この記事はIQ1の2枚目っ Advent Calendar 2019に投稿されています.
IQ1の機械学習
機械学習をするためにはデータの前処理とモデルのハイパラ探索は避けて通れません.でもIQが1なのでデータの前処理もハイパラ探索もできればやりたくないです.
データの前処理はこのご時世勾配ブースティング木系のアルゴリズム(lightgbmとか)に入れてあげれば欠損値も一応そのまま扱えるしカテゴリ変数の前処理をしなくて済むので比較的IQ1にも優しい世界になりました.
一方でハイパラ探索はIQ1には難しすぎます.モデルのハイパラがそれぞれどういうものでどれくらいの範囲を探索すればいいのかが分かっていないといけないので非常に困難です.
lightgbm_tuner
最近optunaがlightgbmのハイパラ探索を自動化するためにoptuna.integration.lightgbm_tunerというモジュールを公開しました.このモジュールは色んな理由でIQ1にも優しいです.
- ハイパラの探索を完全に自動でやってくれる
- step-wiseで探索(各パラメータごとに探索)するので高速に探索できる
- 既存のlightgbmのコードを数箇所書き換えるだけですぐに利用できる(後述)
IQ1の自動ハイパラ探索
最新版のoptunaをインストールしといてください.0.19.0とかだった気がします.pip install optuna --upgradeとかで入ります.
データセットの用意
今回用いるデータセットはkaggleのHouse Pricesにします.
(https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview)
このデータセットは土地の情報とか建物の情報からその家の価格を予測するというデータセットです.
まずはデータをkaggleのAPI使ってダウンロードします
$ kaggle competitions download -c house-prices-advanced-regression-techniques
適当にzipを解凍したらtrain.csvとtest.csvとかが出てきます.今回はsubmitはめんどくさいのでしないのでtrain.csvしか使いません.
適当にjupyter notebookでもなんでもいいのでpythonを開いてpandasでreadしましょう.
import pandas as pd
df=pd.read_csv("train.csv")
print(df.shape)
(1460, 81)
1460件のデータで列が81なことがわかりました.この中にはIDと予測するSalePriceが入っているので使える特徴量は79次元です.
とりあえずいらない列は落として目的変数は別に置いておきましょう
y=df.SalePrice
X=df.drop(["Id","SalePrice"],axis=1)
次に欠損値の確認をします.が,lightgbmに突っ込むので処理はしません.確認だけです.
X.loc[:,pd.isnull(X).any(axis=0)].columns
Index(['LotFrontage', 'Alley', 'MasVnrType', 'MasVnrArea', 'BsmtQual',
'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2',
'Electrical', 'FireplaceQu', 'GarageType', 'GarageYrBlt',
'GarageFinish', 'GarageQual', 'GarageCond', 'PoolQC', 'Fence',
'MiscFeature'],
dtype='object')
次に要素がStringの列についてカテゴリ変数としてlightgbmで扱ってもらうためにlabelencodingをしてからdtypeをcategoryとします.labelencodingは一言で言えば要素がダブらないように文字列を整数値に置き換えるだけです.
from sklearn.preprocessing import LabelEncoder
for name in X.columns:
if X[name].dtype=="object":
# LabelEncoderにNaNが入力できないため"NAN"とする
X[name]=X[name].fillna("NAN")
le = LabelEncoder()
le.fit(X[name])
encoded = le.transform(X[name])
X[name] = pd.Series(encoded).astype('category')
普通のlightgbmで学習
前処理が終わったのでlightgbmに学習させます.こちらのコードが普通のlightgbmに突っ込んだ時のものです
import lightgbm as lgb
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=1)
train_dataset=lgb.Dataset(X_train,y_train)
valid_dataset=lgb.Dataset(X_test,y_test,reference=train_dataset)
# 時間測定用
# %%time
params={"objective":"regression",
"learning_rate":0.05}
model=lgb.train(params,
train_set=train_dataset,
valid_sets=[valid_dataset],
num_boost_round=300,
early_stopping_rounds=50)
...(省略)...
Early stopping, best iteration is:
[113] valid_0's l2: 6.65263e+08
CPU times: user 3.11 s, sys: 537 ms, total: 3.65 s
Wall time: 4.47 s
学習できました.学習にかかる時間は4.47秒でした.
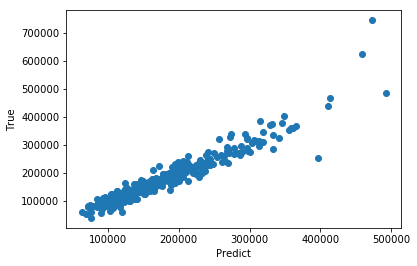
ちなみに予測結果をプロットしたらこんな感じでした.横軸が予測値で縦軸が真値です.
lightgbm_tunerで学習
上記のコードを書き換えてIQ1のハイパラ探索をします
import lightgbm as lgb
import optuna.integration.lightgbm_tuner as lgb_tuner
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=1)
train_dataset=lgb.Dataset(X_train,y_train)
valid_dataset=lgb.Dataset(X_test,y_test,reference=train_dataset)
params={"objective":"regression",
"learning_rate":0.05,
"metric":"l2"}
model=lgb_tuner.train(params,
train_set=train_dataset,
valid_sets=[valid_dataset],
num_boost_round=300,
early_stopping_rounds=50)
書き換わった場所わかりますか?IQ1の間違い探しです.
書き換わった場所は以下の3箇所です
- import文の追加
-
lgb.trainからlgb_tuner.trainに変更 -
paramsに最適化する値metricを追加
ちなみに学習時間は以下の通りです.思ったより遅かった…
CPU times: user 3min 24s, sys: 33.8 s, total: 3min 58s
Wall time: 3min 48s
validationデータのスコアは以下の通りです.
model.best_score
defaultdict(dict, {'valid_0': {'l2': 521150494.1730755}})
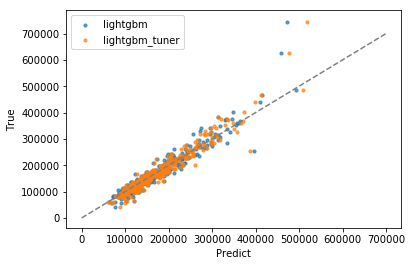
今回の実験結果を比較するとこんな感じです.チューニング後はちゃんと性能上がってますね.
| lightgbm | lightgbm_tuner | |
|---|---|---|
| 学習時間 | 4.47 s | 228 s |
| validデータの精度(MSE) | 6.65263e+08 | 5.21150e+08 |
プロットを見てもPriceの高い方(右のほう)がいい感じになってるのがわかりますね
おわり
これ使えばIQ1でも機械学習ができそうですね!!
ちなみにこれでできたモデルで提出したら2000位くらいでした.(参加人数がsample_submission.csv以上で4900人なのでIQ1以下の人がたくさんいました)
追記
気分でoptunaを使ってハイパラ探索をしてみたらvalidationスコアは上がったけどsubmitスコアは少し悪くなりました.(提出の際にはlearning_rate=0.05,num_boosting_round=1000,early_stopping_rounds=50で再学習させてます)
validationデータに対してoverfitしちゃったんですかね.やっぱりIQ1にはハイパラ探索は難しいですね.
もし何か実践的なハイパラ探索のアドバイスがあればコメントください!!
今回のチューニング戦略は以下の通りです.
- チューニングできそうなパラメータをひたすらに並べて雑に広めに範囲とる
-
learning_rateを粗く設定して試行回数を多くする
(スコアは低い程よい)
- デフォパラのlightgbmでの提出スコア: 0.13852
- lightgbm_tunerでの提出スコア: 0.13174
- optunaでの提出スコア: 0.13401
import optuna
def objective(trial):
'''
trial:set of hyperparameter
'''
# hypyer param
bagging_fraction = trial.suggest_uniform("bagging_fraction",0,1)
bagging_freq = trial.suggest_int("bagging_freq",0,10)
feature_fraction = trial.suggest_uniform("feature_fraction",0,1)
lambda_l1 = trial.suggest_uniform("lambda_l1",0,50)
lambda_l2 = trial.suggest_uniform("lambda_l2",0,50)
min_child_samples = trial.suggest_int("min_child_samples",1,50)
num_leaves = trial.suggest_int("num_leaves",2,50)
max_depth = trial.suggest_int("max_depth",0,8)
params={"learning_rate":0.5,
"objective":"regression",
"bagging_fraction":bagging_fraction,
"bagging_freq":bagging_freq,
"feature_fraction":feature_fraction,
"lambda_l1":lambda_l1,
"lambda_l2":lambda_l2,
"min_child_samples":min_child_samples,
"num_leaves":num_leaves,
"max_depth":max_depth}
model_opt = lgb.train(params,train_set=train_dataset,valid_sets=[valid_dataset],
num_boost_round=70,early_stopping_rounds=10)
return model_opt.best_score["valid_0"]["l2"]
study = optuna.create_study()
study.optimize(objective, n_trials=500)
...(省略)...
[I 2019-12-01 15:02:35,075] Finished trial#499 resulted in value: 537618254.528029. Current best value is 461466711.4731979 with parameters: {'bagging_fraction': 0.9973929186258068, 'bagging_freq': 2, 'feature_fraction': 0.9469601028256658, 'lambda_l1': 10.1589501379876, 'lambda_l2': 0.0306013767707684, 'min_child_samples': 2, 'num_leaves': 35, 'max_depth': 2}.
validationスコアは4.61467e+08でした