こんにちは、Perl 6アドベントカレンダーの15日目の投稿になります。
NLP 5本ノックということで、東北大学の言語処理100本ノックの『第4章: 形態素解析』の 35~39までの5本のうちの前半3本をPerl 6で解きつつ解説をしていきたいと思います。
問題文は掲載しませんので、ブラウザの別窓で下記ページを参照しながらお楽しみください:
http://www.cl.ecei.tohoku.ac.jp/nlp100/#ch4
読み進める前に
注意!
- 読者レベルとしては、Perl 6アドベントカレンダー1日目で紹介したPerl 6 introductionなどのチュートリアルを一通り終えたレベルを想定しています。
- わかりやすく紹介するために、正確ではない表現がところどころ出てくるかもしれません。
- より正確な情報を知りたい場合は、Perl 6アドベントカレンダー1日目で紹介した公式ドキュメント や公式テストケースのroastなどを参照ください。
- 日本語訳が定着していないようなPerl 6独特の英単語を目にするかもしれません。基本的に解説中ではそのまま英単語で書き、その後補足しますのでご容赦ください。
- Perl 6のモットーはTMTOWTDI (やり方は一つじゃない) です。特に正解はありません。でも、「これのほうがもっとかっこよく簡潔に書けるよ!」といった指摘は大歓迎です!
- 元の35~37の問題文だと、30で生成されたデータをそれ以降で使う流れになっています。しかし、ここではバインダの使い方を紹介したかった関係で無視しているので注意してください。
準備
- 拙作のMeCabのPerl 6バインダを入れてください。下記コマンドで、READMEに書いてあるようにIPAdicも勝手に入ります。
$ zef install MeCab
35. 名詞の連接
コード
use MeCab;
use MeCab::Tagger;
my $fh = open "neko.txt", :r;
my MeCab::Tagger $tagger .= new;
for $fh.lines {
my Bool $has-conn = False;
my Str $cat = "";
loop (my MeCab::Node $node = $tagger.parse-tonode($_); $node; $node = $node.next) {
if $node.posid R(cont) 36..67 {
if $has-conn {
$cat ~= $node.surface; # (#1)
} else {
$cat = $node.surface; # (#2)
}
$has-conn = True;
} else {
$has-conn = False;
say $cat if $cat.chars > 0;
$cat = ""; # (#3)
}
}
}
$fh.close;
解説
-
$has-connは名詞が連続して生起している最中か否かを示す変数です。 -
$catは現在保持している最長の名詞句です
-
open "neko.txt", :rで読み取り専用モードでファイルを開き、ファイルハンドルを変数に代入します。
一行ずつ読み取っていきます -
$tagger.parse-tonodeで与えられた行を形態素解析します。形態素の並びをみていきます。
- 現在の形態素が名詞で、名詞が連続している最中なら、
~で文字列をつなげます (#1) - 現在の形態素が名詞で、名詞が連続している最中でないなら、現在の名詞を
$catに代入します (#2) - 現在の形態素が名詞以外なら、
$catに文字列が入っている場合は出力します。そして、$catを空にします。 (#3)
36. 単語の出現頻度
コード
use MeCab;
use MeCab::Tagger;
my $fh = open "neko.txt", :r;
my MeCab::Tagger $tagger .= new;
.say for gather for $fh.lines {
loop (my MeCab::Node $node = $tagger.parse-tonode($_); $node; $node = $node.next) {
next if $node.stat == MECAB_BOS_NODE|MECAB_EOS_NODE;
take $node.surface;
}
}.Bag.sort({ $^b.value <=> $^a.value }).map: { .kv.join("\t") };
$fh.close;
解説
-
open "neko.txt", :rで読み取り専用モードでファイルを開き、ファイルハンドルを変数に代入します。
一行ずつ読み取っていきます -
gather for takeイディオムで表記の遅延リストを生成します -
$tagger.parse-tonodeで与えられた行を形態素解析します -
takeでその形態素の表記を取得します。 -
.Bagでキーが表記、値が頻度のリストを生成します -
.sort({ $^b.value <=> $^a.value })で頻度の降順にソートします -
.map: { .kv.join("\t") }で各表記・頻度のペアをタブ区切りにします -
.say for 《5. の出力のリスト》で出力を行います
補足
-
$node.statは形態素の種類を示すenum型の数字を返します(このバインダでは)。詳しくは下記を参照ください。
37. 頻度上位10語
コード
use MeCab;
use MeCab::Tagger;
use SVG;
use SVG::Plot;
my $text-fh = open "neko.txt", :r;
my MeCab::Tagger $tagger .= new;
my @bag-of-words = gather for $text-fh.lines {
loop (my MeCab::Node $node = $tagger.parse-tonode($_); $node; $node = $node.next) {
next if $node.stat == MECAB_BOS_NODE|MECAB_EOS_NODE;
take $node.surface;
}
}.Bag.sort({ $^b.value <=> $^a.value }).head(10);
my $plot-fh = open 'word-top10.svg', :w ;
$plot-fh.say(
SVG.serialize: SVG::Plot.new(
:title( '単語の分布' ),
:width( 400 ),
:height( 300 ),
:background( '#fffff0' ),
:colors( '#4169e1' ),
:label-font-size(10),
:labels( @bag-of-words>>.key ),
:values( item(@bag-of-words>>.value) ),
).plot(:stacked-bars)
);
$text-fh.close;
$plot-fh.close;
解説
前半
-
open "neko.txt", :rで読み取り専用モードでファイルを開き、ファイルハンドルを変数に代入します。
一行ずつ読み取っていきます -
gather for takeイディオムで表記の遅延リストを生成します -
$tagger.parse-tonodeで与えられた行を形態素解析します -
takeでその形態素の表記を取得します -
.Bagでキーが表記、値が頻度のリストを生成します -
.sort({ $^b.value <=> $^a.value })で頻度の降順にソートします -
.head(10)で上位10件だけ取り出して変数に代入します
後半
-
SVG::Plotを利用してグラフを生成していきます。8日目:Perl6 の SVG::Plot でグラフを描こうでも登場したかと思います
-
open 'word-top10.svg', :wで書き込みモードでファイルハンドルをオープンし変数に代入します。 - グラフにおけるY軸を
:values( item(@bag-of-words>>.value) )、X軸を:labels( @bag-of-words>>.key )で指定します。またグラフの種類に.plot(:stacked-bars)で:stacked-barsを指定します。それ以外の設定は適当でよいと思います。 -
.sayでファイルへの書き出しを行います - ファイルハンドルをcloseします
- グラフを確認します。(Qiitaがsvgに対応してないようでしたので、pngに変換しています)
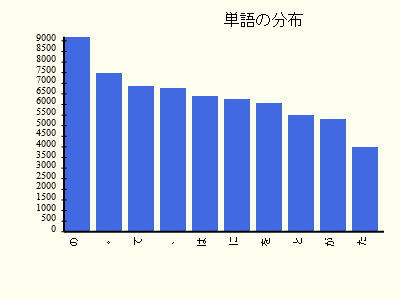
いいかんじですね。
以上、Perl 6アドベントカレンダーの15日目の投稿、Perl 6でNLP 5本ノック 『第4章: 形態素解析』 35~39 前編 でした。