- この記事は https://arxiv.org/abs/1911.04738 を読んだので半分自分用の備忘録的なまとめです
概要
- 化合物を特徴化する手法(Fingerprint)を生成する手法
- 特徴化するために,Attention AutoEncoderで教師なし事前学習
- AutoEncoderの入出力は化合物の文字列表現であるSMILES
背景
- Fingerprintはこれまでたくさん開発されてきたが,それらはrule-basedなもの
- 一方でGraph Neural Network(GNN)を使って化合物をグラフ表現にして入力することでend-to-endで学習する手法も開発されてきた
- しかし,GNNを使うためには大規模なラベル付きデータを用意しなければならないがそれは難しいことが多いため,GNNという手法には限界がある.
- VAEなどを使って事前学習をして化合物のベクトル表現を得る手法はこれまでもいくらかある.
- ただ,データセットが小さい時についての議論が足りてない
- SMILES TransformerはNLPの分野での事前学習手法であるTransformerをChemoinformaticsに適用したもの.
手法
- 画像は論文中より引用
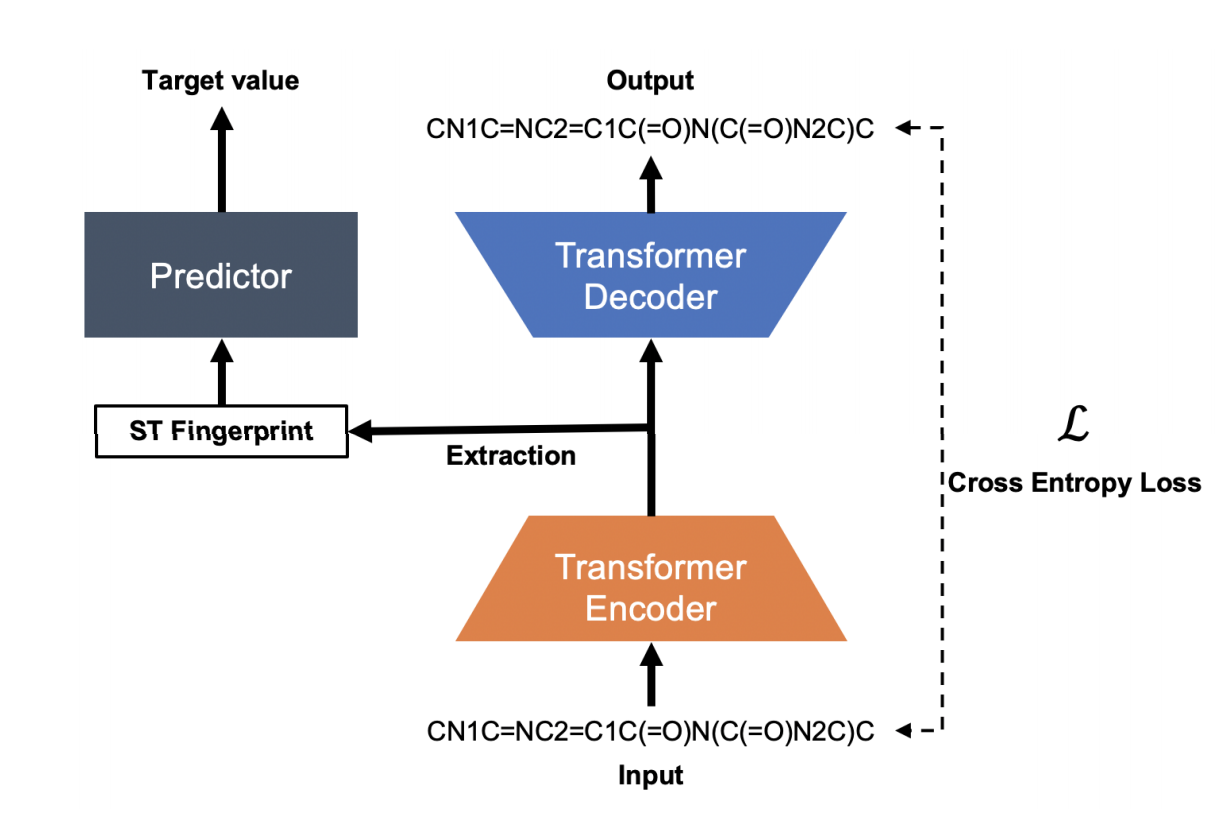
AutoEncoder
入力
- SMILES
- シンボルに区切る(e.g. "Br","c","1","(","=")
- シンボルをlabel-count encoding (論文中にはone-hotって書いてあったけどコード見たらlabel-count encodingっぽく見えた)
- depth=256次元でembedding
- PositionalEncoding
出力
- Linear層に突っ込んでsoftmax
Pre-train
- 861,000化合物をChEMBL24からランダムに取得
- Canonical SMILESのバイアスをなるべく除去するためにSMILES Enumeratorを使ってRandomizeされたSMILESを生成
- encoderとdecoderはそれぞれ4層のtransformer層
Fingerprint
- encoderから出てくる行列は((分子のシンボル長),256)となっていて,このままだとFingerprintとしては使えない
- この行列はシンボルレベルの情報を持っているらしい
- シンボルレベルの情報を分子レベルに集約するために以下の4つを結合(256*4=1024次元)
- encoderの最終層の第一成分のmean
- encoderの最終層の第一成分のmax
- encoderの最終層の第一成分の先頭(最初のシンボルに当たるもの,のはず)
- encoderの最後から1つ前の層の第一成分の先頭
- ECFP4に合わせて1024次元にした
結果
そのうち書く
わからんところ
- Fingerprint化する時にencoderの最終層と最後から1つ前の層の第一成分の先頭を持ってきたところのお気持ちがよくわからない.集約せずにどっかの情報を持ってきたい気分はなんとなくわかるが先頭でいいの?