性があります。
3. 検索結果の日付が明確でないため、この情報がいつの時点のものかは不明確です。
したがって、最新かつ正確な情報を得るためには、日本政府の公式ウェブサイトや信頼できる最新のニュースソースを確認することをお勧めします。現在の正確な情報を知りたい場合は、それらのソースで直接確認することが最善です。