概要
広告のCTR予測において、不均衡データはundersamplingして学習するのが一般的です。
ただし、順序ではなく確率値そのものを正しく予測したいケースで、undersamplingをすると正例負例比率が実際と異なり、calibrationがズレてしまいます。
そこで、モデルが出力する予測値(=以降predictCTRと表記)を実際のCTRに近づけるため、
モデル学習を行う際に学習データと一緒にsample_weightを渡すことでcalibrationを行っていきたいと思います。
sample weightの実装
XGBoostの学習・検証データは下記のようにdmatrix変換をしますが、
dtrain = xgb.DMatrix(train_x, label=train_y)
dvalid = xgb.DMatrix(valid_x, label=valid_y)
dmatrix変換時にsample weight配列を渡すことができます。
dtrain = xgb.DMatrix(train_x, label=train_y, weight=train['weight'])
dvalid = xgb.DMatrix(valid_x, label=valid_y, weight=valid['weight'])
実装はこれだけです。
weightの設定値については要望があれば別途説明したいと思います。
基本的には、ラベル0,1の比率に合わせて設定をしていきます。
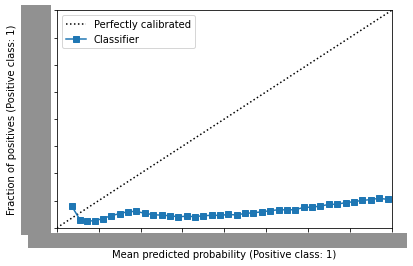
calibration実施前
- sample weightを渡さず、モデル学習をした場合
具体的なCTR値は伏せさせていただいています。
calibration curveでは、斜めに伸びる点線(=45度線)に近いほどcalibrationができていることが確認できます。
calbration curveをプロットしてみると、明らかに45度線から外れて下に張り付いています。
calibration curveの横軸はpredictCTR, 縦軸は実際のCTRです。
つまり、この図からわかることは、predictCTRが実際のCTRよりも大きく上振れてしまっているということです。
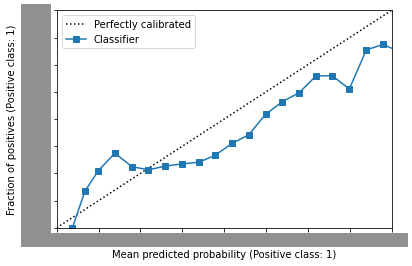
calibration実施後
- sample weightを渡して、モデル学習をした場合
先程のcalibrationなしの状態と比べると45度線に沿ってプロットされていることがわかるかと思います。
ヒストグラムも合わせて確認すると、calibrationが改善されていることが確認できました。
後書き
今回はsample weightを使ったcalibrationを試してみました。
calibrationの結果、CTR予測モデルの精度が実際に上がるのかについては検証中です。
引き続きcalibration周りの研究を進めるため、進展があれば追記していきたいと思います。