はじめに
Google Cloud Dataflowを利用する機会があったので、利用した機能をまとめました。
なおパイプライン開発や、Apache Beam のプログラミングモデルを全く知らない状態でDataflowを始めたため、最初はとても苦戦しました。そのためこれからチャレンジする人の参考になればと思います。
Dataflowとは
GCP上でバッチやストリーミングのデータ処理パイプラインが行えるマネージドサービスです。
ざっくり言うとApache BeamをGCP上で動かせるマネージドサービスになります。
利用可能な言語はJavaとPythonになり、本記事はJavaでコーディングしています。Apache BeamのSDKにはGoもあるのでDataflow側が対応すればGoも利用できるかもしれませんね。
主要なドキュメントとしてはこの辺が参考になります。
Dataflowに向いていること
- 大量データを並列処理したいとき
Dataflowに向いていないこと
- 単純なバッチ処理
- BigQueryにデータをINSERTし、その後でINSERTしたデータを処理するような処理
最初にやったこと
Dataflowのドキュメントを読んだだけでは全くイメージがつかなかったためクイックスタートを行いました。
まだ理解に自信が無かったので、こちらの記事を参考にサンプルプログラムも動かしました。
クイックスタートとサンプルプログラムを動かすことで大分イメージが付くため、初めて触る方は是非動かしてください!
参考になったGithubリポジトリ
ワードを数えるサンプルコード
https://github.com/apache/beam/tree/master/examples/java/src/main/java/org/apache/beam/examples
BigQueryを参照してDataflowを実装しているサンプルコード
https://github.com/GoogleCloudPlatform/bigquery-etl-dataflow-sample
コードを書いてみる
商品情報と商品の売り上げを出力するプログラムを実装してみました。
- PipelineOptions
- PCollection
- ファイル出力
- 変換処理
実装したコードはこちらを参照下さい。
PipelineOptions
まず初めにパイプラインのオプションを外部からパラメータとして受け取る処理について記載します。
これはパラメーターで指定したGCPのプロジェクトIDや利用するワーカーの数などをパイプラインに設定する必要があるためです。
PipelineOptionsFactoryクラスのfromArgs()メソッドを利用してパラメータを取得し、PipelineOptionsオブジェクトにセットします。
PipelineOptions options = PipelineOptionsFactory
.fromArgs(args)
.withValidation()
.create();
デフォルトで用意されているパラメータの詳細は、こちらをご覧ください。
独自でパラメータを実装する場合は、PipelineOptionsクラスを継承することで実現可能です。
下記では、HogeHogeOptionパラメータが指定可能になります。
PipelineOptions options = PipelineOptionsFactory
.fromArgs(args)
.withValidation()
.as(CustomOptions.class);
public interface CustomOptions extends PipelineOptions {
@Description("Custom command line argument.")
@Default.String("DEFAULT")
String getHogeHogeOption();
void setHogeHogeOption(String hogehogeOption);
}
PCollection
PCollectionオブジェクトはパイプラインの各ステップの入力と出力として使用するデータセットになります。
利用するダミーデータはIdと商品名のListになります。
public static List<String> getInitialDataGoods() {
List<String> goods = new ArrayList<>();
goods.add("1,Tシャツ"); //Id,Name
goods.add("2,ポロシャツ");
goods.add("3,パーカー");
goods.add("4,ジャージ");
goods.add("5,ブルゾン");
goods.add("6,ダウンジャケット");
goods.add("7,ピーコート");
goods.add("8,スタジャン");
goods.add("9,デニムパンツ");
return goods;
}
ではPCollectionオブジェクトに読み込んでみます。
Apache Beam Programingガイドに記載のPCollectionの特徴としては、
- 複数のパイプラインで共有することはできない。
- JavaのCollectionクラスに似ている。
になります。
pipeline.apply("Goods", Create.of(goods))でgoodsオブジェクトを読み込み、PCollectionオブジェクトのデータセットとして出力します。
public static void main(String[] args) {
List<String> goods = getInitialDataGoods();
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline pipeline = Pipeline.create(options);
PCollection<String> goodsCollection = pipeline.apply("Goods", Create.of(goods)); <----ここです
goodsCollection.apply(TextIO.write().to("./src/main/resources/goodsSales.txt"));
pipeline.run().waitUntilFinish();
}
ファイル出力
PCollectionオブジェクトで保持したデータセットをファイルに出力します。
goodsCollection.apply(TextIO.write().to("./src/main/resources/goodsSales.txt"));
このままだとファイル出力処理が分散して動くため複数ファイルに分かれて出力されます。
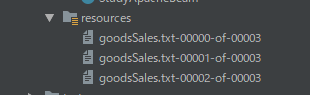
そのためwithoutSharding()メソッドでファイルが分かれないように制御します。
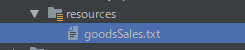
goodsCollection.apply(TextIO.write().to("./src/main/resources/goodsSales.txt").withoutSharding());
これで1ファイルに出力されます。
ファイルの出力内容はこちらです。
2,ポロシャツ
1,Tシャツ
7,ピーコート
9,デニムパンツ
4,ジャージ
8,スタジャン
5,ブルゾン
6,ダウンジャケット
3,パーカー
変換処理
読み込んだデータは出力するだけでなく変換したくなりますよね。
変換処理について理解している範囲でご紹介します。
パイプライン上のPCollectionオブジェクトの変換には、下記の変換がサポートされています。
- ParDo
- GroupByKey
- CoGroupByKey
- Combine
- Flatten
- Partition
ここでは、ParDo・GroupByKey・CoGroupByKeyについて説明します。
ParDo
データの変換で一番よく使うとParDo変換を実装してみます。
実装する場合は、DoFnオブジェクト形式の実装を自前で行う必要がありますが、慣れるととても簡単です。
ここでは、カンマ区切りのIdとNameからNameだけを取り出してみます。
public static void main(String[] args) {
List<String> goods = getInitialDataGoods();
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline pipeline = Pipeline.create(options);
PCollection<String> goodsCollection = pipeline.apply(
"Goods",
Create.of(goods)
);
PCollection<String> goodsNameCollection = goodsCollection.apply(
"Goods Name extraction",
ParDo.of(
new DoFn<String,String>(){ //左がInput、右がOutputの型
@ProcessElement
public void processElement(ProcessContext c) {
List<String> line = Arrays.asList(c.element().split(","));
c.output(line.get(1));
}
}
)
);
goodsNameCollection.apply(TextIO.write().to("./src/main/resources/goodsName.txt").withoutSharding());
pipeline.run().waitUntilFinish();
}
DoFnの匿名クラスにprocessElement()メソッドを実装し、ProcessContext cでInputデータを1つずつ受け取り処理します。処理が終わったらc.output()メソッドでOutputします。
出力結果はこちらです。
スタジャン
ブルゾン
ダウンジャケット
ジャージ
パーカー
ポロシャツ
ピーコート
Tシャツ
デニムパンツ
GroupByKey
key/value形式のデータをグルーピングするために利用するGroupByKeyを実装してみます。
グルーピングする内容はシンプルに価格と商品です。
ダミーデータは下記の価格と商品名のListになります。
public static List<KV<String,String>> getInitialDataPriceGoodsKV(){
List<KV<String,String>> price = new ArrayList<>();
price.add(KV.of("1000","Tシャツ"));
price.add(KV.of("1000","タオル"));
price.add(KV.of("1000","靴下"));
price.add(KV.of("2000","デニムパンツ"));
price.add(KV.of("2000","ビジネスシャツ"));
price.add(KV.of("3000","ジャケット"));
return price;
}
public static void main(String[] args) {
List<KV<String,String>> prices = getInitialDataPriceGoodsKV();
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline pipeline = Pipeline.create(options);
PCollection<KV<String,String>> priceCollection = pipeline.apply(
"Price Grouping",
Create.of(prices)
);
PCollection<String> priceGroupCollection =
priceCollection
.apply(
GroupByKey.create())
.apply(
"KV to String",
ParDo.of(
new DoFn<KV<String, Iterable<String>>, String>() {
@ProcessElement
public void prcessElement(ProcessContext c){
KV<String,Iterable<String>> elem = c.element();
String output = "";
for(String e : elem.getValue() ) {
if(!StringUtils.isEmpty(output)){
output = output + "," + e;
}else{
output = e;
}
}
c.output(elem.getKey() + ":" + output);
}
}
)
);
priceGroupCollection.apply(TextIO.write().to("./src/main/resources/priceGroup.txt").withoutSharding());
pipeline.run().waitUntilFinish();
}
GroupByKey.create()でInputデータのkeyでグルーピングしたKV<String, Iterable<String>>のデータを生成します。
そしてFnDoの匿名クラスでKV<String, CoGbkResult>からStringへ変換しています。
出力結果はこちらです。
2000:デニムパンツ,ビジネスシャツ
3000:ジャケット
1000:靴下,タオル,Tシャツ
CoGroupByKey
複数のkey/value形式のデータをグルーピングするために利用するCoGroupByKeyを実装してみます。
実際のプロジェクトの場合、頻繁に利用する処理だと思います。
ダミーデータは、商品名とサイズ、商品名と売り上げのListになります。
public static List<KV<String,String>> getInitialDataGoodsSizeKV() {
List<KV<String,String>> goods = new ArrayList<>();
goods.add(KV.of("Tシャツ","S"));
goods.add(KV.of("Tシャツ","M"));
goods.add(KV.of("Tシャツ","L"));
goods.add(KV.of("ジャージ","S"));
goods.add(KV.of("ジャージ","L"));
goods.add(KV.of("ダウンジャケット","XL"));
return goods;
}
public static List<KV<String,String>> getInitialDataGoodsSalesKV() {
List<KV<String,String>> sales = new ArrayList<>();
sales.add(KV.of("Tシャツ","10000"));
sales.add(KV.of("Tシャツ","20000"));
sales.add(KV.of("ジャージ","50000"));
sales.add(KV.of("デニムパンツ","4000"));
sales.add(KV.of("デニムパンツ","30000"));
return sales;
}
public static void main(String[] args) {
List<KV<String,String>> goodsSizeKV = getInitialDataGoodsSizeKV();
List<KV<String,String>> goodsSalesKV = getInitialDataGoodsSalesKV();
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline pipeline = Pipeline.create(options);
PCollection<KV<String,String>> goodsSizeKVCollection =
pipeline.apply("GoodsSize KV",Create.of(goodsSizeKV));
PCollection<KV<String,String>> goodsSalesKVCollection =
pipeline.apply("GoodsSales KV",Create.of(goodsSalesKV));
final TupleTag<String> goodsSizeTag = new TupleTag<>();
final TupleTag<String> goodsSalesTag = new TupleTag<>();
PCollection<String> goodsSizeSalesCollection =
KeyedPCollectionTuple.of(goodsSizeTag,goodsSizeKVCollection)
.and(goodsSalesTag,goodsSalesKVCollection)
.apply(CoGroupByKey.create())
.apply(
"KV to String",
ParDo.of(
new DoFn<KV<String, CoGbkResult>, String>() {
@ProcessElement
public void prcessElement(ProcessContext c){
KV<String, CoGbkResult> elem = c.element();
Iterable<String> goodsSize = elem.getValue().getAll(goodsSizeTag);
Iterable<String> goodsSales = elem.getValue().getAll(goodsSalesTag);
String output = "";
for(String size : goodsSize ) {
if(!StringUtils.isEmpty(output)){
output = output + "," + size;
}else{
output = size;
}
}
for(String sales : goodsSales ) {
if(!StringUtils.isEmpty(output)){
output = output + "," + sales;
}else{
output = sales;
}
}
c.output(elem.getKey() + ":" + output);
}
}
)
);
goodsSizeSalesCollection
.apply(TextIO.write().to("./src/main/resources/goodsSizeSales.txt").withoutSharding());
pipeline.run().waitUntilFinish();
}
複数のkey/value形式の結合イメージとしては、SQLで言うところFULL OUTER JOINをイメージしてもらえれば分かり易いと思います。KeyedPCollectionTuple.of()で結合対象データを指定し、CoGroupByKey.create()で結合しています。
KeyedPCollectionTuple.of()とCoGroupByKey.create()の部分の説明は、Apache Beam Programingガイドの内容を引用させて頂きます。
In the Beam SDK for Java,
CoGroupByKeyaccepts a tuple of keyedPCollections (PCollection>) as input. For type safety, the SDK requires you to pass eachPCollectionas part of aKeyedPCollectionTuple. You must declare aTupleTagfor each inputPCollectionin theKeyedPCollectionTuplethat you want to pass toCoGroupByKey. As output,CoGroupByKeyreturns aPCollection>, which groups values from all the inputPCollections by their common keys. Each key (all of typeK) will have a differentCoGbkResult, which is a map fromTupleTagtoIterable. You can access a specific collection in anCoGbkResultobject by using theTupleTagthat you supplied with the initial collection.
The following conceptual examples use two input collections to show the mechanics of CoGroupByKey.
簡単に説明すると、TupleTagオブジェクトをCoGbkResultオブジェクトのMapアクセスのキーとして利用するため、TupleTagを宣言してKeyedPCollectionTuple.of()に渡しています。そのためDoFn()の中でgoodsSizeTagを用いてelemからIterable<String> goodsSizeが取得できるのです。
出力結果はこちらです。
Tシャツ:L,M,S,10000,20000
ジャージ:L,S,50000
ダウンジャケット:XL
デニムパンツ:4000,30000
pom.xml
Mevenプロジェクトで開発する場合のpom.xmlの設定はこちらを参考にしてください。
Apache beamのJavaの対応バージョンはJava 8になるのでご注意ください。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>studyapachebeam</groupId>
<artifactId>study-apache-beam</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven-compiler-plugin.version>3.7.0</maven-compiler-plugin.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven-exec-plugin.version>1.6.0</maven-exec-plugin.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.19.0</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.19.0</version>
<scope>runtime</scope>
</dependency>
</dependencies>
</project>
最後に
Dataflowは大量データを処理できる非常にパワフルなサービスなので興味がある人はは是非体験してください。
ただし、実際にサービスで利用する場合は開発要件がマッチしているかどうかは慎重に吟味することをお勧めします。
初めてDataflow(ApacheBeam)を実装する人は様々なサンプルコードを動かしてほしく、本記事を書かせていただきました。
誰かの手助けになれば幸いです。
誤記などありましたら、お手数でですがご連絡いただければと思います。